







2# Deep learningforvisualunderstanding:Areview 论文阅读
刚刚入门深度学习这个大坑,就从两篇著名的综述论文开始我的学习之路吧
abstract 摘要
Deep learning algorithms are a subset of the machine learning algorithms, which aim at discovering multiple levels of distributed representations. Recently, numerous deep learning algorithms have been proposed to solve traditional artificial intelligence problems. This work aims to review the state-of-theart in deep learning algorithms in computer vision by highlighting the contributions and challenges from over 210 recent research papers. It first gives an overview of various deep learning approaches and their recent developments, and then briefly describes their applications in diverse vision tasks, such as image classification, object detection, image retrieval, semantic segmentation and human pose estimation. Finally, the paper summarizes the future trends and challenges in designing and training deep neural networks.
深度学习算法是机器学习算法的一个子集,旨在发现多个层次的分布式表示。近年来,许多深度学习算法被提出来解决传统的人工智能问题。本文旨在回顾计算机视觉深度学习算法的研究现状,着重介绍210多篇最新研究论文的贡献和挑战。本文首先概述了各种深度学习方法及其最新进展,然后简要介绍了它们在图像分类、目标检测、图像检索、语义分割和人体姿态估计等视觉任务中的应用。最后,本文总结了深度神经网络设计与训练的未来趋势与挑战.
总的来说,摘要部分阐明了一篇文章要介绍的内容
这篇我们可以清晰的看到目的是回顾 deep learning algorithms in computer vision 的内容
1.Introduction介绍
Deep learning is a subfield of machine learning which attempts to learn high-level abstractions in data by utilizing hierarchical architectures. It is an emerging approach and has been widely applied in traditional artificial intelligence domains, such as semantic parsing [1], transfer learning [2,3], natural language processing [4], computer vision [5,6] and many more. There are mainly three important reasons for the booming of deep learning today: the dramatically increased chip processing abilities (e.g. GPU units), the significantly lowered cost of computing hardware, and the considerable advances in the machine learning algorithms
Various deep learning approaches have been extensively reviewed and discussed in recent years [8–12]. Among those Schmidhuber et al. [10] emphasized the important inspirations and technical contributions in a historical timeline format, while Bengio [11] examined the challenges of deep learning research and proposed a few forward-looking research directions. Deep networks have been shown to be successful for computer vision tasks because they can extract appropriate features while jointly performing discrimination [9,13]. In recent ImageNet Large Scale Visual Recognition Challenge (ILSVRC) competitions [189], deep learning methods have been widely adopted by different researchers and achieved top accuracy scores .
深度学习是机器学习的一个分支,它试图利用层次结构学习数据中的高级抽象。它是一种新兴的方法,已广泛应用于传统人工智能领域,如语义分析[1]、转移学习[2,3]、自然语言处理[4]、计算机视觉[5,6]等。深度学习的蓬勃发展主要有三个重要原因:芯片处理能力(如GPU单元)的显著提高、计算硬件成本的显著降低以及机器学习算法的长足进步
近年来,各种深度学习方法被广泛地回顾和讨论[8-12]。在Schmidhuber等人。[10] 强调了历史时间轴格式的重要启示和技术贡献,而Bengio[11]研究了深度学习研究的挑战,并提出了一些前瞻性的研究方向。深度网络在计算机视觉任务中被证明是成功的,因为它们可以在联合执行识别的同时提取适当的特征[9,13]。在最近的ImageNet大规模视觉识别挑战赛(ILSVRC)竞赛[189],深度学习方法已被不同研究者广泛采用,并获得最高的准确度分数
深度学习是机器学习的一个分支
深度学习的蓬勃发展主要有三个重要原因
- 芯片处理能力(如GPU单元)的显著提高
- 计算硬件成本的显著降低
- 机器学习算法的长足进步
The remainder of this paper is organized as follows:
In Section 2, we divide the deep learning algorithms into four categories: Convolutional Neural Networks, Restricted Boltzmann Machines, Autoencoder and Sparse Coding. Some well-known models in these categories as well as their developments are listed. We also describe the contributions and limitations for these models in this section. In Section 3, we describe the achievements of deep learning schemes in various computer vision applications, i.e. image classification, object detection, image retrieval, semantic segmentation and human pose estimation. The results on these applications are shown and compared in the pipeline of their commonly used datasets. In Section 4, along with the success deep learning methods have achieved, we also face several challenges when designing and training the deep networks. In this section, we summarize some major challenges for deep learning, together with the inherent trends that might be developed in the future. In Section 5, we conclude the paper.
在第二节中,我们将深度学习算法分为四类:
卷积神经网络、
受限Boltzmann机器、
自动编码器
稀疏编码
文中列举了这几类产品中的一些知名车型及其发展情况。我们还将在本节中描述这些模型的贡献和局限性。在第三部分,我们描述了深度学习方案在各种计算机视觉应用中的成果,即图像分类、目标检测、图像检索、语义分割和人体姿态估计。这些应用程序的结果在其常用数据集的管道中显示和比较。在第四部分,随着深度学习方法取得的成功,我们在设计和训练深层网络时也面临着一些挑战。在本节中,我们总结了深度学习的一些主要挑战,以及未来可能发展的内在趋势。在第五节中,我们对论文进行了总结。
2. Methods and recent developments
In recent years, deep learning has been extensively studied in the field of computer vision and as a consequence, a large number of related approaches have emerged. Generally, these methods can be divided into four categories according to the basic method they are derived from: Convolutional Neural Networks (CNNs), Restricted Boltzmann Machines (RBMs), Autoencoder and Sparse Coding.
