






在现代社会,每日通勤道路交通构成了城市与社会运转的重要脉络。无数车辆在道路上川流不息,承载着人们的出行需求与经济活动的活力。而这一切平稳安全运行的基础,便是安全平稳的路面。然而,传统道路路面的日常巡检、养护与维修工作面临着诸多挑战,亟待借助新兴技术实现突破。长期以来,道路养护工作主要依赖专业的施工团队进行例行巡护。他们肩负着检查路面状况、及时发现并处理问题的重任。但专业化的运行模式存在明显的局限性。一方面,专业化运行成本相对较高,需要投入大量的人力、物力和时间成本来维持日常巡检工作。专业的养护人员需要定期对道路进行巡查,这不仅耗费人力,还受到诸多因素的制约。例如,恶劣的气象条件如暴雨、暴雪、大雾等,会严重影响巡检工作的开展,导致无法做到实时高效全天候的作业。在这样的情况下,路面出现的潜在安全隐患可能无法及时被发现并处理,从而给道路交通安全带来威胁。
随着 AI 智能化技术的快速发展和普及,传统道路交通养护行业迎来了变革的契机。越来越多的传统行业开始引入 AI 智能化技术来赋能生产作业,道路交通养护也不例外。我们可以充分利用道路两侧已经安装好的大量摄像头设备,这些摄像头原本用于交通监控等用途,如今可以发挥更大的价值。