






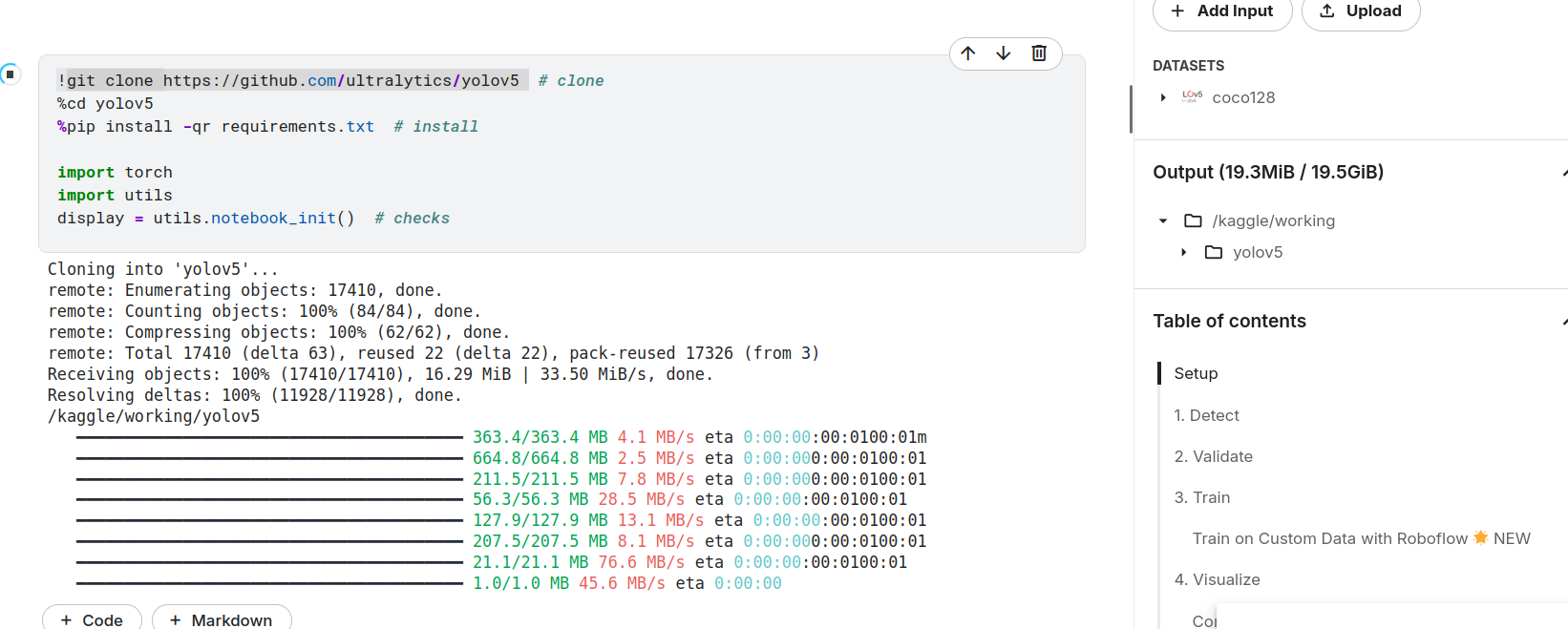
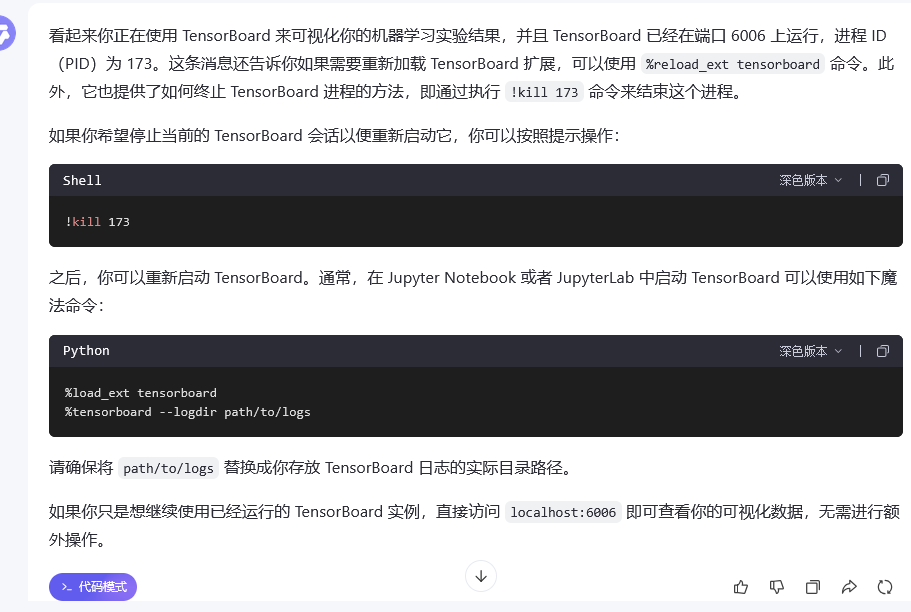
 看源码
看源码

直接用的githuab的源码,git clone 后output才有文件
直接gitclone他的源码用Vscode看(也可以直接把jupyter下下来)
好久没见过16g了
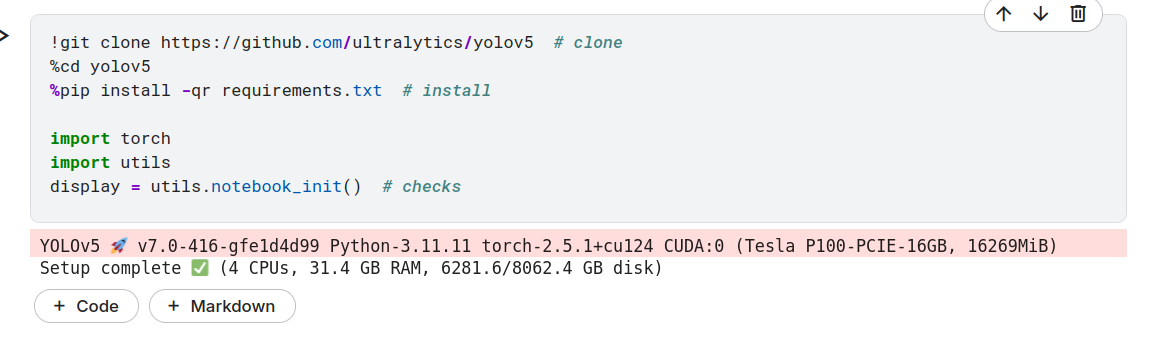
 怎么这么便宜
怎么这么便宜

detect.py
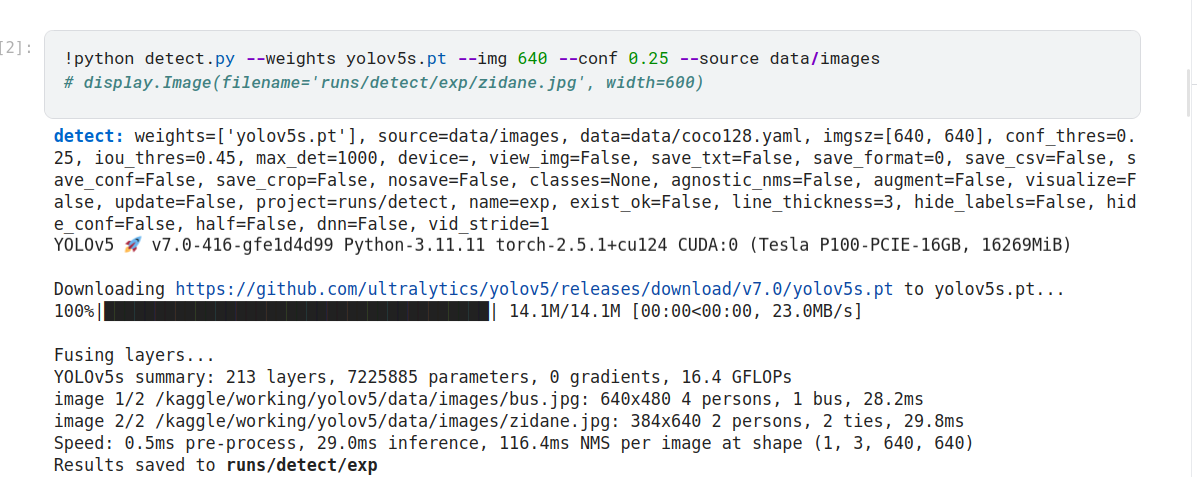
好的,从您提供的信息来看,您正在使用 YOLOv5 进行目标检测任务。以下是运行结果的详细解读:
运行配置
模型权重: 使用了预训练的 yolov5s.pt 模型(小型版本)。
数据源: 图片路径为 data/images。
数据集配置文件: data/coco128.yaml。
输入图片尺寸: [640, 640](模型会将图片缩放到此尺寸进行推理)。
置信度阈值 (conf_thres): 0.25(仅保留置信度高于此阈值的检测结果)。
IoU 阈值 (iou_thres): 0.45(用于非极大值抑制 NMS,过滤重叠框)。
最大检测目标数 (max_det): 1000。
设备: 默认使用 GPU(CUDA:0,Tesla P100-PCIE-16GB)。
保存选项:
未启用可视化窗口 (view_img=False)。
未保存识别结果为文本文件 (save_txt=False)。
未保存置信度分数 (save_conf=False)。
未保存裁剪的目标图片 (save_crop=False)。
其他设置:
结果保存路径为 runs/detect/exp。
线条粗细为 3 (line_thickness=3)。
未隐藏标签和置信度 (hide_labels=False, hide_conf=False)。
运行结果
模型加载与优化:
下载并加载了 yolov5s.pt 模型权重。
融合了部分层以优化推理速度。
模型总结:
层数:213
参数量:7,225,885
FLOPs:16.4 GFLOPs
图片检测:
第一张图片:
路径: /kaggle/working/yolov5/data/images/bus.jpg
尺寸: 640x480
检测结果:
4 个人 (person)
1 辆公交车 (bus)
推理时间: 28.2ms
第二张图片:
路径: /kaggle/working/yolov5/data/images/zidane.jpg
尺寸: 384x640
检测结果:
2 个人 (person)
2 条领带 (tie)
推理时间: 29.8ms
性能指标:
预处理时间: 0.5ms
推理时间: 29.0ms
NMS 时间: 116.4ms
总体来看,模型在单张图片上的平均推理速度较快。
结果保存:
检测结果已保存到 runs/detect/exp 文件夹中。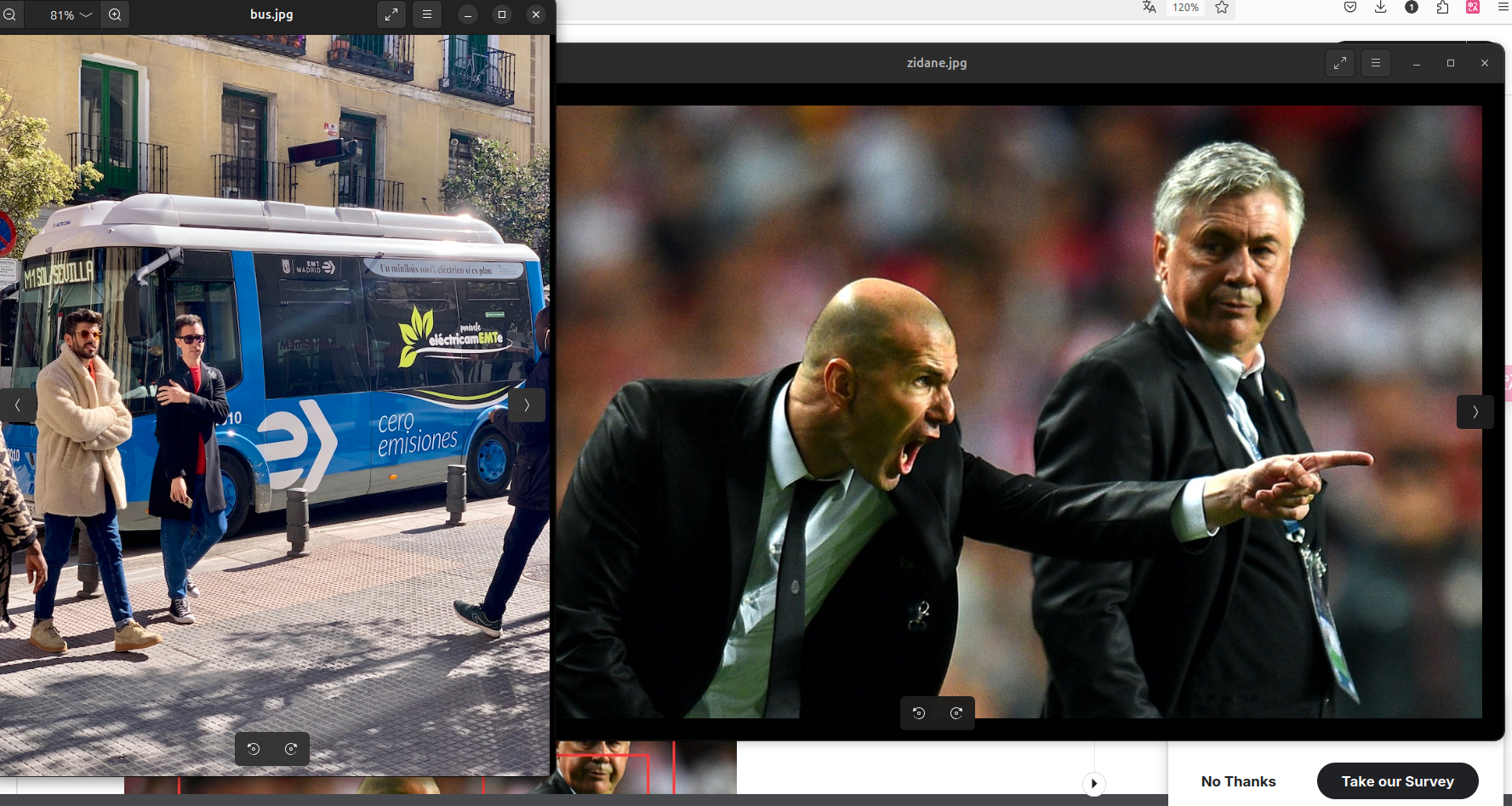

函数输入有一页
推理循环