The categorization of deep learning methods along with some representative works is shown in Fig. 1.
In the next four parts, we will briefly review each of these deep learning methods and their most recent developments.
近年来,深度学习在计算机视觉领域得到了广泛的研究,因此出现了大量相关的方法。一般来说,这些方法按其产生的基本方法可分为四类:卷积神经网络(CNNs)、受限Boltzmann机器(RBMs)、自动编码器和稀疏编码。
深度学习方法的分类以及一些有代表性的作品如图1所示。
在接下来的四个部分中,我们将简要回顾这些深度学习方法及其最新发展。
2.1. Convolutional Neural Networks (CNNs)
CNN的基本介绍
一般CNN架构的流水线如下图所示
输入图像->卷积->池化->全连接->得出结论 Fish

一般来说,CNN由三个主要的神经层组成
- 卷积层 convolutional layers
- 池化层 pooling layers
- 全连接层fully connected layers
在图中我们可以看到网络训练分为两个阶段
- 前向阶段 forward stage
- 后向阶段 backward stage
forward的主要目标是用每层的当前参数(权重和偏差)来表示输入图像。然后利用预测输出计算地面真实性标签的损失成本。
backward在损失成本的基础上,利用链式规则计算出各参数的梯度。所有参数都会根据梯度进行更新,为下一步的正演计算做好准备。
在经过充分的前向和后向迭代后,才可以停止网络学习。
Convolutional layers
在卷积层中,CNN利用各种核来卷积整个图像以及中间特征映射,生成各种特征映射
卷积运算有三个主要优点
- 1)同一特征映射中的权重共享机制减少了参数的数量
- 2)局部连通性学习相邻像素之间的相关性
- 3)对象的位置不变性。
下图是个3*3的卷积核
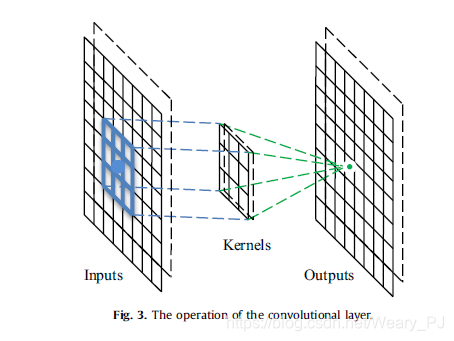
由于卷积运算带来的好处,一些著名的研究论文将其用作完全连接层的替代物,以加快学习过程。处理卷积层的一个有趣的方法是网络中的网络(NIN)方法,其中的主要思想是用一个小的多层感知器代替传统的卷积层,该感知器由多个具有非线性激活函数的全连接层组成,从而用非线性神经网络代替线性滤波器。该方法在图像分类中取得了良好的效果。
Pooling layers
下图给出最大池的处理
对于8-8个特征映射,输出映射减少到44个维度,使用最大池操作符,其大小为22和步长为2。
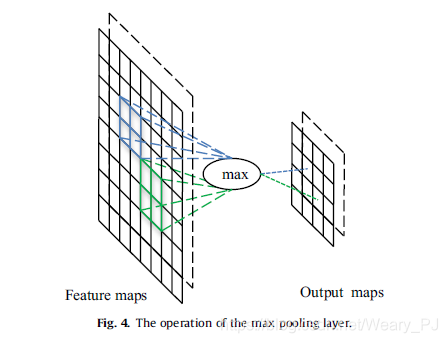
文中还介绍了三种与池层相关的著名方法,每种方法都有不同的用途。
随机池 Stochastic pooling
max-pooling的一个缺点是对训练集的过度拟合非常敏感,这使得很难很好地推广到测试样本。为了解决这个问题,Zeiler等人提出了一种随机池方法,它通过根据多项式分布随机选择每个池区域内的激活,用随机过程代替传统的确定性池操作。它相当于标准的max pooling,但是有许多输入图像的副本,每个副本都有小的局部变形。这种随机性有助于防止过拟合问题。
