






这篇文章的核心内容是介绍了一种新型的卷积神经网络(ConvNet)架构——OverLoCK,它通过模拟人类视觉系统的“概览优先(Overview-first)、细致观察次之(Look-Closely-next)”机制,显著提升了卷积网络在多种视觉任务中的性能。以下是文章的主要研究内容总结:
1. 研究背景与动机
-
人类视觉系统中的自上而下注意力机制:人类视觉系统在处理图像时,首先会形成场景的粗略概览(概览优先),然后通过自上而下的注意力机制,对感兴趣区域进行更细致的观察(细致观察次之)。这种机制能够有效结合全局上下文信息和局部细节,提升视觉任务的准确性。
-
现有卷积网络的局限性:传统的卷积网络(如金字塔结构的网络)通常通过逐步下采样来扩展感受野,但这种结构忽略了自上而下的注意力机制,导致在处理高分辨率图像时,难以同时捕捉全局信息和局部细节。
2. OverLoCK架构设计
-
深度阶段分解策略(DDS):将网络分解为三个协同工作的子网络:
-
Base-Net:编码低层和中层特征。
-
Overview-Net:生成粗略的全局上下文表示(概览优先),提供全局语义信息。
-
Focus-Net:在Overview-Net提供的上下文引导下,对特征图进行细粒度的感知(细致观察次之),生成更准确的高层表示。
-
-
上下文混合动态卷积(ContMix):为了解决传统卷积核在处理高分辨率图像时感受野有限的问题,提出了一种动态卷积机制。ContMix通过计算输入特征图中每个标记与全局上下文特征图中区域中心的亲和力,生成动态卷积核,从而在保持局部归纳偏差的同时,能够建模长程依赖关系。
3. 实验与性能评估
-
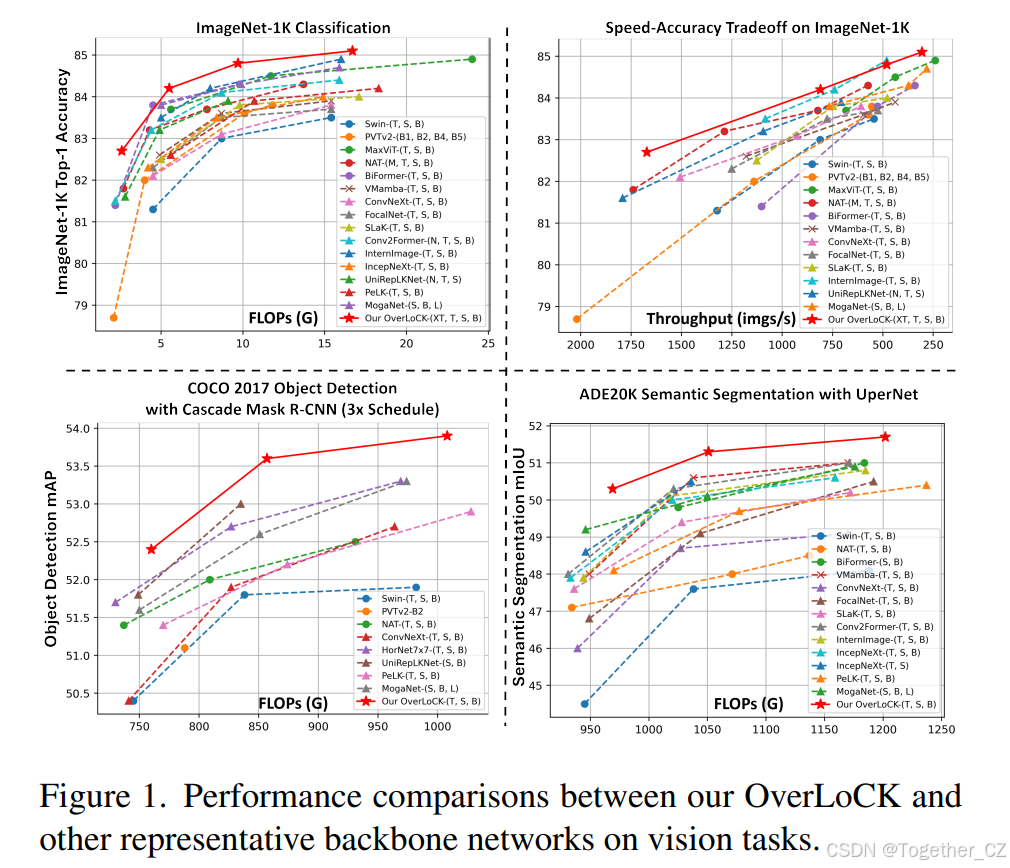
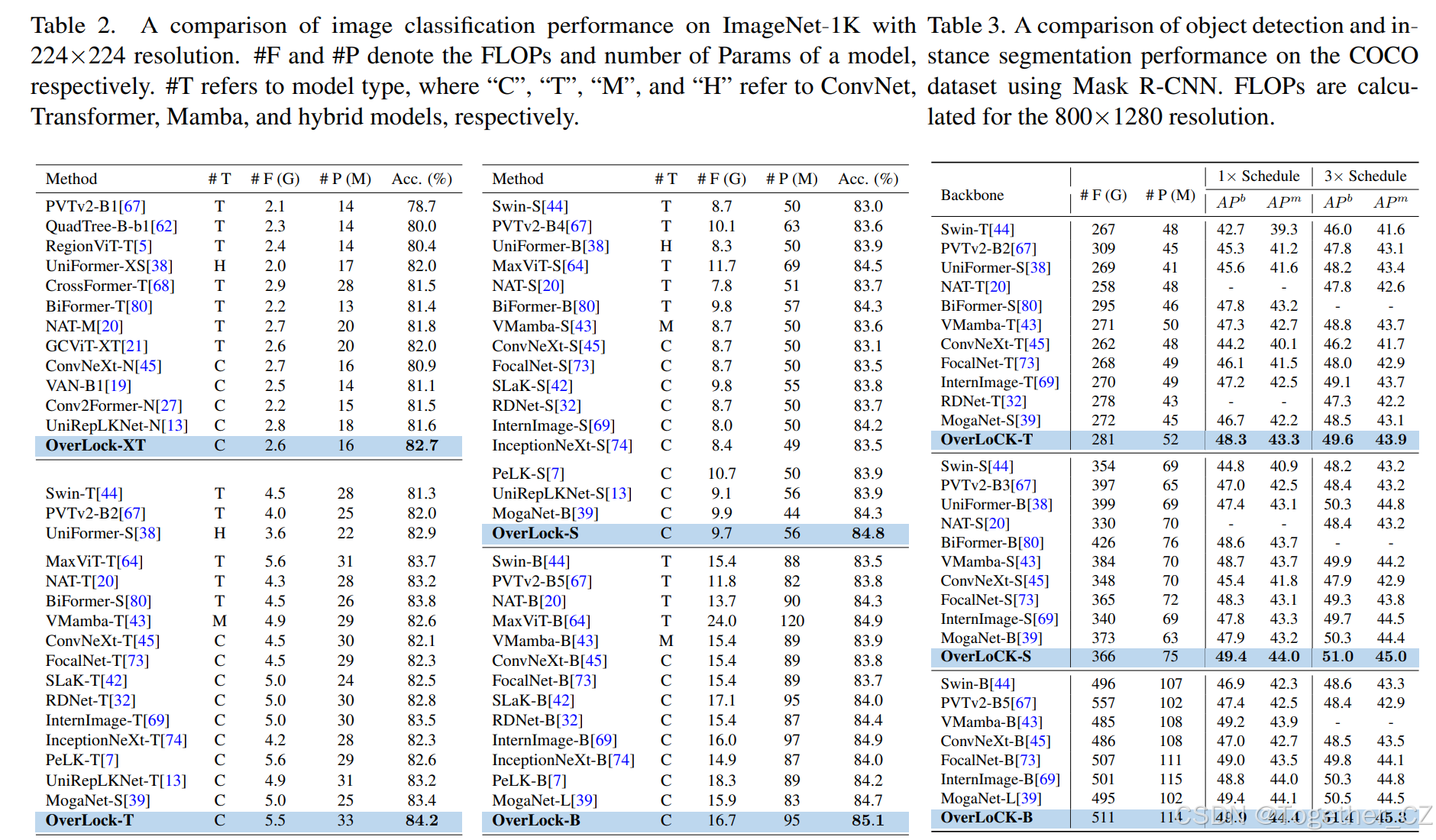
图像分类:在ImageNet-1K数据集上,OverLoCK在Top-1准确率上显著优于多个现有的ConvNet、Transformer和Mamba基模型。例如,OverLoCK-T的Top-1准确率达到了84.2%,比ConvNeXt-B高出约1.4%,且计算复杂度更低。
-
目标检测和实例分割:在COCO数据集上,使用Mask R-CNN和Cascade Mask R-CNN框架,OverLoCK在APb(平均精度)上优于多个现有模型。例如,OverLoCK-S在Mask R-CNN 1×计划下,APb比MogaNet-B高出1.5%。
-
语义分割:在ADE20K数据集上,OverLoCK在mIoU(平均交并比)上取得了领先性能。例如,OverLoCK-T的mIoU比MogaNet-S高出1.1%,比VMamba-T高出2.3%。
4. 消融研究
-
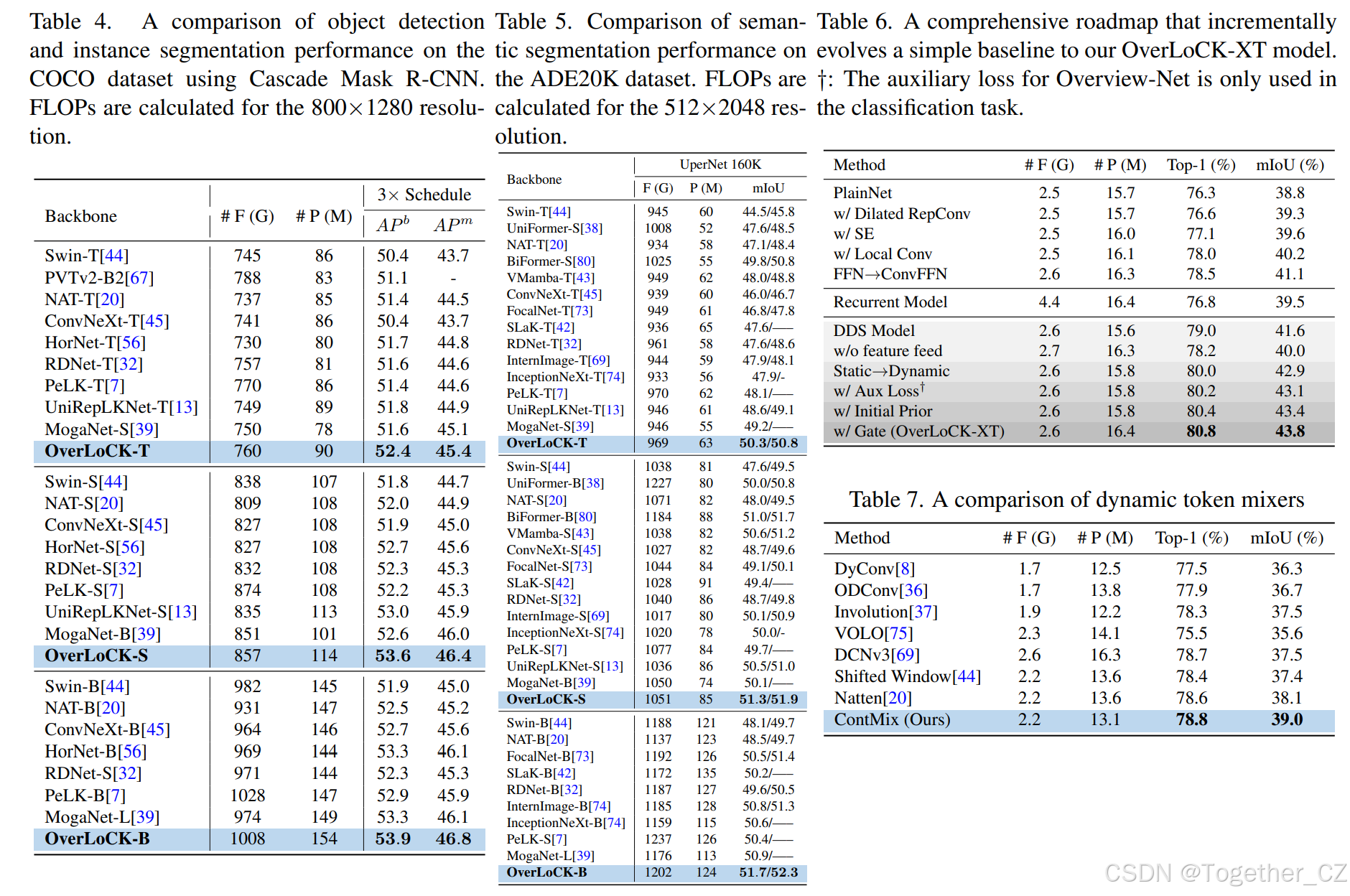
核大小、阶段比例、通道缩减因子和辅助损失的影响:通过一系列消融实验,验证了OverLoCK中各个设计选择的有效性。例如,核大小配置{[17, 15, 13], [7], [13, 7]}在图像分类和语义分割任务上取得了最佳性能;阶段比例1:2能够平衡上下文引导和特征提取的需求;通道缩减因子CRF=4时,上下文先验的引导能力最强。
-
ContMix模块的消融研究:验证了ContMix中各个组件(如Softmax、RepConv、小核等)对性能的影响,表明这些设计选择对于提升模型性能至关重要。
5. 鲁棒性与速度分析
-
鲁棒性:OverLoCK在多个分布外(OOD)基准测试(如ImageNet-V2、ImageNet-A、ImageNet-R和ImageNet-Sketch)上展现出卓越的鲁棒性,优于现有的ConvNet、Transformer和Mamba基模型。
-
速度与准确率权衡:OverLoCK在速度和准确率之间取得了卓越的平衡。例如,OverLoCK-XT在吞吐量上比Swin-T快了300多张图片/秒,同时显著提高了Top-1准确率1.4%;OverLoCK-S在吞吐量上比MogaNet-B快了100多张图片/秒,同时将Top-1准确率从84.3%提高到84.8%。
6. 可视化分析
-
类别激活图:通过GradCAM可视化,展示了Overview-Net和Focus-Net在物体定位和形状识别上的协同作用。Overview-Net提供粗略定位,Focus-Net在上下文引导下进行更准确的定位。
-
有效感受野(ERF):与现有模型相比,OverLoCK能够同时捕捉全局信息和局部细节,展现出更强的表示能力。
7. 结论
文章提出了一种受人类视觉系统启发的新型卷积网络架构OverLoCK,通过深度阶段分解策略(DDS)和上下文混合动态卷积(ContMix),在图像分类、目标检测、语义分割等多种视觉任务上取得了显著的性能提升,同时在速度和准确率之间取得了良好的平衡。OverLoCK的设计不仅提升了模型的性能,还为卷积网络的发展提供了新的思路。
这篇文章的核心贡献在于提出了一种新型的卷积网络架构,通过模拟人类视觉系统的注意力机制,显著提升了卷积网络在多种视觉任务中的性能,同时保持了计算效率。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:
官方项目地址在这里,如下所示:
摘要