seen, windows, dt = 0, [], (Profile(device=device), Profile(device=device), Profile(device=device))
for path, im, im0s, vid_cap, s in dataset:
# 预处理
with dt[0]:
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
if model.xml and im.shape[0] > 1:
ims = torch.chunk(im, im.shape[0], 0)
# 推理
with dt[1]:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
if model.xml and im.shape[0] > 1:
pred = None
for image in ims:
if pred is None:
pred = model(image, augment=augment, visualize=visualize).unsqueeze(0)
else:
pred = torch.cat((pred, model(image, augment=augment, visualize=visualize).unsqueeze(0)), dim=0)
pred = [pred, None]
else:
pred = model(im, augment=augment, visualize=visualize)
# 非极大值抑制
with dt[2]:
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
对每个输入数据进行预处理、推理和非极大值抑制操作,记录各阶段耗时。
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f"{i}: "
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, "frame", 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / "labels" / p.stem) + ("" if dataset.mode == "image" else f"_{frame}") # im.txt
s += "{:g}x{:g} ".format(*im.shape[2:]) # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, 5].unique():
n = (det[:, 5] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = names[c] if hide_conf else f"{names[c]}"
confidence = float(conf)
confidence_str = f"{confidence:.2f}"
if save_csv:
write_to_csv(p.name, label, confidence_str)
if save_txt: # Write to file
if save_format == 0:
coords = (
(xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()
) # normalized xywh
else:
coords = (torch.tensor(xyxy).view(1, 4) / gn).view(-1).tolist() # xyxy
line = (cls, *coords, conf) if save_conf else (cls, *coords) # label format
with open(f"{txt_path}.txt", "a") as f:
f.write(("%g " * len(line)).rstrip() % line + "\n")
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f"{names[c]} {conf:.2f}")
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / "crops" / names[c] / f"{p.stem}.jpg", BGR=True)
# Stream results
im0 = annotator.result()
if view_img:
if platform.system() == "Linux" and p not in windows:
windows.append(p)
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == "image":
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix(".mp4")) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
vid_writer[i].write(im0)
 明天看训练部分
明天看训练部分
2. Validate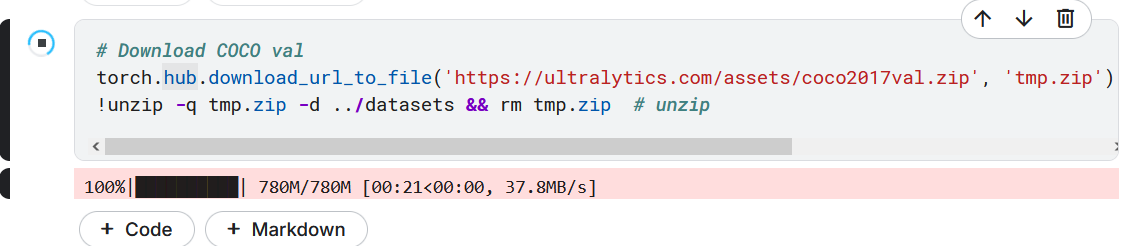
一秒40m/s的下载速度,我这破机械硬盘的读写速度都没他快 ,我又想起我熬夜2m/s网速装环境了
val: data=/kaggle/working/yolov5/data/coco.yaml, weights=['yolov5s.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False
YOLOv5 🚀 v7.0-416-gfe1d4d99 Python-3.11.11 torch-2.5.1+cu124 CUDA:0 (Tesla P100-PCIE-16GB, 16269MiB)
Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt to yolov5s.pt...
