









在构建神经网络时,参数初始化是一个关键步骤,它影响模型的收敛速度和最终性能。合理的参数初始化可以帮助避免训练过程中出现的问题,如梯度消失或梯度爆炸,从而提高训练效率和模型的准确性。
1. 参数初始化的目的
加速收敛:良好的初始化可以使得网络更快地收敛到最优解。
避免梯度消失/爆炸:适当的初始权重可以防止在反向传播过程中梯度过小或过大。
提高模型性能:合理的初始化可以帮助模型在训练初期更好地捕捉数据的特征。
2. 常见的参数初始化方法
2.1 零初始化(Zero Initialization)
2.1.1 定义
零初始化是将神经网络中所有权重参数设置为0的初始化方法。这意味着在训练的开始阶段,每个神经元的输出是相同的,且没有任何有效的学习信号。
2.1.2 工作原理
在零初始化中,所有的权重被设置为0,而偏置可以设置为0或者其他的常数。在前向传播时,由于所有神经元的权重相同,其输出也会相同。这会导致在反向传播阶段,每个神经元接收到的梯度也相同,从而使得更新过程无效。
2.1.3 优缺点
优点:
简单易实现:零初始化是一种直观且易于实现的初始化方式。
缺点:
对称性问题:所有神经元的输出相同,导致所有权重在反向传播时接收到的梯度是相同的。这会阻止模型学习,因为所有的神经元在训练过程中会更新到相同的参数,无法进行有效的特征提取。
梯度消失:在真实的训练过程中,无论是线性激活还是非线性激活,零初始化都会导致网络的每一层都无法学习,因为它们都获得相同的梯度。
2.1.4 示例代码
以下是使用 Keras 设置零初始化的简简单示例:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, initializers
# 构建一个使用零初始化的神经网络
model_zero = keras.Sequential()
model_zero.add(layers.Dense(128, activation='relu', kernel_initializer=initializers.Zeros(), input_shape=(28*28,)))
model_zero.add(layers.Dense(10, activation='softmax'))
# 编译模型
model_zero.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 模型摘要
model_zero.summary()
2.1.5 使用建议
不推荐在深度学习中使用零初始化:由于其导致的对称性问题,零初始化通常不适用于深度神经网络。相反,常用的初始化方法如 Xavier 初始化和 He 初始化能更有效地打破对称性,使得网络能够有效学习。
可以用于偏置项初始化:在某些情况下,零初始化可以用于偏置项,因为偏置通常不需要打破对称性。
2.1.6 小结
零初始化虽然实现简单,但由于其固有的缺陷,特别是在多层神经网络中的对称性问题,通常不适合作为权重的初始化方法。为了确保更有效的学习,推荐使用其他更为复杂的初始化方法(如 He 或 Xavier 初始化)。
2.2 随机初始化(Random Initialization)
2.2.1 定义
随机初始化是为神经网络的权重赋予较小的随机值,而不是使用零或常数。这种方法帮助打破神经元之间的对称性,从而使得神经网络能够更有效地学习。
2.2.2 工作原理
在随机初始化中,权重通常会从某种分布中随机抽取,例如:
均匀分布:权重从固定范围内的均匀分布中抽取。
正态分布:权重从平均值为0的小方差的正态分布中抽取。
通过这种方式,神经网络中的每个权重都是独一无二的,这让每个神经元对输入数据有不同的响应,有助于提高学习效果。
2.2.3 优缺点
优点:
打破对称性:随机初始化能够避免所有神经元学习到相同的特征,允许它们学习到不同的表示。
提高学习效率:随机权重可以在前向传播中产生不同的激活值,从而在反向传播中接收到不同的梯度,改善学习动态。
缺点:
选择合适的范围:如果随机范围过大,可能导致梯度爆炸;如果范围过小,可能导致梯度消失。这需要在实践中仔细调整。
不适用所有激活函数:对于某些激活函数,随机初始化可能不是最佳选择。例如,ReLU 激活函数在权重初始化时可能会产生不良影响。
2.2.4 初始化的常用分布
均匀分布:通常设定在范围内随机生成权重,a 可以根据输入层和输出层的神经元数量进行调整。
正态分布:权重通常从均值为0,标准差为σ的正态分布中选取,其中 σ 的选择依赖于激活函数和网络深度。
2.2.5 示例代码
以下是使用 Keras 实现随机初始化的简单示例,包括均匀分布和正态分布的初始化:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, initializers
# 使用均匀分布随机初始化的神经网络
model_uniform = keras.Sequential()
model_uniform.add(layers.Dense(128, activation='relu',
kernel_initializer=initializers.RandomUniform(minval=-0.05, maxval=0.05),
input_shape=(28*28,)))
