









多模态中各种Fusion骚操作
大噶好,我是DASOU;
今天继续写多模态系列文章,对多模态感兴趣的可以看我之前的文章:
其实对于多模态来说,主要可以从三个部分去掌握它:
- 如何获取多模态的表示【learning multimodal representations】
- 如何做各个模态的融合【fusing multimodal signals at various
levels】 - 多模态的应用【multimodal applications】
今天我主要放在第二个部分,也就是各个模态的Fusion方式汇总;
Fusion做的事情简单来说就是把不同模态的信息整合为一个信息,得到一个特征向量,然后利用这个特征向量再去做下游任务;
所以它的任务就是更深的挖掘不同模态信息同时更好的融合进最终的representation;
我们可以把Fusion分为三种融合方式:
- 基于简单操作的融合
- Attention-based Fusion
- 双线性池化融合
1. 基于简单操作的融合
Simple Operation-based Fusion 就是说来自不同模态的特征向量可以使用很简单的方式进行整合,比如多个模态的特征向量的拼接,加权和;
举个简单的例子,比如我们现在做一个图文双模态的分类任务,我们获取了文本特征向量和图片特征向量,那么我们可以把两个特征向量直接拼接,就当做是融合后的向量了;
如果我认为文本的包含的信息更加的重要,图片包含的信息不是那么重要,我完全可以自定义文本特征向量权重为0.7,图片特征向量权重为0.3,然后两者的向量再concat或者做加权的和;
其实如果我们自己最开始做一个多模态任务,最先想到的方式就应该是这种基于简单操作的方式;
但是这个方式存在一个问题,就是两个模态之后没有做足够的交互,两者之间的联系比较弱一点;
针对这个,我们一般会在得到concat features之后,不会直接去做分类任务,而是再接一个或者几个全连接层,让模型自动的去学习两个模态之间的关系,这样效果会更好;
这里还有一点需要注意的是,对于concat方式,我们最好是确保文本特征向量和图片特征向量维度是固定的,这样后面接全连接层维度不会出错;
但是有些时候我们输入的图片数量不固定,那么图片特征向量维度不一定,这个时候操作比较多,举个简单例子可以先做一个max pooling到固定维度再去和文本拼接;
如果做加权和,我们需要确保文本和图片特征维度是相同的,这个就不多说,很好理解;
以我自己个人经验来说,在图文多模态分类这个,使用concat这种方式,能比单一的使用文本效果提升不到2个点左右,当然case by case;
2. Attention-based Fusion