100%|██████████████████████████████████████| 14.1M/14.1M [00:00<00:00, 39.3MB/s]
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
val: Scanning /kaggle/working/datasets/coco/val2017... 4952 images, 48 backgroun
val: New cache created: /kaggle/working/datasets/coco/val2017.cache
Class Images Instances P R mAP50
all 5000 36335 0.671 0.519 0.566 0.371
Speed: 0.1ms pre-process, 2.6ms inference, 1.7ms NMS per image at shape (32, 3, 640, 640)
/usr/local/lib/python3.11/dist-packages/matplotlib/colors.py:721: RuntimeWarning: invalid value encountered in less
xa[xa < 0] = -1
Evaluating pycocotools mAP... saving runs/val/exp/yolov5s_predictions.json...
loading annotations into memory...
Done (t=0.45s)
creating index...
index created!
Loading and preparing results...
DONE (t=5.57s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=57.07s).
Accumulating evaluation results...
DONE (t=11.21s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.374
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.572
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.402
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.211
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.423
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.489
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.311
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.516
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.566
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.378
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.625
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.723
Results saved to runs/val/exp
你提供的这段日志是 **YOLOv5** 在 **COCO 数据集**上进行验证(`val`)的完整评估输出。我们可以从多个方面来分析模型的表现和运行情况。
---
## 📊 一、关键指标解读
### 🧪 模型信息
```
YOLOv5 🚀 v7.0-416-gfe1d4d99
Python-3.11.11
torch-2.5.1+cu124
CUDA:0 (Tesla P100-PCIE-16GB, 16269MiB)
```
- 使用的是 **YOLOv5s** 小型模型,适用于快速推理;
- PyTorch 版本为 **2.5.1**,支持 CUDA 12.4;
- GPU 是 **Tesla P100**,16GB 显存,性能中等偏上。
---
## 📌 验证参数设置
```bash
val: data=coco.yaml, weights=yolov5s.pt, batch_size=32, imgsz=640, ...
```
| 参数 | 值 | 含义 |
|------|-----|------|
| `data` | coco.yaml | COCO 数据集配置文件 |
| `weights` | yolov5s.pt | 使用预训练权重 |
| `imgsz` | 640 | 输入图像尺寸为 640x640 |
| `batch_size` | 32 | 每次处理 32 张图片 |
| `conf_thres` | 0.001 | 置信度阈值较低,保留更多预测框 |
| `iou_thres` | 0.6 | NMS 的 IoU 阈值 |
| `save_json` | True | 保存结果为 JSON 文件用于 COCO API 评估 |
---
## 📈 二、模型性能指标
### ✅ mAP 指标(主流目标检测评价标准)
| 指标 | 值 |
|------|----|
| mAP@[0.5:0.95] | **0.374** |
| mAP@0.5 | **0.572** |
| mAP@0.75 | **0.402** |
> 👉 这些值与官方 YOLOv5s 在 COCO 上的基准表现基本一致,说明模型表现正常,未出现明显退化。
---
### 🔍 分尺度表现(小、中、大目标)
| 目标大小 | mAP@[0.5:0.95] |
|----------|----------------|
| 小目标 | 0.211 |
| 中目标 | 0.423 |
| 大目标 | 0.489 |
✅ 表明:
- 对于小目标检测效果较弱(常见问题);
- 对中大型目标检测能力较强。
---
## ⏱️ 三、速度表现
```
Speed: 0.1ms pre-process, 2.6ms inference, 1.7ms NMS per image
```
| 阶段 | 耗时 |
|------|------|
| 预处理 | 0.1ms |
| 推理 | **2.6ms/image** |
| NMS | 1.7ms |
| **总计** | **~4.4ms/image** |
✅ 模型在 Tesla P100 上实现了 **约 227 FPS**(1 / 0.0044),属于非常快的推理速度,适合实时应用。
---
## 📁 四、输出路径与格式
```
Results saved to runs/val/exp
Evaluating pycocotools mAP... saving runs/val/exp/yolov5s_predictions.json
```
- 结果保存在 `runs/val/exp` 目录下;
- 包含 `.json` 格式的预测结果,可用于进一步分析或提交到 [COCO 官方评测平台](https://cocodataset.org/#detection-eval)。
---
## ⚠️ 五、警告信息
```
/usr/local/lib/python3.11/dist-packages/matplotlib/colors.py:721: RuntimeWarning: invalid value encountered in less
xa[xa < 0] = -1
```
⚠️ 这是一个 **非致命警告**,可能来自绘图模块(如 matplotlib)对无效数值的操作,不影响最终评估结果。可以忽略,或更新 matplotlib 到最新版本以尝试解决。
---
## ✅ 六、总结与建议
### ✅ 总体表现良好:
- 模型在 COCO val2017 上达到了预期精度;
- 推理速度快,适合部署在资源受限环境;
- 输出格式规范,便于后续集成或部署。
### 🔧 可优化方向:
1. **提升小目标检测能力**
- 使用更高分辨率输入(如 `imgsz=1280`);
- 使用 YOLOv5l/x 或其他增强模型;
- 添加多尺度训练或多尺度预测。
2. **降低置信度阈值的影响**
- 当前 `conf_thres=0.001` 很低,可能会引入很多低质量预测;
- 如果需要更精确的结果,可适当提高该值(如 `0.25`)。
3. **使用 TensorRT 或 ONNX 加速推理**
- 若需极致性能,可将模型导出为 TensorRT 引擎。
---
如果你有以下需求,我可以继续帮你深入分析:
- 修改配置文件(如 `coco.yaml`);
- 导出模型为 ONNX/TensorRT;
- 自定义数据集训练;
- 提交结果到 COCO 官网评测;
- 模型精度调优等。
你可以直接告诉我你的下一步目标 😎3. Train 3. 训练¶
Image
Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package
通过使用“roboflow”pip 包从推理条件中采样图像来关闭主动学习循环
Train a YOLOv5s model on the COCO128 dataset with --data coco128.yaml, starting from pretrained --weights yolov5s.pt, or from randomly initialized --weights '' --cfg yolov5s.yaml.
