









发表于2024年1月
MICCAI
代码开源:https://github.com/med-air/Endo-FM
摘要
基础模型在疾病诊断、文本报告生成等各种应用中取得了显著成功。然而,目前仍缺乏用于内窥镜视频分析的基础模型。在本文中,我们提出了Endo-FM,这是一种专门利用大量内窥镜视频数据开发的基础模型。首先,我们构建了一个视频变换器,它能够捕捉跨空间和时间维度的局部和全局长程依赖关系。其次,我们通过自监督的方式,利用全局和局部视图对变换器模型进行预训练,旨在使其对时空变化具有鲁棒性,并在不同场景下具有判别力。为了开发这个基础模型,我们通过整合9个公开可用的数据集以及来自中国上海仁济医院宝山分院的一个私人收集的数据集,构建了一个大规模的内窥镜视频数据集。我们的数据集总共包含超过3.3万个视频片段,多达500万帧,涵盖了各种检查方案、目标器官和疾病类型。我们预训练的Endo - FM可以通过微调轻松应用于给定的下游任务,作为骨干网络。通过在3种不同类型的下游任务(包括分类、分割和检测)上进行实验,我们的Endo - FM在很大程度上超越了当前最先进的(SOTA)自监督预训练和基于适配器的迁移学习方法,例如VCL(在分类、分割和检测任务上,F1分数分别提高3.1%、Dice系数提高4.8%、F1分数提高5.5% )和ST - Adapter(在分类、分割和检测任务上,F1分数分别提高5.9%、Dice系数提高9.6%、F1分数提高9.9%)。代码、数据集和模型已在https://github.com/med-air/Endo-FM上发布。
关键词
基础模型;内窥镜视频;预训练
1 引言
在大规模数据上预训练的基础模型最近在医学图像的各种下游任务中取得了成功,包括分类[9]、检测[34]和分割[32]。然而,医学数据具有多种成像模态,并且临床数据收集成本高昂。目前,在某些特定类型的数据上训练的特定基础模型是否有用仍存在争议。在本文中,我们专注于内窥镜视频,这是一种常规成像模态,并且在胃肠道疾病诊断、微创手术和机器人手术中受到越来越多的研究。拥有一个有效的基础模型有望促进需要内窥镜视频分析的下游任务。
现有的针对医学任务的基础模型研究,如X射线诊断[4]和放射学报告生成[21,22],涉及在大规模图像-文本对上进行预训练,并依赖大型语言模型来学习跨模态特征。然而,由于内窥镜视频的临床常规操作通常不涉及文本数据,目前基于纯图像的基础模型更具可行性。