通过这些摄像头采集路面图像数据,为后续的智能化处理提供基础数据支持。接下来,由专业的标注团队对采集到的路面图像数据进行标注处理。标注工作是智能化检测识别模型开发的关键环节,标注团队需要对图像中的各种路面状况进行精准标注,例如坑洞、裂缝等常见问题。这些标注好的数据将作为训练素材,用于开发构建智能化的检测识别模型。通过深度学习等先进算法,模型能够学习到不同路面问题的特征,从而具备对路面状况进行智能检测分析的能力。当模型开发完成后,将其部署在边缘端算力设备上面。边缘端算力设备能够实时处理来自路面两侧摄像头传入的画面,对当前路面进行智能检测分析。这一过程实现了对路面状况的实时监测,一旦发现路面出现坑洞、裂缝等问题,系统能够迅速做出反应,及时发出隐患预警信息。这些预警信息会被发送到中央端,由中央端根据预警情况发送作业指令到专业的运营团队。运营团队接到指令后,可以迅速采取后续处理措施,如安排维修人员前往现场进行修复等。
本文正是在这样的思考背景下,想要从实验的角度来探索构建道路交通场景下的路面坑洼开裂等病害缺陷智能化检测识别系统,在前文中我们已经进行了相关的开发实践,感兴趣的话可以自行移步阅读即可:
《AI赋能道路巡检开启智慧养护新纪元,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建道路交通场景下水泥路面坑洼开裂缺陷智能检测识别系统》
《AI赋能道路巡检开启智慧养护新纪元,基于YOLOv7全系列【tiny/l/x】参数模型开发构建道路交通场景下水泥路面坑洼开裂缺陷智能检测识别系统》
《AI赋能道路巡检开启智慧养护新纪元,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建道路交通场景下水泥路面坑洼开裂缺陷智能检测识别系统》
《AI赋能道路巡检开启智慧养护新纪元,基于YOLOv9全系列【yolov9/t/s/m/c/e】参数模型开发构建道路交通场景下水泥路面坑洼开裂缺陷智能检测识别系统》
《AI赋能道路巡检开启智慧养护新纪元,基于YOLOv10全系列【n/s/m/b/l/x】参数模型开发构建道路交通场景下水泥路面坑洼开裂缺陷智能检测识别系统》
《AI赋能道路巡检开启智慧养护新纪元,基于YOLOv11全系列【n/s/m/l/x】参数模型开发构建道路交通场景下水泥路面坑洼开裂缺陷智能检测识别系统》
本文主要是想要基于YOLO系列最新的目标检测模型YOLOv12全系列的模型来进行相应的开发实践,首先看下实例效果:
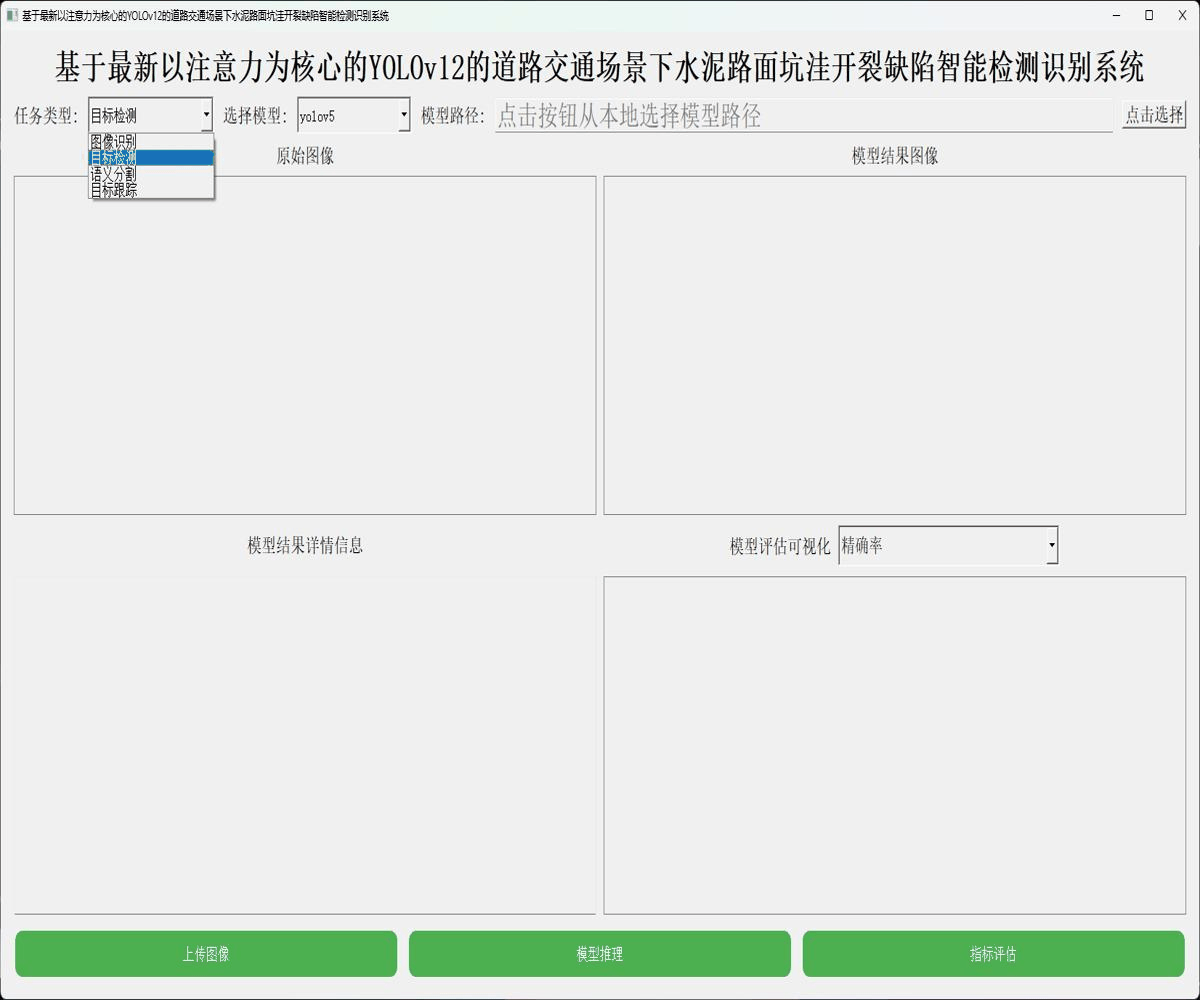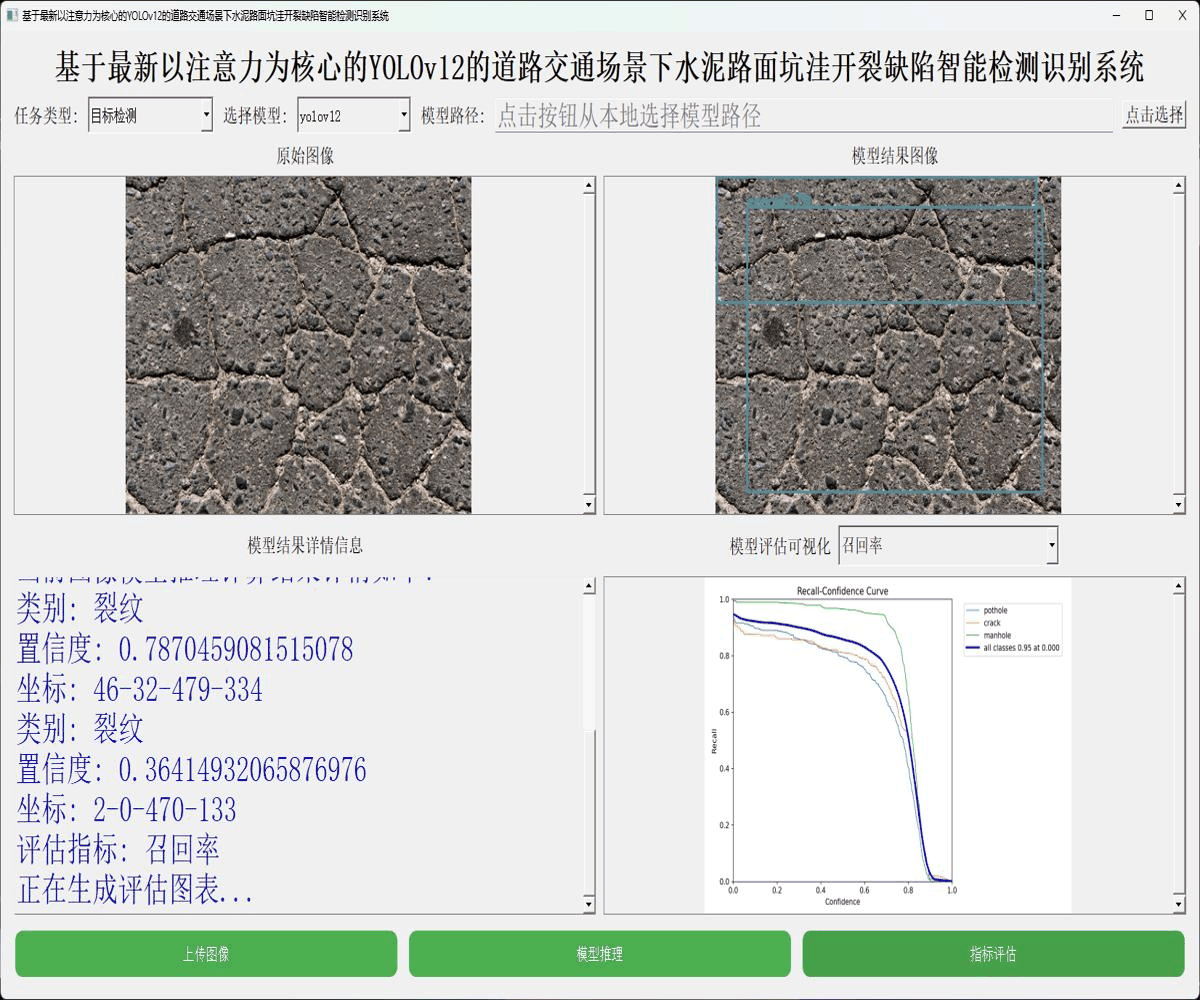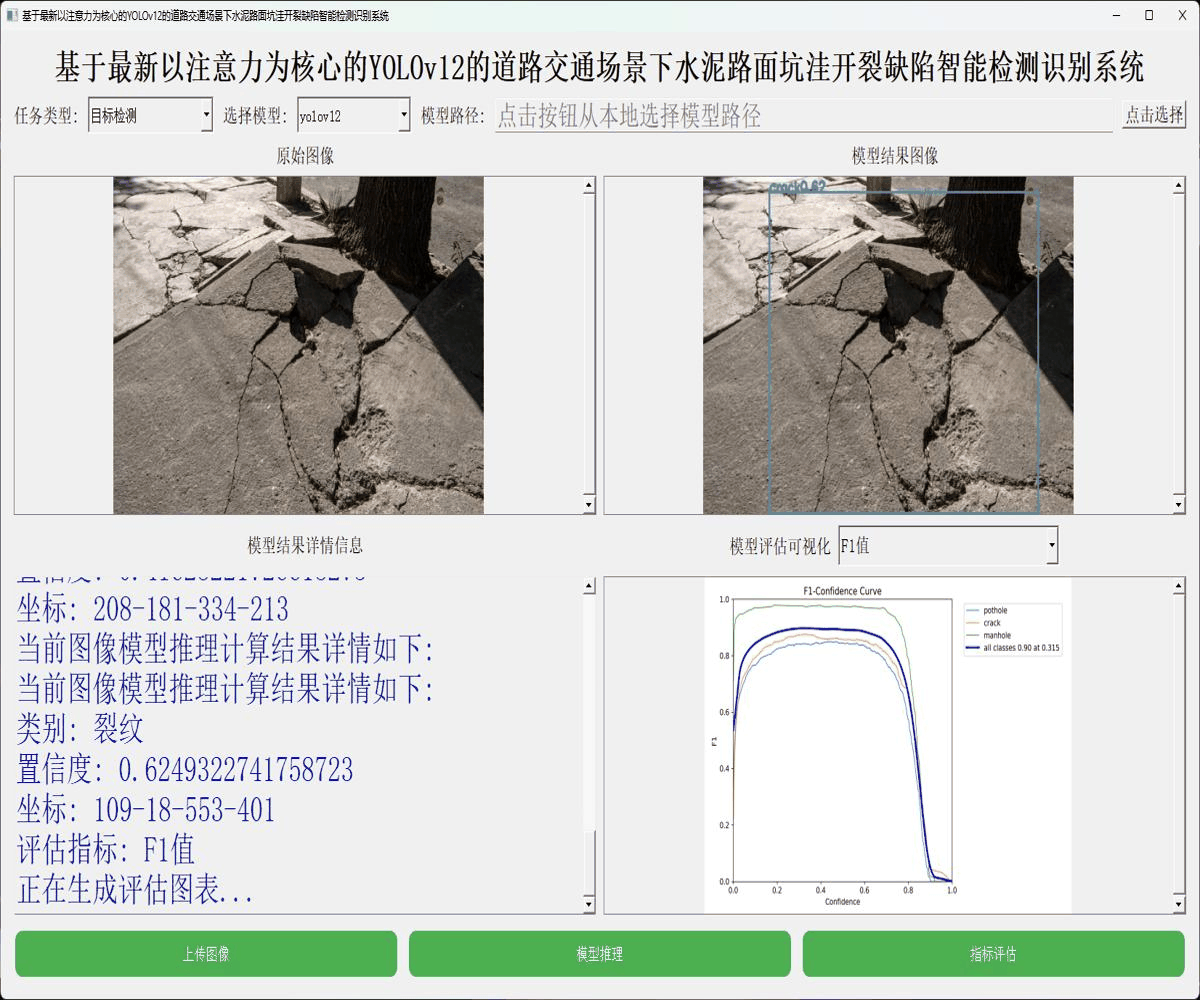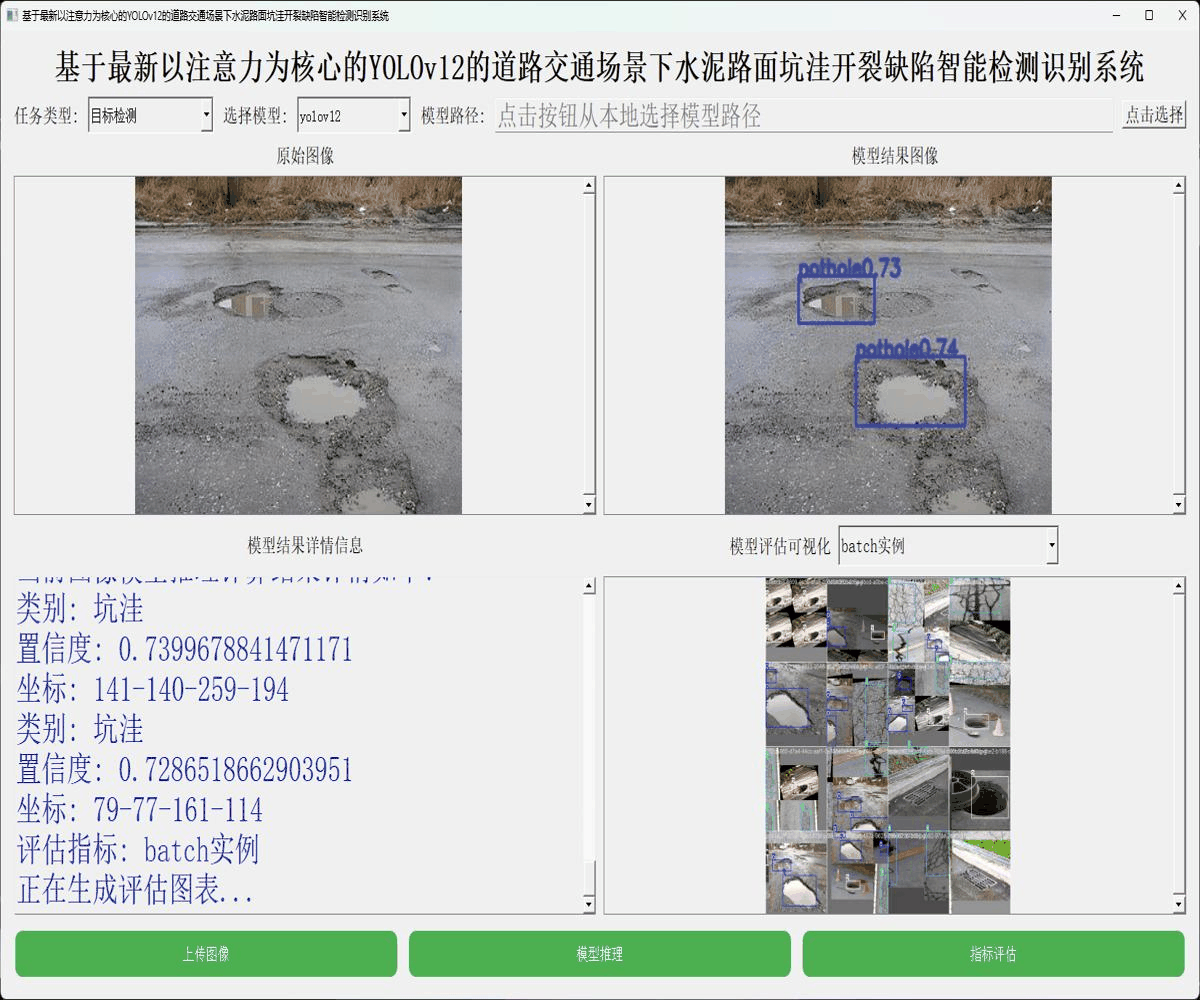
接下来看下实例数据:
YOLO系列最近的迭代速度不可谓不快,可能感觉YOLOv11都还没有推出多久,YOLOv12就这么水灵灵地来了,下面是对YOLOv12论文的阅读记录,感兴趣的话可以自行移步阅读即可:
官方发布的预训练权重如下:
Turbo (default version):
| Model | size (pixels) | mAPval 50-95 | Speed T4 TensorRT10 | params (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLO12n | 640 | 40.4 | 1.60 | 2.5 | 6.0 |
| YOLO12s | 640 | 47.6 | 2.42 | 9.1 | 19.4 |
