










各位是否注意过人类观察世界的独特方式?
顾名思义,就是当面对复杂场景时,我们往往先快速获得整体印象,再聚焦关键细节。这种「纵观全局 - 聚焦细节(Overview-first-Look-Closely-next)」的双阶段认知机制是人类视觉系统强大的主要原因之一,也被称为 Top-down Attention。
虽然这种机制在许多视觉任务中得到应用,但是如何利用这种机制来构建强大的 Vision Backbone 却尚未得到充分研究。
近期,香港大学的研究团队创新性地将特定认知模式引入到 Vision Backbone(视觉骨干网络)的设计中,成功构建出一种全新的视觉基础模型 ——OverLoCK(Overview - first - Look - Closely - next ConvNet with Context - Mixing Dynamic Kernels,即先概览后细察的上下文混合动态卷积网络 )。在 ImageNet、COCO、ADE20K 这三个计算机视觉领域极具挑战性的权威数据集上,OverLoCK 模型均展现出卓越性能。以参数规模为 30M 的 OverLoCK - Tiny 模型为例,它在 ImageNet - 1K 数据集上取得了 84.2% 的 Top - 1 准确率。相较于此前的 ConvNet(卷积网络)、Transformer 以及 Mamba 等模型,OverLoCK 模型在准确率等关键指标上优势显著,为视觉基础模型的发展开辟了新路径。

我在这给大家放上链接,大家有兴趣的可以去访问,并复现一下论文代码。
-
论文标题:OverLoCK: An Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels
-
论文链接:https://arxiv.org/abs/2502.20087
-
代码链接:https://github.com/LMMMEng/OverLoCK
动机
Top - down Attention 机制的核心特性,在于借助大脑反馈信号作为明确的信息指引,精准定位场景中的关键区域。然而,当前多数主流的 Vision Backbone 网络,诸如 Swin、ConvNeXt 以及 VMamba 等,依旧采用经典的金字塔架构。在这种架构下,特征由低层向高层逐步编码,且每一层的输入特征仅取决于前一层的输出特征,致使这些方法缺乏清晰的自上而下的语义引导。所以,研发一种既能够有效实现 Top - down Attention 机制,又具备强劲性能的卷积网络,至今仍是计算机视觉领域一个尚未攻克的难题。
一般而言,Top - down Attention 首先会生成相对粗糙的全局信息,以此作为先验知识。为充分发挥这类信息的价值,token mixer 需具备卓越的动态建模能力。具体来讲,token mixer 既要能构建大感受野,自适应地建立全局依赖关系,又需维持局部归纳偏置,从而捕捉精细的局部特征。但研究发现,现有的卷积方法难以同时满足上述要求。Self - attention 和 SSM 能够在不同输入分辨率下,灵活自适应地对长距离依赖进行建模;与之不同,大核卷积和动态卷积受限于固定的核尺寸,在面对高分辨率输入时,其作用范围仍局限于有限区域。尽管 Deformable 卷积在一定程度上可缓解该问题,但其可变的 kernel 形态会削弱卷积本身的归纳偏置,进而降低对局部特征的感知能力。由此可见,如何在确保强归纳偏置的基础上,让纯卷积网络拥有与 Transformer 和 Mamba 相当的动态全局建模能力,成为亟待解决的关键问题。
