






这篇文章提出了一种新型的卷积操作——线性可变形卷积(LDConv),旨在解决传统卷积操作在采样形状和参数数量上的局限性。主要内容总结如下:
-
问题背景:
-
传统卷积操作(如标准卷积和可变形卷积)存在采样形状固定、参数数量呈平方增长等问题,限制了卷积神经网络(CNN)的灵活性和性能。
-
可变形卷积虽然通过偏移量调整采样形状,但其参数数量仍然呈平方增长,且未探索不同初始采样形状对网络性能的影响。
-
-
LDConv的核心思想:
-
LDConv通过引入线性增长的参数数量和任意采样形状,提供了更灵活的卷积操作。
-
提出了一种坐标生成算法,为任意大小的卷积核生成初始采样位置,并通过偏移量动态调整采样形状,以适应目标的变化。
-
LDConv可以替代标准卷积操作,显著提升网络性能,同时减少计算开销和参数数量。
-
-
主要贡献:
-
提出了一种新的卷积操作,允许卷积核具有任意数量的参数和任意采样形状。
-
通过实验验证了LDConv在目标检测任务中的优越性,特别是在COCO2017、VOC 7+12和VisDrone-DET2021等数据集上表现突出。
-
LDConv可以轻松集成到现有的卷积模块(如FasterBlock和GSBottleneck)中,进一步提升网络性能。
-
-
实验结果:
-
在多个目标检测数据集上的实验表明,LDConv能够显著提高检测精度,尤其是在大目标检测任务中表现更为突出。
-
与可变形卷积和其他新型卷积操作相比,LDConv在参数数量和计算开销上具有明显优势。
-
-
未来工作:
-
进一步优化LDConv的计算效率,减少内存访问时间。
-
探索LDConv在更多特定任务中的应用,如医学图像分析、自动驾驶等。
-
LDConv通过引入线性增长的参数数量和任意采样形状,提供了一种灵活且高效的卷积操作,能够显著提升卷积神经网络的性能,并为未来的研究提供了新的方向。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:
摘要
基于卷积操作的神经网络在深度学习领域取得了显著成果,但标准卷积操作存在两个固有缺陷。一方面,卷积操作局限于局部窗口,无法捕捉其他位置的信息,且其采样形状是固定的。另一方面,卷积核的大小固定为 k×k,即固定的方形形状,且参数数量随尺寸呈平方增长。尽管可变形卷积(Deformable Conv)解决了标准卷积固定采样的问题,但其参数数量也呈平方增长,且未探索不同初始采样形状对网络性能的影响。针对上述问题,本文提出了线性可变形卷积(LDConv),它赋予卷积核任意数量的参数和任意采样形状,为网络开销与性能之间的权衡提供了更丰富的选择。LDConv定义了一种新的坐标生成算法,为任意大小的卷积核生成不同的初始采样位置。为了适应目标的变化,引入了偏移量来调整每个位置的采样形状。LDConv将标准卷积和可变形卷积的参数增长趋势修正为线性增长。与可变形卷积相比,LDConv提供了更丰富的选择,并且当LDConv的参数数量设置为K的平方时,LDConv可以等价于可变形卷积。不同的是,本文还探讨了使用相同大小但不同初始采样形状的LDConv对神经网络的影响。LDConv通过不规则的卷积操作完成了高效特征提取的过程,并为卷积采样形状带来了更多的探索选项。在COCO2017、VOC 7+12和VisDrone-DET2021等代表性数据集上的目标检测实验充分证明了LDConv的优势。LDConv是一种即插即用的卷积操作,可以替代卷积操作以提高网络性能。
1. 引言
卷积神经网络(CNNs),如ResNet [1]、DenseNet [2]和YOLO [3],在各种应用中表现出色,并引领了现代社会的技术进步。从自动驾驶汽车中的图像识别 [4] 和医学图像分析 [5],到智能监控 [6] 和个性化推荐系统 [7],这些成功的网络严重依赖于卷积操作,卷积操作能够高效地提取图像中的局部特征并确保模型的复杂性。
