






这篇文章提出了一种名为dino.txt的新方法,旨在将自监督视觉模型DINOv2与文本对齐,从而使其能够处理开放词汇任务。以下是文章的主要内容总结:
-
背景与动机:
-
自监督视觉模型(如DINOv2)在多种下游任务中表现出色,但它们缺乏与语言的直接对齐,限制了其在开放词汇任务中的应用。
-
现有的视觉-语言模型(如CLIP)虽然具备语言对齐能力,但训练成本高昂。
-
-
方法:
-
dino.txt基于**LiT(Locked-image Text Tuning)**策略,冻结预训练的DINOv2视觉编码器,仅训练文本编码器以对齐视觉和语言特征。
-
通过将[CLS]标记与patch平均池化连接,改进图像表示,使其同时捕捉全局和局部信息。
-
在冻结的视觉编码器上添加两个可学习的视觉块,以更好地适应新的训练数据。
-
提出了一种结合文本和图像模态的数据筛选方法,平衡数据分布,提升训练效率。
-
-
实验与结果:
-
在零样本分类和开放词汇语义分割任务上,dino.txt取得了与最先进模型相当或更好的性能。
-
与CLIP相比,dino.txt在显著降低计算成本的情况下,达到了更高的分类准确率。
-
在开放词汇分割任务中,dino.txt无需额外工程改进,直接使用局部特征即可获得高质量的分割结果。
-
-
贡献:
-
提出了一种高效的方法,将自监督视觉模型与文本对齐,解锁了开放词汇能力。
-
通过改进图像表示和数据筛选策略,显著提升了模型在全局和密集任务上的性能。
-
揭示了现有分割基准在评估开放词汇分割任务时的局限性,并提出了改进方向。
-
-
未来工作:
-
探索如何在冻结视觉编码器和适应新数据之间找到更好的平衡,以进一步提升文本编码器的质量。
-
dino.txt通过简单的训练策略和高效的数据筛选,成功地将自监督视觉模型与文本对齐,为开放词汇任务提供了一种高效且强大的解决方案。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
自监督视觉基础模型生成的嵌入在广泛的下游任务中表现出色。然而,与CLIP [64]等视觉-语言模型不同,自监督视觉特征并未与语言对齐,这限制了它们在开放词汇任务中的应用。我们的方法名为dino.txt,为广泛使用的自监督视觉编码器DINOv2 [60]解锁了这一新能力。我们基于LiT训练策略 [92],该策略训练文本编码器以与冻结的视觉模型对齐,但在密集任务上表现不佳。我们提出了几个关键改进,以提升全局和密集任务的性能,例如将[CLS]标记与patch平均值连接以训练对齐,并使用文本和图像模态来筛选数据。通过这些改进,我们成功训练了一个类似CLIP的模型,仅需CLIP的一小部分计算成本,同时在零样本分类和开放词汇语义分割中取得了最先进的结果。
1 引言
现代视觉基础模型通过自监督学习(SSL)训练,生成了鲁棒且通用的特征,在下游任务中表现出色。这些特征通常直接使用,通过轻量级适配器(如线性分类器)进行微调,无需昂贵的微调过程。因此,一个强大的视觉骨干可以同时用于不同的任务。特别是DINOv2 [60],因其多功能性而广受欢迎。这个自监督模型训练用于捕捉图像的全局上下文和局部信息,在分类和分割等任务中取得了最先进的性能。然而,自监督视觉模型没有提供与语言的接口,限制了它们在开放词汇场景中的应用,而多模态模型 [15, 74] 则具备内置的语言-视觉对齐能力。在复杂且可提示的机器学习系统时代,这是一个显著的弱点。我们在这项工作中旨在通过将DINOv2的特征空间与语言对齐,为其配备语言接口,从而利用这个强大的自监督模型来处理开放词汇识别任务。