自上而下的注意力在人类视觉系统中起着至关重要的作用,大脑最初会获得场景的粗略概览以发现显著线索(即“概览优先”),随后进行更仔细的细粒度检查(即“细致观察次之”)。然而,现代卷积网络(ConvNets)仍然局限于金字塔结构,通过逐步下采样特征图来扩展感受野,忽略了这一重要的仿生学原理。我们提出了OverLoCK,这是第一个明确引入自上而下注意力机制的纯卷积网络(ConvNet)骨干架构。与金字塔骨干网络不同,我们的设计采用了具有三个协同子网络的分支架构:1)用于编码低/中层特征的Base-Net;2)用于通过粗略全局上下文建模生成动态自上而下注意力的轻量级Overview-Net(即“概览优先”);以及3)在自上而下注意力引导下执行更细粒度感知的健壮Focus-Net(即“细致观察次之”)。为了充分释放自上而下注意力的力量,我们进一步提出了一种新颖的上下文混合动态卷积(ContMix),它能够有效地建模长程依赖关系,同时在输入分辨率增加时仍能保持固有的局部归纳偏差,解决了现有卷积中的关键限制。我们的OverLoCK在性能上显著优于现有方法。例如,OverLoCK-T在Top-1准确率上达到了84.2%,显著超过了ConvNeXt-B,同时仅使用了大约三分之一的FLOPs/参数。在目标检测方面,我们的OverLoCK-S在APb上比MogaNet-B高出1%。在语义分割方面,我们的OverLoCK-T在mIoU上比UniRepLKNet-T提高了1.7%。
1. 引言
自上而下的神经注意力是人类视觉系统中一种至关重要的感知机制,它表明大脑最初处理视觉场景以快速形成总体高级感知,随后这种感知会反馈与感官输入融合,使大脑能够做出更准确的判断,例如物体的位置、形状和类别。许多先前的研究已经将这种自上而下的注意力引入视觉模型,但其中一些由于模型设计不兼容而不适合用于构建现代视觉骨干网络,而其余方法主要关注循环架构,由于循环操作引入了额外的计算开销,导致性能与计算复杂性之间的权衡并不理想。
自上而下注意力机制的一个关键特性是使用反馈信号作为显式引导以定位场景中的有意义区域。然而,大多数现有视觉骨干网络所采用的经典层次架构与这种生物机制形成对比,因为它逐步从低层到高层编码特征,使得某一层的输入特征仅依赖于前一层的特征。因此,缺乏来自高层的显式语义引导。为了研究这一点,我们对三种代表性层次视觉模型Swin-T、ConvNeXt-T和VMamba-T的类别激活图和有效感受野(ERFs)进行了可视化。如图2所示,尽管这些图像分类模型在不同程度上能够捕获长程依赖关系,但它们在特征图中难以准确地定位具有正确类别标签的物体,尤其是在远离分类器层的Stage 3,尽管它们在不同程度上能够捕获长程依赖关系。相比之下,我们提出的新网络架构能够在Stage 3和Stage 4中产生更准确的类别激活图。
因此,如何开发一种能够利用自上而下注意力机制的现代ConvNet,同时在性能和复杂性之间实现卓越的权衡,仍然是一个有待解决的问题。基于上述讨论,我们提出了一种受人类视觉系统中自上而下注意力机制启发的深度阶段分解策略(DDS)。与以往工作不同,我们的目标是通过动态自上而下的语义上下文增强ConvNets中的特征图和卷积核权重。如图3所示,DDS将网络分解为三个子网络:Base-Net、Overview-Net和Focus-Net。具体而言,Base-Net编码低层和中层信息,其输出被输入到轻量级的Overview-Net中,以快速聚集一个语义上有意义但质量较低的上下文表示,类似于视觉感知中的“概览”过程。随后,我们将Overview-Net的输出指定为上下文先验,与Base-Net的输出一起输入到更深且更强大的Focus-Net中,以获得更准确和信息量更大的高层表示,类似于视觉感知中的“细致观察”过程。由于自上而下的上下文包含了整个输入图像的信息,为了充分释放其力量并将其信息吸收进卷积核中,Focus-Net应该使用一种强大的动态卷积作为标记混合器,能够自适应地建模长程依赖关系以产生较大的感受野,同时保留局部归纳偏差以捕获细腻的局部细节。然而,我们发现现有的卷积无法同时满足这些要求。与能够自适应地在各种输入分辨率下建模长程依赖关系的自注意力机制和状态空间模型不同,大核卷积和动态卷积仍然受限于有限区域,因为它们的核大小是固定的,即使在输入图像分辨率不断增加时,也表现出较弱的长程建模能力。尽管可变形卷积可以在一定程度上缓解这些问题,但可变形的核形状牺牲了卷积的固有归纳偏差,导致局部感知能力相对较弱。因此,使纯卷积具备与Transformer和Mamba基模型相当的动态全局建模能力,同时保留强大的归纳偏差,仍然是一个挑战。为了解决这一问题,我们引入了一种新颖的上下文混合动态卷积(ContMix),它能够动态地建模长程依赖关系,同时保持强大的归纳偏差。具体而言,对于输入特征图中的每个标记,我们计算其与顶向下文特征图中一组区域中心的所有标记之间的亲和力,得到一个亲和力图。随后,我们使用一个可学习的线性层将亲和力图的每一行转换为动态卷积核。因此,每个卷积核权重都携带了来自顶向下文语义的全局信息。因此,在使用我们的动态卷积核进行卷积操作时,特征图中的每个标记都会与卷积核中编码的全局信息相互作用,从而在卷积核大小固定的情况下捕获长程依赖关系。配备了我们提出的DDS和ContMix,我们提出了一个新颖的具有上下文混合动态核的概览优先、细致观察次之的卷积网络(OverLoCK)。如图1所示,我们的OverLoCK在性能上优于代表性的ConvNet、Transformer和Mamba基模型,同时在速度和准确性之间取得了卓越的平衡。例如,在ImageNet-1K数据集上,OverLoCK-T的Top-1准确率达到了84.2%,比UniRepLKNet-T高出1%,比VMamba-T高出1.6%。在下游任务中,OverLoCK也展现了领先性能。例如,OverLoCK-S在语义分割中的mIoU上比MogaNet-B高出1.2%,在目标检测的APb上比PeLK-S高出1.4%。此外,我们的方法还能够在与竞争对手相比的情况下生成更大的有效感受野,同时保持强大的局部归纳偏差,并产生更合理的特征响应,如图2所示。
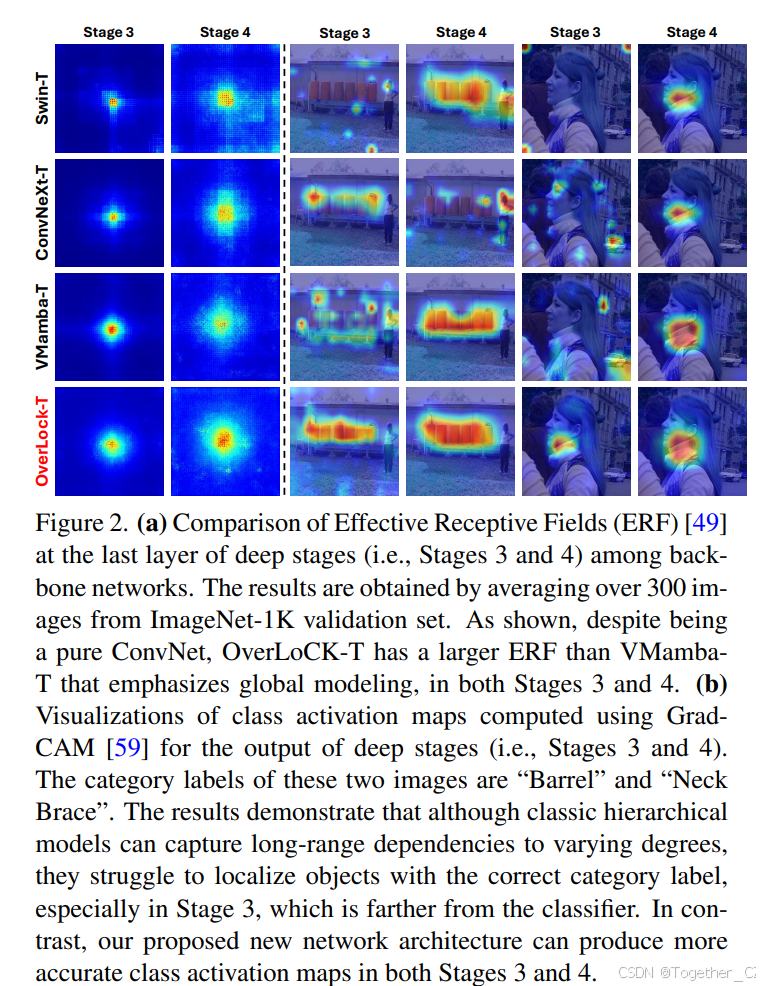
