







理论准备
在开始本章内容之前,我们先来温习一下导数是什么(这里不讨论复杂的特殊情况)。导数是微积分里的一个重要概念,用来描述在某点上函数的变化率,其几何意义表示为该点斜率。导数值越大,说明函数在该点斜率越陡,沿该点函数值变化快;导数值越小,说明函数在该点斜率越平稳,沿该点函数值变化慢。导数值为正,原函数的函数值递增;导数值为负,原函数的函数值递减。导数值为0时函数的值为某区间上的极值。
梯度下降法
梯度下降法简而概之就是通过导函数寻找函数的极小值。经常运用于机器学习的参数调整,让我们的算法更好地拟合数据。
梯度下降法原理
要求函数极小值,我们已经知道导数可以衡量在某点处的增长趋势和快慢,那么我们可以通过判断某点导数来决定我们下一步的选择。
如图为的函数,它的导函数为
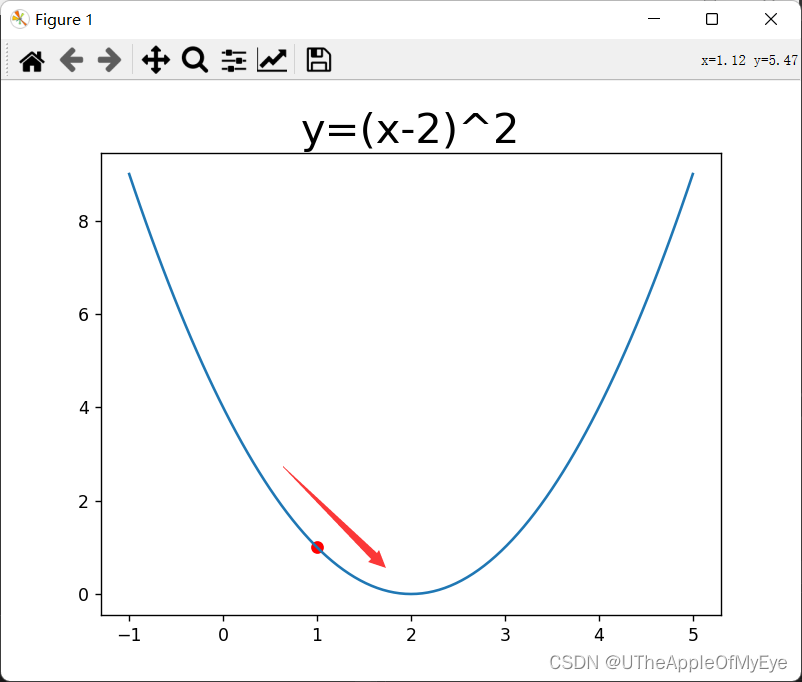
假设当我们取x=1,此时y=1,导函数y' = -2为负数,我们想取得函数的极小值那此时我们就想到要沿着导函数值趋于0的方向移动,因为等到导函数值变为0时它取到函数的极小值。好既然如此那我们就尝试用当前点的值减去导函数的值作为新的取值点,。
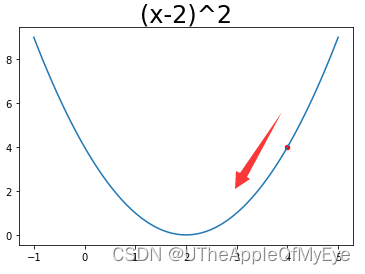
再假设现在x=4,此时y=4,导函数y' = 4为正数, 此时我们想取到极小值就需要向左移动,那么我们新点的取值就可以得到,。诶?是不是很巧,都用的减号。因为它们都需要朝着导函数为0的方向前进。
那么好我们已经知道怎么在原有点的基础上移动了,可问题又出现了,如果直接这么代入进去就会出现一个很大的问题啊,我们发现步子走太大了(因为导函数值可能会很大),可能直接掠过极小值了。比如第一张图当x=1时导函数y' = -2 ,那么x-y'=3,此时函数y=1。
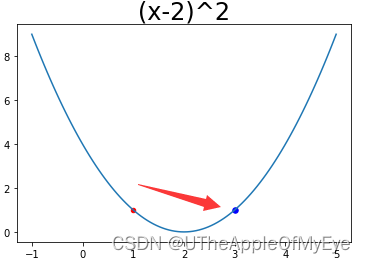
如果此时程序继续运行,x=3,y' = 2,那么x-y‘=1。欸,我又回去了,此时就出现了振荡,所以说步子迈太大容易扯着蛋。那我们该如何防止此事发生呢?我们就想到,如果我们让导数乘上一个系数(大于0,小于1)使它变小,那么不就使得我们更新点的速度慢下来了吗。这就是机器学习中学习率的来历。那么此时我们的公式就变成。
字母 就是学习率,学习率的取值依靠当前算法与要求取值,并不统一。那我们类比推理,当自变量不唯一时,我们就可以使用偏导数进行计算,这里不展开讨论。这里啰嗦一句,梯度下降法只适用于找极小值,找不到极大值。
梯度下降法例题
现在我们用新知识来想想那个我们困扰我们一生的问题,为什么小明要一边开水,一边放水。
一个泳池,开水龙头进入水池的水的量(单位:吨)为工作时间x(0<x<20,单位小时)的函数f(x):
其放水出去水的量(单位:吨)也为工作时间x的函数g(x):
(1)当x为多少时,水池刚好为空
(2)用导数求解x为多少时水池里水最多
(3)用梯度下降法求(2)问题
以下为代码实现
import numpy as np
import pandas as pd
#第一题
def f(x):
return -x**2+16*x+300
def g(x):
return x**2-40*x+500
#用g(x)-f(x)构造新函数
def k(x):
return 2*x**2-56*x+200
def equation(x):
return g(x)-f(x)
def combination(a,b,c):
#二次函数判别式
delta=b**2-4*a*c
if delta<0:
pass
elif delta==0:
print(-b/2*a)
elif delta>0:
x1=(-b-delta**0.5)/(2*a)
x2=(-b+delta**0.5)/(2*a)
#x的取值范围是(0,20)
if(0<=x1<=20):
print("x1 =",x1)
if(0<=x2<=20):
print("x2 =",x2)
#新二次函数的系数,k(x)=g(x)-f(x)
a=2
b=-56
c=200
combination(a,b,c)
#第二题
#k(x)的导函数
def derivative(x):
return 4*x-56
#导数为0时x的取值
max_point=56/4
print(new_func(max_point))
#第三题
#设定误差值,只要小于误差值我们就停止循环
gap=1e-5
#设定学习率大小
eta=0.05
#设置最大循环次数
max_loop=1000
#从0开始寻找极小值
x=0
for _ in range(max_loop):
df=derivative(x)
#更新x的值
x_new=x-eta*df
#小于误差退出循环
if abs(x-x_new)<gap:
break
x=x_new
print(k(x_new))














 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