空间金字塔池层 Spatial pyramid pooling (SPP)
通常,基于CNN的方法需要一个固定大小的输入图像。这种限制可能会降低对任意大小图像的识别精度。为了消除这种局限性,有人使用了通用的CNN架构,但使用空间金字塔池层替换了最后一个池层。空间金字塔池可以从任意图像(或区域)中提取固定长度的表示,为处理不同的尺度、大小、高宽比提供了一种灵活的解决方案,并可应用于任何CNN结构中,以提高这种结构的性能。
Def-pooling
变形处理是计算机视觉的一个基本挑战,尤其是对于目标识别任务。最大池和平均池在处理变形时很有用,但它们不能学习对象零件的变形约束和几何模型。为了更有效地处理变形,欧阳等人引入了一个新的变形约束池层,称为def pooling layer,通过学习视觉模式的变形来丰富深层模型。它可以在任何信息抽象层次上替代传统的最大池层。
由于池策略的目的和过程不同,可以将不同的池策略组合起来以提高CNN的性能。
全连接层 Fully-connected layers
全连接层的性能类似于传统的神经网络,包含CNN中约90%的参数。它使我们能够将神经网络前馈到一个预定长度的向量。我们可以将该向量前馈到一定数量的类别中进行图像分类,也可以将其作为特征向量进行后续处理。
这些层的缺点是它们包含很多参数,这导致训练它们的计算量很大。因此,用一定的方法去除这些层或减少连接是一个很有前途和普遍应用的方向。例如,GoogLeNet通过从完全连接到稀疏连接的架构,在保持计算预算不变的同时,设计了一个深而宽的网络。
处理过拟合的方法
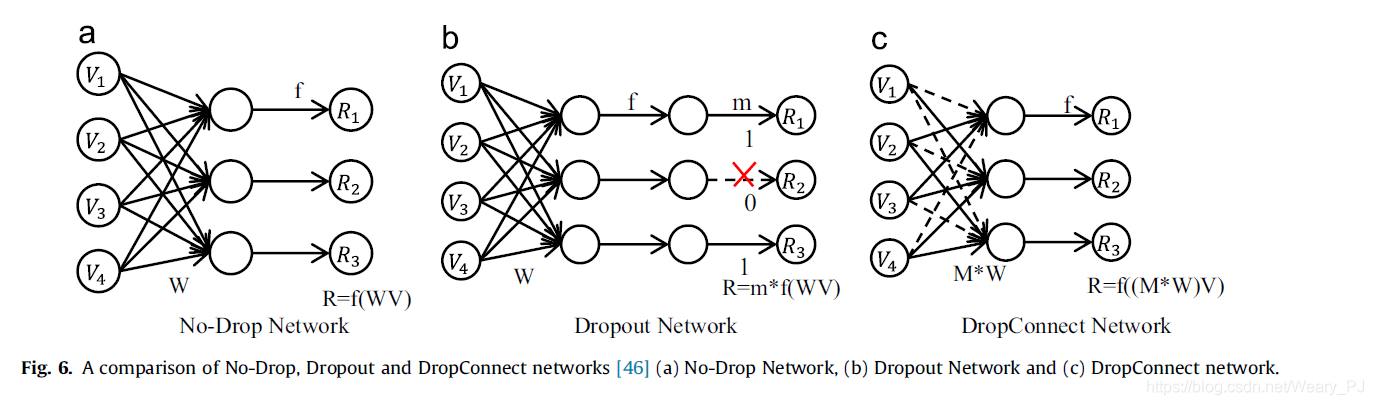
- Dropout
- 在每一个训练过程中,该算法将随机省略一半的特征检测器,以防止训练数据的复杂协同适应,提高泛化能力
- DropConnect
- 是从Dropout中派生出的一种众所周知的泛化,它随机地降低权重而不是激活。实验表明,它可以在各种标准基准测试中获得有竞争力甚至更好的结果,尽管速度稍慢。
深度学习中Dropout原理解析
Deep learning (DropConnect简单理解)
看看这个文章就很好理解 几者的作用了
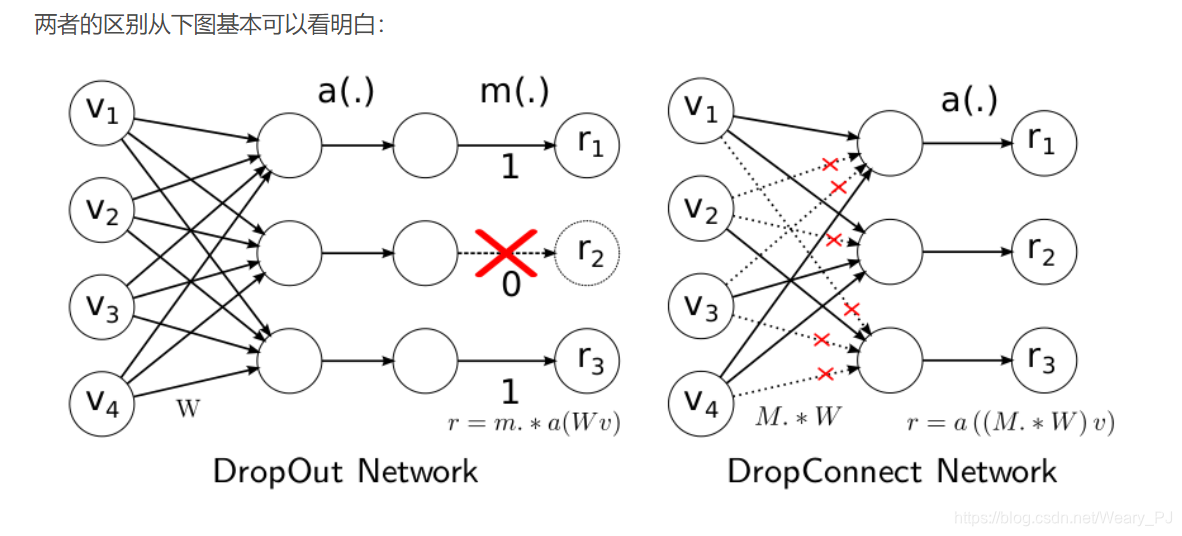
结合上图, No-Drop Network就是常见的全连接层,而我们知道全连接层因为参数众多,计算量大容易产生过拟合,所以发明了Dropout这种方法,它其实就是在训练的过程中,随机删除一些隐藏层,如上图的红叉.而DropConnect的区别看下面一张图就很好理解了
Data augmentation
当CNN应用于视觉对象识别时,通常利用数据增广来生成额外的数据,而不引入额外的标记成本
下面的这篇文章介绍了一些常用的数据增强的方法,也做了通俗易懂的介绍
可以看看这篇文章: 数据增强(Data Augmentation)
比如AlexNet就使用了2种数据增强的方式
- 生成图像平移和水平反射
- 改变训练图像中RGB通道的强度

关于AlexNet可以看看这篇文章: 卷积神经网络之AlexNet
Pre-training and fine-tuning 预训练与微调
- 预训练是指用预先训练好的参数来初始化网络,而不是随机设置参数。在基于CNNs的模型中,它具有加快学习速度、提高泛化能力等优点,因此得到了广泛的应用.