为此,我们开发了一种基于ViT B/16[8]的视频变换器,包含1.21亿个参数,作为我们视频数据的基础模型骨干网络。我们注意到,最近的一项工作[34]中,一个基于Swin UNETR[11]、具有6200万个参数的类似规模的基础模型已成功应用于CT扫描。这表明我们的视频变换器有足够的能力对内窥镜视频丰富的时空信息进行建模。
为了从内窥镜视频数据中学习丰富的时空信息[12],我们的Endo - FM通过自监督的方式进行预训练,缩小同一视频不同时空视图的特征表示之间的差距。生成这些视图是为了解决内窥镜视频中各种上下文信息和运动的问题。受自监督视觉变换器[6,30]的启发,我们提出通过教师 - 学生方案对模型进行预训练。
在该方案下,训练学生在潜在特征空间中预测(匹配)教师的输出。换句话说,给定来自同一视频的两个时空感知视图,由教师处理的一个视图由由学生处理的另一个视图进行预测,以学习时空信息。因此,为来自同一内窥镜视频的不同时空视图设计有效且合适的匹配策略非常重要。
在本文中,我们提出了Endo-FM,这是一种专为内窥镜视频分析设计的新型基础模型。首先,我们基于ViT[8]构建了一个视频变换器,以捕捉长程空间和时间依赖关系,并设计了动态时空位置编码,用于处理具有不同空间大小和时间帧率的输入数据。其次,Endo - FM在教师 - 学生方案下,通过对不同视频视图进行时空匹配来进行预训练。具体来说,我们为输入视频片段创建各种在空间大小和帧率上不同的时空感知视图。教师和学生模型都处理视频的这些视图,并在潜在特征空间中从一个视图预测另一个视图。这使得Endo - FM能够学习对视图、尺度和运动不变的时空特征,这些特征可以在不同的内窥镜领域和疾病类型之间转移,同时保留特定于每个上下文的判别特征。
我们通过整合9个公开数据集和一个来自中国上海仁济医院宝山分院新收集的私有数据集,构建了一个大规模内窥镜视频数据集,包含超过3.3万个视频片段,多达500万帧。我们预训练的Endo - FM可以作为骨干网络轻松应用于各种下游任务。在3种不同类型的下游任务上的实验结果证明了Endo-FM的有效性,它在很大程度上超越了当前最先进的自监督预训练和基于适配器的迁移学习方法,例如VCL(在分类、分割和检测任务上,F1分数分别提高3.1%、Dice系数提高4.8%、F1分数提高5.5% )和ST - Adapter(在分类、分割和检测任务上,F1分数分别提高5.9%、Dice系数提高9.6%、F1分数提高9.9%)。
2 方法
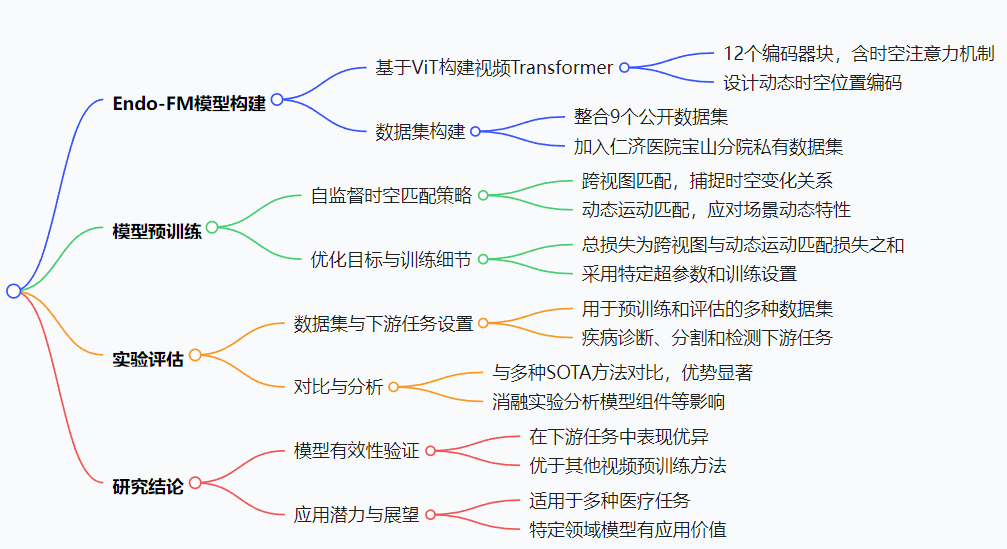
首先,我们构建一个视频变换器作为Endo - FM的架构(2.1节)。然后,我们提出一种新颖的自监督时空匹配方案(2.2节)。最后,我们在2.3节中描述整体训练目标和具体细节。我们方法的概述如图1所示。