方法:赋予视觉骨干网络人类视觉的「两步走」认知机制
研究团队从神经科学中获取灵感,借鉴人类视觉皮层通过 Top-down Attention 实现 “先整体认知,后细节分析”(Overview-first-Look-Closely-next)的信息处理模式,创新性地突破传统视觉骨干网络的经典金字塔架构,提出深度阶段分解(DDS, Deep-stage Decomposition)策略,构建了包含三大子模型的全新视觉骨干网络体系:
- Base-Net:底层特征的高效感知模块
类比视觉系统的 “视网膜”,Base-Net 专注于中低层特征提取。它采用 UniRepLKNet 中的 Dilated RepConv Layer 作为 token mixer(令牌混合器),通过空洞卷积的扩张特性扩大感受野,同时保留卷积操作的局部归纳偏置,实现对图像基础信息的高效捕捉。 - Overview-Net:全局语义的快速提取模块
该模块负责生成粗糙但关键的高级语义信息,模拟人类视觉 “第一眼认知” 的过程。同样基于 Dilated RepConv Layer 构建 token mixer,Overview-Net 能够快速聚合全局上下文,输出 high-level 语义信息,作为后续精细分析的先验指导(Top-down Guidance)。 - Focus-Net:全局引导下的细节增强模块
在 Overview-Net 输出的 Top-down Guidance 驱动下,Focus-Net 实现 “凝视观察” 式的精细特征分析。其核心由ContMix 动态卷积和Gate 机制构成:前者通过动态调整卷积核形态,自适应捕捉不同尺度特征;后者则基于全局语义指导,选择性地增强或抑制局部特征。这种设计确保 Focus-Net 既能利用全局先验优化局部分析,又能维持强归纳偏置,避免特征过度泛化。
Top-down Guidance 的动态引导机制
Overview-Net 生成的 Top-down Guidance 并非静态传递,而是通过多层次、持续性的交互深度融入 Focus-Net:
- 权重与门控协同:在每个 Focus-Net 模块中,Top-down Guidance 同时参与动态卷积核权重的生成与 Gate 机制的计算,确保卷积操作与全局语义对齐;
- 特征融合强化:通过将 Top-down Guidance 直接整合至特征图(feature map),Focus-Net 能够持续更新特征表示,逐步增强对复杂场景的鲁棒性,最终实现超越传统视觉骨干网络的性能表现。
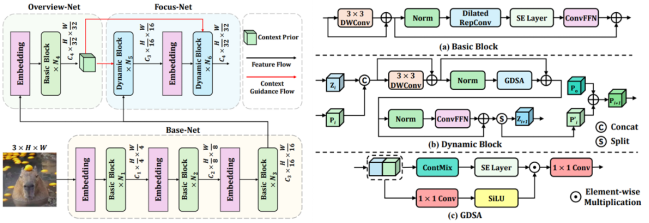
图 1: OverLoCK 模型整体框架和基本模块
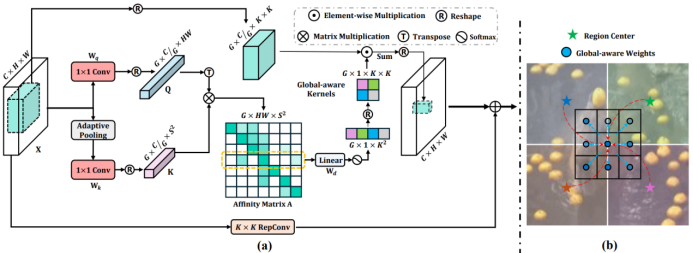
图 2: ContMix 框架图
具有强大 Context-Mixing 能力的动态卷积 ——ContMix