图2. (a) 比较了不同骨干网络在深层阶段(即第3阶段和第4阶段)的最后一个层的有效感受野(ERF)[49]。这些结果是通过对ImageNet-1K验证集中的300张图像进行平均计算得到的。如图所示,尽管OverLoCK-T是一个纯卷积网络,但在第3阶段和第4阶段,其有效感受野都比强调全局建模的VMamba-T更大。 (b) 使用GradCAM [59]计算的深层阶段(即第3阶段和第4阶段)输出的类别激活图的可视化结果。这两张图像的类别标签分别是“桶”和“颈托”。结果表明,尽管经典的层次模型能够在不同程度上捕获长程依赖关系,但它们在定位具有正确类别标签的物体时存在困难,尤其是在远离分类器的第3阶段。相比之下,我们提出的新网络架构能够在第3阶段和第4阶段产生更准确的类别激活图。
2. 相关工作
卷积网络(ConvNets)的演变。自AlexNet问世以来,ConvNets逐渐成为计算机视觉领域的主导架构。VGGNet引入了堆叠小核以构建深层网络的概念。ResNet和DenseNet进一步提出了跳跃连接,以解决深层网络中的梯度消失/爆炸问题。然而,随着视觉Transformer的兴起,ConvNets在视觉任务中的主导地位受到了挑战。因此,近期的方法提出了越来越大的核大小,以模仿自注意力机制并建立长程依赖关系。ConvNeXt开创性地使用了7×7核来构建视觉骨干网络,超越了Swin Transformer的性能。RepLKNet进一步探索了使用31×31核的超大核的潜力。另一方面,门控机制在ConvNets中得到了广泛探索。例如,MogaNet引入了一种多阶门控聚合模块,以增强多尺度特征表示的细化能力。最近,RDNet重新思考了DenseNet的设计,并提出了一个高效的密集连接ConvNet。与以往工作不同,本文专注于从架构和混合器的角度改进ConvNets的性能。
动态卷积。动态卷积已被证明可以有效提升ConvNets的性能,通过增强特征表示来适应输入依赖的滤波器。除了常规的通道变化建模外,一些方法还提出了空间变化建模,可以为特征图中的每个像素生成不同的卷积权重。此外,为了使卷积核的权重和形状能够动态变化,InternImage重新设计了可变形卷积,取得了显著的性能提升。然而,以往的工作未能同时建模长程依赖关系,同时保留强大的局部归纳偏差,这一限制被我们新提出的动态卷积有效解决。
仿生视觉模型。人类视觉系统启发了许多优秀的视觉骨干网络的设计。例如,一些先进的视觉骨干网络受到了周边视觉机制的启发,取得了显著的性能提升。同样,自上而下的注意力机制也推动了计算机视觉和机器学习领域的发展,例如在特定任务上提升性能、探索新的学习算法以及设计具有循环风格的通用架构。与上述工作不同,我们提出了一个新颖的基于现代ConvNet的视觉骨干网络,能够高效地生成和利用自上而下的引导,在多种视觉任务中取得了显著的性能提升。
3. 方法论
3.1 深度阶段分解
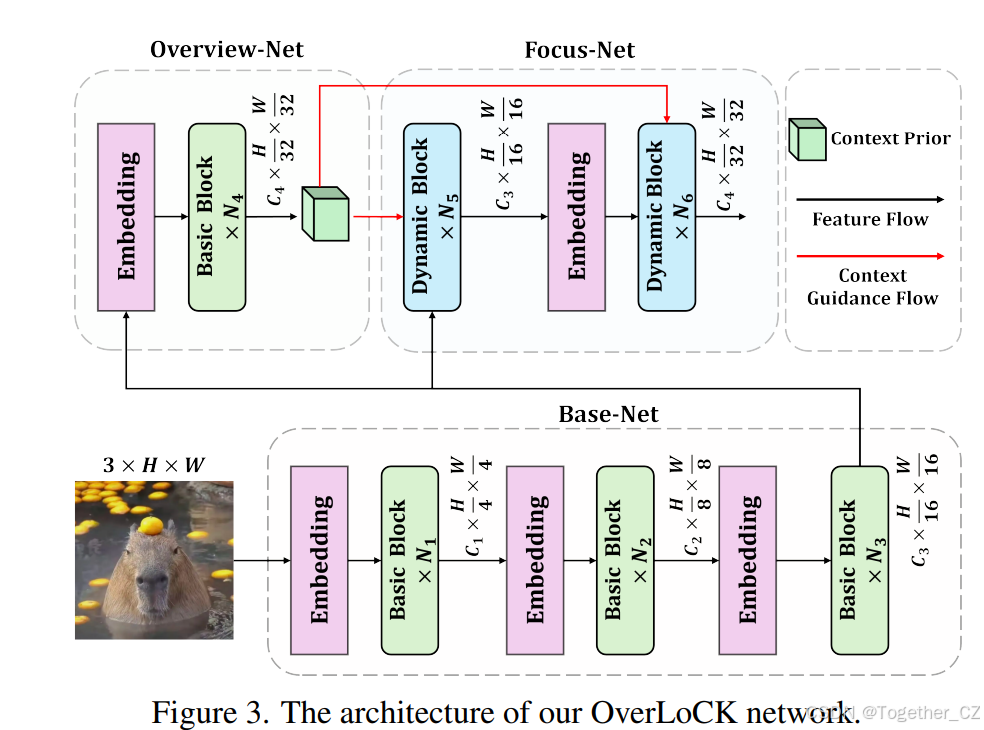
受人类视觉系统中“概览优先-细致观察次之”机制的驱动,我们提出了深度阶段分解策略(DDS),与经典层次架构不同,它将网络分解为三个不同的子网络:Base-Net、Overview-Net和Focus-Net。如图3所示,Base-Net通过三个嵌入层将输入图像逐步下采样至H×W,生成中层特征图。这个中层特征图被输入到轻量级的Overview-Net以及更深且更强大的Focus-Net中。Overview-Net通过立即下采样中层特征图至H×W,快速生成一个语义上有意义但质量较低的概览特征图,它作为输入图像的总体理解,实际上被用作反馈信号融合到Focus-Net的所有构建块中,提供总体上下文信息。因此,它被称为上下文先验。最后,在上下文先验的引导下,Focus-Net返回并逐步细化中层特征图,同时扩大感受野,以获得更准确和信息量更大的高层表示。需要注意的是,在上述设计中,实际上存在两个骨干网络,一个由Base-Net和Overview-Net级联而成,另一个由Base-Net和Focus-Net级联而成。每个骨干网络由四个阶段组成,这些阶段由四个嵌入层及其后续网络构建块定义。我们的DDS设计通过让一个Base-Net为两个骨干网络提供中层特征,最小化了计算开销。在ImageNet-1K上进行预训练时,为了实现Focus-Net和Overview-Net中的表示学习,它们各自连接到自己的分类器头,并对两个分类器施加相同的分类损失。当预训练的网络被迁移到下游任务时,我们不再对Overview-Net应用辅助监督信号,因为它已经在预训练阶段学习了高层表示。此外,在密集预测任务中应用辅助监督会使训练过程变得耗时。在分类任务中,Focus-Net始终用于进行预测。在密集预测任务中,我们使用Base-Net在H×W和H×W分辨率下的特征,以及Focus-Net在H×W和H×W分辨率下的特征来构建特征金字塔。这四组特征也对应于我们提出的ConvNet骨干网络的第1至第4阶段。
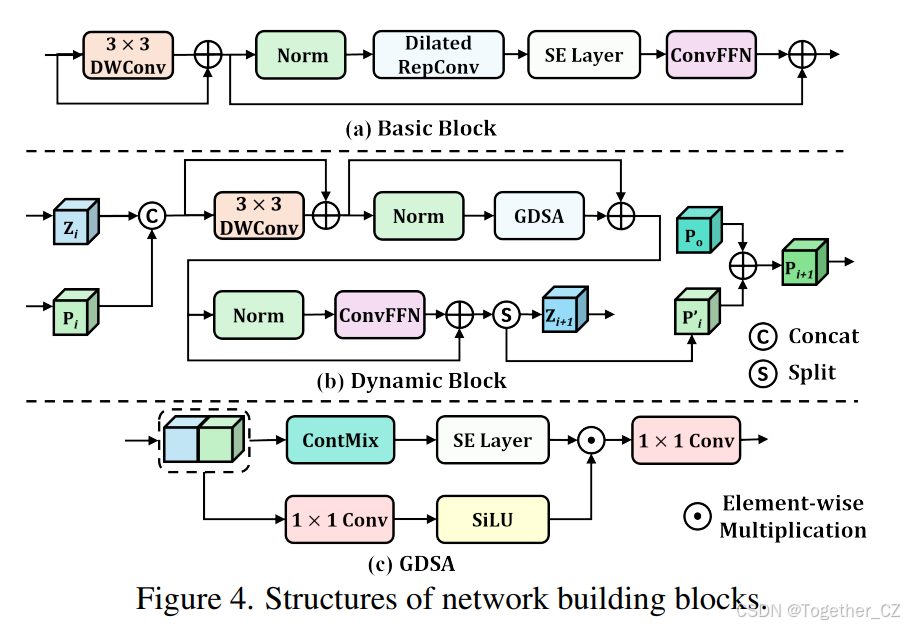
Base-Net和Overview-Net。如图4(a)所示,我们采用基本块作为Base-Net和Overview-Net的构建块。输入特征首先被送入一个残差3×3深度可分离卷积(DWConv),以执行局部感知。然后,输出被送入一个由层归一化(Layer Normalization)、扩张可重复卷积(Dilated RepConv)、SE层和ConvFFN组成的块中。
Focus-Net。如图3(b)所示,Focus-Net采用了一个更复杂的构建块,称为动态块,主要由残差3×3 DWConv、门控动态空间聚合器(GDSA)和ConvFFN组成。GDSA的流程如图3(c)所示,其中它使用我们提出的ContMix(第3.2节)作为核心标记混合器,并引入了门控机制以消除上下文噪声。需要注意的是,Focus-Net中的动态块在进入嵌入层之前属于Base-Net+Focus-Net骨干网络的第3阶段。