大多数先进的文本对齐视觉基础模型使用CLIP算法 [64] 的变体进行训练,该算法通过利用大规模、通常带有噪声的配对图像-文本数据集,训练视觉和文本编码器以在共享空间中对齐它们的模态表示。它们通常从头开始训练,导致计算成本高昂。锁定图像文本调优(LiT)[92] 是CLIP的一个变体,它使用冻结的预训练视觉模型作为视觉编码器,并仅训练文本编码器以与视觉编码器的嵌入空间对齐。这降低了计算成本,同时保留了视觉编码器的理想特性。在这项工作中,我们认为,鉴于现成的强大视觉编码器,我们可以并且应该以更低的成本实现比CLIP更好的视觉-语言对齐。为此,我们探索了将LiT训练应用于DINOv2作为视觉编码器。
如表1、3所示,将LiT应用于强大的DINOv2编码器并不简单,因为它在需要细粒度细节的任务(如语义分割或图像-文本检索)上表现不佳。首先,从使用CLIP/LiT训练范式训练的模型中获取良好的密集特征并不容易,该范式仅对比全局图像和文本表示。其次,由于冻结的视觉编码器,视觉预训练数据与LiT训练数据之间的领域差距可能会阻碍图像与其标题的对齐。为了解决这些问题,我们引入了对LiT范式的几项改进。我们不是使用视觉编码器的[CLS]标记来表示图像,而是将该标记与图像中所有patch标记的平均池化连接起来,作为视觉表示,以允许将图像的全局上下文和局部信息与其文本描述对齐。然后,我们通过在冻结的视觉编码器之上添加两个可学习的视觉块来减少上述领域差距,从而使视觉特征能够适应新的训练数据。我们在图1中展示了我们的训练在零样本分类和开放词汇分割中的好处。
此外,预训练数据的质量已被证明对模型的性能 [64, 88] 和训练效率 [27] 有强烈影响。我们展示了通过关注数据集筛选,我们可以进一步改进我们的训练过程。事实上,我们提出通过平衡图像和文本数据的长尾分布来筛选训练数据集。一个平衡良好的数据分布可以简化训练,使我们仅需一小部分计算成本就能达到良好的性能。这反过来又使我们能够尝试更宽的文本编码器,从而进一步提高性能。最后,我们的研究不仅为DINOv2解锁了文本对齐,还揭示了LiT框架的局限性,这些局限性在错误分析部分进行了讨论,为更有效和高效的框架指明了未来方向,以实现语言对齐的视觉基础模型。
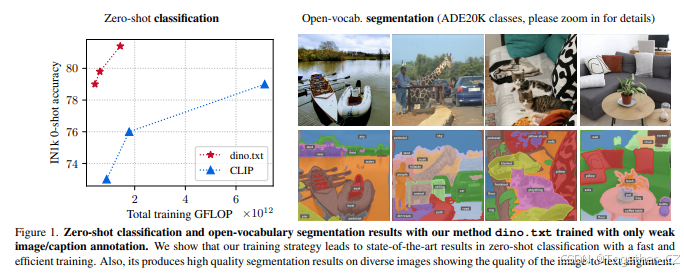
图1. 使用我们的方法dino.txt在仅使用弱图像/标题注释训练下的零样本分类和开放词汇分割结果。我们展示了我们的训练策略在快速高效的训练中实现了最先进的零样本分类结果。同时,它在多样化的图像上生成了高质量的分割结果,展示了图像到文本对齐的质量。
总结一下,这项工作的贡献包括:
(i) 一种名为dino.txt的新方法,为DINOv2解锁了图像和像素级的文本对齐,(ii) 在现有工作基础上的关键改进,使我们能够以通常计算成本的一小部分训练这种多模态对齐,(iii) 广泛的错误分析,展示了现有分割基准在这项任务中的局限性以及这些模型的不同错误类型。
2 相关工作
自监督特征学习。由于自监督训练的视觉特征具有良好的性能和泛化能力,它们被广泛应用于许多机器学习系统中。近年来,已经开发了多种学习这些模型的方法。其中,对比学习 [59] 训练模型将相似图像的特征拉近,同时将不相似图像的特征推远。著名的方法包括使用内存库的MoCo [36]、去除负样本对的BYOL [34]、对比在线聚类分配的SwAV [10] 或扩展SwAV到视觉Transformer的DINO [11]。相比之下,基于重建的方法通过预测输入图像的隐藏部分来学习,例如缺失像素(MAE [37])、来自量化码本的patch(BeiT [5])或潜在空间中的patch特征(I-JEPA [4])。在如此多的可行方法中,一个决定因素仍然是SSL方法是否能够随着数据和模型规模的增加而改进:多个工作 [31, 32, 33, 9] 探索了扩展问题,其中DINOv2 [60] 为这个问题设定了当前的最先进水平。