尽管CNN在分类 [8]、目标检测 [9]、语义分割 [10] 等方面取得了许多成功,但它们仍存在一些局限性。其中最显著的局限性之一是卷积采样形状和大小的选择。标准卷积操作通常依赖于具有固定采样位置的方形卷积核,如 1×1、3×3、5×5 和 7×7 等。传统卷积核的采样位置不可变形,无法动态响应各种目标的变化。可变形卷积 [11; 12] 通过使用偏移量灵活调整卷积核的采样形状,从而适应目标的变化,提升了网络性能。例如,在 [13; 14; 15] 中,这些工作利用可变形卷积来对齐特征。Zhao等人 [16] 通过将其添加到YOLOv4 [17] 中,提升了死鱼检测的性能。Yang等人 [18] 通过将其引入YOLOv8 [19] 的骨干网络,改进了牛只检测的性能。Li等人 [20] 将可变形卷积引入深度图像压缩任务 [21; 22],以获得内容自适应的感受野。尽管上述研究展示了可变形卷积的优越性,但它仍然不够灵活。可变形卷积只能定义 k×k 的卷积操作来提取特征,即参数数量为1, 4, 9, 16, 25等。实际上,可变形卷积需要通过坐标对特征进行重采样,然后通过常规卷积操作提取特征。因此,可变形卷积的参数数量呈平方增长,这使得重采样和卷积特征提取过程的计算和内存开销难以调节。在处理图像时,我们可能需要应用更大尺寸的可变形卷积来提取信息。例如,将 5×5 的可变形卷积调整为较大的 6×6 卷积核,即参数数量从25直接变为36。这种突变可能导致设备内存不足。因此,可变形卷积参数数量的平方增长趋势在设置卷积大小时缺乏灵活性,并且在硬件环境中不够友好,忽略了参数数量为3, 5, 7, 8, 10, 11, 12等的卷积操作。此外,可变形卷积未探索不同初始采样形状对网络的影响。
针对上述问题,我们提出了灵活的线性可变形卷积(LDConv),它能够灵活调整卷积核参数数量的大小,以适应目标形状的变化。与标准的规则卷积不同,LDConv是一种新型卷积操作,它可以使用任意数量的参数(如1, 2, 3, 4, 5, 6, 7等)来提取特征,而标准卷积或可变形卷积无法实现这一点。LDConv可以轻松地替换网络中的标准卷积操作,以提高网络性能。重要的是,LDConv允许卷积参数数量呈线性增长或减少,这对硬件环境非常有利,并且可以作为轻量级模型的替代方案,以减少参数数量和计算开销。其次,当资源充足时,它提供了更多选择来增强网络的性能。规则卷积核使参数数量呈平方增长趋势,而LDConv仅呈线性增长趋势,并为卷积核提供了更多选择。此外,其思想可以扩展到特定领域,因为可以根据先验知识为卷积操作创建特殊的采样形状,然后通过偏移量动态自动适应目标形状的变化。同时,LDConv可以轻松地添加到一些新型卷积模块中,以增强其性能,如FasterBlock [23] 和GSBottleneck [24]。在VOC [25]、COCO2017 [26]、VisDrone-DET2021 [27] 等代表性数据集上的目标检测实验充分证明了LDConv的优势。总之,我们的贡献如下:
-
针对不同大小的卷积核,提出了一种算法,为任意大小的卷积核生成初始采样坐标。
-
为了适应目标的不同变化,通过获得的偏移量调整不规则卷积核的采样位置。同时,还探索了三种方法来提取与不规则卷积核对应的特征。
-
与规则卷积核相比,LDConv实现了不规则卷积核提取特征的功能,为各种变化的目标提供了任意采样形状和大小的卷积核,弥补了规则卷积的不足。
-
使用相应大小的LDConv替换FasterBlock和GSBottleneck中的卷积操作,以提高这两个模块的性能。
2. 相关工作
近年来,许多工作从不同角度考虑和分析标准卷积操作,并设计了新型卷积操作以提高网络性能。
Li等人 [28] 认为卷积核在所有空间位置共享参数,这导致不同空间位置的建模能力有限,无法有效捕捉空间长距离关系。其次,为每个输出通道使用不同的卷积核的方法实际上并不高效。因此,为了解决这些缺点,他们提出了Involution算子,通过反转卷积操作的特征来提高网络性能。Qi等人 [29] 提出了基于可变形卷积的DSConv。可变形卷积中通过学习获得的偏移量是自由的,这导致模型丢失了一小部分精细结构特征。这对分割细长管状结构的任务提出了巨大挑战,因此他们提出了DSConv。Zhang等人 [30] 从新的角度理解空间注意力机制,他们认为空间注意力机制本质上解决了卷积操作的参数共享问题。然而,一些空间注意力机制,如CBAM [31] 和CA [32],并未完全解决大尺寸卷积参数共享的问题。因此,他们提出了RFAConv。Chen等人 [33] 提出了动态卷积(Dynamic Conv)。与每层使用一个卷积核不同,动态卷积基于注意力动态聚合多个并行的卷积核。动态卷积提供了更大的特征表示能力。Tan等人 [34] 认为卷积核大小在CNN中经常被忽视,这可能会影响网络的准确性和效率。其次,仅使用逐层卷积并未充分利用卷积网络的潜力。因此,他们提出了MixConv,它自然地在单个卷积中混合多个卷积核大小,以提高网络的性能。