上下文流。Focus-Net内存在一个动态上下文流。来自Overview-Net的上下文先验不仅在Focus-Net内的特征和卷积核权重级别上提供引导,而且在每次块的前向传递中都会被更新。假设第i个块的入口处的上下文先验和特征图分别为P∈R×H×W和Z∈R×H×W,P和Z通过连接后被送入块中(如图3(b)所示)。在块内,通过在GDSA中计算动态门来调制特征图,从而实现特征级别的引导,该动态门是通过将连接后的特征图应用1×1卷积后跟SiLU激活函数得到的(如图3(c)所示)。随后,动态门与并行分支的输出逐元素相乘。另一方面,为了实现权重级别的引导,上下文先验通过利用P来计算ContMix中的动态卷积核权重,这将在下一小节中详细说明。在离开块之前,融合后的特征图被分割为P′∈R×H×W和Z+1∈R×H×W,它们可以被视为解耦且更新后的上下文先验和特征图。为了避免上下文先验被稀释,我们将初始上下文先验P加到P′上,即P+1=αP′+βP,其中α和β是可学习的标量,均在训练前初始化为1。我们对原始上下文先验进行通道降维和空间上采样,以节省计算量并匹配Focus-Net的输入分辨率,从而得到上下文流的初始上下文先验P。
3.2 具有上下文混合的动态卷积
在本节中,我们探索一种使卷积具备长程依赖关系建模能力的解决方案,以便它们能够更好地处理不同输入分辨率的情况。同时,我们仍然希望它们能够保留强大的归纳偏差。为了实现这些目标,同时充分利用来自Overview-Net的上下文先验的力量,我们提出了一种新颖的具有上下文混合能力的动态卷积,即ContMix。我们的关键思想是通过计算单个标记与特征图中一组区域中心的所有标记之间的亲和力值来表示标记与其上下文之间的关系。然后,这些亲和力值可以被聚合起来,以一种可学习的方式定义标记级动态卷积核,从而将上下文知识注入到每个卷积核权重中。一旦这样的动态核被应用于特征图的滑动窗口,特征图中的每个标记都将通过区域中心聚集的近似全局信息进行调制。因此,长程依赖关系可以被有效地建模。
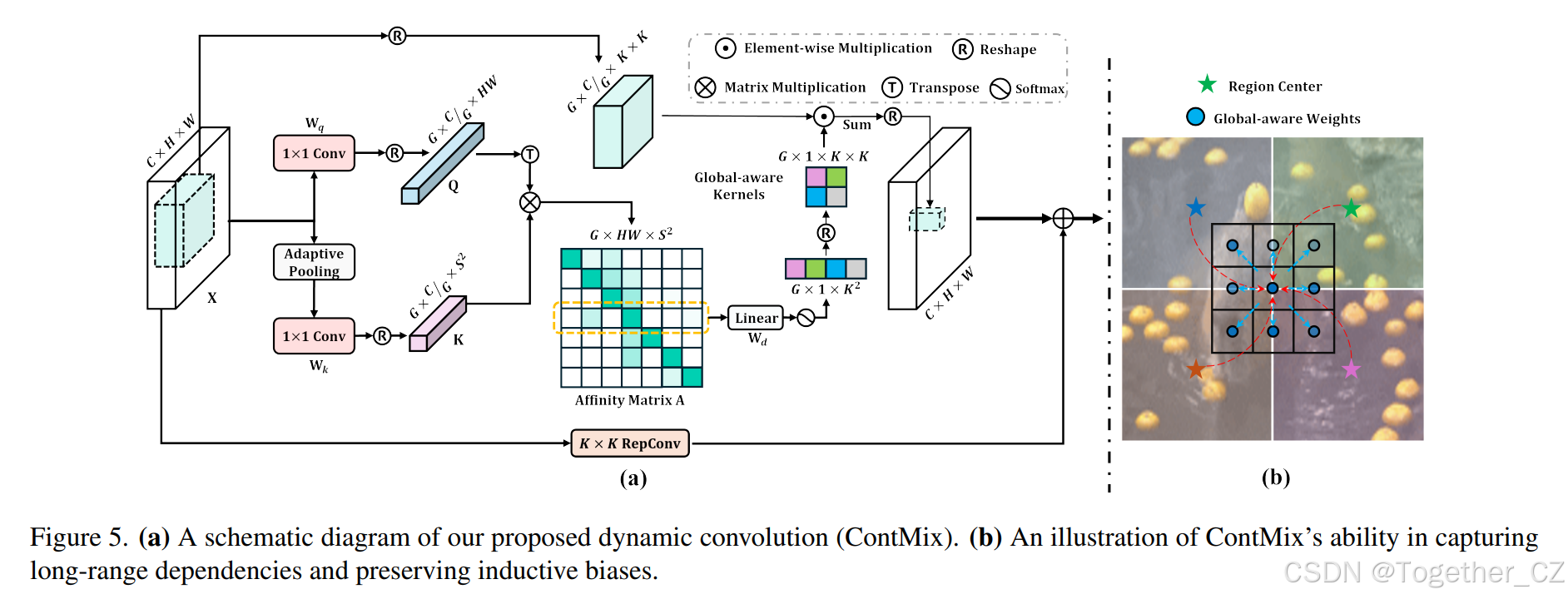
标记级全局上下文表示。如图5所示,给定一个输入特征图X∈R×H×W,我们首先将其转换为两部分,即Q∈R×HW=Re(WqX)和K∈R×S=Re(WkPool(X)),其中Wq和Wk表示1×1卷积层,Re(·)表示重塑操作,K表示通过自适应平均池化将X聚集到S×S区域中心。接下来,我们将Q和K的通道均匀地划分为G组,得到{Qg}G和{Kg}G,使得Qg∈R×HW和Kg∈R×S。在这里,组类似于多头注意力中的头。由于每对Qg和Kg都被展平为2D矩阵,简单的矩阵乘法可以计算出G个亲和力矩阵{Ag}G={QgTKg}G,其中Ag∈RHW×S。亲和力矩阵Ag的第i行,Ag,包含了Qg中第i个标记与Kg中所有标记之间的亲和力值。
标记级全局上下文混合。为了生成更鲁棒的特征表示,我们定义了G个空间变化的K×K动态核。首先,我们使用另一个可学习的线性层Wd∈RS×K来聚合存储在每个亲和力矩阵Ag的矩阵行中的标记级亲和力值,通过在Ag和Wd之间执行矩阵乘法来实现。需要注意的是,所有G个亲和力矩阵共享同一个Wd,以节省计算效率。然后,使用softmax函数对聚合后的亲和力进行归一化。这两个操作可以表示为Dg=softmax(AgWd)∈RHW×K。最后,Dg的每一行都可以被重塑为目标核形状,以在每个标记位置产生一个输入依赖的核。在卷积操作中,特征图X的通道也被均匀地划分为G组,同一组内的通道共享相同的动态核。
实现。我们的ContMix是一个通用的即插即用模块。在OverLoCK网络的动态块中,ContMix被定制如下。上述Q和K矩阵是使用X的通道分别对应于Zi和Pi(最新的上下文先验)来计算的。这种设置与仅使用当前融合特征X来计算Q和K相比,能够获得更好的性能。此外,我们经验性地将S设置为7,以确保我们的ContMix具有线性时间复杂度。同时,许多先前的研究表明,结合大核和小核可以更好地提取多尺度特征。因此,我们将ContMix中的一半组分配给大核,另一半分配给小核,其大小设置为5×5,以便使用不同大小的核来建模长程依赖关系和局部细节。我们还使用带有K×K核的扩张可重复卷积层来增加通道多样性。
3.3 网络架构
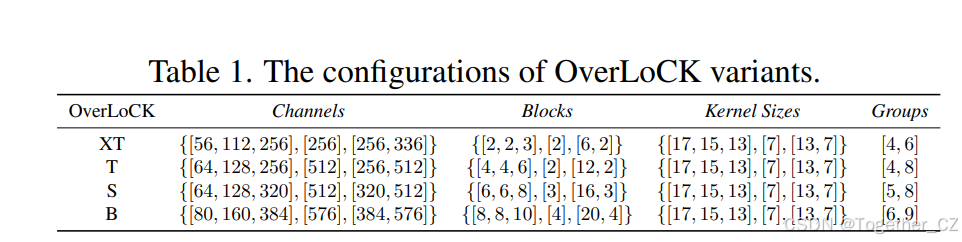
我们的OverLoCK网络有四种架构变体,包括极小(XT)、小(T)、中(S)和大(B)。如表1所示,我们使用四个变量来控制模型大小:通道数、块数、核大小和组数。例如,在OverLoCK-XT中,通道数=[56, 112, 256], [256], [256, 336],表示Base-Net的三个阶段中的通道数分别为[56, 112, 256],Overview-Net中的通道数为256,Focus-Net的两个阶段中的通道数分别为[256, 336]。块数和核大小的定义类似。此外,组数=[4, 6]表示Focus-Net的两个阶段中ContMix中的动态核的组数分别为4和6。
4. 实验
在本节中,我们在各种视觉任务上进行了全面的实验评估,从图像分类开始。然后,我们将预训练的模型迁移到下游任务,包括目标检测和语义分割。由于篇幅限制,本节仅报告部分结果,附录中提供了更多的实验结果。
4.1 图像分类 设置
我们在ImageNet-1K数据集上进行实验,并遵循DeiT中描述的相同实验设置以确保公平比较。具体而言,所有模型均使用AdamW优化器训练300个周期。随机深度率分别设置为OverLoCK-XT、-T、-S和-B模型的0.1、0.15、0.4和0.5。所有实验均在8个NVIDIA H800 GPU上进行。