第一种方式我一般是在任务中作为基线,简单粗暴有提升;之后任务迭代的时候,一般都会往attention上靠一靠;
因为concat虽然后面加上了全连接层学习两者之间关系,但是在两者的交互上来说还是有点弱的;
对于attention的操作可以简单分为:1.Image attention;2. Symmetric attention for images and text;3. Attention in a bimodal transformer; 4. Other attention-like mechanisms;
我详细说一下第三点,就是基于TRM的attention,因为TRM太火了;
基于TRM的attention这块,从两个类别去理解它,一个是基于TRM的多模态预训练模型,一个是基于TRM的微调模型;
基于TRM的多模态预训练模型,就是所借助TRM,输入是图片和文本信息,然后做预训练任务,从大量数据中学习到信息,然后得到多模态预训练模型,然后放入到下游任务中去;
但是这些有个问题,很多人都没有大量的图文平行无监督数据,相反大家一般都有图文平行的标注数据;
所以我们可以直接借助TRM的结构,直接做下游任务的微调就可以,这一块有个论文是facebook的MMBT;
MMMBT其实很简单,直接看这个图: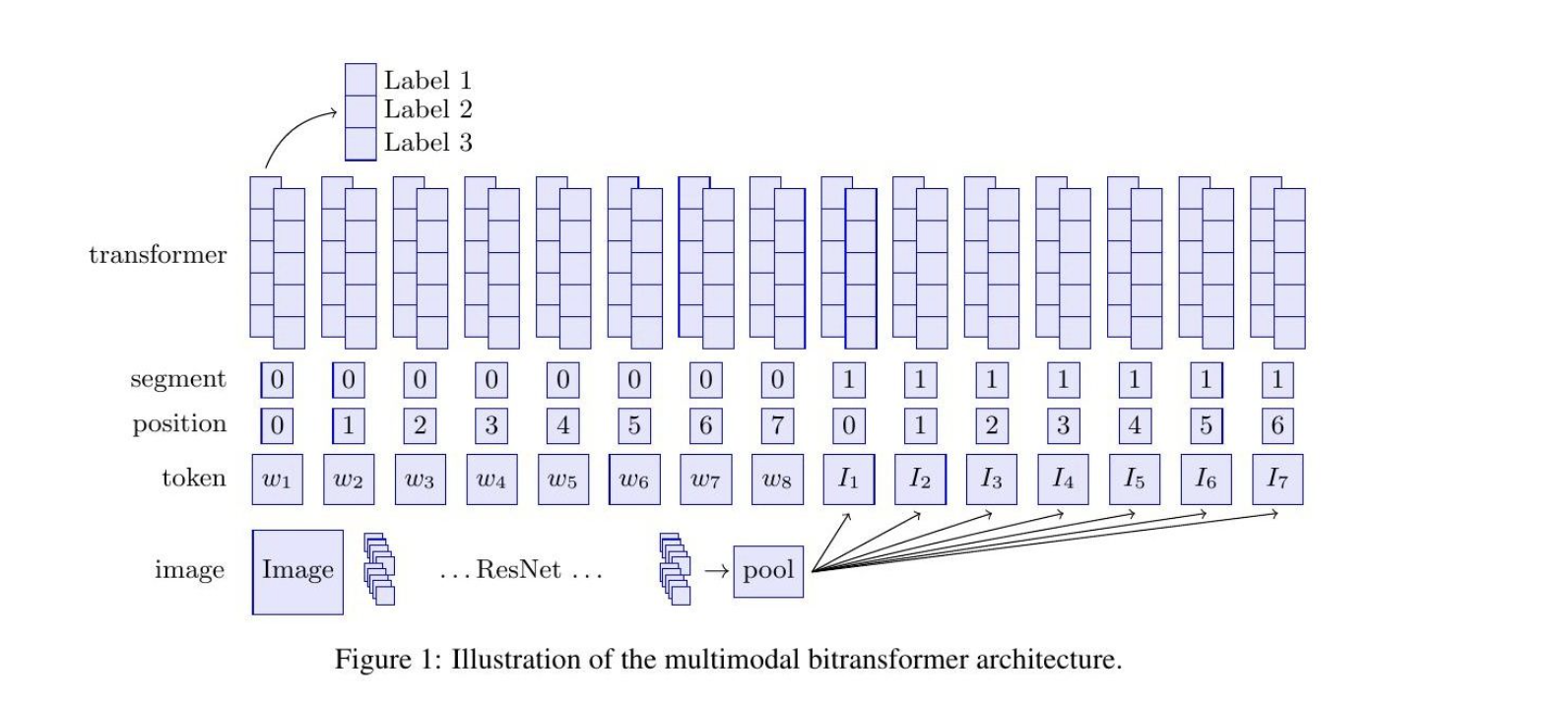
就是借助bert做初始化,然后图片从resent得到向量输出,一般是三个,然后拼接文本,输入到bert,直接在下游任务做微调;
在这里我想多说几句,其实还可以直接对文本和图片之间做attention,多头或者单头都可以,其实单头就够了;
在写代码的时候,我在遇到一个问题,就是文本和图片之间attention的矩阵化,我踩了下坑~~~;
3. 基于双线性池化的融合办法
双线性池化也是一个比较受重视的融合方法,不过它的问题就是在于会把n为变成n的平方,复杂度大大提升,后续的改进一般都是在降低复杂度这一块;
双线性池化最初的操作,就是做向量的外积,获得一个矩阵,然后对矩阵做sum池化,得到特征向量,然后再去做分类;
如果是在实际业务,大家还是优先考虑前两种吧,双线性池化这个放后一点;
先写这么多,后续会写一个MMBT论文的解读;
参考论文:Multimodal Intelligence: Representation Learning, Information Fusion, and Applications
https://arxiv.org/pdf/1911.03977.pdf



















 3841
3841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