为了克服传统序列数据处理的局限性,Romero等人 [36] 提出了CKConv,它将卷积核视为连续函数而不是一系列独立的权重,从而克服了CNN的缺点。CKConv可以在单次操作中定义任意大的内存范围,独立于网络深度、扩展因子或网络大小。在设计卷积神经网络时,选择合适的卷积核大小对模型性能至关重要。传统方法需要在训练前固定卷积核大小,但在训练过程中动态学习卷积核大小有助于提高网络性能。因此,Romero等人 [37] 提出了FlexConv,它能够在训练过程中学习高带宽的变大小卷积核,同时保持参数数量不变。在CNN中,可以通过增加卷积核的大小来扩展感受野。然而,可训练参数的数量在2D情况下随卷积核大小的平方增长,迅速变得不可行,且训练非常困难。因此,为了在卷积神经网络中使用大感受野并避免参数数量和计算成本,Hassani等人 [38] 提出了DCLS方法,通过控制两个超参数(卷积核数量和扩展卷积核的大小),可以在保持参数数量不变的情况下实现更大的感受野。CNN网络中卷积核大小的设置受到限制,通常需要预先设置卷积核大小,这使得超参数调优变得繁琐。因此,Pintea等人 [39] 提出了N-JetNet,它利用尺度空间理论获得卷积核的自相似参数化。
尽管这些方法提高了卷积操作的性能,但一些工作仍局限于规则卷积操作,不允许卷积采样形状的多种变化。其他工作允许灵活调整卷积核大小,但网络获得的性能仍然不够理想。相比之下,我们提出的LDConv可以使用任意数量的参数和采样形状的卷积核高效提取特征,以实现网络的良好性能。
3. 方法
3.1 定义初始采样位置
基于卷积操作的卷积神经网络通过规则的采样网格在相应位置定位特征。在 [11, 35, 40] 中,给出了 3×3 卷积操作的规则采样网格。设 R 表示采样网格,则 R 表示如下:
R={(−1,−1),(−1,0),...,(0,1),(1,1)}
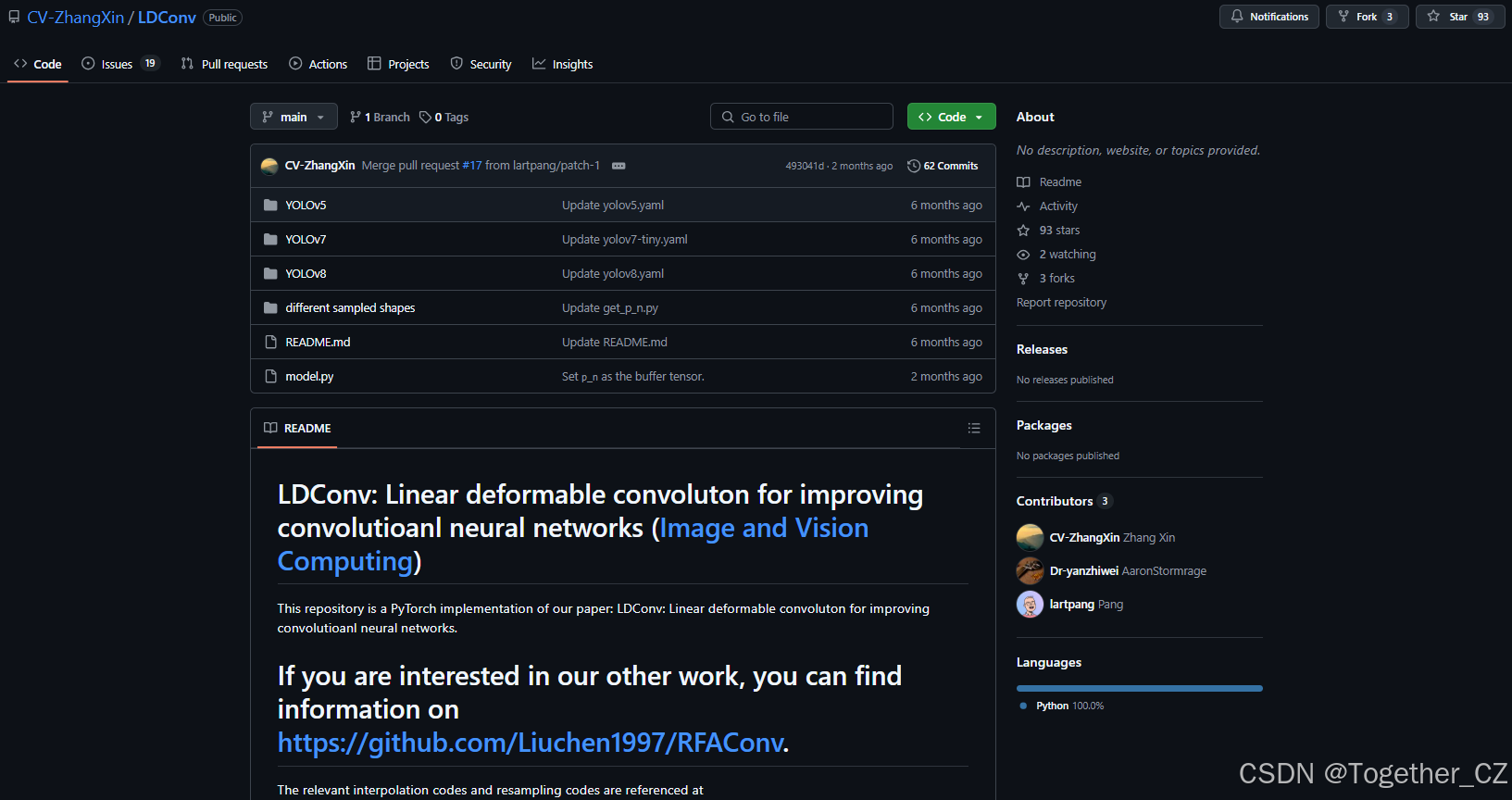
然而,由于可变形卷积和这些工作中定义的采样坐标是规则的,无法通过不规则卷积高效提取特征。而LDConv针对不规则形状的卷积核。因此,为了允许不规则卷积核具有采样网格,我们为任意大小的卷积创建了一种算法,生成卷积核的初始采样坐标 Pn。首先生成规则的采样网格,然后为剩余的采样点创建不规则的采样网格,最后将它们拼接在一起形成整体采样网格。伪代码如下:
# func get_p_n(num_param, dtype)
# num_param: the kernel size of LDConv
# dtype: the type of data如图1所示,生成了任意大小卷积的初始采样坐标。这些具有不同参数数量的卷积核的初始采样形状的设置需要考虑两个方面。首先,不同的初始采样形状在相同大小的情况下会影响网络的性能,而近似方形的形状有助于偏移学习,如第4.5节的探索性实验所示。其次,为了方便生成任意大小的卷积核。因此,图1中的采样形状考虑了上述两点,为任意大小的卷积生成相应的初始采样形状。规则卷积的采样网格将中心作为原点 (0,0),而大多数不规则卷积不以中心为原点。为了适应所使用的卷积大小,算法中将左上角的点设置为采样原点 (0,0)。

3.2 线性可变形卷积
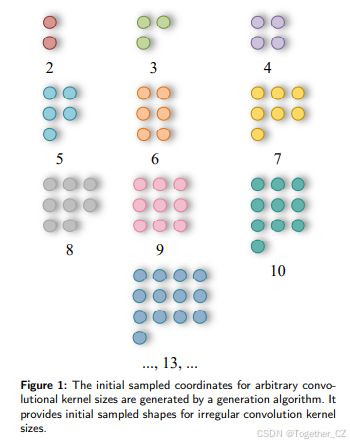
显然,标准卷积的采样位置是固定的,这导致卷积只能提取局部信息,无法捕捉其他位置的信息。可变形卷积(Deformable Conv)通过学习偏移量来调整初始规则模式的采样网格,从而在一定程度上弥补了卷积操作的不足。然而,标准卷积和可变形卷积的采样网格是规则的,不允许卷积核具有任意数量的参数。此外,随着卷积核大小的增加,参数数量呈平方增长,这对硬件环境并不友好。因此,我们提出了一种新型的线性可变形卷积(LDConv)。如图2所示,LDConv的整体结构展示了其工作原理。LDConv的特征提取过程可以分为三个步骤。
