






 文章指出标准神经网络在分布变化下泛化难,提出新的加权平均策略DiWA。通过偏差 - 方差 - 协方差局部分解理论分析,表明增加模型多样性可减少协方差项。实验验证DiWA在DomainBed基准上持续提高技术水平,且无额外推理开销。
文章指出标准神经网络在分布变化下泛化难,提出新的加权平均策略DiWA。通过偏差 - 方差 - 协方差局部分解理论分析,表明增加模型多样性可减少协方差项。实验验证DiWA在DomainBed基准上持续提高技术水平,且无额外推理开销。
Diverse Weight Averaging for Out-of-Distribution Generalization
文章连接:DiWA
引理 1:说明权重平均和功能集成有类似的结果。
两个命题:只是单独说方差,协方差与泛化误差的关系,只提到了源数据,与比较无关。
摘要
在计算机视觉的分布变化下,标准神经网络难以泛化。幸运的是,结合多个网络可以持续改善分布外泛化。特别是,加权平均(WA)策略在竞争性的DomainBed基准上表现最好;它们直接平均多个网络的权重,尽管它们是非线性的。在本文中,我们提出了一种新的加权平均(DiWA)策略,其主要动机是增加平均模型之间的功能多样性。为此,DiWA平均了几次独立训练运行获得的权重:实际上,由于超参数和训练程序的差异,不同运行获得的模型比单次运行收集的模型更多样化。我们通过期望误差的新的偏差-方差-协方差局部分解来激发对多样性的需求,利用WA和标准功能集成之间的相似性。此外,这种分解强调,当方差项占主导地位时,WA成功,我们表明,当测试时间的边际分布发生变化时,WA就会成功。在实验上,DiWA在没有推理开销的情况下持续提高了DomainBed上的技术状态。
引言
学习具有良好泛化能力的鲁棒模型对于许多实际应用至关重要[1,2]。然而,经典的经验风险最小化(Empirical Risk Minimization, ERM)对分布偏移缺乏鲁棒性[3,4,5]。为了提高分类中的out- distribution (OOD)泛化,最近的一些研究提出在多个相关但不同的领域上同时训练模型[6]。虽然理论上很吸引人,但域不变方法[7]要么表现不如[8,9],要么只略微改善[10],[11]基于参考DomainBed基准的ERM[12]。目前,DomainBed上最先进的策略是对沿着训练轨迹获得的权重进行平均[13]。[14]认为这种加权平均(WA)在OOD中是成功的,因为它找到了更平坦的损失景观的解决方案。
在本文中,我们指出了这种基于平面度的分析的局限性,并为面向对象分析中WA的成功提供了新的解释。基于WA与集成[15]的相似性,集成是一种众所周知的提高鲁棒性的策略[16,17],可以对来自各种模型的预测进行平均。在文献[18]的基础上,我们提出了WA期望误差的偏差-方差-协方差-局部性分解。它包含四项:首先,我们在标签后验分布中显示的偏移增加的偏差(即相关位移[19]);其次,我们所显示的方差在输入边际分布移位(即多样性移位[19])下增加;第三,当模型多样化时,协方差减小;最后给出了平均模型权值的局部性条件。
在此基础上,我们的目标是利用多元加权平均(DiWA)方法获得权重可平均的多元模型。在实践中,DiWA对模型的权重进行平均从共享相同初始化的独立训练运行中获得。其动机是这些模型比单次运行获得的模型更加多样化[20,21]。然而,用批处理归一化[22]和ReLU层[23]平均独立训练网络的权重可能是违反直觉的。这种平均是有效的,特别是当模型可以通过低损失路径在权重空间中线性连接时。有趣的是,当运行从共享预训练初始化开始时,这种线性模式连接特性[24]得到了经验验证[25]。这种见解是DiWA的核心,也是其他近期作品的核心[26,27,28],如第6节所述。
总而言之,我们的主要贡献如下:
我们提出了一种新的基于预期误差偏差-方差-协方差局部分解的理论分析方法(第2节)。通过将相关位移与其偏差和多样性位移与其方差联系起来,我们表明,在多样性位移下,WA是成功的。
我们通过增加加权平均模型的多样性来处理协方差项。在我们的DiWA方法中,我们去关联它们的训练过程:在实践中,这些模型是从独立运行中获得的(第3节)。然后,我们从经验上验证了多样性提高了OOD性能(第4节),并表明DiWA在DomainBed基准[12]的所有真实数据集上都是最先进的(第5节)。
2 理论见解
在2.1节的设置下,我们在2.2节中引入WA,并在2.3节中分解其预期的OOD误差。然后,我们在第2.4节中分别考虑这种偏差-方差-协方差-局部性分解的四项。这种理论分析将使我们更好地理解WA何时成功,最重要的是,如何在第3节中进行实证改进。
2.1 符号和问题定义
记号 我们记
X
\mathcal{X}
X 为图像输入空间,
Y
\mathcal{Y}
Y 是标签空间,
l
:
Y
2
→
R
+
l:\mathcal{Y}^2\rightarrow \mathbb{R}_{+}
l:Y2→R+ 是损失函数。
S
S
S 是训练(源)域,分布为
p
S
p_S
pS,
T
T
T 是测试(目标)域,分布为
p
T
p_T
pT。为了简便,我们模糊地使用
p
S
,
p
T
p_S, p_T
pS,pT 去涉及
(
X
,
Y
)
(X,Y)
(X,Y) 的联合,后验和边际分布。记
f
S
,
f
T
:
X
→
Y
f_S, f_T:\mathcal{X}\rightarrow \mathcal{Y}
fS,fT:X→Y为源函数和目标标签函数。我们假设数据中没有噪声:
f
S
f_S
fS 定义在
X
S
≜
{
x
∈
X
/
p
S
(
x
)
>
0
}
,
∀
(
x
,
y
)
∼
p
S
,
f
S
=
y
\mathcal{X}_S \triangleq \{x\in \mathcal{X}/p_S(x)>0\}, \forall (x,y)\sim p_S,f_S=y
XS≜{x∈X/pS(x)>0},∀(x,y)∼pS,fS=y 上,
f
T
f_T
fT 定义在
X
T
≜
{
x
∈
X
/
p
T
(
x
)
>
0
}
,
∀
(
x
,
y
)
∼
p
T
,
f
T
=
y
\mathcal{X}_T \triangleq \{x\in \mathcal{X}/p_T(x)>0\}, \forall (x,y)\sim p_T,f_T=y
XT≜{x∈X/pT(x)>0},∀(x,y)∼pT,fT=y 上。
问题 考虑一个神经网络,
f
(
,
˙
θ
)
:
X
→
Y
f(\dot, \theta):\mathcal{X}\rightarrow \mathcal{Y}
f(,˙θ):X→Y 由一个固定结构
f
f
f 和权重
θ
\theta
θ。我们寻找最小化目标泛化误差的
θ
\theta
θ
ε
T
=
E
(
x
,
y
)
∼
p
T
[
l
(
f
(
x
,
θ
)
,
y
]
.