结果。如表2所示,我们的纯ConvNet模型在性能上显著优于其他竞争对手。例如,OverLoCK-XT超过了强大的Transformer基模型BiFormer-T和最近的超大核ConvNet UniRepLKNet-N,Top-1准确率分别提高了1.3%和1.1%。对于小模型,我们的OverLoCK-T与其他方法相比也取得了最佳性能,Top-1准确率达到了84.2%,分别比MogaNet-S和PeLK-T提高了0.8%和1.6%。在放大到更大模型时,我们的OverLoCK仍然保持显著优势。具体而言,OverLoCK-S在Top-1准确率上比BiFormer-B和UniRepLKNet-S分别提高了0.5%和0.9%,且计算复杂度相当。对于最大模型,OverLoCK-B在Top-1准确率上达到了85.1%,比MaxViT-B高出0.2%,同时计算复杂度显著降低。同时,我们使用单个NVIDIA L40S GPU上的128批量大小评估了不同模型的吞吐量。图1表明,我们的OverLoCK在速度和准确性之间取得了卓越的权衡。例如,OverLoCK-S在吞吐量上比MogaNet-B高出超过100张图片/秒,同时显著提高了Top-1准确率,从84.3%提高到84.8%。同样,OverLoCK-XT在吞吐量上比BiFormer-T高出超过600张图片/秒,同时显著提高了Top-1准确率1.3%。总体而言,据我们所知,OverLoCK是第一个在ImageNet-1K上对强大基线取得如此显著性能提升的纯ConvNet模型。
4.2 目标检测和实例分割 设置
我们使用COCO 2017数据集评估我们的网络架构在目标检测和实例分割任务上的性能。我们采用了Mask R-CNN和Cascade Mask R-CNN框架,并采用了与Swin中相同的实验设置。骨干网络最初在ImageNet-1K上进行预训练,然后分别针对12个周期(1×计划)和36个周期(3×计划,具有多尺度训练)进行微调。
结果。如表3和表4所示,OverLoCK在性能上明显优于其他方法。例如,在使用Mask R-CNN 1×计划时,OverLoCK-S在APb上分别比BiFormer-B和MogaNet-B高出0.8%和1.5%。当使用Cascade Mask R-CNN时,OverLoCK-S在APb上分别比PeLK-S和UniRepLKNet-S高出1.4%和0.6%。值得注意的是,我们观察到一个有趣的现象:尽管ConvNet基方法在图像分类任务上与Transformer基方法达到了相当的性能,但在检测任务上存在显著的性能差距。例如,MogaNet-B和BiFormer-B在ImageNet-1K上的Top-1准确率均为84.3%,但前者在检测任务上落后于后者。这验证了我们之前的论点,即ConvNet的固定核大小导致感受野有限,从而在使用大输入分辨率时导致性能下降。相反,我们的OverLoCK即使在大分辨率下也能有效地捕获长程依赖关系,从而取得了卓越的性能。
4.3 语义分割 设置
我们在ADE20K数据集上进行语义分割实验,采用UperNet框架。为了公平比较,我们采用与Swin中相同的训练设置,所有骨干网络均使用在ImageNet-1K上预训练的权重进行初始化。
结果。如表5所示,我们的OverLoCK在语义分割任务上取得了领先的性能。例如,OverLoCK-T在mIoU上分别比MogaNet-S和UniRepLKNet-T高出1.1%和1.7%,并且超过了强调全局建模的VMamba-T,mIoU提升了2.3%。这种优势在中型和大型模型中也是一致的。此外,我们发现感受野有限的问题也对ConvNet在分割任务上的性能产生了负面影响,例如,尽管MogaNet-B在分类任务上与BiFormer-B具有相同的准确率,但前者在分割任务上落后于后者0.9%。相比之下,我们的OverLoCK有效地缓解了这一问题。
4.4 消融研究 设置
我们在图像分类和语义分割任务上进行了全面的消融研究,以评估OverLoCK中各个组件的有效性。具体而言,我们在ImageNet-1K数据集上训练每个模型变体120个周期,遵循[7, 42]中的设置,同时保持其余训练设置与第4.1节中描述的一致。随后,我们在ADE20K数据集上对预训练的模型进行微调,迭代80K步,批量大小为32,以便更快地进行训练,同时保持其余设置与第4.3节中描述的一致。由于篇幅限制,更多的消融研究结果在附录中呈现。
通往OverLoCK模型的详细路线图。首先,我们的目标是开发一个使用静态大核卷积的强大基线模型。为此,我们首先评估了基本块中不同组件的性能(如图4(a)所示)。具体而言,我们使用一个普通的卷积层后接一个普通的FFN作为构建块,构建了一个层次化模型。该模型包含四个阶段,每个阶段的块数分别设置为[2, 2, 9, 4],每个阶段的通道数分别设置为[56, 112, 304, 400]。四个阶段的核大小与XT模型一致。该模型被称为“PlainNet”,其Top-1/mIoU准确率分别为76.3%/38.8%,如表6所示。然后,我们将普通的卷积层替换为扩张可重复卷积层,称为“带扩张可重复卷积”(Top-1/mIoU:76.6%/39.3%)。接下来,我们逐步添加SE层(Top-1/mIoU:77.1%/39.6%)、3×3 DWConv(Top-1/mIoU:78.0%/40.2%),并将普通的FFN替换为ConvFFN(Top-1/mIoU:78.5%/41.1%)。得到的网络被称为“基线”。随后,我们探索了三种策略,将自上而下的注意力注入到这个基线网络中。(1)受AbsViT的启发,我们通过上采样第4阶段的输出,并将其与第3阶段的输入连接起来,构建了一个循环模型,称为“循环模型”。然而,该模型的性能下降到76.8%/39.5%,且复杂度更高,表明循环设计不适合现代基于ConvNet的骨干网络。(2)我们采用我们提出的DDS来将基线网络分解为三个相互连接的子网络。来自BaseNet和Overview-Net的输出被连接起来并送入FocusNet。为了确保与基线模型具有相似的计算成本,三个子网络中的块数和通道数分别设置为[56, 112, 304]、[400]、[304, 400]和[2, 2, 3]、[2]、[6, 2]。