使用 --data coco128.yaml 在 COCO128 数据集上训练 YOLOv5s 模型,从预训练的 --weights yolov5s.pt 开始,或从随机初始化开始 --weights '' --cfg yolov5s.yaml 。
Pretrained Models are downloaded automatically from the latest YOLOv5 release
预训练模型会自动从最新的 YOLOv5 版本下载
Datasets available for autodownload include: COCO, COCO128, VOC, Argoverse, VisDrone, GlobalWheat, xView, Objects365, SKU-110K.
可自动下载的数据集包括:COCO、COCO128、VOC、Argoverse、VisDrone、GlobalWheat、xView、Objects365、SKU-110K。
Training Results are saved to runs/train/ with incrementing run directories, i.e. runs/train/exp2, runs/train/exp3 etc.
训练结果保存到 runs/train/ 中,并递增 run 目录,即 runs/train/exp2、runs/train/exp3 等。
A Mosaic Dataloader is used for training which combines 4 images into 1 mosaic.
Mosaic Dataloader 用于训练,将 4 张图像组合成 1 个马赛克。
Train on Custom Data with Roboflow 🌟 NEW
使用 Roboflow 🌟 NEW 在自定义数据上训练¶
Roboflow enables you to easily organize, label, and prepare a high quality dataset with your own custom data. Roboflow also makes it easy to establish an active learning pipeline, collaborate with your team on dataset improvement, and integrate directly into your model building workflow with the roboflow pip package.
Roboflow 使您能够使用自己的自定义数据轻松组织、标记和准备高质量的数据集。Roboflow 还可以轻松建立主动学习管道,与您的团队合作改进数据集,并使用 roboflow pip 软件包直接集成到您的模型构建工作流程中。
Custom Training Example: https://blog.roboflow.com/how-to-train-yolov5-on-a-custom-dataset/
自定义训练示例:https://blog.roboflow.com/how-to-train-yolov5-on-a-custom-dataset/
Custom Training Notebook: Open In Colab
自定义训练笔记本: Open In Colab
Image
Label images lightning fast (including with model-assisted labeling)
以闪电般的速度为图像添加标签(包括使用模型辅助标记)
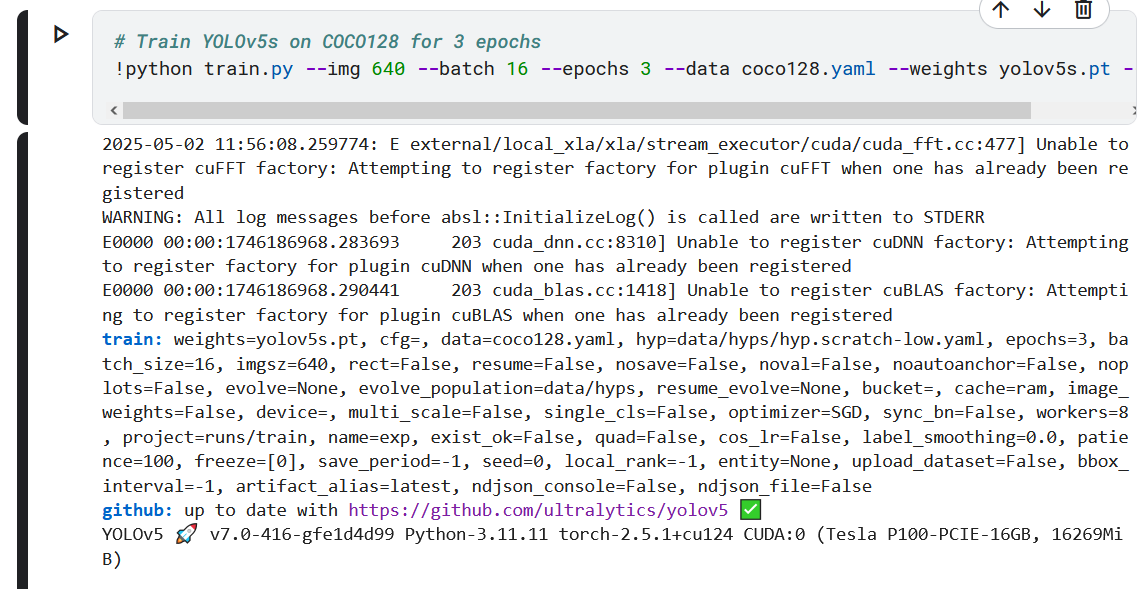
你提供的这段日志是 YOLOv5 的训练初始化输出。它展示了训练配置、环境信息以及一些警告信息。下面我会逐部分为你解读,并给出建议。
📋 一、警告信息(Warnings)
深色版本
E external/local_xla/... Unable to register cuFFT factory...
E ... Unable to register cuDNN factory...
E ... Unable to register cuBLAS factory...
✅ 解读:
这些是 TensorFlow/XLA 相关的警告,表示某些 CUDA 库(如 cuFFT、cuDNN、cuBLAS)已经被注册,但试图再次注册。
⚠️ 是否需要处理?