2.1 用于时空编码的视频变换器
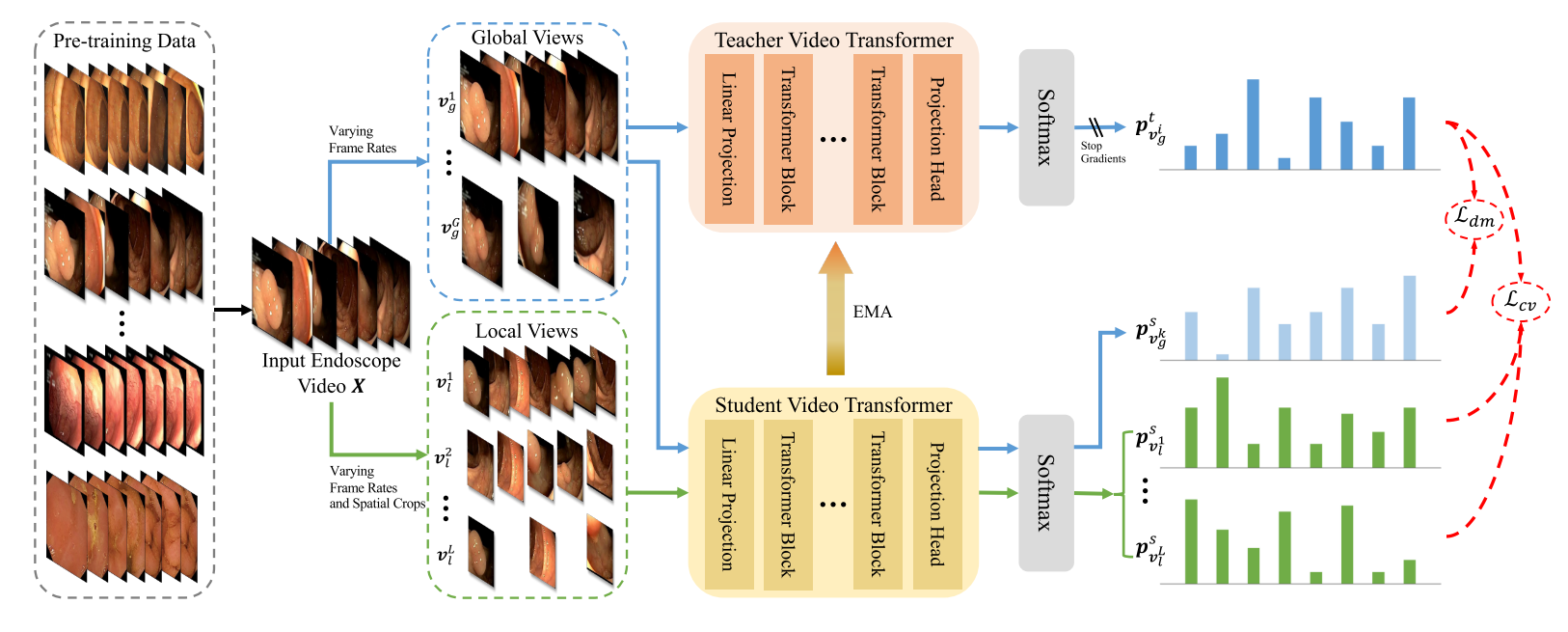
图1:我们提出的Endo - FM示意图。我们构建了一个视频变换器模型并设计了一种自监督预训练方法。
我们构建一个视频变换器来编码输入的内窥镜视频。我们模型中的空间和时间注意力机制能够捕捉跨空间和时间维度的长程依赖关系,其感受野比传统卷积核更大[23]。我们的模型由12个编码器块构建而成,并配备了时空注意力机制[3]。具体来说,给定一个内窥镜视频片段\(X \in \mathbb{R}^{T ×3 ×H ×W}\)作为输入,它由\(T\)帧大小为\(H ×W\)的帧组成,\(X\)中的每一帧被划分为\(N=H W / P^{2}\)个大小为\(P ×P\)的补丁,然后这些补丁被映射为\(N\)个补丁令牌。因此,每个编码器块处理\(N\)个补丁(空间)和\(T\)个时间令牌。给定来自块\(m\)的一个补丁的中间令牌\(z^{m} \in \mathbb{R}^{D}\),下一个块中的令牌计算如下:
\[\begin{aligned} z_{time }^{m+1} & =MHSA_{time }\left(LN\left(z^{m}\right)\right)+z^{m}, \\ z_{space }^{m+1} & =MHSA_{space }\left(LN\left(z_{time }^{m+1}\right)\right)+z_{time }^{m+1}, \\ z^{m+1} & =MLP\left(LN\left(z_{space }^{m+1}\right)\right)+z_{space }^{m+1}, \end{aligned}\]
其中\(MHSA\)表示多头自注意力,\(LN\)表示层归一化[1],\(MLP\)表示多层感知器。我们的模型还包括一个可学习的类别令牌,代表模型在空间和时间维度上学习到的全局特征。对于预训练,我们使用一个多层感知器将最后一个编码器块的类别令牌投影为\(X\)的特征\(f\)。
与ViT[8]中的静态位置编码不同,我们设计了一种动态时空编码策略,以帮助我们的模型处理具有不同空间大小和帧率的各种时空视图(2.2节)。具体来说,我们将空间和时间位置编码向量固定为输入视图每个维度的最高分辨率,这样便于对空间大小较小或时间帧率较低的视图进行插值。这些空间和时间位置编码向量被添加到相应的空间和时间令牌中。这种动态策略确保学习到的位置编码适用于具有不同输入大小的下游任务。
2.2 通过时空匹配进行自监督预训练