以图2中的N=5为例。首先,基于N的大小,通过提出的算法1生成初始采样形状(Pn)。然后,获得原始坐标(![]() )。这一步的重点是为具有N个参数的卷积核生成特征图上的相应采样坐标。其次,通过卷积操作获得相应卷积核的偏移量,偏移量的维度为(B, 2N, H, W),然后将偏移量添加到原始坐标中,生成卷积对应的新采样坐标。这一步的重点是为特征图中不同位置的卷积生成不同的采样形状。最后,通过插值和重采样获得相应位置的特征,然后应用相应的卷积操作来提取特征。这一步主要是提取相应位置的特征。通过上述三个步骤,LDConv可以完成任意大小的卷积操作以提取特征。
)。这一步的重点是为具有N个参数的卷积核生成特征图上的相应采样坐标。其次,通过卷积操作获得相应卷积核的偏移量,偏移量的维度为(B, 2N, H, W),然后将偏移量添加到原始坐标中,生成卷积对应的新采样坐标。这一步的重点是为特征图中不同位置的卷积生成不同的采样形状。最后,通过插值和重采样获得相应位置的特征,然后应用相应的卷积操作来提取特征。这一步主要是提取相应位置的特征。通过上述三个步骤,LDConv可以完成任意大小的卷积操作以提取特征。
LDConv和可变形卷积的共同点是,两者都通过偏移量调整初始采样形状。它们的不同之处在于,LDConv通过提出的算法生成初始采样坐标,从而完成了具有任意数量参数的特征提取过程。这一点非常重要,因为它将可变形卷积参数数量的增长趋势修正为线性增长。这为调节网络的参数数量、计算开销以及设备内存消耗提供了灵活性。此外,可变形卷积的最后一步无法提取与不规则卷积对应的特征。
相反,我们在设计LDConv时探索了三种方法,如图3所示。重采样特征可以转换为四维(C, N, H, W),然后使用步长为(N, 1, 1)的Conv3d来提取特征。如图3(a)所示。重采样特征也可以在通道维度上堆叠(C × N, H, W),然后使用1×1卷积操作将维度减少到(C, H, W)。如图3(b)所示。在可变形卷积[11]和RFAConv[30]中,它们在空间维度上堆叠3×3卷积特征,然后使用步长为3的卷积操作来提取特征。然而,这种方法针对的是方形采样形状,即卷积核为方形,如1×1、2×2、3×3等。因此,这些方法无法实现不规则的卷积操作。而通过将重采样特征在行或列上堆叠,可以使用列卷积或行卷积来提取与不规则采样形状对应的特征。特征通过适当大小和步长的卷积核进行提取。如图3(c)所示。上述方法可以提取与不规则采样形状对应的特征。只需对特征进行重塑并使用相应的卷积操作即可。因此,在图2中,最后的“Reshape”和“Conv”代表了上述任何一种方法。此外,为了清楚地展示LDConv的过程,在图2中重采样后,我们将卷积大小对应的特征维度放在第三维,但在代码实现时,它位于最后一维。
LDConv可以完美地完成不规则卷积特征提取过程,并且可以根据偏移量灵活调整采样形状,为卷积采样形状带来更多的探索选项。与标准卷积和可变形卷积相比,LDConv更加通用,因为标准卷积和可变形卷积受限于规则卷积核的思想。
3.3 扩展的LDConv
我们认为LDConv的设计具有创新性,能够实现具有不规则和任意采样形状的卷积核特征提取。即使不使用可变形卷积中的偏移量思想,LDConv仍然可以生成多种卷积核形状。因为LDConv可以通过重采样初始坐标来呈现多种变化,如图4所示,我们为大小为5的卷积设计了多种初始采样形状。在图4中,我们仅展示了一些大小为5的示例。然而,LDConv的大小可以是任意的,因此随着大小的增加,LDConv的初始卷积采样形状变得更加丰富,甚至无限。鉴于目标形状在不同数据集中有所不同,设计与采样形状对应的卷积操作至关重要。LDConv通过根据特定领域设计相应形状的卷积操作,完全实现了这一点。它还可以通过添加可学习的偏移量来动态适应目标的变化,类似于可变形卷积。对于特定任务,卷积核初始采样位置的设计非常重要,因为它是先验知识。正如Qi等人[29]所提出的,他们为细长管状结构分割任务设计了相应形状的采样坐标,但他们的形状选择仅针对细长管状结构。
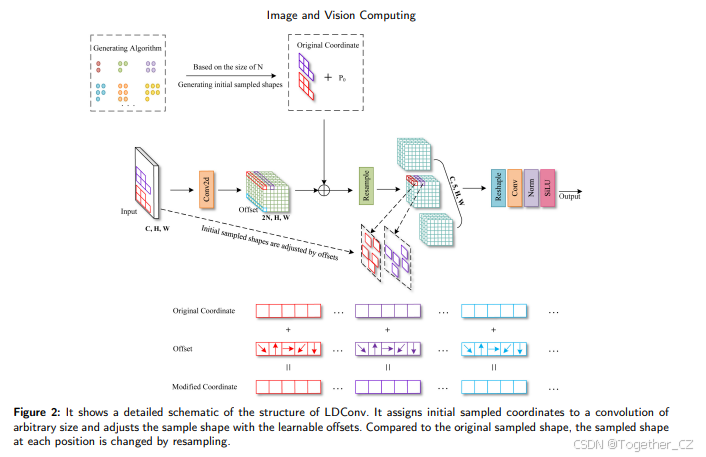
图2:展示了LDConv结构的详细示意图。它为任意大小的卷积分配初始采样坐标,并通过可学习的偏移量调整采样形状。与原始采样形状相比,每个位置的采样形状通过重采样发生了变化。