在计算机视觉领域,模型对于不同分辨率输入的适应性,以及在处理过程中维持强大归纳偏置的能力,始终是研究的重点方向。尤其是在充分利用如 Overview - Net 所提供的 Top - down Guidance 这类高层语义信息时,现有卷积方法存在明显不足。为攻克这些难题,研究团队匠心独运,提出了全新的动态卷积模块 ——ContMix。
ContMix 的核心创新之处,在于其独有的全局上下文关联建模方式。在特征图中,每个 token(可理解为特征的基本单元)与多个区域的中心 token 之间的关系,通过计算 affinity map(亲和图)得以清晰表征。这种亲和图精准地描绘出该 token 与全局上下文的紧密联系。在此基础上,借助可学习的转换机制,将亲和图巧妙地转化为动态卷积核。值得一提的是,全局上下文信息并非简单附加,而是被深度融入到卷积核内部的每一个权重之中。如此一来,当动态卷积核以滑动窗口的经典方式作用于特征图时,每一个 token 在局部操作的同时,都能与丰富的全局信息实现深度调制。即使是在局部窗口内进行常规操作,ContMix 也展现出了令人惊叹的全局建模能力,突破了传统卷积操作在局部与全局信息融合上的瓶颈。
在实验探索阶段,研究人员针对动态卷积核的生成方式进行了细致研究。他们尝试了多种策略,最终发现,将当前输入的 feature map 作为 query(查询),并把 Overview - Net 输出的 Top - down Guidance 作为 key(键)来计算动态卷积核,相较于其他方式,如使用二者级联得到的特征生成 query/key pairs,能够获得更为优异的性能表现。这种方式不仅更有效地利用了 Top - down Guidance 中的高层语义信息,还让模型在处理复杂视觉任务时,展现出更强的适应性和准确性,为构建高性能视觉基础模型提供了有力支撑 。
实验结果
图像分类
在大规模图像分类任务中,OverLoCK 展现出了卓越性能。以极具代表性的 ImageNet-1K 数据集测试为例,OverLoCK 相较于现存多种方法,优势显著,在性能与资源利用的权衡上表现更为出色。
在同等参数量条件下,OverLoCK 对先前大核卷积网络 UniRepLKNet 实现了大幅超越。参数量是衡量模型复杂度与资源占用的关键指标,在二者相当的情况下,OverLoCK 的性能提升,充分彰显了其架构设计与算法优化的先进性。举例来说,在处理复杂场景图像时,UniRepLKNet 可能因对全局与局部信息的融合不够高效,导致分类偏差;而 OverLoCK 凭借创新的动态卷积机制 ContMix,能够精准捕捉图像中各元素的全局上下文联系,将这些信息融入卷积核权重,进而在分类任务中做出更准确判断。
与基于 Gate 机制构建的卷积网络 MogaNet 相比,OverLoCK 的优势同样明显。MogaNet 的 Gate 机制在信息筛选与传递过程中,存在一定局限性,在面对多样复杂的图像数据时,难以充分挖掘关键特征并抑制冗余信息。反观 OverLoCK,其特有的深度阶段分解(DDS)策略,通过 Base-Net、Overview-Net 和 Focus-Net 三个子网络的协同运作,模拟人类视觉的 “先全局、后细节” 认知模式。Overview-Net 生成的 Top-down Guidance,能在特征和卷积核权重层面,为 Focus-Net 的精细分析提供强有力的语义引导,使模型在 ImageNet-1K 图像分类中,无论是对常见场景还是罕见场景的图像,均能实现更精准分类,性能远超 MogaNet 。