model_uniform.add(layers.Dense(10, activation='softmax'))
# 使用正态分布随机初始化的神经网络
model_normal = keras.Sequential()
model_normal.add(layers.Dense(128, activation='relu',
kernel_initializer=initializers.RandomNormal(mean=0.0, stddev=0.05),
input_shape=(28*28,)))
model_normal.add(layers.Dense(10, activation='softmax'))
# 编译模型
model_uniform.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model_normal.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 输出模型摘要
model_uniform.summary()
model_normal.summary()
2.2.6 使用建议
选择合适的初始化方法:在使用随机初始化时,应该根据具体任务和网络架构选择适合的分布和范围。对于较深的网络,建议使用更为复杂的初始化方法,如 Xavier 初始化或 He 初始化,以进一步改善学习性能。
监控训练过程:在训练过程中,监控损失函数和准确率等指标,以确保随机初始化没有导致问题。
2.2.7 小结
随机初始化是神经网络训练中的一种重要策略,通过随机赋值打破对称性,提高模型学习的灵活性和效率。这种方法通常被广泛应用,尤其是在与更深的神经网络和复杂任务结合时。了解和选择合适的随机初始化方法对于构建有效的神经网络至关重要。
2.3 Xavier 初始化(Glorot 初始化)
2.3.1 定义
Xavier 初始化,又称为 Glorot 初始化,是一种用于神经网络的权重初始化方法,由 Xavier Glorot 和 Yoshua Bengio 在 2010 年提出。它旨在帮助改善深度神经网络的训练效果,尤其是在使用 Sigmoid 或 Tanh 激活函数时。
2.3.2 工作原理
Xavier 初始化的核心思想是保持每一层输入和输出的方差相同。这种方法通过考虑神经元的数量来计算权重初始化的范围,确保信号在网络中传播时不会过度放大或缩小,从而避免梯度消失或梯度爆炸的问题。
对于一个具有 个输入和
个输出的层,权重矩阵
会被初始化为均值为0,方差为
的正态分布,公式为:
或者,可以从均匀分布中初始化,范围为,其中:
这两个公式的目标是保持输入和输出的方差一致,确保在整个网络中信号的稳定传播。
2.3.3 优缺点
优点:
有效性:在使用 Sigmoid 或 Tanh 等激活函数的深度网络中,Xavier 初始化通常能够有效地加速收敛,提高模型训练的成功率。
保持方差:通过控制权重的初始化范围,有助于避免梯度消失和梯度爆炸的问题。
缺点:
不适用于所有激活函数:对于使用 ReLU 或其变体的网络,Xavier 初始化可能不够理想,因此对这类激活函数建议使用 He 初始化。
2.3.4 示例代码
以下是使用 Keras 进行 Xavier 初始化的简单示例:
示例1:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, initializers
# 使用 Xavier 初始化的深度神经网络
model_xavier = keras.Sequential()
model_xavier.add(layers.Dense(128, activation='tanh',
kernel_initializer=initializers.GlorotNormal(),
input_shape=(28*28,)))
model_xavier.add(layers.Dense(64, activation='tanh',
kernel_initializer=initializers.GlorotNormal()))
model_xavier.add(layers.Dense(10, activation='softmax'))
# 编译模型
model_xavier.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 输出模型摘要
model_xavier.summary()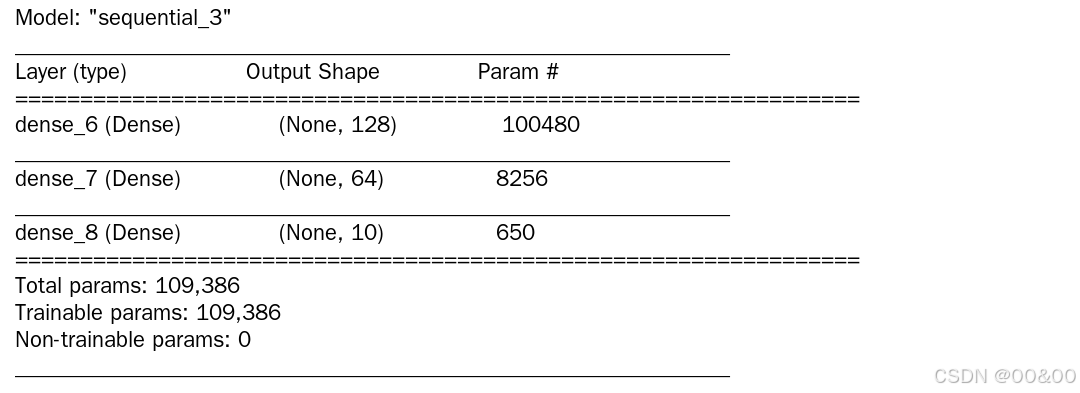 示例2:
示例2:
# 导入模块
import tensorflow as tf
# 进行实例化(正态化)
initializer_normal = tf.keras.initializers.glorot_normal()
# 进行实例化(标准化)
initializer_uniform = tf.keras.initializers.glorot_uniform()
# 采样得到权重
values_normal = initializer_normal(shape=(9,1))
values_uniform= initializer_normal(shape=(9,1))
# 打印结果
print('values_normal:\n',values_normal)