LDConv真正实现了具有任意数量的任意形状的卷积核操作过程,并且可以使卷积核呈现多种形状。可变形卷积[11]旨在弥补规则卷积的不足,而DSConv[29]则是为特定目标形状设计的。它们没有探索任意大小的卷积和任意采样形状的卷积。LDConv的设计通过允许卷积操作通过偏移量高效提取不规则采样形状的特征,弥补了这些问题。LDConv允许卷积具有任意数量的卷积参数,并且允许卷积呈现多种形状。
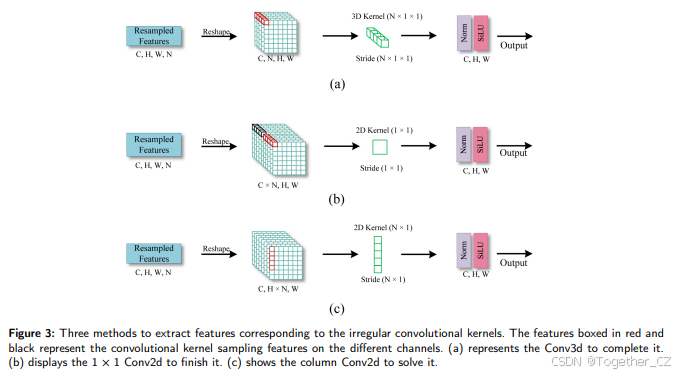
图3:展示了三种提取与不规则卷积核对应特征的方法。红色和黑色框中的特征表示不同通道上的卷积核采样特征。(a) 表示使用Conv3d来完成特征提取。(b) 展示了使用1×1 Conv2d来完成特征提取。(c) 展示了使用列Conv2d来解决特征提取问题。
此外,LDConv作为一种灵活的卷积操作,可以轻松替换一些高效模块中的卷积操作,以提高网络性能,例如FasterBlock[23]和GSBottleneck[24]。因此,我们提出了改进的FasterBlock和改进的GSBottleneck,如图5和图6所示。在FasterBlock中,首先使用PConv提取特征,然后使用两个1×1卷积操作构建Bottleneck。因此,使用LDConv(N=2)替换它们,并确保参数数量不变。在GSBottleneck中,使用LDConv(N=5)替换3×3卷积操作,以提高性能并减少参数数量和计算开销。
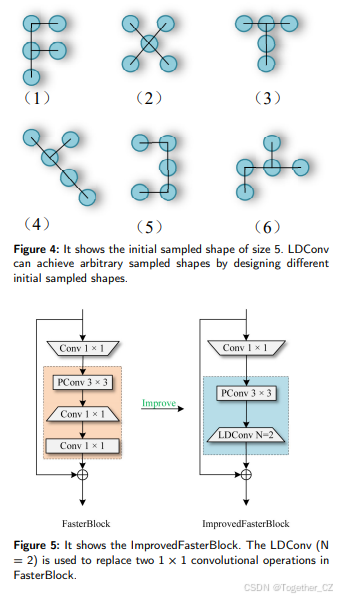
4. 实验
为了验证LDConv的优势,我们基于先进的YOLOv5 [41]、YOLOv7 [42] 和YOLOv8 [19] 进行了丰富的目标检测实验。首先,YOLO系列算法作为目标检测领域的代表性算法,已广泛应用于各个领域,并获得了良好的检测性能。其次,YOLO系列算法的网络结构相比其他网络结构更为简单,这便于我们在不同数据集上进行大量实验,以展示LDConv的优势。所有实验模型均基于RTX3090进行训练。为了验证LDConv的优势,我们在COCO2017、VOC 7+12和VisDrone-DET2021等代表性数据集上进行了相关实验。
4.1 COCO2017上的目标检测实验
COCO2017数据集包含训练集(118287张图像)、验证集(5000张图像),涵盖80个物体类别。它已成为计算机视觉研究领域,尤其是目标检测领域的标准数据集。我们选择最先进的YOLOv5n和YOLOv5s检测器作为基线模型。然后,使用不同大小的LDConv替换YOLOv5n和YOLOv5s中的卷积操作。替换细节与[30]中的目标检测实验相同。在实验中,除了epoch和batch-size参数外,使用网络的默认参数。基于batch size为32,我们训练每个模型300个epoch。根据之前的工作,我们报告了![]() 、
、![]() 、AP、
、AP、![]() 、
、![]() 。
。
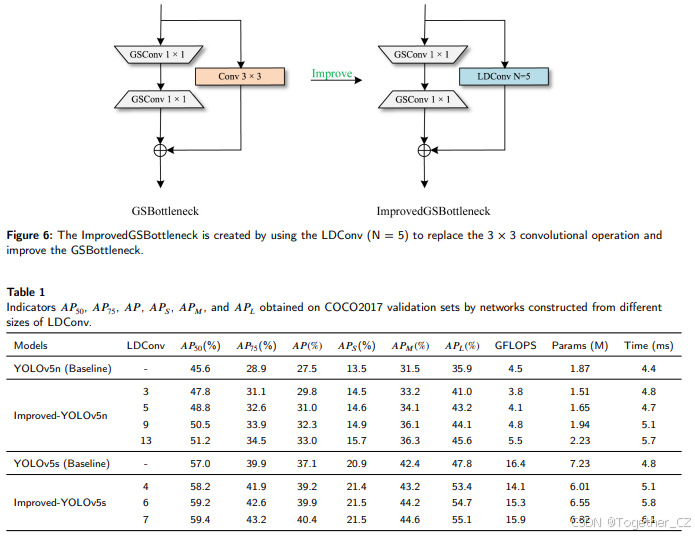
此外,我们还报告了YOLOv5n和YOLOv5s在使用大小为5、4、6、7、9和13的LDConv时的目标检测结果。如表1所示,随着卷积核大小的增加,YOLOv5的检测精度逐渐提高,同时模型所需的参数数量和计算开销也逐渐增加。表1中的时间表示处理一张图像所需的时间,单位为毫秒(ms)。与标准卷积操作相比,LDConv显著提高了YOLOv5在COCO2017上的目标检测性能。可以看出,当LDConv的大小为5时,它不仅减少了模型所需的参数数量和计算开销,还显著提高了YOLOv5n的检测精度。其![]() 和AP均提高了三个百分点,表现突出。LDConv提高了基线模型的
和AP均提高了三个百分点,表现突出。LDConv提高了基线模型的![]() ,但明显的是,LDConv相比中小物体显著提高了大物体的检测精度。我们认为,LDConv通过偏移量更好地适应了大物体的形状。
,但明显的是,LDConv相比中小物体显著提高了大物体的检测精度。我们认为,LDConv通过偏移量更好地适应了大物体的形状。
4.2 VOC 7+12上的目标检测实验
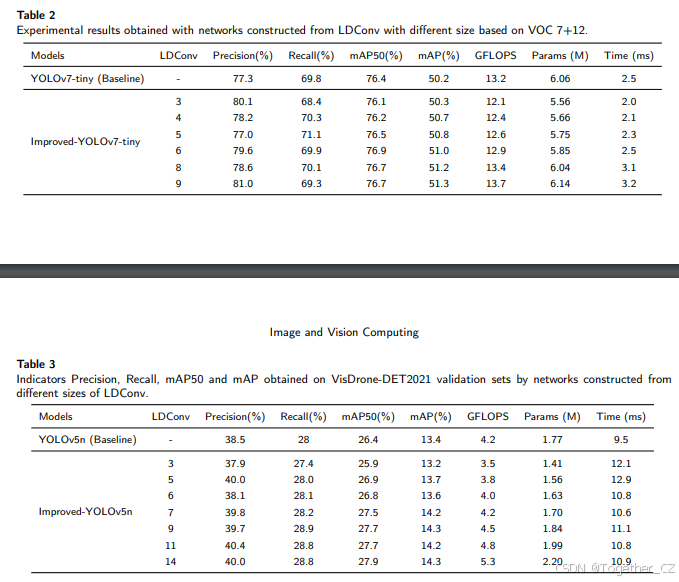