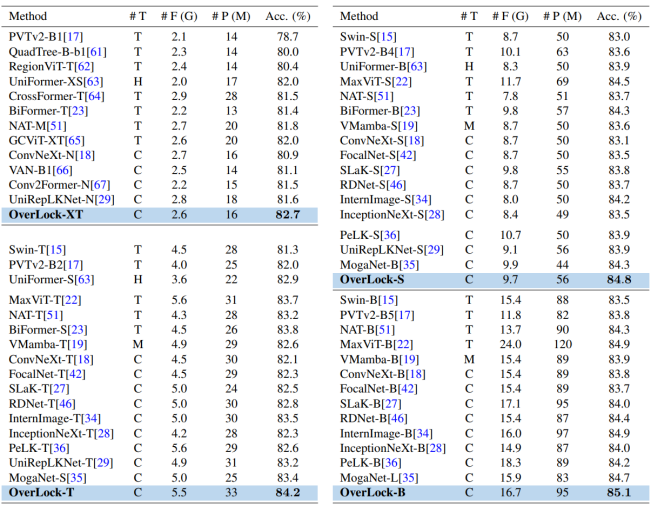
表 1: ImageNet-1K 图像分类性能比较
目标检测和实例分割
如下表2所示,在 COCO 2017 数据集的检验下,OverLoCK 的优异性能得到了进一步的有力证明。从表 2 的数据来看,当以 Mask R-CNN (1× Schedule) 作为基本框架进行实验时,OverLoCK-S 展现出了令人瞩目的优势。在关键的 APb 指标上,它分别比 BiFormer-B 和 MogaNet-B 提升了 0.8% 和 1.5%。这意味着在目标检测和实例分割任务中,OverLoCK-S 能够更精准地识别和定位目标物体,显著提高了检测的精度和可靠性。
而当切换到 Cascade Mask R-CNN 框架时,OverLoCK-S 的表现依然出色,相较于 PeLK-S 和 UniRepLKNet-S,分别实现了 1.4% 和 0.6% 的 APb 提升。这充分说明,无论采用何种主流的目标检测框架,OverLoCK-S 都能够凭借其独特的架构和算法设计,发挥出强大的性能优势。
特别值得关注的是,在图像分类任务中,基于卷积网络的方法与 Transformer 类方法的表现常常难分伯仲。然而,一旦进入检测任务领域,两者之间的性能差距就会明显显现。以 MogaNet-B 和 BiFormer-B 为例,它们在 ImageNet-1K 数据集上均能达到 84.3% 的 Top-1 准确率,这表明它们在图像分类方面具备相当的能力。但在检测任务中,MogaNet-B 的性能却明显落后于 BiFormer-B。这一现象深刻地反映了传统卷积网络存在的固有缺陷 —— 固定尺寸的卷积核限制了感受野的大小,当面对高分辨率的输入图像时,这种局限性会导致模型难以捕捉到足够的长距离依赖关系,进而影响检测性能。
与之形成鲜明对比的是,OverLoCK 网络凭借其创新的设计,成功克服了这一难题。即使在大分辨率的复杂场景下,OverLoCK 也能够有效地捕捉长距离依赖关系,实现对图像中各个元素之间复杂关系的准确理解和建模。这使得 OverLoCK 在检测任务中表现卓越,不仅能够精准定位目标物体,还能更好地处理物体之间的相互关系和遮挡情况,从而在 COCO 2017 数据集上取得了优异的成绩,有力地验证了其在目标检测领域的先进性和实用性。
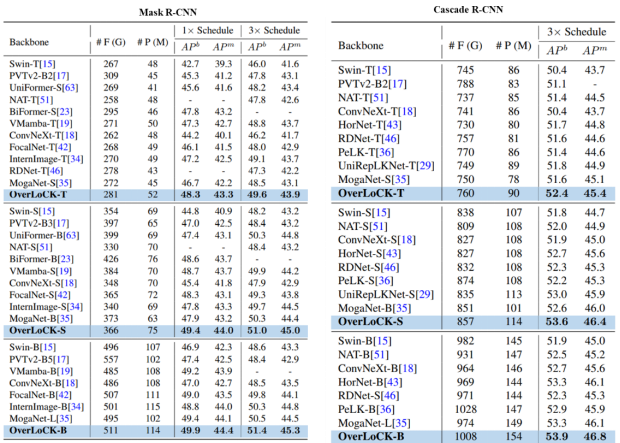
表 2: 目标检测和实例分割性能比较
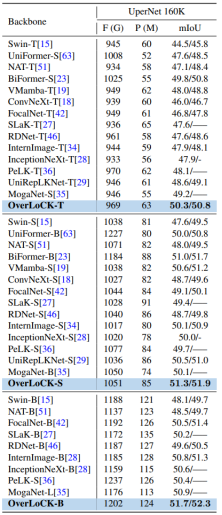
表 3: 语义分割性能比较
语义分割:突破全局建模瓶颈的卓越表现
如上表3所示,在语义分割领域的权威测试平台 ADE20K 数据集上,OverLoCK 模型展现出了超越主流视觉骨干网络的卓越性能。从表 3 的实验数据可见,OverLoCK 在精度与效率的权衡上达到了新高度:以轻量化版本 OverLoCK-T 为例,其在平均交并比(mIoU)指标上,分别以 1.1%、1.7% 的优势超越 MogaNet-S 与 UniRepLKNet-T;面对以全局建模能力著称的 VMamba-T,OverLoCK-T 更是实现了 2.3% 的显著性能提升。这一结果表明,无论是处理复杂场景的类别分割,还是应对精细结构的像素级标注,OverLoCK 都能通过创新的深度阶段分解策略,精准捕捉图像中各区域的语义关联,有效避免传统模型因局部信息局限导致的分割误差。
