







【模糊逻辑】模糊集合和模糊逻辑-3
2.16 从精确逻辑到模糊逻辑
相较于精确逻辑,模糊逻辑往往无法直接给出正确或者错误,或者真或假。这种逻辑关系往往是处理无法明确说明对错(正确与否)的情况。在模糊逻辑中,命题表征的是其正确/错误程度,从0到1之间来连续表示,而非二值化。
例如先前提到过的模糊集可以从精确集扩展,模糊关系可以从精确关系扩展那样,模糊逻辑也可以由精确逻辑扩展得到。所以这里的一些符号也就借鉴着精确逻辑中来使用。
以下定义implication关系在模糊逻辑中的使用。类似精确逻辑,可以用"IF-THEN"表述方式,“如果x为A,则y为B”,其中
x
∈
X
x\in X
x∈X,
y
∈
Y
y\in Y
y∈Y,有隶属函数MF
μ
A
→
B
(
x
,
y
)
\mu_{A\rightarrow B}(x,y)
μA→B(x,y),其中
μ
A
→
B
(
x
,
y
)
∈
[
0
,
1
]
\mu_{A\rightarrow B}(x,y)\in[0,1]
μA→B(x,y)∈[0,1]。值得注意的是,这里的
μ
A
→
B
(
x
,
y
)
\mu_{A\rightarrow B}(x,y)
μA→B(x,y)是对x和y之间的存在隐含关系的程度的度量函数。可以举例如下
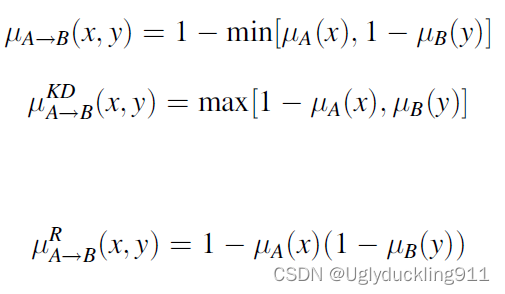
在模糊逻辑中,modus ponens(演绎推理)可以扩展为generalized modus ponens(广义演绎推理)
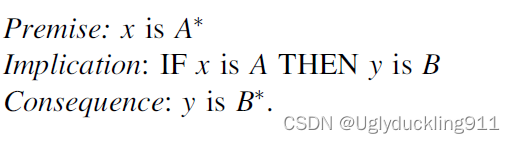
这里值得注意的是,modus ponens 和广义modus ponens存在细微的区别——其中集合
A
∗
A^*
A∗不一定与集合A相同,同样的结果中的集合
B
∗
B^*
B∗不一定与集合B相同。
例子2.30
现在举个男生打篮球的例子,设置命题“如果一个男生身高很矮,则他将不是一个非常专业的篮球运动员”,这里的Implication中A的集合是男生身高很矮,此时premise的 A ∗ A^* A∗可以为男生身高不足1.6米。这里很明显,集合 A ∗ A^* A∗和集合A不同,但是集合 A ∗ A^* A∗和A很相近。同理集合 B ∗ B^* B∗和B也可以是不同的。
所以,对于精确逻辑来说,往往Premise中的集合和Implication中的前提是一样的,而Implication的结果则是命题的结果。而对于模糊逻辑来说,只要这两个集合存在非零的相似程度,那么就可以来构成命题。
假设
μ
A
∗
(
x
)
\mu_{A^*}(x)
μA∗(x)为单元素模糊器(singleton fuzzifier),可以表示如下
μ
A
∗
=
{
1
,
x
=
x
′
0
,
x
≠
x
′
\mu_{A^*}= \left\{ \begin{array}{lr} 1 ,x=x^{'} & \\ 0 ,x\ne x^{'} & \end{array} \right.
μA∗={1,x=x′0,x=x′
根据之前不同积空间的组合的公式,可以将implication的结果
B
∗
B^*
B∗表示如下
μ
B
∗
(
y
)
=
s
u
p
x
∈
X
[
μ
A
∗
(
x
)
★
μ
A
→
B
(
x
,
y
)
]
,
x
∈
X
,
y
∈
Y
\mu_{B^*}(y)=sup_{x\in X}[\mu_{A^*}(x)\bigstar\mu_{A\rightarrow B}(x,y)],x\in X ,y\in Y
μB∗(y)=supx∈X[μA∗(x)★μA→B(x,y)],x∈X,y∈Y
由于假设
μ
A
∗
(
x
)
\mu_{A^*}(x)
μA∗(x)为单元素模糊器,所以有下式
μ
B
∗
(
y
)
=
s
u
p
x
∈
X
[
μ
A
∗
(
x
)
★
μ
A
→
B
(
x
,
y
)
]
=
s
u
p
[
μ
A
→
B
(
x
′
,
y
)
,
0
]
=
μ
A
→
B
(
x
′
,
y
)
,
y
∈
Y
\mu_{B^*}(y)=sup_{x\in X}[\mu_{A^*}(x)\bigstar\mu_{A\rightarrow B}(x,y)] =sup[\mu_{A\rightarrow B}(x^{'},y),0]= \mu_{A\rightarrow B}(x^{'},y),y\in Y
μB∗(y)=supx∈X[μA∗(x)★μA→B(x,y)]=sup[μA→B(x′,y),0]=μA→B(x′,y),y∈Y
此处的符号
★
\bigstar
★可以为最小或者乘积。由上式可知,对于单元素模糊器的最大化运算符是非常容易来估计的,因为
μ
A
∗
(
x
)
\mu_{A^*}(x)
μA∗(x)只有一个非零点。
例子2.31
根据先前的例子,我们知道有,以下等式
μ
B
∗
(
y
)
=
μ
A
→
B
(
x
′
,
y
)
=
1
−
m
i
n
[
μ
A
(
x
′
)
,
1
−
μ
B
(
y
)
]
,
y
∈
Y
\mu_{B^*}(y)=\mu_{A\rightarrow B}(x^{'},y)=1-min[\mu_A(x^{'}),1-\mu_B(y)],y\in Y
μB∗(y)=μA→B(x′,y)=1−min[μA(x′),1−μB(y)],y∈Y
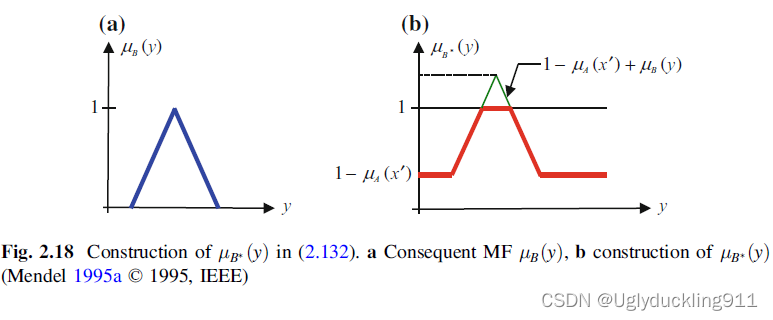
此处,假设
μ
B
∗
(
y
)
\mu_{B^*}(y)
μB∗(y)为三角MF,不难发现这样的结果输出有一个恒定偏置的。