考虑到在内窥镜数据中处理与病变、组织和动态场景相关的上下文信息的困难,我们对Endo - FM进行预训练,使其对这些时空特征具有鲁棒性。受自监督视觉变换器[6]的启发,预训练设计为教师 - 学生方案,其中训练学生匹配教师的输出。为了实现这一点,给定一个输入视频\(X\),我们创建两种类型的时空视图作为模型输入:全局视图和局部视图,如图1所示。全局视图\(\{v_{g}^{i} \in \mathbb{R}^{T_{g}^{i} ×3 ×H_{g} ×W_{g}}\}_{i = 1}^{G}\)通过以不同帧率对\(X\)进行均匀采样生成,局部视图\(\{v_{l}^{j} \in \mathbb{R}^{T_{l}^{j} ×3 ×H_{l} ×W_{l}}\}_{j = 1}^{L}\)通过从\(X\)的随机裁剪区域以不同帧率均匀采样视频帧生成(\(T_{l} ≤T_{g}\))。在预训练期间,全局视图同时输入到教师和学生模型中,而局部视图仅输入到学生模型中。然后,模型输出\(f\)通过具有温度\(\tau\)的softmax函数进行归一化,以获得概率分布\(p = softmax((f / \tau))\)。接下来,我们针对处理内窥镜视频的困难设计了两种匹配方案。
跨视图匹配:与基于图像的预训练[34]不同,我们面向视频的预训练旨在捕捉不同时空变化之间的关系。具体来说,同一内窥镜视频不同帧中呈现的上下文信息可能会受到两个关键因素的影响而变化:1)帧内组织和病变的比例;2)病变区域的存在与否。为了解决这些问题,我们采用跨视图匹配方法,即由学生处理的在线局部视图(\(\{p_{v_{l}^{j}}^{s}\}_{j = 1}^{L}\))预测由教师处理的目标全局视图(\(\{p_{v_{g}^{i}}^{t}\}_{i = 1}^{G}\))。通过采用这种策略,我们的模型从两个角度学习高级上下文信息:1)从局部空间裁剪中可能的相邻组织和病变的角度学习空间上下文;2)从局部时间裁剪中前一帧或后一帧中病变可能存在的角度学习时间上下文。因此,我们的方法有效地解决了可能遇到的比例和存在问题。我们通过最小化以下跨视图匹配损失来实现:
\[\mathcal{L}_{cv}=\sum_{i = 1}^{G} \sum_{j = 1}^{L}-p_{v_{g}^{i}}^{t} \cdot log p_{v_{l}^{j}}^{s} . (2)\]