| YOLO12m | 640 | 52.5 | 4.27 | 19.6 | 59.8 |
| YOLO12l | 640 | 53.8 | 5.83 | 26.5 | 82.4 |
| YOLO12x | 640 | 55.4 | 10.38 | 59.3 | 184.6 |
v1.0:
| Model | size (pixels) | mAPval 50-95 | Speed T4 TensorRT10 | params (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLO12n | 640 | 40.6 | 1.64 | 2.6 | 6.5 |
| YOLO12s | 640 | 48.0 | 2.61 | 9.3 | 21.4 |
| YOLO12m | 640 | 52.5 | 4.86 | 20.2 | 67.5 |
| YOLO12l | 640 | 53.7 | 6.77 | 26.4 | 88.9 |
| YOLO12x | 640 | 55.2 | 11.79 | 59.1 | 199.0 |
一共提供了n、s、m、l和x五款不同参数量级的模型。
这里我们保持完全相同的实验参数设置来进行四款模型的开发训练,等待训练完成之后我们来整体进行各项指标的对比分析。
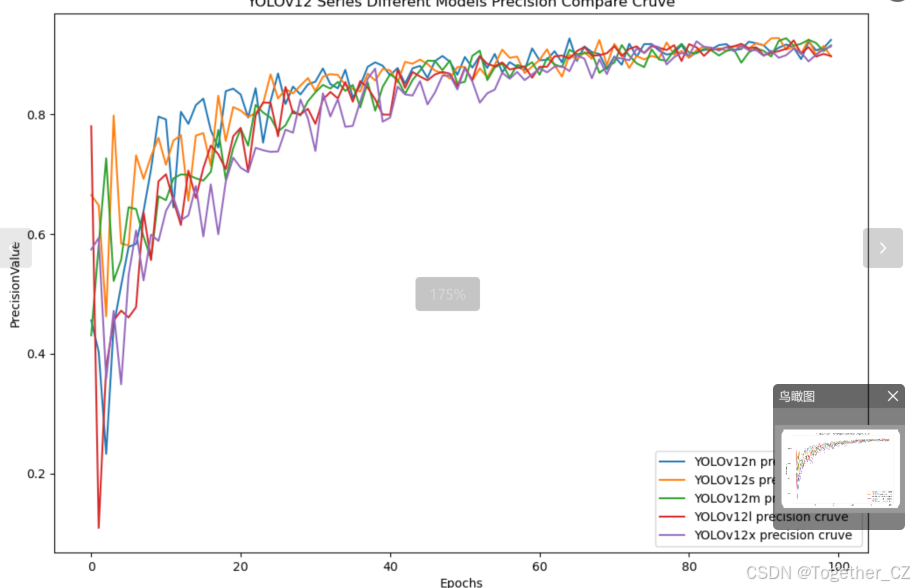
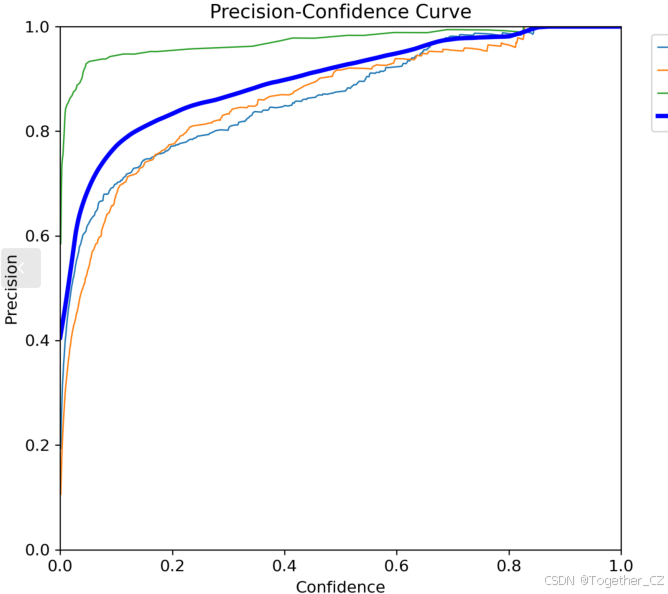
【Precision曲线】
精确率曲线(Precision Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
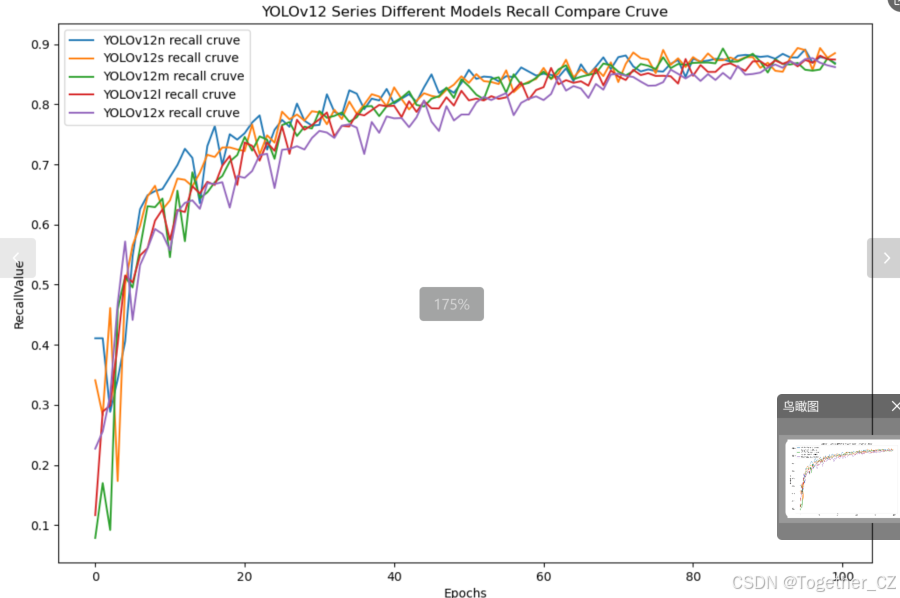
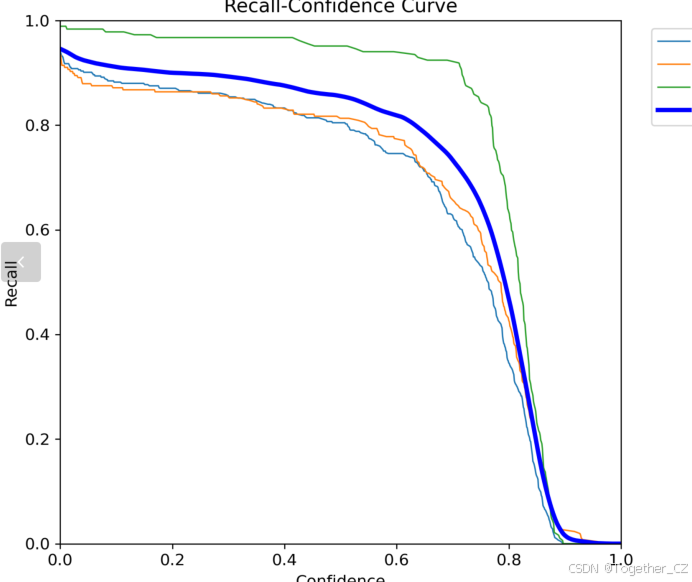
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
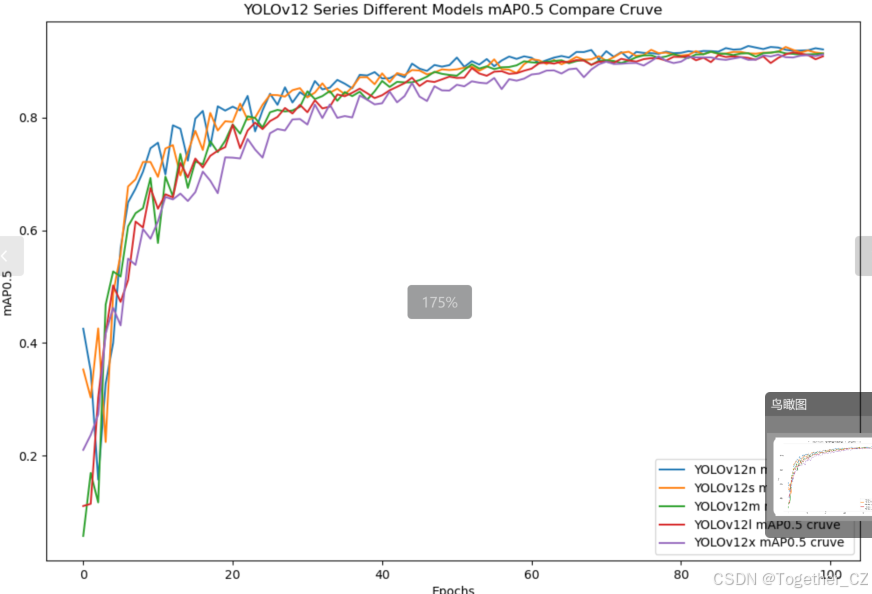
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
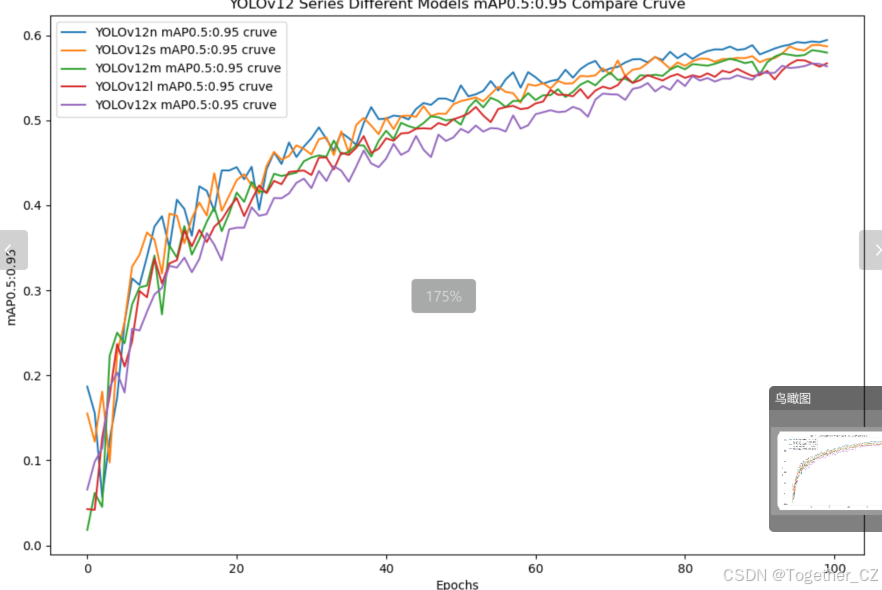
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