例子2.32
类似的如果有以下等式
μ
B
∗
(
y
)
=
μ
A
→
B
L
(
x
′
,
y
)
=
m
i
n
[
1
,
1
−
μ
A
(
x
′
)
+
μ
B
(
y
)
]
,
y
∈
Y
\mu_{B^*}(y)=\mu^L_{A\rightarrow B}(x^{'},y)=min[1,1-\mu_A(x^{'})+\mu_B(y)],y\in Y
μB∗(y)=μA→BL(x′,y)=min[1,1−μA(x′)+μB(y)],y∈Y
此处,假设
μ
B
∗
(
y
)
\mu_{B^*}(y)
μB∗(y)为三角MF,不难发现这样的结果输出依然有一个恒定偏置的。
2.17Mamdani提出的Implication
Mamdani提出的Implication
μ
A
→
B
(
x
′
,
y
)
≡
m
i
n
[
μ
A
(
x
)
,
μ
B
(
x
)
]
,
x
∈
X
,
y
∈
Y
\mu_{A\rightarrow B}(x^{'},y)\equiv min[\mu_A(x),\mu_B(x)],x\in X,y\in Y
μA→B(x′,y)≡min[μA(x),μB(x)],x∈X,y∈Y
之后,Larsen也提出的Implication
μ
A
→
B
(
x
′
,
y
)
≡
μ
A
(
x
)
μ
B
(
x
)
,
x
∈
X
,
y
∈
Y
\mu_{A\rightarrow B}(x^{'},y)\equiv \mu_A(x)\mu_B(x),x\in X,y\in Y
μA→B(x′,y)≡μA(x)μB(x),x∈X,y∈Y
根据上面的Implication可以有以下的输出,则不存在了偏置了。

















 2437
2437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