动态运动匹配:除了病变的比例和存在问题之外,内窥镜视频中捕获的场景固有的动态特性带来了进一步的挑战。不同视频中的运动速度和范围可能有很大差异,这使得训练一个在广泛的动态场景中都有效的模型变得困难。以前的模型[28]从固定帧率的视频片段中学习,无法解决这个问题,因为以不同帧率采样的视频片段包含不同的运动上下文信息(例如,快速与慢速场景变化),并且在细微的组织和病变方面也有所不同。为了应对这一挑战,我们的方法在预训练期间通过由学生处理的另一个在线全局视图(\(p_{v_{g}^{k}}^{s}\))预测由教师处理的目标全局视图(\(p_{v_{g}^{i}}^{t}\)),在内窥镜动态场景中进行运动建模。此外,通过从低帧率视图预测高帧率视图中组织和病变的细微差异,鼓励模型学习更全面的与运动相关的上下文信息。通过以下公式最小化全局视图对之间的动态运动差异:
\[\mathcal{L}_{dm}=\sum_{i = 1}^{G} \sum_{k = 1}^{G}-\mathbb{1}_{[i \neq k]} p_{v_{g}^{i}}^{t} \cdot log p_{v_{g}^{k}}^{s},\]
其中\(\mathbb{1}[\cdot]\)是一个指示函数。
2.3 整体优化目标和预训练细节
Endo - FM的整体训练目标是\(L_{pre - train } = L_{cv} + L_{dm}\)。教师输出采用了中心化和锐化方案[6]。为了防止在预训练期间教师和学生模型不断输出相同的值,我们通过反向传播更新学生模型\(\theta\),而教师模型\(\phi\)通过使用学生的权重进行指数移动平均(EMA)来更新。这通过在每次训练迭代\(t\)时将教师的权重更新为\(\phi_{t} \leftarrow \alpha \phi_{t - 1}+(1 - \alpha) \theta_{t}\)来实现。这里,\(\alpha\)是一个动量超参数,它决定了更新率。
除了2.2节中提到的大小比例、存在和动态场景问题带来的挑战之外,我们还观察到内窥镜视频的外观差异很大。这些视频是使用不同的手术系统在广泛的环境条件下拍摄的[10]。为了解决这种可变性,我们对单个视图内的所有帧应用时间一致的空间增强[28]。我们的增强方法包括随机水平翻转、颜色抖动、高斯模糊、曝光调整等,这增强了Endo - FM的鲁棒性和泛化能力。
对于Endo - FM,我们将补丁大小\(P\)设置为16,嵌入维度\(D\)设置为768。我们为每个输入内窥镜视频创建\(G = 2\)个全局视图和\(L = 8\)个局部视图,其中\(T_{g} \in[8,16]\),\(T_{l} \in[2,4,8,16]\)。全局和局部视图的空间大小分别为224×224和96×96。多层感知器头部将类别令牌的维度投影到65536。温度超参数设置为\(\tau_{t}=0.04\)和\(\tau_{s}=0.07\)。指数移动平均更新动量\(\alpha\)为0.996。训练批次大小为12,使用AdamW[17]优化器(学习率\(2e - 5\),权重衰减\(4e - 2\))。预训练使用余弦退火调度[16]进行30个epoch。