为了进一步验证我们的方法,我们在VOC 7+12数据集上进行了实验,该数据集是VOC2007和VOC2012的组合,包含16551张训练图像和4952张验证图像,涵盖20个物体类别。为了测试LDConv在不同架构中的泛化能力,我们选择了YOLOv7-tiny作为基线模型。由于YOLOv7和YOLOv5是具有不同架构的系统,因此可以比较LDConv在不同架构设置下的性能。在YOLOv7-tiny中,我们使用不同大小的LDConv替换标准卷积操作。替换细节遵循[30]中的工作。所有模型的超参数设置与前一节一致。根据之前的工作,我们报告了mAP50和mAP。如表2所示,随着LDConv大小的增加,网络的检测精度逐渐提高,同时模型的参数数量和计算需求也逐渐增加。这些实验进一步证实了LDConv的优势。
4.3 VisDrone-DET2021上的目标检测实验
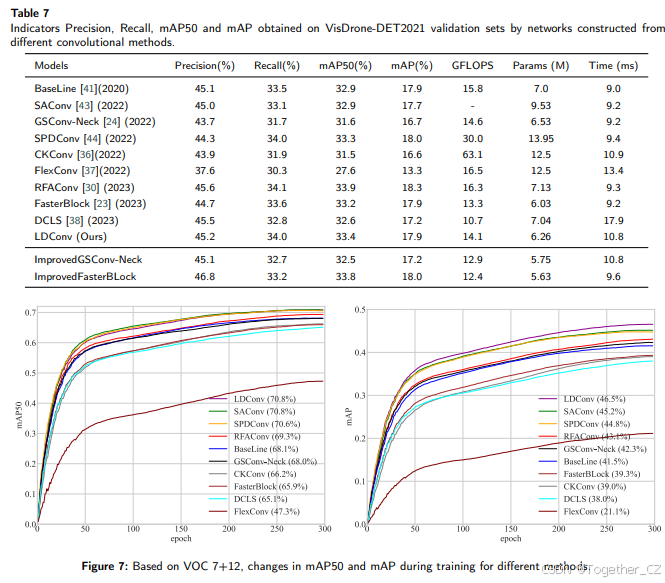
为了再次验证LDConv具有较强的泛化能力,基于VisDrone-DET2021数据,我们进行了相关的目标检测实验。VisDrone-DET2021是一个具有挑战性的数据集,由无人机在不同环境、天气和光照条件下拍摄。它是中国覆盖范围最广的无人机航拍数据集之一。训练集包含6471张图像,验证集包含548张图像。与第4.1节一样,我们选择YOLOv5n作为基线模型,使用LDConv替换网络中的卷积操作。在实验中,batch size设置为16,以便探索更大的卷积大小,其他所有超参数设置与之前相同。与前一节一样,我们分别报告了mAP50和mAP。如表3所示,可以清楚地看到,基于不同大小的LDConv可以作为轻量级选项,减少参数数量和计算开销,并提高网络性能。在实验中,当LDConv的大小设置为3时,模型的检测性能相比基线模型有所下降,但相应的参数数量和计算开销要小得多。此外,我们可以逐步调整LDConv的大小,以探索网络性能的变化。LDConv为网络带来了更丰富的选择。
4.4 对比实验
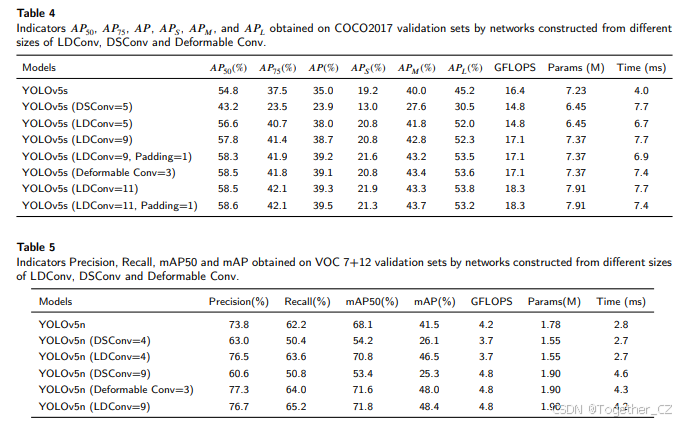
与可变形卷积[11]不同,LDConv为网络提供了更丰富的选择,并弥补了可变形卷积的不足,后者仅使用规则卷积操作,而LDConv可以使用规则和不规则卷积操作。当LDConv的大小设置为K的平方时,它就变成了可变形卷积。此外,DSConv[29]也使用偏移量来调整采样形状,但其采样形状是为管状目标设计的,采样形状的变化有限。为了对比LDConv、可变形卷积和DSConv在相同大小下的优势,我们在COCO2017上基于YOLOv5s进行了实验。如表4所示,当卷积核参数数量为9(即标准的3×3卷积)时,LDConv和可变形卷积的性能相同。因为当卷积核大小为规则时,LDConv等价于可变形卷积。但我们提到,可变形卷积没有探索不规则卷积核大小。因此,无法实现参数数量为5或11的卷积操作。在LDConv的设计中,我们没有对输入特征进行零填充。然而,可变形卷积中使用了填充。为了公平比较,我们在LDConv中也对输入特征使用了零填充。实验表明,LDConv中的零填充有助于提高网络性能。
此外,基于VOC 7+12,我们选择了YOLOv5n来比较LDConv、DSConv和可变形卷积。在使用可变形卷积时,取消了零填充,以便与LDConv进行公平比较。如表5所示,可以看出LDConv取得了更好的性能。理论上,当可变形卷积的大小为3时,其性能应与LDConv(N=9)相当。然而,可变形卷积从索引=1开始采样,而不是0,因此丢失了一些信息。由于DSConv是为特定管状形状设计的,可以看出其在COCO2017和VOC 7+12上的检测性能并不明显。
在实现DSConv时,Qi等人[29]扩展了行或列的特征,最后使用行或列卷积来提取特征,这与我们的方法类似。因此,他们的方法也可以实现参数数量为2、3、4、5、6、7等的卷积操作。在相同大小下,我们也进行了对比实验。因为DSConv没有完成下采样方法,在实验中,我们使用LDConv和DSConv替换YOLOv5n中C3模块的3×3卷积。实验结果如表4和表5所示。LDConv优于DSConv,因为DSConv并非旨在提高任意大小卷积核的性能,而是针对特定形状的目标进行探索。相比之下,LDConv提供了更丰富的卷积核选择和探索,能够有效提高网络性能。
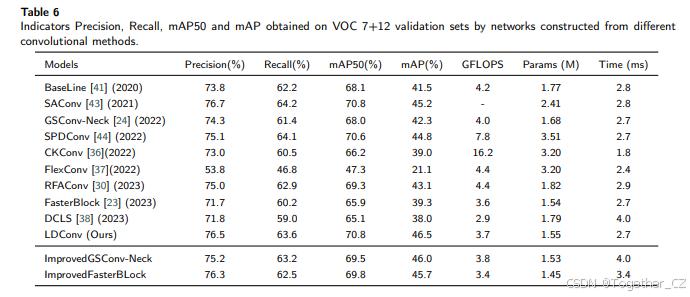