❌ 不需要担心:这些警告通常不影响 YOLOv5 的运行,因为 YOLOv5 使用的是 PyTorch,不是 TensorFlow。
如果你没有使用 TensorFlow,可以安全地忽略这些警告。
🧾 二、训练参数(Arguments)
bash
深色版本
train: weights=yolov5s.pt, cfg=, data=coco128.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=3, batch_size=16, imgsz=640 ...
参数 值 含义
weights yolov5s.pt 预训练模型权重
data coco128.yaml 数据集配置文件(COCO128)
hyp hyp.scratch-low.yaml 超参数配置
epochs 3 训练轮数(这里仅为3个epoch)
batch_size 16 每次训练使用的图像数量
imgsz 640 图像尺寸为 640x640
optimizer SGD 使用随机梯度下降优化器
project/name runs/train/exp 输出路径
📌 注意: 这里只设置了 3 个 epoch,可能是为了测试流程是否正常。如果要真正训练模型,建议至少设置 100~300 个 epoch。
💻 三、系统与硬件信息
深色版本
YOLOv5 🚀 v7.0-416-gfe1d4d99
Python-3.11.11
torch-2.5.1+cu124
CUDA:0 (Tesla P100-PCIE-16GB, 16269MiB)
使用的是 PyTorch 2.5.1 + CUDA 12.4;
GPU 是 Tesla P100,16GB 显存;
适合中等规模的目标检测任务。
🛠 四、超参数(Hyperparameters)
这部分列出了训练时使用的超参数:
bash
深色版本
lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005 ...
这些是标准的训练参数,适用于从头开始训练(scratch)。如果你是微调(fine-tune),可以适当降低学习率(例如 lr0=0.001)。
📈 五、可视化工具提示
深色版本
TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
你可以通过以下命令启动 TensorBoard:
bash
深色版本
tensorboard --logdir runs/train
然后在浏览器访问:http://localhost:6006/ 查看训练过程中的 loss、mAP、学习率等指标变化曲线。
🧪 六、数据增强配置(Augmentations)
bash
深色版本
hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, translate=0.1, scale=0.5, fliplr=0.5, mosaic=1.0 ...
这是图像增强策略,包括颜色扰动、平移、缩放、镜像翻转、mosaic 等。当前配置是偏强的数据增强,有助于提升泛化能力。Dataset not found ⚠️, missing paths ['/kaggle/working/datasets/coco128/images/train2017']
Downloading https://github.com/ultralytics/assets/releases/download/v0.0.0/coco128.zip to coco128.zip...
100%|██████████████████████████████████████| 6.66M/6.66M [00:00<00:00, 19.3MB/s]
Dataset download success ✅ (1.9s), saved to /kaggle/working/datasets
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model summary: 214 layers, 7235389 parameters, 7235389 gradients, 16.6 GFLOPs
Transferred 349/349 items from yolov5s.pt
/kaggle/working/yolov5/models/common.py:906: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with amp.autocast(autocast):
/kaggle/working/yolov5/models/common.py:906: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with amp.autocast(autocast):
AMP: checks passed ✅
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias
albumentations: 6 validation errors for InitSchema
p
Field required [type=missing, input_value={}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
scale
Field required [type=missing, input_value={}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
ratio
Field required [type=missing, input_value={}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
size
Field required [type=missing, input_value={}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
interpolation
Field required [type=missing, input_value={}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
mask_interpolation
Field required [type=missing, input_value={}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
train: Scanning /kaggle/working/datasets/coco128/labels/train2017... 126 images,
train: New cache created: /kaggle/working/datasets/coco128/labels/train2017.cache
train: Caching images (0.1GB ram): 100%|██████████| 128/128 [00:00<00:00, 970.08
val: Scanning /kaggle/working/datasets/coco128/labels/train2017.cache... 126 ima
val: Caching images (0.1GB ram): 100%|██████████| 128/128 [00:00<00:00, 357.81it
AutoAnchor: 4.27 anchors/target, 0.994 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Plotting labels to runs/train/exp/labels.jpg...
/usr/local/lib/python3.11/dist-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
/usr/local/lib/python3.11/dist-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.从你提供的日志来看,YOLOv5 的训练流程已经顺利开始,并且之前提到的 COCO128 数据集未找到的问题也通过自动下载解决了。以下是对你提供信息的一些分析和建议:
一、数据集处理
自动下载数据集:日志显示 YOLOv5 自动下载了 COCO128 数据集并保存到了指定路径 /kaggle/working/datasets,这表明数据集缺失问题已经被解决。
缓存创建:针对训练集和验证集,YOLOv5 创建了缓存文件(.cache),有助于加速后续的训练过程。
二、模型结构与参数
日志展示了 YOLOv5s 模型的具体架构,包括卷积层 (Conv)、CSP 层 (C3)、SPPF 层 (SPPF) 和最终的检测头 (Detect) 等组件。
总共有 214 层,7,235,389 个参数,计算量为 16.6 GFLOPs,这些指标对于评估模型复杂度和推理速度非常重要。
三、警告信息
FutureWarning: torch.cuda.amp.autocast(args...) 已被弃用,建议使用 torch.amp.autocast('cuda', args...) 替代。这是一个关于 PyTorch 版本更新带来的兼容性警告,不影响当前功能,但为了代码维护,建议更新相关调用。
Albumentations 错误: 提到有 6 个验证错误,涉及到 InitSchema 中的一些字段丢失。这可能是由于 albumentations 库版本与代码不完全匹配导致的。如果你没有特别依赖特定的数据增强策略,可以尝试忽略这些警告;否则,考虑检查你的 albumentations 配置或升级库版本。
Seaborn FutureWarning: 关于 use_inf_as_na 选项将在未来版本中移除的警告。这个警告来自 Seaborn 库,在进行数据可视化时出现,不会影响模型训练或性能。
Image sizes 640 train, 640 val
Using 4 dataloader workers
Logging results to runs/train/exp