3 实验
3.1 数据集和下游任务设置

图2:本文中使用的10个预训练和下游数据集的示例帧。
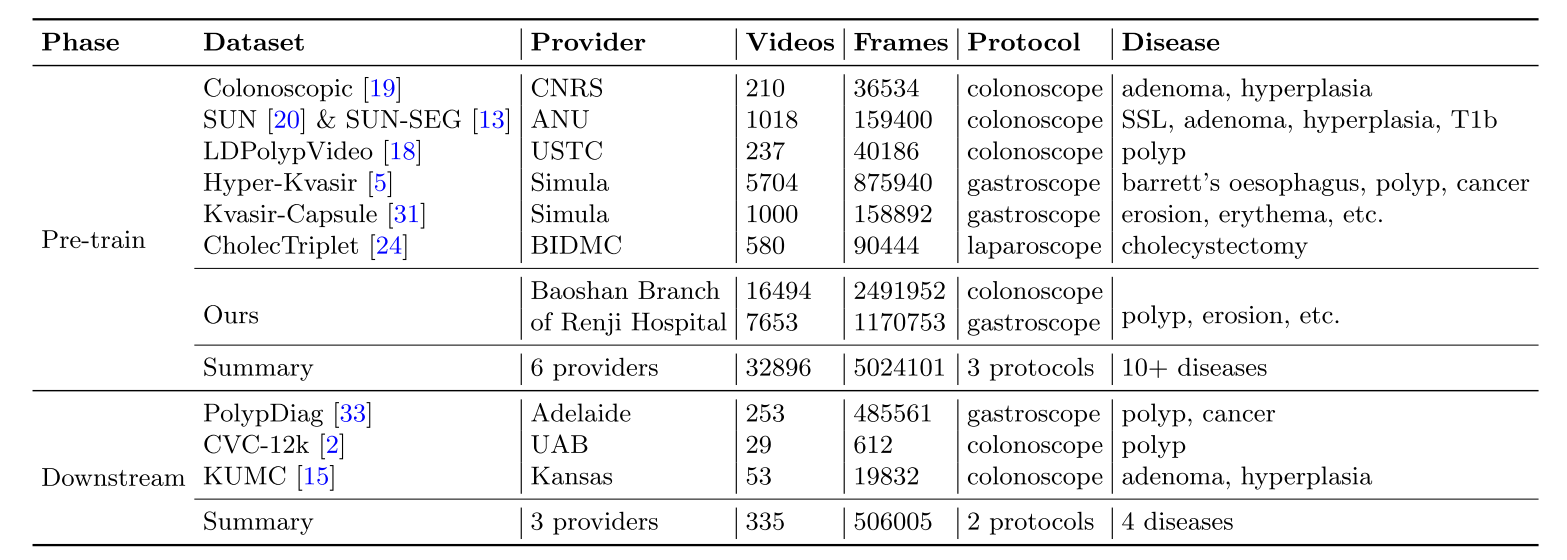
表1:本文中使用的所有预训练和下游数据集的详细信息。
我们收集了所有可能的公开内窥镜视频数据集以及一个来自上海仁济医院宝山分院的新数据集用于预训练。如表1所示,这些公开数据集由世界各地的研究小组[5,20,13,18,19,31]和之前的EndoVis挑战赛[24]提供,涵盖了3种内窥镜检查方案和10多种疾病类型。我们将原始视频处理为平均时长5秒、帧率为30fps的短视频片段。我们在三个下游任务上评估预训练的Endo - FM:疾病诊断(PolypDiag[33])、息肉分割(CVC - 12k[2])和检测(KUMC[15])。三个下游数据集的详细信息如表1所示。10个数据集的示例帧如图2所示。
对于下游微调,我们采用以下设置:1)PolypDiag:在预训练的Endo - FM上附加一个随机初始化的线性层。我们为每个视频采样8帧,空间大小为224×224作为输入,并训练20个epoch。2)CVC - 12k:实现一个以Endo - FM为骨干网络的TransUNet。我们将空间大小调整为224×224并训练150个epoch。3)KUMC:我们以预训练模型为骨干网络实现一个短时傅里叶变换(STFT)[35]来生成特征金字塔。我们将空间大小调整为640×640并训练24k次迭代。我们报告PolypDiag的F1分数、CVC - 12k的Dice系数和KUMC的F1分数。
3.2 与最先进方法的比较
我们将我们的方法与最近的基于视频的最先进预训练方法进行比较,包括引入时空注意力用于视频处理的TimeSformer[3]、提出自监督对比和顺序表示框架的CORP[12]、提出前景 - 背景合并方案的FAME[7]、应用自监督概率视频对比学习策略的ProViCo[26]、学习静态和动态视觉概念的VCL[27]以及通过深度卷积适配CLIP的ST - Adapter[25]。我们还从头开始训练我们的模型作为基线。为了进行公平比较,所有实验都采用相同的实验设置。