这个模型被称为“DDS模型”,其Top-1准确率达到了79.0%/41.6%。(3)在“DDS模型”中,我们仅将Overview-Net的投影输出送入Focus-Net,而不是将其与Base-Net的输出连接起来,得到的模型被称为“无特征馈送”。这个模型的性能有所下降,表明将Base-Net的输出送入Focus-Net的重要性。最后,我们评估了权重级上下文引导的影响,通过将FocusNet中的每个现有块替换为我们提出的动态块(不包括门控模块),并确保上下文先验更新流不使用初始上下文先验。这种修改保持了与我们的XT模型相同的块数和通道数,以确保计算复杂度相当,以便进行公平比较。这个模型被称为“静态→动态”,显著提高了Top-1/mIoU至80.0%/42.9%。接下来,为了使Overview-Net产生语义上有意义的上下文特征,我们使用辅助分类损失来监督其输出。得到的模型被称为“带辅助损失”,其Top-1/mIoU进一步提高了0.2%/0.2%。随后,我们将初始上下文先验引入每个动态块,如第5节所述,以防止上下文先验在更新过程中稀释有意义的信息。这个变体被称为“带初始先验”,增强了Top-1/mIoU 0.2%/0.3%。最后,我们评估了上下文引导特征调制的影响,通过添加门控模块。这得到了我们的XT模型,进一步将Top-1/mIoU提高到80.8%/43.8%。总之,我们提出的方法在显著的性能提升中发挥了重要作用。
不同动态标记混合器的比较。为了公平比较动态标记混合器,我们构建了一个类似Swin的架构,将四个阶段的块数和通道数分别设置为[2, 2, 6, 2]和[64, 128, 256, 512],并采用非重叠的patch嵌入和标准的前馈网络(FFN)。我们以可分离卷积的方式实现DyConv和ODConv,以确保与其他方法具有相当的计算复杂度。此外,我们将所有方法的核/窗口大小设置为7×7,除了VOLO,因为更大的核会显著增加参数数量。从表7可以看出,我们的上下文混合动态核(ContMix)在图像分类和语义分割任务上均取得了最佳结果。值得注意的是,尽管ContMix在低分辨率输入的分类任务上与Natten和DCNv3表现出类似的性能,但在高分辨率输入的语义分割任务上具有明显的优势。这是因为ContMix在捕获长程依赖关系的同时保留了局部归纳偏差。
5. 结论
本文提出了一个仿生的深度阶段分解(DDS)机制,将语义上有意义的上下文注入到网络的中间阶段,并且提出了一个具有上下文混合能力的新颖动态卷积,即ContMix,它在捕获长程依赖关系的同时保留了强大的归纳偏差。通过整合这些组件,我们提出了一个强大的基于纯ConvNet的视觉骨干网络,称为OverLoCK,与强大的基线相比,取得了明显优越的性能。
OverLoCK:一种具有上下文混合动态卷积的概览优先、细致观察次之的卷积网络
附录材料
A. 更多消融研究
基于第4.4节中描述的训练设置,我们还进行了一系列深入的消融实验,以仔细检查我们提出方法中每个组件的影响。
核大小的影响
我们比较了在不同核大小设置下的性能,如表6(我们提出方法中核大小的定义在第3.3节中给出)。结果表明,配置{[17, 15, 13], [7], [13, 7]}在图像分类和语义分割任务上均取得了最佳性能。进一步增大核大小并没有带来额外的改进。
表A. 核大小设置的消融研究
| 核大小配置 | FLOPs (G) | 参数量 (M) | Top-1准确率 (%) | mIoU (%) |
|---|---|---|---|---|
| {[19, 17, 15], [7], [15, 7]} | 2.8 | 16.5 | 80.7 | 43.8 |
| {[17, 15, 13], [7], [13, 7]} | 2.6 | 16.4 | 80.8 | 43.8 |
| {[13, 11, 9], [7], [9, 7]} | 2.6 | 16.3 | 80.5 | 43.5 |
| {[9, 9, 7], [7], [7, 7]} | 2.6 | 16.1 | 80.6 | 43.3 |
| {[7, 7, 7], [7], [7, 7]} | 2.5 | 16.1 | 80.4 | 43.1 |
阶段比例的影响
阶段比例指的是Base-Net最后一个阶段的块数与Focus-Net第一个阶段的块数之间的比例。在OverLoCK模型的默认设置中,阶段比例为1:2,目的是为Focus-Net分配更多的网络块,以便提取更具区分性的深层特征。在本节中,我们进一步将阶段比例设置为1:1和1:3,同时保持网络总块数不变。表B中的结果表明,1:2的阶段比例取得了最佳结果。我们推测,如果阶段比例过小,Focus-Net中的块数不足,将阻碍对深层特征的提取。相反,如果阶段比例过大,Base-Net中的块数不足,将无法提供足够的上下文引导。
表B. 不同阶段比例设置的消融研究
| 阶段比例 | FLOPs (G) | 参数量 (M) | Top-1准确率 (%) | mIoU (%) |
|---|---|---|---|---|
| 1:1 | 2.7 | 16.1 | 80.4 | 42.9 |
| 1:2 | 2.6 | 16.4 | 80.8 | 43.8 |
| 1:3 | 2.7 | 15.9 | 80.6 | 43.6 |
通道缩减因子的影响
在OverLoCK模型的默认配置中,我们使用1×1卷积将Overview-Net的输出通道数减少一个因子(CRF),并将其与Base-Net的输出连接起来,然后送入Focus-Net。因此,CRF的值决定了上下文先验中的通道数,从而影响引导能力。在此过程中,我们还调整Focus-Net中的通道数,以保持不同模型变体之间的复杂度相似。表C中的结果表明,CRF=4时取得了最佳性能。
表C. 通道缩减因子设置的消融研究