此外,为了突出LDConv的优势,我们还与其他新型卷积方法进行了比较,如SAConv[43]、SPDConv[44]、RFAConv[30]、FasterBlock[23]、GSConv-Neck[24]以及相关的工作CKConv[36]、FlexConv[37]和DCLS[38]。基于YOLOv5n和YOLOv5s,我们分别在VOC 7+12和VisDrone-DET2021数据集上进行了实验。同时,我们还使用由ImprovedGSBottleneck构建的ImprovedFasterBlock和ImprovedGSConv-Neck进行了实验。所有实验基于batch size为16和epoch为300进行。在实验中,Bottleneck中的3×3卷积操作分别被LDConv、SAConv、FasterBlock、CKConv、FlexConv和DCLS替换。根据[24, 30, 44]的工作,下采样卷积被RFAConv和SPDConv替换,C3模块被GSConv-Neck替换。
如表6和表7所示,可以看出使用LDConv的网络取得了良好的性能。在表7中,与LDConv相比,RFAConv在VisDrone-DET2021上取得了更好的性能,这是一个包含无人机拍摄图像的具有挑战性的数据集。然而,无人机拍摄的图像通常包含复杂的背景。RFAConv为每个采样位置的卷积核分配不同的注意力权重,使得卷积在从无人机拍摄的图像中提取特征时能够更好地区分背景信息。相比之下,LDConv没有灵活的注意力权重来区分背景信息。此外,CKConv和FlexConv作为一种灵活的卷积操作,可以类似地设置任意大小的内存范围,但其实现需要大量的计算,并且网络性能较差。我们在实验中将CKConv的超参数horizon设置为1、3和5。当horizon为1时,网络性能较差,而当horizon设置为3时,网络性能相比horizon为1时有所提高,但代价是大量的计算开销。当horizon为5时,网络性能并没有显著提高,但计算开销急剧增加。因此,在我们的实验中,我们将CKConv的horizon设置为3。FlexConv基于CKConv,因此为了保持一致性,我们在实验中也将其horizon设置为3。DCLS通过参考相应的代码库设置替换了标准的3×3卷积操作。
为了清楚地观察所有网络在训练过程中mAP50和mAP的变化,我们基于VOC 7+12和VisDrone-DET2021可视化了它们的变化。如图7和图8所示。与这些最先进的方法相比,LDConv能够灵活调整卷积参数的数量和采样形状,以权衡网络的开销并适应目标的变化,因此通过将LDConv添加到网络中,获得了良好的性能。
4.5 探索初始采样形状
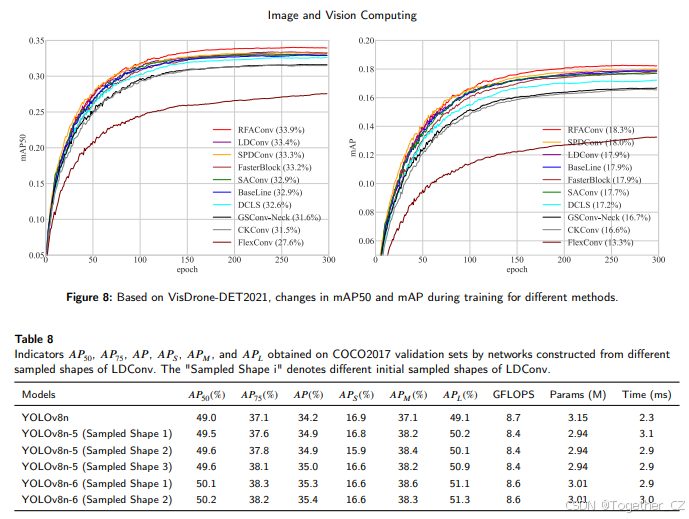
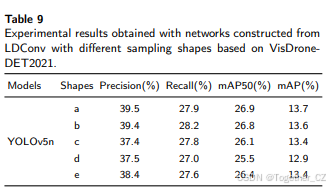
如前所述,LDConv可以通过使用任意大小和任意采样形状来提取特征。为了探索不同初始采样形状的LDConv对网络的影响,我们分别在COCO2017和VisDrone-DET2021上进行了实验。在COCO2017上,我们基于batch size为32和epoch为100进行了实验。在VisDrone-DET2021上,我们基于batch size为16和epoch为300进行了实验。所有其他超参数均为网络默认值。在COCO2017中,我们选择YOLOv8n进行实验。如表8所示,LDConv仍然可以提高网络的检测精度。YOLOv8和YOLOv5的网络结构相似。主要区别之一是C3和C2f的设计。可以看出,YOLOv8中添加LDConv所带来的性能提升不如YOLOv5显著。我们认为,YOLOv8在相同大小下需要比YOLOv5更多的参数,因此更多的参数可以提供更好的特征信息,正如LDConv所做的那样。因此,添加LDConv后,YOLOv8的提升不如YOLOv5显著。此外,在相同大小下,我们在COCO2017中测试了不同初始采样形状对网络性能的影响。显然,在不同初始采样下,网络获得的检测精度波动不大。这得益于COCO2017的大量数据可以灵活调整偏移量。但这并不意味着网络在所有初始采样坐标下获得的检测精度没有显著差异。为了再次探索不同初始采样形状的LDConv对网络的影响,我们在VisDrone-DET2021上基于YOLOv5n进行了大小为5且具有不同初始采样的LDConv实验。如表9所示,可以看出,网络在不同初始采样下获得了不同的检测精度。因此,不同初始采样形状的LDConv对网络性能有影响。此外,对于特定的网络和数据集,探索具有适当初始采样形状的LDConv以提高网络性能非常重要。