定量比较结果如表2所示。我们可以观察到,从头开始训练的模型在所有3个下游任务上表现都很低,尤其是在分割任务上。与从头开始训练相比,我们的Endo - FM在分类、分割和检测任务上分别实现了F1分数提高7.2%、Dice系数提高20.7%、F1分数提高10.6%,这表明我们提出的预训练方法非常有效。此外,我们的Endo - FM优于所有最先进的方法,在3个下游任务上比第二好的方法分别提高了3.1%的F1分数、4.8%的Dice系数和5 3.2 与最先进方法的比较
我们将我们的方法与最近的基于视频的最先进预训练方法进行比较,包括引入时空注意力用于视频处理的TimeSformer[3]、提出自监督对比和顺序表示框架的CORP[12]、提出前景 - 背景合并方案的FAME[7]、应用自监督概率视频对比学习策略的ProViCo[26]、学习静态和动态视觉概念的VCL[27]以及通过深度卷积适配CLIP的ST - Adapter[25] 。我们还从头开始训练我们的模型作为基线。为了进行公平比较,所有实验都采用相同的实验设置。
定量比较结果如表2所示。我们可以观察到,从头开始训练的模型在所有3个下游任务上表现都很低,尤其是在分割任务上。与从头开始训练相比,我们的Endo - FM在分类、分割和检测任务上分别实现了F1分数提高7.2%、Dice系数提高20.7%、F1分数提高10.6% ,这表明我们提出的预训练方法非常有效。此外,我们的Endo - FM优于所有最先进的方法,在3个下游任务上比第二好的方法分别提高了3.1%的F1分数、4.8%的Dice系数和5.5%的F1分数。这些显著的改进得益于我们为内窥镜视频设计的特定时空预训练,以处理复杂的上下文信息和动态场景。同时,除了更轻量级但性能差得多的ST - Adapter[25]之外,Endo - FM比最先进的预训练方法需要更少的预训练时间。
3.3 分析研究
图3:在PolypDiag上的消融实验:(a)组件分析;(b)不同的时空匹配视图组合;(c)全局和局部视图的数量;(d)局部视图的长度。
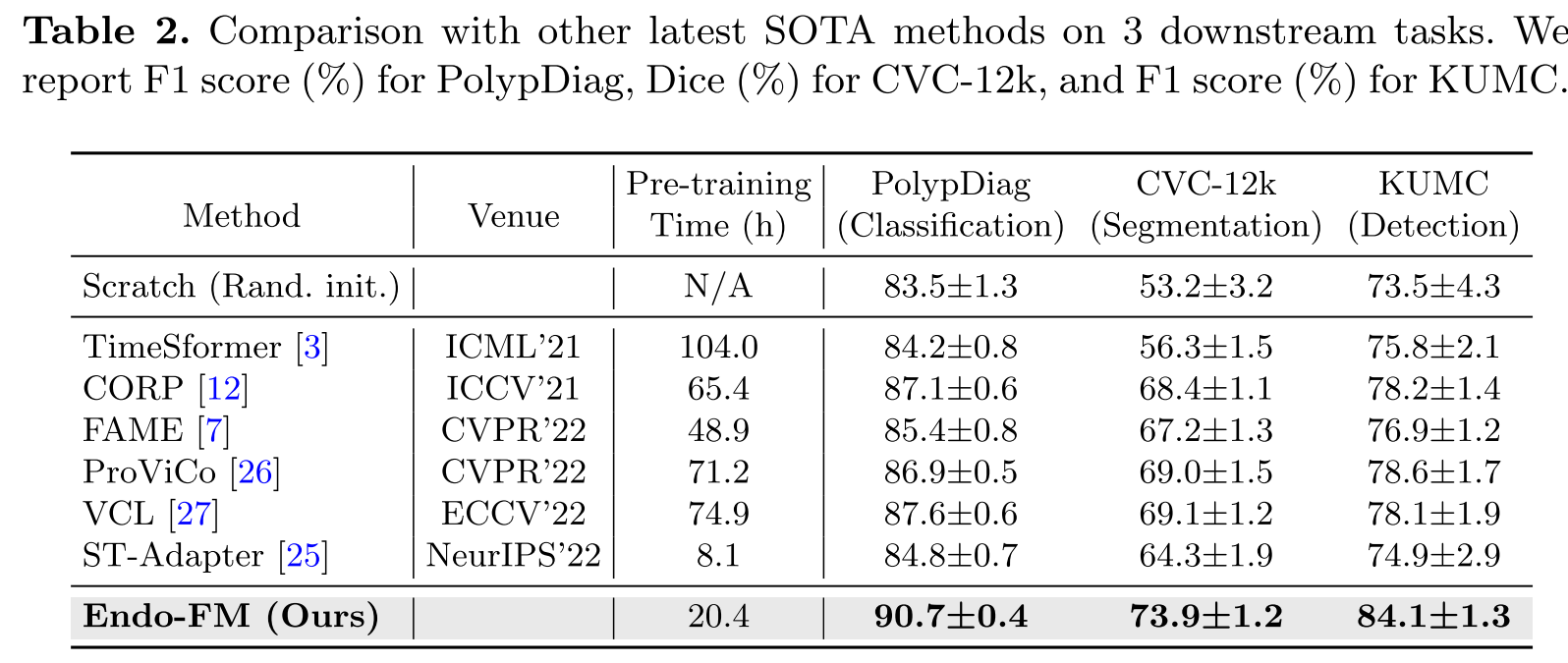
表2:与其他最新最先进方法在3个下游任务上的比较。我们报告PolypDiag的F1分数(%)、CVC - 12k的Dice系数(%)和KUMC的F1分数(%)。
在不失一般性的情况下,我们从三个方面对息肉诊断任务进行消融研究:1)预训练方法的组件分析;2)时空匹配中全局和局部视图的不同组合;3)全局和局部视图的构建变化。