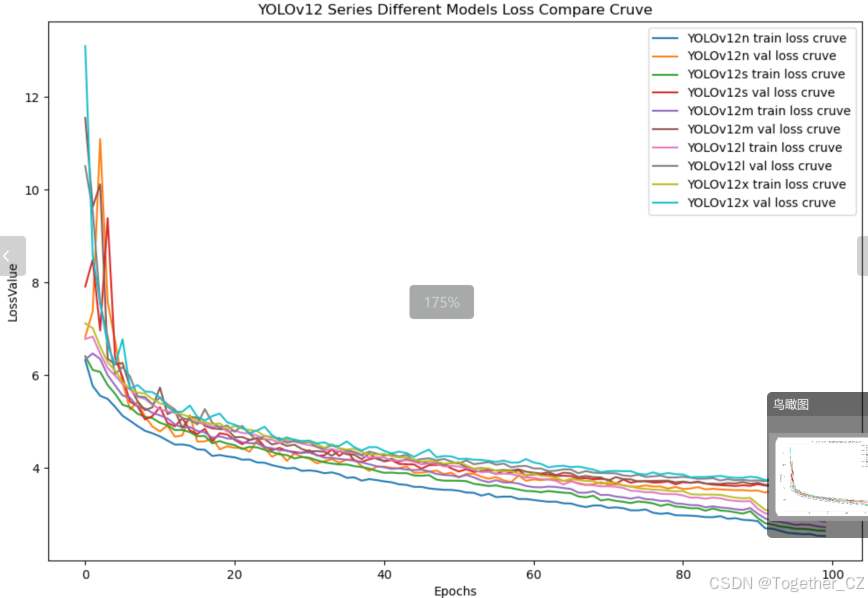
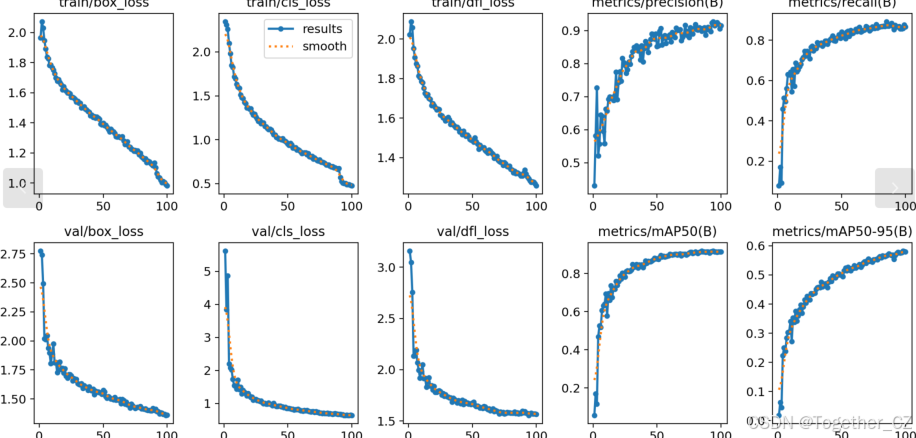
【loss曲线】
在深度学习的训练过程中,loss函数用于衡量模型预测结果与实际标签之间的差异。loss曲线则是通过记录每个epoch(或者迭代步数)的loss值,并将其以图形化的方式展现出来,以便我们更好地理解和分析模型的训练过程。
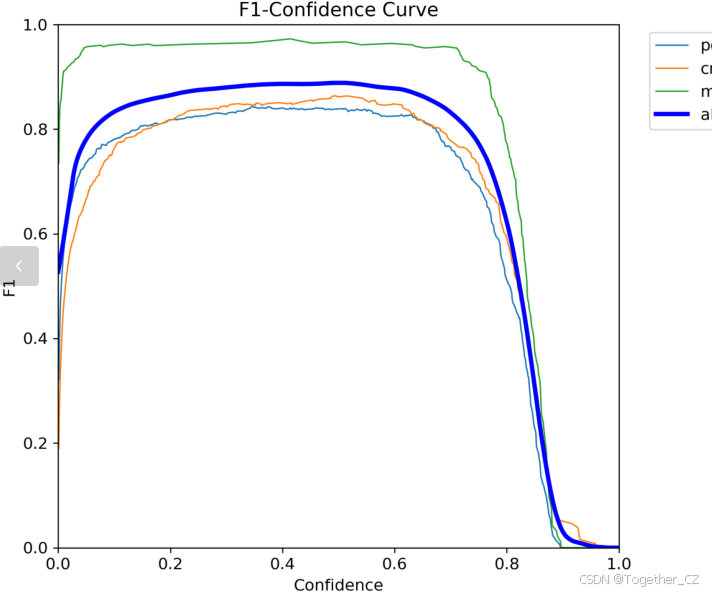
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
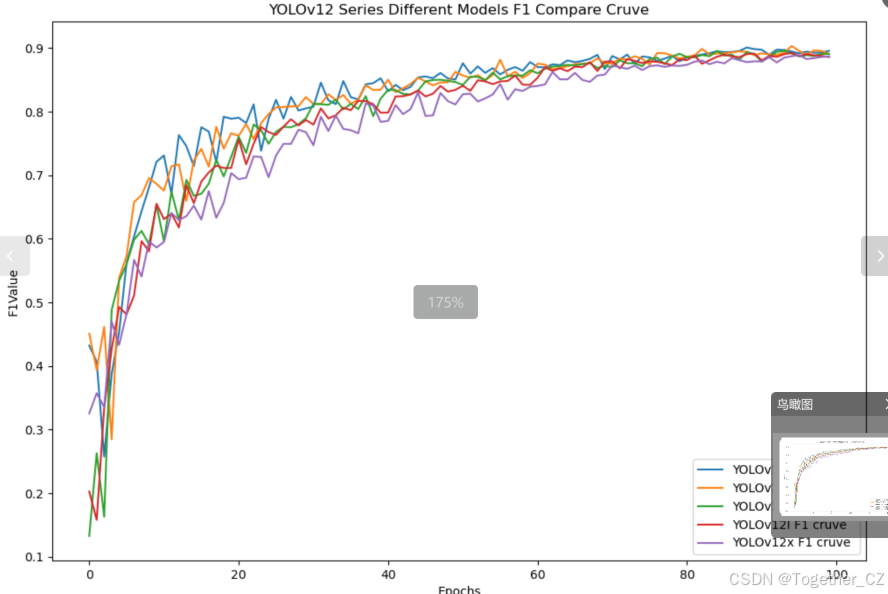
整体对比分析来看:不难发现五款不同参数量级的模型最终达到了较为相似的结果,没有拉开非常大的差距,这里综合参数量考虑我们最终选定了s系列的模型来作为线上的推理计算模型。
接下来看下s系列模型的详细情况。
【离线推理实例】

【Batch实例】

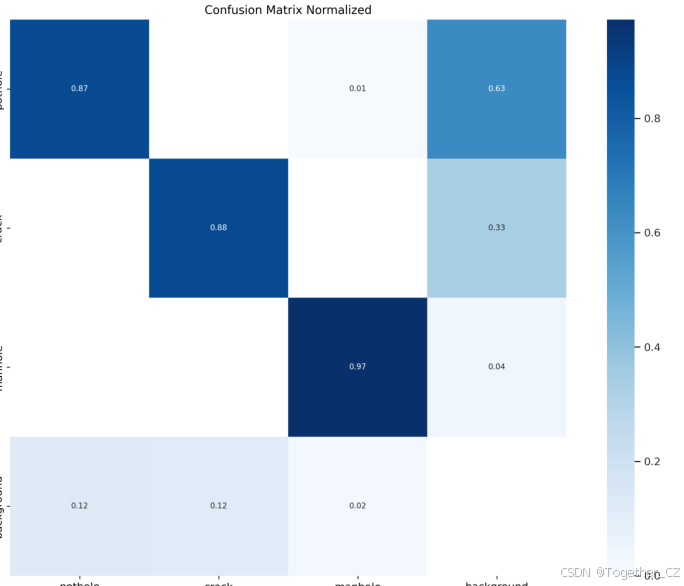
【混淆矩阵】
【F1值曲线】
【Precision曲线】
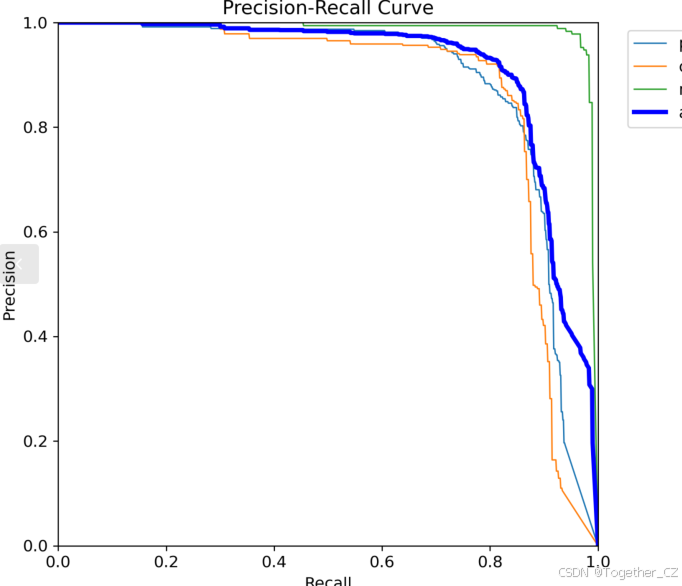
【PR曲线】
【Recall曲线】
【训练可视化】
感兴趣的话也都可以自行动手尝试下!本文仅作为抛砖引玉,从实验的角度进行基础的实践开发尝试,距离真正落地应用还有很长的路要走,不过科技发展的趋势就应该是赋能作业生产,提质增效的同时降低安全隐患。借助这一智能化的道路交通养护模式,能够显著提升人工作业精度。以往依赖人工巡检时,由于受到多种因素影响,可能存在漏检、误检等情况,而智能化检测识别模型能够以更高的精度和稳定性进行检测。同时,这一模式还能有效降低庞大作业队伍的用人成本。传统养护工作中需要大量人力进行日常巡检,现在通过智能化手段,部分巡检工作可以由系统自动完成,从而减少了对人力的依赖,降低了人力成本。智能化赋能道路交通养护,不仅提升了养护工作的效率和质量,更为道路交通安全提供了有力保障。未来,随着 AI 技术的进一步发展和应用深化,道路交通养护行业有望实现更加智能化、高效化和安全化的运行模式,为人们的出行创造更加优质的道路环境。



















 2249
2249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