| 通道缩减因子 | FLOPs (G) | 参数量 (M) | Top-1准确率 (%) | mIoU (%) |
|---|---|---|---|---|
| 2 | 2.6 | 16.1 | 80.5 | 42.9 |
| 4 | 2.6 | 16.4 | 80.8 | 43.8 |
| 6 | 2.7 | 16.6 | 80.7 | 43.4 |
| 8 | 2.7 | 16.7 | 80.6 | 43.0 |
辅助损失的影响
为了探索对Overview-Net应用辅助损失的影响,我们调整了辅助损失的权重,参考了先前的研究[78]。鉴于这些模型的架构是一致的,为了简化比较,我们没有在分割任务上进行进一步的实验。表D中的结果表明,使用辅助损失可以提高准确率,但调整辅助损失的权重对性能没有显著影响。这一发现与先前的研究[78]一致。
表D. 辅助损失的消融研究
| 辅助损失权重 | Top-1准确率 (%) |
|---|---|
| 0 | 80.4 |
| 0.2 | 80.7 |
| 0.4 | 80.8 |
| 0.8 | 80.7 |
| 1.0 | 80.7 |
DDS基自上而下网络的有效性
为了评估我们提出的DDS的有效性,我们将OverLoCK-XT模型重构为一个标准的层次化网络。具体而言,我们通过移除Overview-Net来消除自上而下的注意力机制,同时保持Base-Net和Focus-Net中相同类型的层。为了保持与其它模型相当的复杂度,我们将四个阶段的通道数和层数分别设置为[64, 112, 256, 360]和[2, 2, 9, 4]。这个模型被称为“层次化模型”。此外,我们将其与表6中的“基线”模型进行比较,后者是一个完全静态的ConvNet。如表E所示,“层次化模型”导致了明显的性能下降,这证明了我们基于DDS的自上而下上下文引导的有效性。然而,与“基线”模型相比,它仍然具有显著的优势,这清楚地表明了我们提出的动态卷积模块的优越性。
表E. DDS基自上而下网络的有效性
| 方法 | FLOPs (G) | 参数量 (M) | Top-1准确率 (%) | mIoU (%) |
|---|---|---|---|---|
| 基线模型 | 2.6 | 16.3 | 78.5 | 41.1 |
| 层次化模型 | 2.7 | 16.2 | 79.2 | 41.9 |
| OverLoCK-XT | 2.6 | 16.4 | 80.7 | 43.8 |
ContMix的消融研究
我们对提出的ContMix框架中的各个组件进行了全面的比较,如第3.2节所述。如表F所示,我们首先使用融合后的特征图而不是使用与Zi和Pi(最新的上下文先验)对应的X的通道来计算Q和K。这个模型变体被称为“融合亲和力”,导致了轻微的性能下降。接下来,我们交换了生成Q和K矩阵的特征。这个模型被称为“反向QK”,也表现出性能下降。此外,我们分别移除了Softmax函数(称为“无Softmax”)、移除了RepConv(称为“无RepConv”),并将小核替换为大核(称为“无小核”)。这些改动在分类和分割任务上都降低了性能。
表F. ContMix的消融研究
| 方法 | FLOPs (G) | 参数量 (M) | Top-1准确率 (%) | mIoU (%) |
|---|---|---|---|---|
| 基线 | 2.6 | 16.4 | 80.8 | 43.8 |
| 融合亲和力 | 2.7 | 16.6 | 80.7 | 43.5 |
| 反向QK | 2.7 | 16.4 | 80.6 | 42.9 |
| 无Softmax | 2.6 | 16.4 | 80.5 | 43.5 |
| 无RepConv | 2.5 | 16.1 | 80.6 | 43.4 |
| 无小核 | 2.8 | 16.6 | 80.7 | 43.3 |
B. 图像分类的额外实验
高分辨率评估
按照先前的研究[32, 45, 74],我们进一步研究了在更高分辨率(即384×384)下的ImageNet1K数据集上的图像分类性能。具体而言,我们在224×224的输入上对基础模型进行预训练,然后在384×384的输入上进行30个周期的微调。如表G所示,我们的OverLock-B模型在高分辨率输入条件下取得了卓越的性能。值得注意的是,OverLock-B在Top-1准确率上超过了MaxViT-B 0.5%,同时减少了超过三分之一的参数量。与PeLK-B(一种大核ConvNet)相比,我们的方法也显示出显著的改进。这些结果进一步验证了我们提出的方法在处理高分辨率输入时的鲁棒性。
表G. 384×384输入下的图像分类性能比较
| 方法 | 类型 | FLOPs (G) | 参数量 (M) | 准确率 (%) |
|---|---|---|---|---|
| Swin-B | T | 47.1 | 88 | 84.5 |
| MaxViT-B | T | 74.2 | 120 | 85.7 |
| ConvNeXt-B | C | 45.2 | 88 | 85.1 |
| InceptionNeXt-B | C | 43.6 | 87 | 85.2 |
| RDNet-L | C | 101.9 | 186 | 85.8 |
| PeLK-B-101 | C | 68.3 | 90 | 85.8 |
| OverLoCK-B | C | 50.4 | 95 | 86.2 |
鲁棒性评估
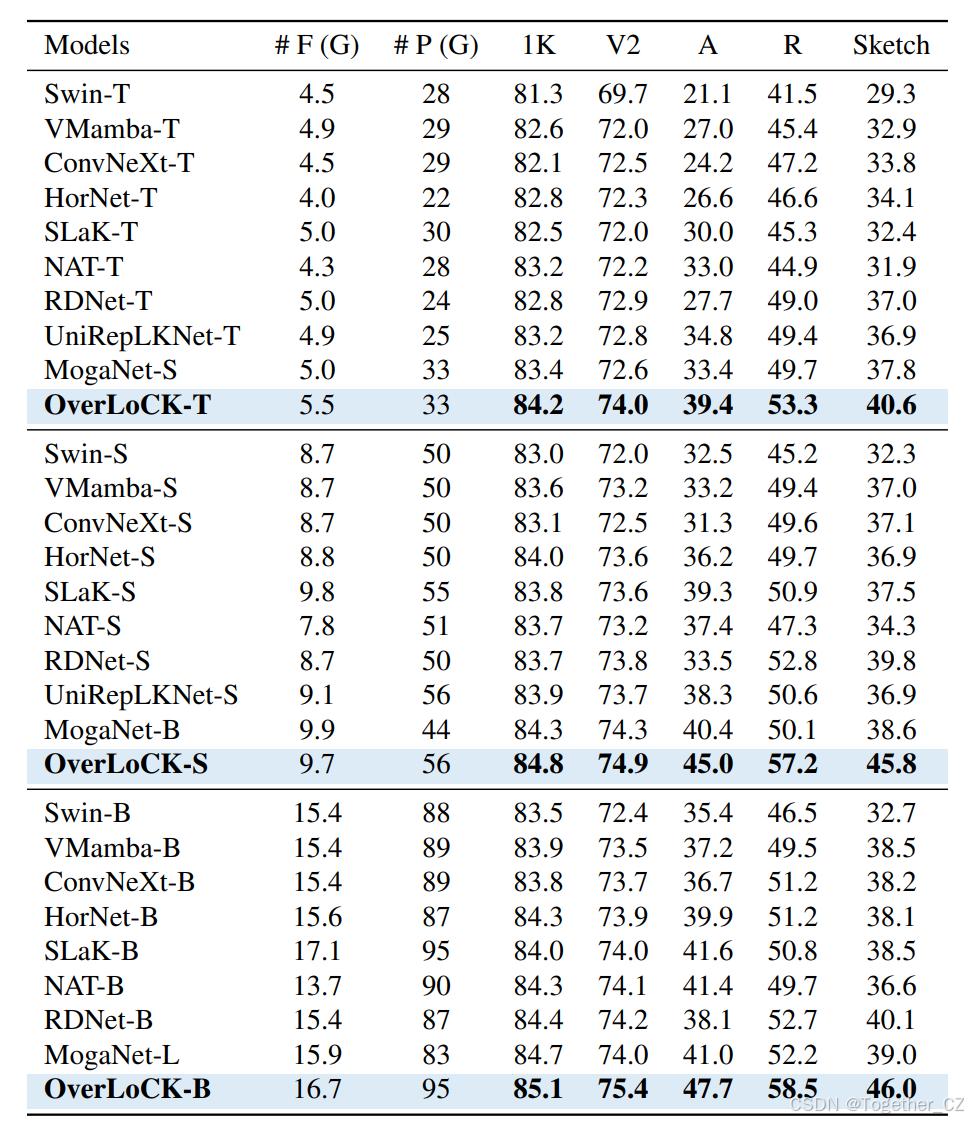