- 微调是优化模型以适应特定任务和数据集的关键阶段。一般来说,微调需要新训练数据集的类标签,用于计算损失函数。在这种情况下,新模型的所有层都将基于预先训练的模型进行初始化
DL笔记:预训练(pre-training/trained)与微调(fine tuning)

这种情况大多数应用于迁移学习当中,当新任务的数据量较小时,之前类似的任务数据量较多时,可以使用之前训练的参数作为初始参数来训练新任务。
除了上述正则化方法外,还有其他常用方法,如权重衰减、权重捆绑等
- 权重衰减(Weight Decay)的工作原理是在代价函数中增加一个额外的项来惩罚参数,阻止它们精确地建模训练数据,从而有助于推广到新的例子.通过减少卷积神经网络中的参数数量
- 权重捆绑允许模型学习输入数据的良好表示。以降低模型的参数并提高其性能
另一个值得注意的有趣的事情是,这些规则化的训练技术并不是相互排斥的,它们可以结合起来以提高性能.
CNN architecture
下面的表格中列出了几种典型CNN模型的结构和它们的主要贡献。

尽管各种模型已经取得了顶级的分类性能,但CNN相关的模型和应用并不仅仅局限于图像分类。基于这些模型,新的框架已经衍生出来,以解决其他具有挑战性的任务,如对象检测、语义分割等。
有两个著名的衍生框架:RCNN(具有CNN特征的区域)和FCN(全卷积网络),主要用于对象检测和语义分割,如下图所示。
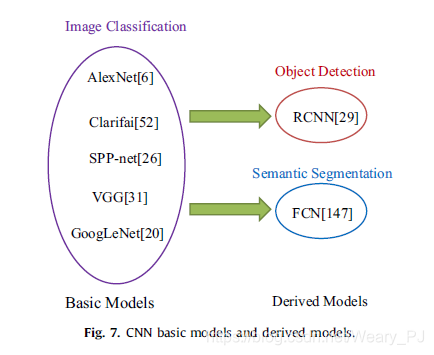
RCNN
RCNN的核心思想是生成多个目标建议,利用CNN从每个建议中提取特征,然后用类别特定的线性SVM对每个候选窗口进行分类。
然而,RCNN的性能过于依赖于目标定位的精度,从而限制了其鲁棒性。此外,大量提案的产生和处理也会降低其效率。最近的发展主要集中在这两个方面。
FCN
RCNN将CNN模型作为特征抽取器,对网络不做任何改变。相比之下,FCN提出了一种将CNN模型重构为完全卷积网络的技术。重铸技术消除了图像分辨率的限制,可以有效地产生相应尺寸的输出。尽管FCN主要用于语义分割,但该技术也可以应用于其他应用,如图像分类、边缘检测等。
除了创建各种模型外,这些模型的使用还表现出以下几个特点:
- Large networks.
一个直观的想法是通过增加cnn的大小来改进cnn的性能,包括增加深度(级别的数量)和宽度(每个级别的单元数量)。上述的GoogLeNet和VGG都采用了相当大的网络,分别为22层和19层,说明增大尺寸有利于提高图像识别精度。
联合训练多个网络可以比单个网络带来更好的性能。还有许多研究人员通过在级联模式下组合不同的深层结构来设计大型网络,其中前一个网络的输出被后一个网络利用,如图8所示。
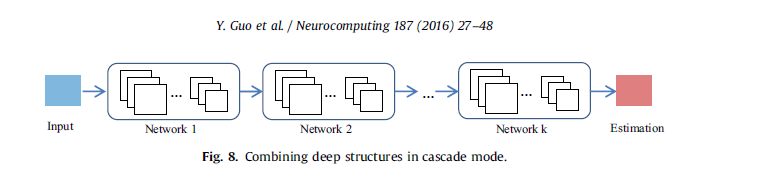
级联结构可以用来处理不同的任务,并且先前网络的功能(即输出)可能随任务的不同而变化。例如,Wang等人。连接两个网络进行目标提取,第一个网络用于目标定位。因此,输出的是对象的对应坐标。Sun等人。提出了三层精心设计的卷积网络来检测面部关键点。第一级提供了高度稳健的初始估计,而随后的两级对初始预测进行了微调。同样,欧阳等人采用了曾等提出的多阶段培训方案,即前一阶段的分类器与当前阶段的分类器共同处理误分类样本。
- Multiple networks.