对比文本-图像预训练。利用文本元数据来训练图像理解模型的想法在计算机视觉中有着悠久的历史 [24, 28, 35, 46]。在深度神经网络的背景下,Joulin等人 [42] 提出使用图像标题中的单词作为目标来训练视觉编码器。这一核心思想在CLIP [64] 中得到了进一步改进。作者提出对图像和标题进行编码,并使用对比损失训练两者。标题的深度编码促进了跨句子的鲁棒泛化,例如通过折叠同义词,从而提高了学习效率。由于原始CLIP是在私有数据集上训练的,开源复现尝试主要集中在收集公共大规模数据集(LAION [70]),这导致了OpenCLIP [16] 系列模型的诞生。最近,Xu等人 [88] 描述了一种重新平衡图像-文本网络数据的简单程序,复现了CLIP的性能。通过DFN [27] 进一步提高了零样本性能,该模型提出过滤训练数据以匹配下游任务的分布。最近开发了更精细的系统:EVA-CLIP [73, 74] 或InternVL [15],在超过50亿参数的规模上展示了进一步缩小全监督和零样本模型在ImageNet上的差距。
除了数据和模型的扩展,还提出了对初始训练算法的一些修改。SigLIP [93] 考虑使用二元对数损失而不是多项交叉熵。LLIP [48] 提出在文本和图像寄存器标记 [18] 之间应用CLIP损失,这些标记以文本标记为条件。相比之下,我们在训练中没有使用任何改进的损失函数,而是坚持使用CLIP的原始对比损失,冻结图像编码器并训练可学习的文本编码器,遵循锁定图像文本调优(LiT [92])中描述的程序。
大规模自动数据筛选。自动数据筛选在训练具有大规模网络爬取数据集的基础模型中起着至关重要的作用,这些数据集通常达到数亿 [29, 69, 88] 的数据量。在这个规模上,手动注释变得不可行,因此这些数据集通常是从互联网上无监督收集的。这种野外数据固有地表现出数据类别的长尾分布 [53],这限制了模型有效学习广泛概念的能力。为了解决这个问题,基础模型的相关工作通常通过抑制头部(频繁)概念和提升尾部(稀有)概念来构建平衡的训练数据集。例如,CLIP的 [64] 数据准备管道收集了50万个频繁单词,并在原始数据集中查询每个单词以检索平衡数量的(图像,标题)对。该管道的未公开细节后来由MetaCLIP [88] 复现和形式化。DFN [27] 训练了一个数据评估模型,以评估数据的“质量”,从原始数据池中采样顶部样本。SemDeDup [2] 通过聚类检测删除重复数据点来修剪它。最后,Vo等人 [79] 通过在数据支持上均匀采样来平衡数据分布。这些方法将数据筛选应用于图像或标题,而我们平衡了两种分布,从而提高了性能并提高了训练效率。
开放词汇分割。CLIP模型可以通过对图像的不同视图执行多次前向传递 [3, 41, 45, 85] 或生成每个感兴趣概念的原型码本 [44, 71, 72] 来生成与文本对齐的patch级特征。MaskCLIP [97] 可以应用于大多数视觉-语言模型(VLM),通过移除最终的全局池化并将最终投影应用于最后一层注意力层的值嵌入,在CLIP空间中实现密集特征。这些特征可以通过改进的注意力机制 [7, 80] 或使用SSL模型作为指导 [43, 47, 86] 来进一步细化。这些努力与我们的工作是正交的,因为它们可以应用于任何密集的CLIP类特征。