print('values_uniform:\n',values_uniform)
2.3.5 使用建议
选择合适的激活函数:Xavier 初始化适合用于 Sigmoid 和 Tanh 激活函数的网络。如果网络使用 ReLU 或其变体,则建议使用 He 初始化。
监控训练过程:在训练期间,检查损失和准确率,以验证 Xavier 初始化对模型训练的影响。
2.3.6 总结
Xavier 初始化是一种有效的神经网络权重初始化方法,使用适当的参数范围和分布,能够显著提高模型训练的效率和效果。了解它的应用场景和限制,对于优化神经网络模型非常重要。
2.4 He 初始化(He Initialization)
2.4.1 定义
He 初始化是由 Kaiming He 等人在 2015 年提出的一种权重初始化方法,旨在改善深度神经网络的训练效果,特别是在使用 ReLU(Rectified Linear Unit)及其变体(如 Leaky ReLU、Parametric ReLU 等)作为激活函数的网络中。
2.3.2 工作原理
He 初始化的主要思想是保持信号在网络中向前传递时的方差,使得每层的输入和输出的方差能够保持稳定。这有助于防止在深度网络中出现的梯度消失或梯度爆炸现象。
在使用 He 初始化时,权重参数 会从均值为0,标准差为
的正态分布中随机初始化,其中
是输入神经元的数量。具体公式如下:
这意味着在每层中,权重的初始化范围会根据输入层的神经元数量进行调整,以适应 ReLU 激活函数的特性。
2.4.3 优缺点
优点:
适合 ReLU 激活函数:He 初始化特别设计用于处理 ReLU 激活函数,因此在深层神经网络中,能有效避免梯度消失的问题。
加速收敛:通过合理的初始化,可以显著提高网络的训练速度和性能,使得模型更快收敛到最优解。
缺点:
不适于 Sigmoid 或 Tanh 激活函数:虽然 He 初始化对 ReLU 非常有效,但对于使用 Sigmoid 或 Tanh 的网络并不合适。在这种情况下,Xavier 初始化可能更为适用。
2.4.4 示例代码
以下是使用 Keras 中进行 He 初始化的简单示例:
示例1:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, initializers
# 使用 He 初始化的深度神经网络
model_he = keras.Sequential()
model_he.add(layers.Dense(128, activation='relu',
kernel_initializer=initializers.HeNormal(),
input_shape=(28*28,)))
model_he.add(layers.Dense(64, activation='relu',
kernel_initializer=initializers.HeNormal()))
model_he.add(layers.Dense(10, activation='softmax'))
# 编译模型
model_he.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 输出模型摘要
model_he.summary()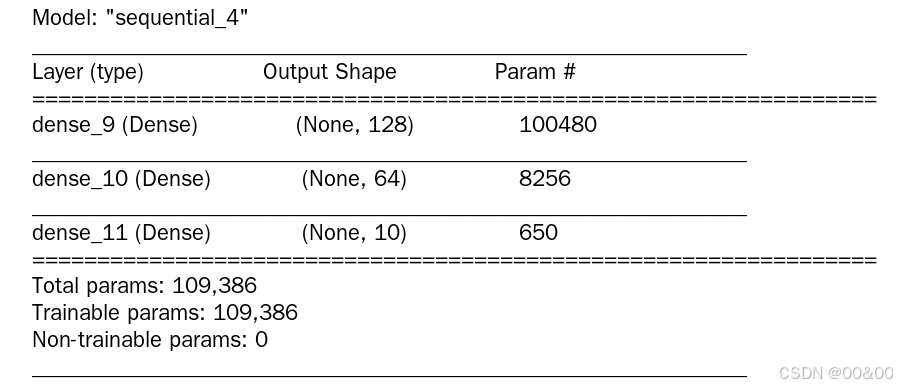
示例2:
# 导⼊⼯具包
import tensorflow as tf
# 进⾏实例化
initializer_normal = tf.keras.initializers.he_normal()
initializer_uniform = tf.keras.initializers.he_uniform()
# 采样得到权重值
values_normal = initializer_normal((9,1))
varlues_uniform = initializer_uniform((9,1))
# 打印结果
print('values_normal:\n',values_normal)
print('values_uniform:\n',values_uniform)
2.4.5 使用建议
适用场景:He 初始化推荐用于以 ReLU 为激活函数的深度学习模型。如果使用 Sigmoid 或 Tanh 等其他激活函数,则应考虑使用 Xavier 初始化。
监控训练过程:在训练神经网络时,观察损失值和准确度,以确定 He 初始化是否适合当前模型架构和任务。
2.4.6 小结
He 初始化是一种卓越的权重初始化方法,专门针对使用 ReLU 激活函数的网络设计。通过合理的权重初始化,不仅可以提高模型的训练效率,还有助于改善最终性能。了解 He 初始化的应用和限制,将有利于您在构建深度学习模型时做出更明智的选择。
3. 总结
参数初始化是神经网络训练中的一个重要环节,合理的初始化方法可以显著提高模型的训练效率和性能。通过选择适合的初始化策略,可以帮助模型更快地收敛,并避免常见的训练问题。了解不同的初始化方法及其适用场景,有助于在实际应用中做出更好的选择。


















 2336
2336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