当前应用中的另一个趋势是组合多个网络的结果,其中每个网络可以独立地执行任务,而不是设计一个单一的体系结构并联合训练内部的网络来执行任务,如图9所示。
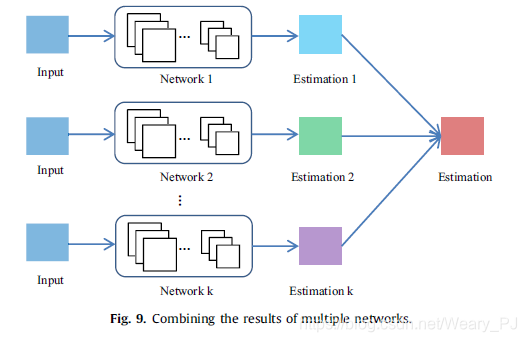
- Diverse networks
除了改变CNN的结构,一些研究人员还试图引入其他来源的信息,例如将它们与浅层结构结合,整合上下文信息,如图10所示。
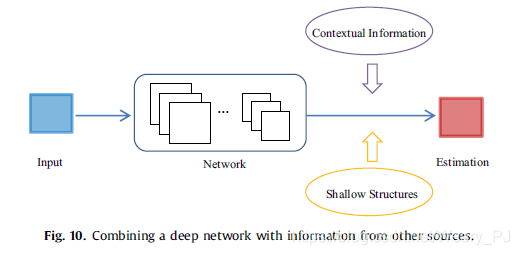
浅显的方法可以使我们对问题有更多的了解。在文献中,可以找到将浅层方法与深度学习框架相结合的例子[35],即采用深度学习方法提取特征并将这些特征输入到浅层学习方法中,例如支持向量机。最具代表性和最成功的算法之一是RCNN方法,它将高度独特的CNN特征输入到支持向量机中,以完成最终的目标检测任务。除此之外,深层CNNs和Fisher向量(FV)是互补的,它们还可以结合起来显著提高图像分类的精度。
总结
论文主要阐述了CNN的架构,流程等内容
包括了传统CNN的三层架构, 卷积,池化,全连接, 另外还介绍了三种经典的池化层
对于过拟合现象的处理, 提出了Dropout,DroConnect
还介绍了 数据增强 预训练与微调等概念
最后,对于几种经典的CNN架构做了简单的介绍,详细的还需要自己去查阅文献来了解
下一个部分就是RBMs
2.2. 受限玻尔兹曼机器(RBMs)
受限玻尔兹曼机(RBM)原理总结
受限Boltzmann机是一种生成型随机神经网络,由Hinton等人提出。1986年[53]。RBM是Boltzmann机器的一个变种,其限制条件是可见单元和隐藏单元必须形成一个二分图。这种限制允许更有效的训练算法,特别是基于梯度的对比散度算法[54]。
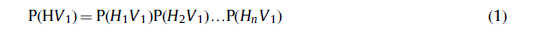
利用RBMs作为学习模块,我们可以构建以下深层模型:deep-confidence网络(DBNs)、deep-Boltzmann机器(DBMs)和深层能量模型(dem)。三种模型之间的比较如图11所示。
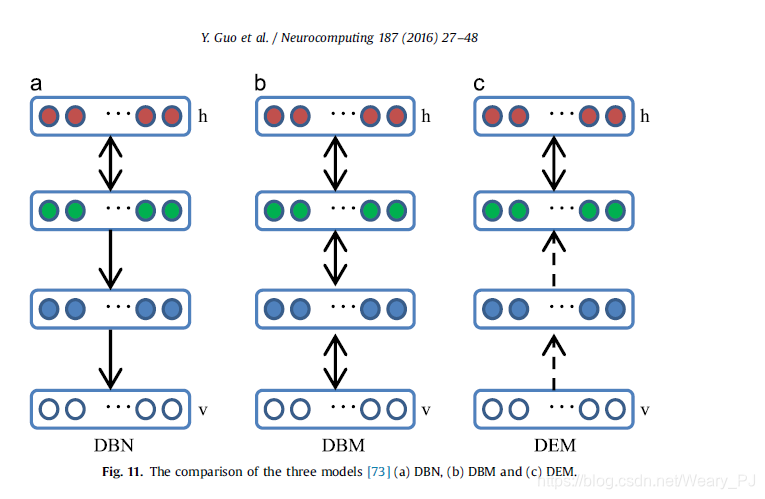
DBN在顶部两层有无向连接,形成RBM,并有指向性连接到下层。所有网络层之间的连接都是无定向的。DEM的下层有确定性隐藏单元,顶层隐藏层有随机隐藏单元。
表2总结了这三种深度模型以及相关的代表性参考文献。
Deep Belief Networks (DBNs)
(DBN)的提出是深度学习的一个重大进步。它是一个概率生成模型,它提供了观测数据和标签的联合概率分布。DBN首先利用一种高效的逐层贪婪学习策略初始化深层网络,然后结合期望的输出对所有权值进行微调。贪婪学习过程有两个主要的优点[58]:
(1)它可以生成适当的网络初始化,解决了参数选择的困难,在一定程度上可能导致局部最优值较差;(2)学习过程是无监督的,并且不需要类标签,因此它消除了训练时标记数据的必要性
然而,创建一个DBN模型是一项计算成本很高的任务,需要训练多个RBM,并且不清楚如何近似最大似然训练来进一步优化模型[12]。
DBNs成功地将研究人员的注意力集中在深度学习上,因此,产生了许多变体[59–62]。Nair等人。[60]开发了一个改进的DBN,其中顶层模型使用三阶Boltzmann机器进行对象识别。[59]中的模型使用稀疏RBMs学习了自然图像的两层模型,其中第一层学习局部、定向的边缘滤波器,第二层捕捉各种轮廓特征以及角点和连接点。为了提高对遮挡和随机噪声的鲁棒性,Lee等。[63]应用了两种策略:一种是利用DBN第一层的稀疏连接对模型进行正则化,另一种是开发一种概率去噪算法。
当应用于计算机视觉任务时,DBNs的一个缺点是它们没有考虑输入图像的2D结构。为了解决这个问题,人们引入了卷积的深度信念网络(CDBN)[61]。CDBN通过引入卷积RBMs,利用相邻像素的空间信息,生成一个平移不变的生成模型,该模型能很好地适应高维图像的缩放。在文献[64]中进一步扩展了该算法,在人脸验证中取得了良好的性能。