通过使用像素级注释 [22, 30, 49, 51, 66, 81] 或粗略的图像/标题注释 [12, 30, 51, 52, 54, 58, 65, 89, 90, 94] 进行微调或从头开始训练CLIP类模型,可以获得改进的patch级对齐。在这项工作中,我们专注于后者。ViewCO [68] 利用多视图一致性,CLIPSelf [84] 使用教师-学生学习策略生成与裁剪获得的密集特征对齐的密集特征。GroupViT [89] 集成了可学习的标记,这些标记使用分组块进行训练,CoCu [87] 通过使用图像检索在图像-标题对上创建概念库并将其用作训练数据进一步改进了这一点。PACL [58] 使用专用模块训练patch到文本的亲和力,TCL [12] 提出局部对比目标以将精心选择的patch与文本对齐,CoDe [83] 使用单词-区域局部对比目标将图像区域与文本片段匹配。与我们更接近的是,CLIPpy [65] 微调了一个SSL视觉骨干和预训练的文本编码器以生成对齐的特征(使用平均patch),但以分类结果较差为代价。在这项工作中,我们展示了可以使用简单的损失训练具有图像和像素级对齐的模型。
3 提出的方法:dino.txt
在这项工作中,我们展示了将文本编码器与自监督视觉基础模型对齐的简单性和效率。我们展示了可以直接使用基础模型的嵌入空间来执行零样本分类和开放词汇语义分割。第一部分定义了模型架构和训练目标。然后我们描述了建立训练数据集的数据筛选,接着是我们的推理协议。我们方法的概述如图2所示。
锁定图像文本对齐

文本编码器由一系列Transformer [78] 块和一个顶部的单一线性层组成,该线性层将特征映射到图像嵌入大小。文本编码器的所有参数都按照LiT [92] 从头开始训练。我们遵循 [64, 92] 并将输出的[EOS]文本标记与图像嵌入对齐,从而获得相应句子和图像之间的全局对齐。
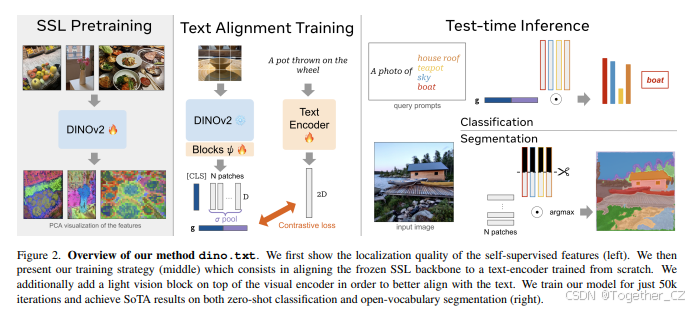
图2. 我们的方法dino.txt的概述。我们首先展示了自监督特征的定位质量(左)。然后,我们介绍了我们的训练策略(中),该策略包括将冻结的自监督学习(SSL)骨干与从头训练的文本编码器对齐。此外,我们在视觉编码器之上添加了一个轻量级的视觉块,以更好地与文本对齐。我们仅训练了50k次迭代,并在零样本分类和开放词汇分割任务上取得了最先进的结果(右)。
改进的图像表示用于文本对齐。在这里,我们描述了用于图像-文本对齐的图像表示的选择。我们旨在改进用于分类和检索任务的全局级文本对齐,以及用于分割的patch级对齐,使用_一个不需要任何像素级监督的单一学习目标_。以前的工作提出了专门为任务设计的方法:对于图像级分类,[CLS]嵌入c是文本对齐的主要选择 [64],而对于分割,最终的patch嵌入可以池化 [58, 65],例如使用最大或平均池化,强制梯度流向patch,但不幸的是会损害分类性能 [65]。相反,我们在这里旨在强制_全局和局部_与文本的对齐。为此,我们将[CLS]嵌入与平均池化的patch嵌入连接起来。

其中“;”表示连接。我们发现使用平均池化作为σ效果最好。通过将梯度传播到patch标记的平均值,每个标记都可以学习为最终描述符做出贡献,从而实现更细粒度的对齐。我们在表2中讨论了这种表示对密集任务的重要性。有趣的是,我们观察到这种联合表示提高了下游分类和分割任务的对齐。
对比锁定图像文本对齐。图像-文本对齐目标鼓励文本表示接近其配对的图像,同时将其与非对应的图像排斥。如前所述,我们使用图像描述符g作为文本嵌入的对齐目标。在图像骨干冻结的情况下,可训练的部分包括额外的视觉块和文本编码器。我们使用对比学习目标 [64] 在图像-标题对的数据集上进行训练,该数据集是自动筛选的,没有任何监督。
基于文本和图像的数据筛选