消融研究:ContMix 模块的即插即用优势
作为 OverLoCK 的核心创新组件,ContMix 动态卷积模块展现出强大的泛化与适配能力。通过构建基于不同 token mixer 的金字塔架构对比实验(见表 4),研究团队验证了 ContMix 在语义分割任务中的显著优势。尤其在高分辨率输入场景下,ContMix 凭借其独特的全局上下文建模机制,能够动态调整卷积核权重,实现对长距离依赖关系的高效捕捉。相较于传统大核卷积或固定形态的 token mixer,ContMix 不仅避免了因固定感受野导致的信息缺失,还通过 Top-down Guidance 的深度融合,增强了对复杂语义结构的理解能力。这种即插即用特性使 ContMix 可无缝集成至多种视觉骨干网络,为后续模型优化提供了极具潜力的模块化解决方案。如需了解更多实验细节与参数分析,可查阅论文原文获取完整技术解析。
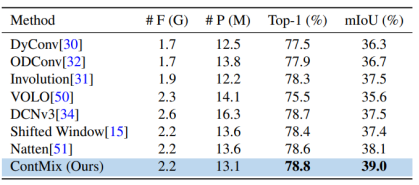
表 4 不同 token mixer 的性能比较
可视化研究
有效感受野对比:展现独特优势
在视觉骨干网络的性能评估中,有效感受野是一项关键指标。通过对不同 vision backbone 网络的深入分析可以发现,如图 3 所示,OverLoCK 展现出了独一无二的优势。它不仅拥有最大的感受野,能够捕捉到更广阔范围内的图像信息,从而对全局场景有更全面的理解;同时,还具备显著的局部敏感度,能够精准聚焦于图像的细节之处,不放过任何细微的特征变化。这种全局与局部兼顾的能力是其他网络难以企及的,其他网络往往在追求大感受野时牺牲了局部敏感度,或者在注重局部细节时无法兼顾更广泛的场景信息,而 OverLoCK 成功地实现了两者的完美平衡。
Top-down Guidance 可视化:验证设计合理性
为了更直观地展现 Top-down Guidance 在 OverLoCK 模型中的作用效果,我们采用了 Grad-CAM 技术,对 Overview-Net 与 Focus-Net 生成的特征图进行了细致的对比分析。从图 4 中可以清晰地看到,Overview-Net 首先对目标物体进行了粗粒度的定位,勾勒出了目标物体在图像中的大致位置和范围。当这一信号作为 Top-down Guidance 注入到 Focus-Net 后,发生了显著的变化:目标物体的空间定位变得更加精准,轮廓特征也得到了极大的精细化。原本较为模糊的边界变得清晰可辨,物体的细节特征也更加突出。这一过程与人类视觉中的 Top-down Attention 机制高度相似,人类在观察事物时,也是先对整体有一个初步的认知,然后再在这个基础上对细节进行深入的分析和处理。OverLoCK 通过这种设计,模拟了人类的视觉认知过程,有效地提升了模型对图像的理解和处理能力,有力地印证了其设计的合理性和科学性。
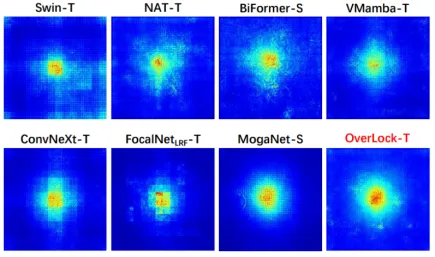
图 3: 有效感受野比较

图 4: Top-down guidance 可视化


















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