Deep Boltzmann Machines (DBMs)
由Salakhutdinov等人提出的深玻尔兹曼机(DBM)。[65]是另一种深度学习算法,其中单元再次分层排列。与dbn相比,dbn的前两层形成无向图形模型,而下层形成有向生成模型,DBM在其结构中具有无向连接。
与RBM一样,DBM也是Boltzmann家族的一个子集。不同之处在于,DBM具有多层隐藏单元,奇数层中的单元有条件地独立于偶数层,反之亦然。由于隐藏单元之间的相互作用,计算隐藏单元上的后验分布不再具有可操作性。在训练网络时,DBM会联合训练一个特定的无监督模型的所有层,而不是直接使似然最大化,而是使用基于随机极大似然(SML)[161]的算法来最大化似然下限,i、 在每次参数更新之间使用马尔可夫链蒙特卡罗(MCMC)方法只执行一次或几次更新。为了避免陷入局部极小,从而使许多隐藏单元失效,在对DBM网络进行预训练时,还将贪婪的分层训练策略加入到各层中,这与DBN的方法非常相似[12]。
这种联合学习在深层特征学习者的可能性和分类性能方面都带来了很好的改进。然而,DBMs的一个关键缺点是近似推理的时间复杂度远远高于DBNs,这使得联合优化DBM参数对于大数据集是不现实的。为了提高数据库管理系统的效率,一些研究人员引入了一种近似推理算法[66,67],该算法利用一个单独的“识别”模型来初始化所有层中潜在变量的值,从而有效地加快了推理速度。
还有许多其他方法旨在提高数据库管理系统的有效性。改进可以在训练前[68,69]或训练阶段[70,71]进行。例如,Montavon等人。[70]引入了定心技巧,提高了DBM的稳定性,使其更具区分性和生成性。利用多预测训练方案[72]对DBM进行联合训练,在图像分类方面优于文献[71]提出的方法。
Deep Energy Models (DEMs)
深部能量模型(DEM),由Ngiam等人介绍。[73]是训练深层架构的较新方法。与具有多个随机隐层特性的DBNs和DBMs不同,DEM只有一层随机隐单元,可以进行有效的训练和推理。
该模型利用深度前馈神经网络对能源景观进行建模,能够同时训练各层。通过对自然图像的性能评价,证明了多层联合训练比贪婪分层训练在质量和数量上都有了提高。Ngiam等人。[73]使用混合蒙特卡罗(HMC)训练模型。还有其他选项,包括对比差异、分数匹配等。类似的工作可以在[74]中找到。
虽然RBMs不像CNNs那样适合视觉应用,但也有一些将RBMs应用于视觉任务的好例子。形状Boltzmann机器是由Eslami等人提出的。[168]处理二元形状图像的建模任务,该任务学习对象形状上的高质量概率分布,以实现分布样本的真实性和对同一形状类新示例的泛化。Kae等人。[169]结合CRF和RBM对人脸分割中的局部结构和全局结构进行建模,一致地减少了人脸标注的误差。提出了一种新的手机识别深度体系结构[170],它将平均协方差RBM特征提取模块与标准DBN相结合。这种方法既解决了GMMs的代表性低效率问题,又解决了以往将DBNs应用于电话识别的一个重要局限性。
2.3. Autoencoder 自动编码器
自动编码器是一种特殊类型的人工神经网络,用于学习高效编码[75]。不是训练网络去预测给定输入X的某个目标值Y,而是训练一个自动编码器来重建它自己的输入X,因此输出向量与输入向量具有相同的维数。自动编码器的一般过程如图12所示在此过程中,通过最小化重构误差来优化自动编码器,并以相应的代码作为学习特征。
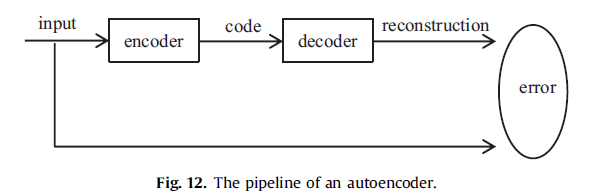
一般来说,单一的图层无法得到原始数据的有区别和代表性的特征。研究人员现在使用deep自动编码器,它将从上一个自动编码器学到的代码转发到下一个,来完成他们的任务。
深度自动编码器最早由Hinton等人提出,并在最近的论文中得到了广泛的研究。深度自动编码器通常使用反向传播的变体进行训练,例如共轭梯度法。尽管通常相当有效,但如果前几层中存在错误,该模型可能会变得相当无效。这可能导致网络学习重建训练数据的平均值。解决这个问题的一个适当方法是用近似于最终解的初始权值对网络进行预训练。也有一些自动编码器的变体被提出,以使表示尽可能“恒定”相对于输入的变化。