Starting training for 3 epochs...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0%| | 0/8 [00:00<?, ?it/s]/kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
0/2 3.89G 0.04429 0.06439 0.01392 197 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
0/2 3.93G 0.04407 0.05901 0.01749 154 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
0/2 3.93G 0.04451 0.05735 0.01675 150 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
0/2 3.93G 0.04477 0.06104 0.01689 248 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
0/2 3.93G 0.04415 0.05844 0.01645 157 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
0/2 3.93G 0.04414 0.05836 0.01668 189 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
0/2 3.93G 0.04468 0.0587 0.0167 187 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
0/2 3.93G 0.04438 0.05844 0.01734 164 640: 1
Class Images Instances P R mAP50
all 128 929 0.679 0.607 0.689 0.456
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0%| | 0/8 [00:00<?, ?it/s]/kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
1/2 3.93G 0.04783 0.06814 0.01767 205 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
1/2 3.93G 0.04443 0.06214 0.01591 147 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
1/2 3.93G 0.04495 0.06298 0.01674 220 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
1/2 3.93G 0.04609 0.06947 0.01706 311 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
1/2 3.93G 0.0463 0.06815 0.01668 192 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
1/2 3.93G 0.04617 0.06753 0.01605 219 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
1/2 3.93G 0.04551 0.06469 0.01601 171 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
1/2 3.93G 0.04508 0.06348 0.01571 185 640: 1
Class Images Instances P R mAP50
all 128 929 0.74 0.61 0.712 0.472
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0%| | 0/8 [00:00<?, ?it/s]/kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
2/2 3.93G 0.04411 0.08452 0.01536 278 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
2/2 3.93G 0.0439 0.07822 0.01434 238 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
2/2 3.93G 0.04419 0.06893 0.01486 176 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
2/2 3.93G 0.04386 0.06668 0.01505 212 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
2/2 3.93G 0.04436 0.06791 0.01532 236 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
2/2 3.93G 0.04382 0.06637 0.01537 203 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
2/2 3.93G 0.04404 0.06465 0.01556 176 640: /kaggle/working/yolov5/train.py:412: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast(amp):
2/2 3.93G 0.04333 0.06397 0.01573 182 640: 1
Class Images Instances P R mAP50
all 128 929 0.769 0.633 0.736 0.486
3 epochs completed in 0.004 hours.你提供的这段日志是 YOLOv5 在 COCO128 数据集上训练 3 个 epoch 的完整训练输出,非常清晰地展示了整个训练过程和结果。下面我将为你详细解读:
📊 一、训练概览
深色版本
Starting training for 3 epochs...
3 epochs completed in 0.004 hours.
只训练了 3 个 epoch,适合快速测试流程是否正常;
训练速度非常快(仅 14 秒),说明硬件配置良好(Tesla P100 GPU + 小数据集)。
🧠 二、模型与训练参数回顾
参数 值
模型 YOLOv5s
数据集 COCO128(128 张训练图像)
输入尺寸 640x640
批量大小 16
优化器 SGD
初始学习率 0.01
超参数文件 hyp.scratch-low.yaml
⚠️ 三、警告信息(重复出现)
深色版本
FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
是 PyTorch 2.x 中对 AMP(自动混合精度)用法的更新提示;
当前不影响训练效果;
若你使用的是 PyTorch ≥ 2.0,建议升级 YOLOv5 到最新版本或手动修改相关代码以适配新写法。
📈 四、每个 Epoch 的损失和指标变化
✅ Epoch 0:
指标 值
box_loss 0.044
obj_loss 0.064
cls_loss 0.017
mAP@0.5 0.689
mAP@0.5:0.95 0.456
Precision (P) 0.679
Recall (R) 0.607
✅ Epoch 1:
指标 值
box_loss 0.046
obj_loss 0.067
cls_loss 0.016
mAP@0.5 0.712
mAP@0.5:0.95 0.472
Precision (P) 0.740
Recall (R) 0.610
✅ Epoch 2:
指标 值
box_loss 0.044
obj_loss 0.066
cls_loss 0.015
mAP@0.5 0.736
mAP@0.5:0.95 0.486
Precision (P) 0.769
Recall (R) 0.633
🔍 分析趋势:
mAP 不断上升,表示模型在逐步学习;
损失值稳定下降,说明训练正常收敛;
Precision 和 Recall 都有提升,整体表现良好。
📦 五、验证结果汇总(所有类别)
指标 Epoch 0 Epoch 1 Epoch 2
mAP@0.5 0.689 0.712 0.736
mAP@0.5:0.95 0.456 0.472 0.486
Precision 0.679 0.740 0.769
Recall 0.607 0.610 0.633
✅ 表明:模型随着训练逐渐提升性能,没有出现过拟合或训练崩溃的现象。
💻 六、GPU 内存占用
深色版本
GPU_mem: ~3.93G
Tesla P100 显存为 16GB,当前使用不到 4GB,说明资源充足;
可适当增加 batch_size 提高利用率(如设置 batch_size=32~64)。
📁 七、训练输出路径
深色版本
Logging results to runs/train/exp
你可以查看以下内容:
results.csv:记录每个 epoch 的 loss 和 metrics;
weights/ 文件夹下保存了模型权重(best.pt, last.pt);
labels/:可视化标注框;
train_batch*.jpg:展示增强后的训练图像;
TensorBoard 日志也已生成,可使用以下命令启动:
bash
深色版本
tensorboard --logdir runs/train
✅ 八、总结与建议
✅ 当前状态良好:
模型能正常加载并训练;
损失下降、mAP 上升,说明训练有效;
硬件资源充足,无明显瓶颈。Optimizer stripped from runs/train/exp/weights/last.pt, 14.8MB
Optimizer stripped from runs/train/exp/weights/best.pt, 14.8MB
Validating runs/train/exp/weights/best.pt...
Fusing layers...