训练数据在机器学习模型性能中起着至关重要的作用 [79, 88]。CLIP风格的VLM训练需要高质量的图像-文本对,然而现有的数据筛选方法仅依赖于文本模态 [64, 88],我们稍后将展示这是次优的。例如,最近的MetaCLIP [88] 从互联网收集的大规模图像-文本对池中筛选CLIP训练数据。它首先基于WordNet [55] 同义词集和维基百科构建一组文本查询。接下来,建立从每个查询到其标题包含查询的图像-文本对的映射。最后,从这些集合中对对进行子采样以形成最终数据集。这种方法显著提高了CLIP的性能,但它忽略了数据池中视觉概念的分布。如果图像和其标题之间的概念完全对齐,那么基于文本选择数据将导致视觉空间中的平衡选择。然而,从互联网自动收集的标题通常带有噪声,并不完全描述相应图像中的内容(见图3),因此,忽略图像分布是次优的。

在这项工作中,我们提出通过结合文本和图像筛选来平衡标题和图像分布。我们使用 [88] 进行文本筛选,而对于图像筛选,我们使用Vo等人 [79] 的基于聚类的方法。后者将数据池划分为连贯的簇,从中采样数据以形成筛选后的数据集。与 [88] 不同,这种方法不需要预定义的概念集来执行聚类,这在视觉空间中并不容易构建。相反,它使用层次化k-means构建簇。通过这种方式获得的簇在空间中均匀分布,其大小自然遵循长尾分布。然后通过从簇中进行子采样来形成筛选后的数据集,以减少头部簇的影响,从而平衡概念。在这项工作中,我们提出将这种筛选方法应用于图像,并将 [88] 的管道应用于标题。然后我们取这些结果的交集以形成最终选择。
推理

4 实验
任务和指标
零样本分类。我们使用CLIP中描述的协议在ImageNet-1K [19] (IN1K)、ImageNet-v2 [67] (IN-v2)、ImageNet-Adversarial [38] (IN-A)、ObjectNet [6] (ObjNet)、iNaturalist2021 [40] (iNat21) 和Places205 [95] (PL205) 上评估零样本分类。在测试时,我们将类名输入文本编码器以检索文本向量,并测量它们与图像编码器生成的全局描述符的余弦相似度。
图像-文本检索。我们在标准跨模态检索基准上评估图像-文本检索:COCO2017 [76] 和Flickr30K [63]。这些数据集包含图像及其对应描述性标题的对。任务涉及基于文本查询找到最相似的图像。我们使用Recall@1指标,如果最近的图像匹配真实对,则等于1,否则为0。
开放词汇分割。我们在ADE20K 96、Cityscapes [17] (City.)、COCO-Stuff 8、PASCAL Context [56] (C59) 和PASCAL VOC20 26 数据集上评估dimo.txt在开放词汇分割任务中的结果。我们使用mIoU指标(平均交并比)。为了生成像素级特征,我们使用第3.3节中详述的推理程序,并另外遵循TCL [12] 的滑动窗口协议。如果没有特别说明,我们使用模型生成的最终patch标记嵌入。然而,大多数通用图像-文本编码器 [27, 64, 73, 74, 93] 不会在最终patch嵌入上应用监督信号,导致输出patch质量较差。因此,我们使用众所周知的MaskCLIP [97] 策略来评估这些方法在分割任务上的表现。它转发最后一层注意力层中的值嵌入(绕过最终注意力),从而在对齐空间中生成patch嵌入。
实现细节