组件分析:我们首先研究我们方法中的每个组件,如图3(a)所示。这里,“w/ \(L_{cv}\) (spat.)”和“w/ \(L_{cv}\) (temp.)”表示仅对局部视图使用空间和时间采样。我们可以了解到,对局部视图进行空间和时间采样都有助于提高性能,并且它们的组合会产生加成效果,使F1分数提高4.3%。此外,我们提出的动态匹配方案将性能提升到89.7%,这表明从动态场景中捕捉与运动相关的上下文信息非常重要。另外,通过视频增强,性能从89.7%进一步提高到90.7%。
时空匹配组合:我们进一步研究时空匹配中全局和局部视图组合的影响,如图3(b)所示。这里,符号\(v_{l} \to v_{g}\)表示从\(v_{l}\)预测\(v_{g}\),反之亦然。这表明联合预测场景,即我们从\(v_{l}\)(跨视图匹配)和\(v_{g}\)(动态运动匹配)两者预测\(v_{g}\),会产生最佳性能。这种趋势可以归因于联合预测场景能够更全面地理解复杂内窥镜视频中的上下文,而这在单独的情况下是缺乏的。
全局和局部视图的构建:我们进一步分析构建全局(\(G \in[1,2]\))和局部视图(\(L \in[1,2,4,6,8]\))的策略。我们改变全局和局部视图的数量,以及局部视图的长度(\(T_{l}\)),如图3(c)和图3(d)所示。我们发现,纳入更多的视图并增加局部视图长度的变化会产生更好的性能。对于“\(G = 1\)”,我们仍然为\(L_{dm}\)创建2个全局视图,但对于\(L_{cv}\)只考虑较长的那个。这些改进源于从多样的内窥镜视频中学习到的时空变化不变和跨视频判别特征。
4 结论与讨论
据我们所知,我们开发了第一个专门用于分析内窥镜视频的基础模型Endo - FM。Endo - FM基于视频变换器构建,以捕捉丰富的时空信息,并经过预训练以对多样的时空变化具有鲁棒性。我们构建了一个包含超过3.3万个视频片段的大规模内窥镜视频数据集。在3个下游任务上的大量实验结果证明了Endo - FM的有效性,它显著优于其他基于视频的最先进预训练方法,并展示了其在临床应用中的潜力。
关于最近为分割任务开发的SAM[14]模型,我们尝试使用与Endo - FM相同的微调方案将SAM应用于我们的下游任务CVC - 12k。实验结果表明,SAM在下游分割任务上可以实现与我们的Endo - FM相当的性能。考虑到SAM是用10倍数量的样本进行训练的,我们特定领域的Endo - FM在内窥镜场景中被认为是强大的。此外,除了分割之外,Endo - FM还可以轻松应用于其他类型的任务,包括分类和检测。因此,我们设想,尽管存在通用基础模型,但Endo - FM或类似的特定领域基础模型将对医学应用有所帮助。

















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