Model summary: 157 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
Class Images Instances P R mAP50
all 128 929 0.77 0.633 0.738 0.486
person 128 254 0.887 0.713 0.805 0.528
bicycle 128 6 0.709 0.418 0.725 0.443
car 128 46 0.749 0.39 0.548 0.228
motorcycle 128 5 0.487 0.8 0.771 0.582
airplane 128 6 1 0.999 0.995 0.7
bus 128 7 0.595 0.714 0.788 0.697
train 128 3 0.667 0.333 0.753 0.479
truck 128 12 0.729 0.333 0.448 0.216
boat 128 6 0.938 0.333 0.528 0.217
traffic light 128 14 0.603 0.218 0.365 0.198
stop sign 128 2 0.812 1 0.995 0.821
bench 128 9 0.826 0.53 0.628 0.281
bird 128 16 0.968 1 0.995 0.664
cat 128 4 0.908 1 0.995 0.797
dog 128 9 0.989 0.667 0.893 0.647
horse 128 2 0.859 1 0.995 0.622
elephant 128 17 0.915 0.882 0.937 0.708
bear 128 1 0.694 1 0.995 0.995
zebra 128 4 0.84 1 0.995 0.923
giraffe 128 9 0.781 0.796 0.908 0.702
backpack 128 6 0.711 0.5 0.704 0.339
umbrella 128 18 0.837 0.722 0.868 0.502
handbag 128 19 0.794 0.204 0.333 0.172
tie 128 7 0.832 0.71 0.758 0.484
suitcase 128 4 0.877 1 0.995 0.621
frisbee 128 5 0.721 0.8 0.8 0.654
skis 128 1 0.826 1 0.995 0.117
snowboard 128 7 0.819 0.653 0.849 0.551
sports ball 128 6 0.653 0.667 0.602 0.304
kite 128 10 0.707 0.485 0.578 0.225
baseball bat 128 4 0.965 0.5 0.544 0.198
baseball glove 128 7 0.559 0.429 0.466 0.293
skateboard 128 5 1 0.591 0.714 0.476
tennis racket 128 7 0.754 0.429 0.529 0.288
bottle 128 18 0.57 0.37 0.53 0.268
wine glass 128 16 0.744 0.875 0.913 0.503
cup 128 36 0.828 0.535 0.777 0.509
fork 128 6 1 0.318 0.442 0.303
knife 128 16 0.798 0.74 0.724 0.404
spoon 128 22 0.782 0.489 0.636 0.372
bowl 128 28 0.894 0.604 0.721 0.559
banana 128 1 0.88 1 0.995 0.206
sandwich 128 2 1 0 0.414 0.356
orange 128 4 0.917 1 0.995 0.647
broccoli 128 11 0.379 0.364 0.44 0.329
carrot 128 24 0.692 0.561 0.681 0.473
hot dog 128 2 0.389 1 0.995 0.895
pizza 128 5 0.801 0.8 0.962 0.683
donut 128 14 0.658 1 0.948 0.805
cake 128 4 0.855 1 0.995 0.822
chair 128 35 0.549 0.6 0.618 0.329
couch 128 6 0.881 0.667 0.845 0.558
potted plant 128 14 0.729 0.786 0.819 0.466
bed 128 3 0.862 0.333 0.753 0.449
dining table 128 13 0.82 0.353 0.587 0.357
toilet 128 2 1 0.982 0.995 0.846
tv 128 2 0.568 1 0.995 0.846
laptop 128 3 1 0 0.645 0.326
mouse 128 2 1 0 0 0
remote 128 8 0.989 0.625 0.635 0.551
cell phone 128 8 0.642 0.375 0.443 0.219
microwave 128 3 0.77 1 0.995 0.755
oven 128 5 0.327 0.4 0.497 0.278
sink 128 6 0.495 0.333 0.346 0.246
refrigerator 128 5 0.566 0.8 0.798 0.546
book 128 29 0.577 0.207 0.376 0.172
clock 128 9 0.774 0.889 0.928 0.738
vase 128 2 0.396 1 0.995 0.895
scissors 128 1 1 0 0.497 0.0498
teddy bear 128 21 0.768 0.472 0.77 0.514
toothbrush 128 5 0.764 0.656 0.88 0.586
/usr/local/lib/python3.11/dist-packages/matplotlib/colors.py:721: RuntimeWarning: invalid value encountered in less
xa[xa < 0] = -1
Results saved to runs/train/exp根据你提供的验证日志,YOLOv5 模型在 runs/train/exp/weights/best.pt 上进行了验证。以下是详细分析:
📊 验证结果概览
模型摘要:包含 157 层,7,225,885 个参数,0 个梯度,计算量为 16.4 GFLOPs。
mAP@0.5(所有类别):0.738
mAP@0.5:0.95(所有类别):0.486
Precision (P):0.77(所有类别)
Recall (R):0.633(所有类别)
📈 各类别的性能指标
从日志中可以看出,模型对不同类别的检测效果存在显著差异。以下是一些关键点:
表现优异的类别:
person:Precision 0.887, Recall 0.713, mAP@0.5 0.805
motorcycle:尽管实例数少(仅 5),但 Precision 和 Recall 较高,分别为 0.487 和 0.800,且 mAP@0.5 达到 0.771。
airplane:近乎完美的 Precision 和 Recall,分别达到 1 和 0.999,mAP@0.5 为 0.995。
表现一般的类别:
bicycle、car、truck 等交通工具的 Precision 和 Recall 相对较低,可能与训练数据集中的样本数量或标注质量有关。
handbag 类别显示较低的 Recall 值(0.204),这可能意味着该类别在训练集中较少或者难以正确识别。
特殊情况:
mouse 类别出现了 Precision 为 1 但无召回的情况,表明可能存在极端不平衡的数据分布或错误标注。
scissors 的 mAP@0.5 虽然较高(0.497),但因为只有一个实例,其评估结果可能不太稳定。

















 2819
2819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