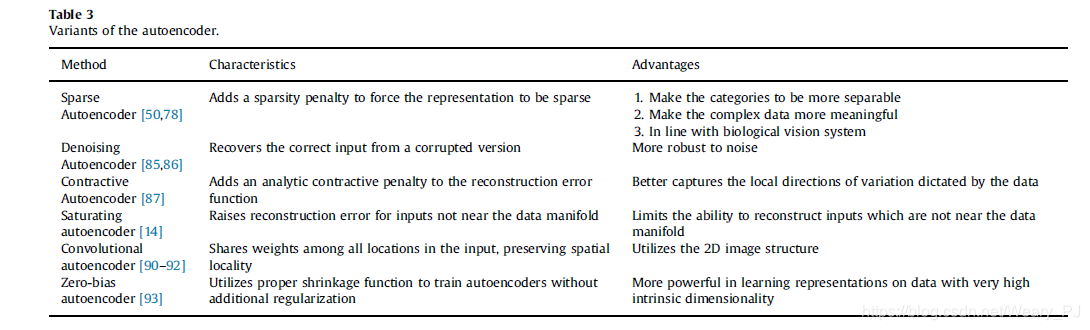
在上表中,列出了一些众所周知的自动编码器变体,并简要总结了它们的特点和优点。在下一节中,我们将描述三个重要的变体:稀疏自动编码器、去噪自动编码器和压缩式自动编码器。
Sparse autoencoder 稀疏自动编码器
稀疏自动编码器的目标是从原始数据中提取稀疏特征。表示的稀疏性可以通过惩罚隐藏单元偏差[50,59,80]来实现,也可以通过直接惩罚隐藏单元激活的输出来实现[81,82]。
稀疏表示有几个潜在的优点[50]:1)使用高维表示增加了不同类别很容易分离的可能性,就像在支持向量机理论中一样;2)稀疏表示为我们提供了一个简单的解释复杂的输入数据,以数个“部分”;3) 生物视觉在早期视觉区域使用稀疏表示[83]。
稀疏自动编码器的一个非常著名的变体是具有池和局部对比度标准化的九层局部连接稀疏自动编码器[84]。该模型允许系统训练人脸检测器,而不必标记图像是否包含人脸。所得到的特征检测器对平移、缩放和平面外旋转具有鲁棒性。
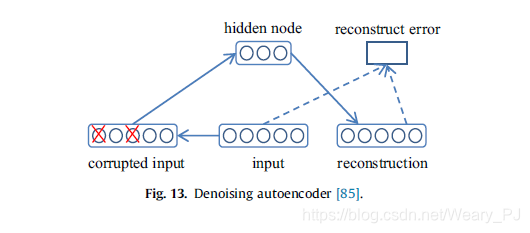
Denoising autoencoder 去噪自动编码器
为了提高模型的鲁棒性,文森特提出了一种称为去噪自动编码器(DAE)[85,86]的模型,它可以从损坏的版本中恢复正确的输入,从而迫使模型捕捉输入分布的结构。DAE的处理如图13所示。
Contractive autoencoder 收缩式自动编码器
收缩式自动编码器(CAE),由Rifai等人提出。[87],紧随DAE之后,并分享了学习鲁棒表示的类似动机[12]。DAE通过在训练集中注入噪声使整个映射具有鲁棒性,CAE通过在重构误差函数中加入解析压缩惩罚来实现鲁棒性。
尽管DAE和CAE之间的显著差异由Bengio等人指出。[12] ,Alain等人。[88]建议的DAE和CAE的一种形式是密切相关的:一个具有小腐败噪声的DAE可以被看作是一种CAE类型,其中压缩惩罚是对整个重建函数的,而不仅仅是在编码器上。DAE和CAE都已成功应用于无监督和转移学习挑战[89]。
2.4 Sparse coding 稀疏编码
稀疏编码的目的是学习描述输入数据的一组过完备的基本函数。稀疏编码有许多优点:
(1)它可以通过使用多个基,并捕获共享基的相似描述符之间的相关性来更好地重建描述符;
(2)稀疏性允许表示能够捕获图像的显著特性;
(3)这与生物视觉系统一致,后者认为信号的稀疏特征对学习是有用的;
(4) 图像统计研究表明,图像块是稀疏信号
(5)具有稀疏特征的模式更具线性可分性。
理解稀疏编码
3.应用和结果
深度学习已广泛应用于计算机视觉的各个领域,如图像分类、目标检测、图像检索与语义分割、人体姿态估计等。在这一部分中,我们将简要地总结这五个方面的研究进展(所有的结果都来自于原始论文),特别是基于CNN的算法。
3.1. 图像分类
如图所示,图像分类任务包括以存在特定可视对象类的概率标记输入图像[129]。

在论文里面,提到了多种用于图像分类的方法
3.2. 目标检测
目标检测不同于图像分类任务,但与之密切相关。在图像分类中,利用整个图像作为输入,估计图像中目标的类别标签。对于目标检测,除了输出给定类存在的信息外,我们还需要估计实例(或多个实例)的位置,如图19所示。如果输出的边界框与地面真实物体有足够大的重叠(通常超过50%),则认为检测窗口是正确的。
3.3. 图像检索
图像检索的目的是查找包含与查询图像中的相似对象或场景的图像,如图20所示。

3.4. 语义切分
在过去的半年里,大量的研究集中在语义切分任务上,取得了可喜的进展。它们成功的主要原因来自于CNN模型,它能够在大规模数据集上处理预先训练的网络的像素级预测。与图像级分类和对象级检测不同,语义分割要求输出掩码具有二维空间分布。在语义分割方面,最新和最先进的基于CNN的方法可以概括如下:
(1) Detection-based segmentation.