训练。我们在PyTorch [62] 中实现了我们的训练框架。我们遵循OpenCLIP库 [39] 中的CLIP损失函数实现。我们使用PyTorch的torch.compile功能在Nvidia A100 GPU(80 GB VRAM)上进行高效训练。从 [18] 初始化的DINOv2视觉编码器保持冻结,这节省了计算和内存,允许比CLIP更大的批量大小,如表3所示。对于表1,2中的数字,我们遵循CLIP的配方并将批量大小设置为32K。在其他表中,我们使用65K以获得更好的结果。我们还观察到,通过训练50K次迭代可以获得良好的结果,这对应于在32K和65K批量大小下分别看到的1.6和32亿图像-文本对。我们选择此设置作为默认设置,并在第4.3节中讨论更多超参数。
训练数据集。我们将第3.2节中描述的文本和图像筛选过程应用于从CommonCrawl [1] 派生的初始数据池,该数据池包含23亿图像-文本对。我们使用我们的筛选策略每epoch采样6.5亿对。对于基于文本的筛选部分,数据池中的文本频率是离线预计算的,并且频繁的文本数据被随机丢弃,遵循 [88]。这个过程每epoch保留9亿对。对于基于图像的筛选,我们使用预训练的DINOv2 ViT-L/14提取嵌入,用于离线3级层次化kk-means [79],每级分别有20M、800K和80K个中心。我们同样丢弃出现在大簇中的对,每epoch保留15亿对。给定epoch的最终训练数据集由在文本和图像筛选过程中保留的文本-图像对组成,以下称为LVTD-2.3B,代表大规模视觉文本数据集。
高分辨率推理。典型的分割协议,由TCL [12] 推广,包括应用滑动窗口策略并将分割结果聚合到单个预测图中。我们将此策略扩展到高分辨率窗口程序,在该程序中,我们以密集滑动窗口方式采样各种大小的裁剪(1%、10%、100%的总面积),并向坐标添加噪声,使得裁剪对应于非矩形四边形。我们将裁剪扭曲为正方形,提取特征,然后通过插值将特征投影回密集像素网格,并平均所有贡献。我们使用k-means聚类特征,k=32,然后在中心上运行零样本分类器。对于使用此程序的结果,每个像素平均被访问40次,在A100 GPU上总共处理大约800个裁剪,耗时10秒。这种方法展示了更精细尺度的特征,改进该程序是未来的工作方向。我们在表6(最后一行)中提供了结果,并在图4中进行了可视化。
我们的方法dimo.txt的消融研究
我们在本节中研究了dimo.txt不同组件的影响。在所有实验中,我们按照Xu等人 [88] 从LVTD-2.3B获得的基于文本筛选的数据集上训练模型,除非另有说明。
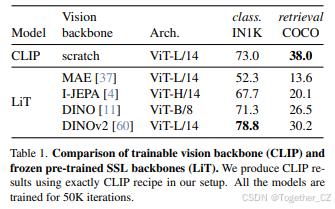
LiT与SSL并不简单。为了训练文本编码器以与DINOv2特征对齐,我们采用了LiT。我们使用DINOv2 ViT-L/14视觉编码器和预训练的BERT-base [20] 进行的初步LiT实验在CC12M [13] 上训练时,在IN1K上达到了70.0的零样本准确率。作为比较,原始LiT论文报告了使用ViT-L/16视觉编码器和预训练的BERT-large文本编码器在相同数据集上训练时的67.6。接下来,我们在更大的数据集LVTD-2.3B上训练我们的模型,并在表1中比较了CLIP和LiT与不同预训练视觉编码器的性能。我们观察到,在考虑的视觉骨干中,DINOv2带来了最佳性能。它使LiT在分类中取得了良好的结果。然而,与CLIP相比,检索性能有所下降,这可能是由于冻结的视觉编码器无法适应新的训练数据。这些结果表明,我们需要一种新的策略来对齐冻结的骨干编码器与文本,使其能够泛化到不同的任务,例如我们提出的dimo.txt。
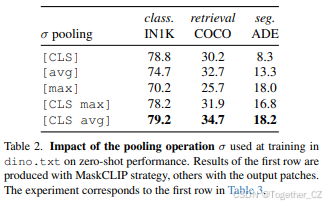
训练时池化操作σ的影响。我们在表2中评估了训练时池化操作的选择对下游任务性能的影响。通常,方法使用最大 [65] 或平均池化 [58] 来对齐patch嵌入与文本,但这会损害分类结果。我们在实验中观察到相同的现象,单独使用最大或平均池化会降低分类性能。然而,当我们使用我们提出的连接池化 [CLS avg] 时,我们获得了_分类和密集任务_的显著提升,表明无需在任务之间进行选择。