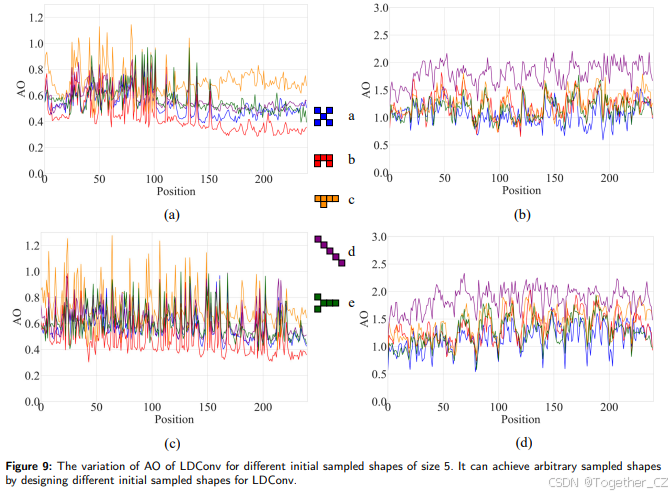
5. 分析与讨论
在之前的实验中,我们使用不同初始采样形状的LDConv(大小为5)来评估YOLOv5n的性能。可以清楚地注意到,网络在不同初始采样形状下的表现有所不同。这表明偏移量的调整能力也是有限的。为了衡量每个给定位置的偏移量变化,我们定义了平均偏移量(Average Offset),其定义如下:
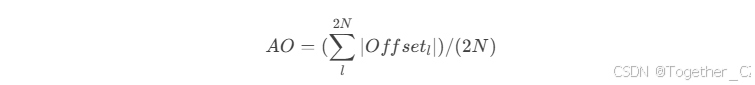
平均偏移量(AO)通过对偏移量求和,然后取平均值来衡量每个位置采样点的平均变化程度。为了观察偏移量的变化,我们选择了训练好的网络,并选择LDConv的最后一层来分析偏移量的整体变化趋势。为了进行分析,我们在VisDrone-DET2021中随机选择了四张图像,然后可视化大小为5的LDConv,该LDConv初始为不同的采样位置。如图9所示,我们可视化了每个采样位置的偏移量AO的变化程度。图9中的不同颜色表示训练后不同初始采样形状在每个采样位置的偏移量变化。线条的颜色对应于中间的初始采样形状。图9中的不同初始采样形状对应于表9中的初始采样形状。可以得出结论,图9中蓝色和红色初始采样形状的AO变化较小。这意味着红色和蓝色的初始采样形状比其他初始采样形状更适合该数据集。如表9中的实验所示,蓝色和红色对应的初始采样形状获得了更好的检测精度。所有实验证明,LDConv能够显著提升网络性能。与可变形卷积不同,LDConv能够根据大小灵活调整网络性能。在所有实验中,我们广泛探索了大小为5的LDConv。因为在训练COCO2017这样的大数据集时,我们发现当LDConv的大小设置为5时,训练速度与原始模型相差不大。此外,随着LDConv大小的增加,训练时间逐渐增加。在COCO2017、VOC 7+12和VisDrone-DET2021的实验中,大小为5的LDConv为网络带来了良好的效果。当然,LDConv在其他大小上的探索也是可行的,因为参数数量的线性增长和任意采样形状为LDConv的探索提供了丰富的选择。LDConv可以实现任意大小和任意采样的卷积操作,并通过偏移量自动调整采样形状以适应目标变化。所有实验表明,LDConv提高了网络性能,并为网络开销与性能之间的权衡提供了更丰富的选择。此外,尽管LDConv提高了模型的检测精度,但在训练过程中牺牲了一些检测速度。原因是LDConv在访问内存时花费了太多时间,因此在未来,我们将设计适当的操作符以减少内存访问时间,从而提高LDConv的速度。
6. 结论
显然,在现实生活以及计算机视觉领域,物体的形状表现出各种变化。卷积操作的固定采样形状无法适应这种变化。尽管可变形卷积可以通过偏移量灵活调整卷积的采样形状,但它仍然存在局限性。因此,本文提出了LDConv,它真正实现了卷积具有任意采样形状和大小的功能,为卷积核的选择提供了多样性。此外,本文还探索了不同的初始采样形状,并改进了FasterBlock和GSBottleneck。尽管我们在本文中仅为大小为5的LDConv设计了多种采样坐标形状,但LDConv的灵活性在于它可以针对任意大小的采样核来提取信息。因此,在未来,我们希望为特定任务领域探索具有适当大小和采样形状的LDConv,这将为后续任务增添动力。
总结
本文提出的LDConv通过引入线性可变形卷积,解决了传统卷积操作在采样形状和参数数量上的局限性。LDConv不仅能够灵活调整卷积核的大小和形状,还能通过偏移量自适应地调整采样位置,从而显著提升了目标检测任务的性能。实验结果表明,LDConv在多个数据集上均表现出色,并且能够有效减少模型的计算开销和参数数量。未来的研究方向包括进一步优化LDConv的计算效率,并探索其在更多特定任务中的应用。



















 1906
1906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