(2) FCN-CRFs based segmentation.
(3) Weakly supervised annotations
3.5. 人体姿态估计
人体姿势估计的目的是从静止图像或图像序列中估计人体关节的定位,如图21所示。它在视频监控、人类行为分析、人机交互(HCI)等广泛的潜在应用中非常重要,并且最近正在被广泛研究。然而,由于人类外貌的巨大变化,复杂的背景,以及许多其他干扰因素,如光照、视角、尺度等,这一任务也非常具有挑战性。在这一部分中,我们主要总结了从静态图像中估计人的清晰度的深度学习方案,尽管这些方案可以与运动功能相结合,进一步提升视频性能。
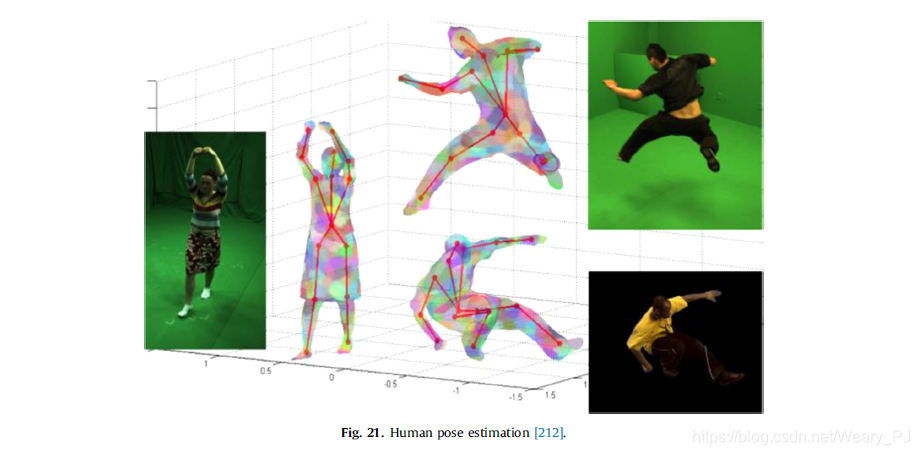
通常,人体姿态估计涉及到图像中的人的识别、人体部位的检测与描述、人体空间形态的建模等多个问题。在深入学习之前,最好的人体姿势估计方法是基于人体部位检测器,即先检测并描述人体部位,然后在局部区域之间施加上下文关系。一种典型的基于零件的方法是图形结构[196],它利用树模型来捕捉相邻零件之间的几何关系,并通过各种著名的基于零件的方法进行了开发。
由于深度学习算法能够学习更能容忍干扰因素变化的高级特征,并在各种计算机视觉任务中取得了成功,近年来受到了研究界的广泛关注。
4.趋势和挑战
5.结论
本文对深度学习进行了全面的回顾,并提出了一个分类方案来分析现有的深度学习文献。根据深度学习算法的基本模型,将其分为四类:卷积神经网络、受限Boltzmann机器、自动编码器和稀疏编码。详细讨论和分析了这四个类的最新方法。对于在计算机视觉领域的应用,本文主要介绍了基于CNN的方法的进展,因为它是应用最广泛、最适合图像的方法。最值得注意的是,最近的一些文章报道了一些鼓舞人心的进展,表明一些基于CNN的算法已经超过了人类评分员的准确性。
尽管迄今报告的结果令人鼓舞,但仍有很大的进一步发展空间。例如,基本的理论基础还没有解释在什么条件下,他们将表现良好或优于其他方法,以及如何确定一个特定任务的最优结构。本文描述了这些挑战,并总结了设计和训练深层神经网络的新趋势,以及未来可能进一步探索的几个方向。


















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