我们进一步使用ImageNet的分布外(OOD)基准测试来评估我们模型的鲁棒性,包括ImageNet-V2[57]、ImageNet-A[26]、ImageNet-R[25]和ImageNet-Sketch[65]。如表H所示,我们的方法在不同数据集上展现出卓越的鲁棒性,优于代表性的ConvNet、视觉Transformer和视觉Mamba。值得注意的是,尽管OverLoCK-B在ImageNet-1K上的Top-1准确率仅比MogaNet-L高出0.4%,但它在OOD数据集上取得了显著的改进,在ImageNet-V2上提高了1.4%,在ImageNet-A上提高了6.7%,在ImageNet-R上提高了6.3%,在ImageNet-Sketch上提高了6.8%。这些结果展示了我们纯ConvNet的强大鲁棒性。
表H. 不同模型的鲁棒性比较
C. 速度分析
我们在图1中提供了速度-准确率权衡的比较。更多细节列在表I中,OverLoCK变体通常在速度和准确性上都优于其他网络的更大变体,显示出卓越的速度和准确率权衡。例如,OverLoCK-XT实现了1672张图片/秒的吞吐量,比Swin-T快了300多张图片/秒,同时显著提高了Top-1准确率1.4%。此外,与ConvNeXt-B相比,OverLoCK-T在吞吐量上提高了约200张图片/秒,同时以仅约三分之一的FLOPs实现了更好的性能。当与更先进的模型相比时,OverLoCK仍然显示出显著的优势。例如,OverLoCK-S在吞吐量上比MogaNet-B快了100多张图片/秒,同时将Top-1准确率从84.3%提高到84.8%。同样,OverLoCK-XT在吞吐量上比BiFormer-T快了600多张图片/秒,同时显著提高了Top-1准确率1.3%。
表I. 不同模型的速度和准确率比较
| 方法 | FLOPs (G) | 参数量 (M) | 吞吐量 (imgs/s) | 准确率 (%) |
|---|---|---|---|---|
| Swin-T | 4.5 | 28 | 1324 | 81.3 |
| FocalNet-T | 4.5 | 29 | 1251 | 82.3 |
| Swin-S | 8.7 | 50 | 812 | 83.0 |
| FocalNet-S | 8.7 | 50 | 777 | 83.5 |
| Swin-B | 15.4 | 88 | 544 | 83.5 |
| FocalNet-B | 15.4 | 89 | 481 | 83.7 |
| MaxViT-T | 5.6 | 31 | 683 | 83.7 |
| SLaK-T | 5.0 | 30 | 1126 | 82.5 |
| MaxViT-S | 11.7 | 69 | 439 | 84.5 |
| SLaK-S | 9.8 | 55 | 747 | 83.8 |
| MaxViT-B | 24.0 | 120 | 241 | 84.9 |
| NAT-M | 2.7 | 20 | 1740 | 81.8 |
| InternImage-T | 5.0 | 30 | 1084 | 83.5 |
| NAT-T | 4.3 | 28 | 1287 | 83.2 |
| InternImage-S | 8.0 | 50 | 740 | 84.2 |
| NAT-S | 7.8 | 51 | 823 | 83.7 |
| NAT-B | 13.7 | 90 | 574 | 84.3 |
| UniRepLKNet-N | 2.8 | 18 | 1792 | 81.6 |
| BiFormer-T | 2.2 | 13 | 1103 | 81.4 |
| UniRepLKNet-T | 4.9 | 31 | 1094 | 83.2 |
| BiFormer-S | 4.5 | 26 | 527 | 83.8 |
| BiFormer-B | 9.8 | 57 | 341 | 84.3 |
| VMamba-T | 4.9 | 29 | 1179 | 82.6 |
| VMamba-S | 8.7 | 50 | 596 | 83.6 |
| VMamba-B | 15.4 | 89 | 439 | 83.9 |
| OverLoCK-XT | 2.6 | 16 | 1672 | 82.7 |
| ConvNeXt-T | 4.5 | 29 | 1507 | 82.1 |
| OverLoCK-T | 5.5 | 33 | 810 | 84.2 |
| ConvNeXt-S | 8.7 | 50 | 926 | 83.1 |
| OverLoCK-S | 9.7 | 56 | 480 | 84.8 |
| ConvNeXt-B | 15.4 | 89 | 608 | 83.8 |
| OverLoCK-B | 16.7 | 95 | 306 | 85.1 |
D. 可视化分析
上下文引导的效果
为了直观地理解上下文引导的效果,我们分别使用GradCAM[59]对OverLoCK-T的Overview-Net和Focus-Net生成的类别激活图进行了可视化,用于ImageNet-1K验证集。如图A所示,Overview-Net首先对物体进行粗略定位,当这个信号被用作Focus-Net的自上而下引导时,物体的位置和形状变得更加准确。
有效感受野分析
为了直观地展示OverLoCK的表示能力,我们将我们的OverLoCK-T与其他具有相当复杂度的代表性模型的有效感受野(ERF)[49]进行了比较。这些可视化是使用来自ImageNet1K验证集的300张随机采样的224×224分辨率图像生成的。如图B所示,我们的模型不仅产生了全局响应,还表现出显著的局部敏感性,表明OverLoCK能够同时有效地建模全局和局部上下文。

图A. OverLoCK网络的类别激活图。 (a)、(b)和(c)分别显示了输入图像、Overview-Net的类别激活图和Focus-Net的类别激活图。

图B. 不同模型的有效感受野比较。



















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