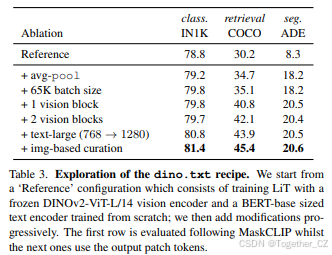
改进的训练配方。我们在表3中评估了我们训练中不同组件的影响。除了我们的池化策略,我们还观察到使用更大的批量大小也提高了所有任务的结果。有趣的是,在视觉编码器之上添加两个可学习的视觉块显著提高了检索结果,表明该任务需要更好的视觉与文本的对齐。将文本嵌入大小从768增加到1280也在所有任务上带来了大幅提升。最后,我们可以观察到结合图像和文本筛选的重要性,这将在下面进一步讨论。
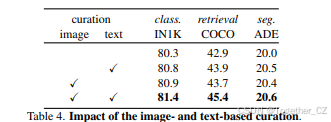
数据集筛选的影响。表4分解了每种数据筛选策略对dimo.txt结果的影响。基于文本和图像的数据筛选都有助于重新平衡长尾数据分布,并提升性能。我们提出的结合它们的方法在所有三个任务上带来了最佳性能。这一结果突显了基于文本和视觉模态筛选数据对视觉-语言训练的重要性。
与最先进技术的比较
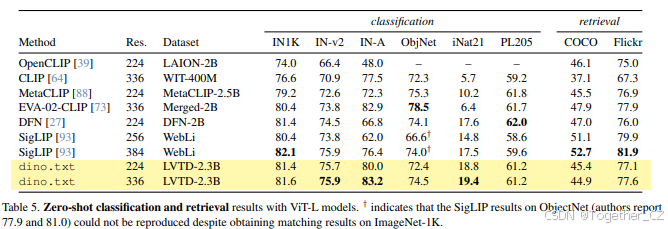
零样本分类和检索。我们在表5中比较了dimo.txt与最先进的基线在两个图像级理解任务上的表现:零样本图像分类和跨模态检索。我们的模型在分类基准上与替代的CLIP类模型相当或更好,在INv2、IN-A和具有挑战性的iNaturalist数据集上设定了最先进的性能。还可以观察到,dimo.txt在文本-图像检索任务上的性能低于SigLIP [93] 等竞争对手。这可能是由于我们训练的文本编码器质量不令人满意,这反过来是冻结视觉编码器的结果,如第4.5节后面讨论的那样。然而,我们接下来看到dimo.txt在开放词汇分割任务上大大优于SigLIP。

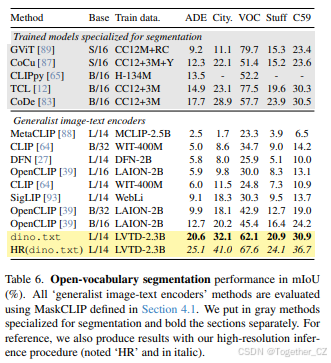
开放词汇分割。在分割方面,我们的方法大大优于替代方案,如表6所示,并且与专门模型相当或更好,无需任何工程改进:我们简单地将分类模型应用于局部特征。我们注意到,与其他方法相比,VOC20上的性能趋势较低,而在其他数据集上较高,我们将其归因于领域差距,因为VOC20经常只包含一个近距离居中的对象。我们在附录中消融了使用我们提出的表示与MaskCLIP的影响。我们还展示了我们高分辨率策略的结果质量,如图4所示。
训练效率。我们在图1中展示了在IN1K验证集上,随着训练GFLOP的增加,dimo.txt和CLIP的零样本分类性能如何演变,两者在相同的LVTD-2.3B数据集上训练。在128个A100 GPU上,19小时的训练足以达到81.4%的IN1K准确率。相比之下,CLIP需要110小时才能达到79.0%。此外,将CLIP训练限制为匹配我们最佳性能模型的GFLOP预算仅达到73%的准确率,比我们的模型低8.4%。
5 结论
我们提出了一种名为dino.txt的训练配方,它将文本编码器从头对齐到冻结的自监督视觉模型,特别是DINOv2 [18, 60],解锁了开放词汇能力。该方法包括一种无需人工注释的自监督数据筛选技术,并允许快速训练,从而在零样本分类中取得了与最先进技术相当的性能。生成的文本编码器还与patch级特征对齐,因此得益于冻结视觉编码器的质量,提供了精确的密集开放词汇分割能力。我们还认为,经典的语义分割基准需要重新思考开放词汇,因为它们不允许重叠概念,也不允许比注释更细粒度的预测。



















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