\varepsilon_T=\mathbb{E}_{(x,y)\sim p_T}[l(f(x,\theta), y].
εT=E(x,y)∼pT[l(f(x,θ),y].
f
(
,
˙
θ
)
f(\dot, \theta)
f(,˙θ) 在
X
T
\mathcal{X}_T
XT 上逼近
f
T
f_T
fT。然而这在 OOD 的设置中是复杂的,因为我们在训练中只有来自
S
S
S 的数据,相关但与
T
T
T 不同。
S
S
S 和
T
T
T 之间的不同是由于分布漂移(
p
S
(
X
,
Y
)
≠
p
T
(
X
,
Y
)
p_S(X,Y)\neq p_T(X,Y)
pS(X,Y)=pT(X,Y))根据【19】分解为多样性漂移(又称协变量漂移,当边际分布不同时(即
p
S
(
X
)
≠
p
T
(
X
)
p_S(X)\neq p_T(X)
pS(X)=pT(X))和以及相关偏移(又名概念偏移,当后验分布不同时,即
p
S
(
Y
∣
X
)
≠
p
T
(
Y
∣
X
)
p_S(Y|X)\neq p_T(Y|X)
pS(Y∣X)=pT(Y∣X),且
f
S
≠
f
T
f_S\neq f_T
fS=fT)权重通常是在训练数据集
d
S
∈
S
d_S\in S
dS∈S(包含
n
S
n_S
nS 个从
p
S
(
X
,
Y
)
p_S(X,Y)
pS(X,Y) 独立同分布的样本,配置为
c
c
c ) 上学习,其中包含学习中的所有其他随机性来源(例如,初始化,超参数,训练随机性,epoch等)。我们称
l
S
=
{
d
S
,
c
}
l_S=\{d_S,c\}
lS={dS,c}为域
S
S
S 上的一个学习过程,并显式地将
θ
(
l
S
)
\theta (l_S)
θ(lS) 表示
1
/
n
∑
(
x
,
y
)
∈
d
S
l
(
f
(
θ
,
x
)
,
y
)
1/n \sum _{(x,y)\in d_S}l(f(\theta, x),y)
1/n∑(x,y)∈dSl(f(θ,x),y)在
l
S
l_S
lS下随机最小化后得到的权重。
2.2 OOD的加权平均和当前分析的局限性
权重平均。我们研究了组合
M
M
M 个个体成员权重
{
θ
m
}
m
=
1
M
≜
{
θ
(
l
S
(
M
)
)
}
m
=
1
M
\{\theta_m\}_{m=1}^M\triangleq \{\theta(l_S^{(M)})\}_{m=1}^M
{θm}m=1M≜{θ(lS(M))}m=1M 的好处,这些权重来自
M
M
M个(潜在相关)同分布(id)学习过程
L
S
M
≜
{
l
S
(
M
)
}
m
=
1
M
L_S^M\triangleq \{l_S^{(M)}\}_{m=1}^M
LSM≜{lS(M)}m=1M。在3.2节中讨论的条件下,尽管在架构
f
f
f 中存在非线性,但可以对这
M
M
M 个权重进行平均。加权平均(WA)[13]定义为:
f
W
A
≜
f
(
,
˙
θ
W
A
)
,
θ
W
A
≜
θ
W
A
(
L
S
M
)
≜
1
/
M
∑
m
=
1
M
θ
m
f_{WA}\triangleq f(\dot,\theta_{WA}), \theta_{WA}\triangleq \theta_{WA}(L_S^M)\triangleq 1/M \sum_{m=1}^M\theta_m
fWA≜f(,˙θWA),θWA≜θWA(LSM)≜1/Mm=1∑Mθm是目前 DomainBed[12]上的最新状态[14,29],其中权值
{
θ
m
}
m
=
1
M
\{\theta_m\}_{m=1}^M
{θm}m=1M沿单一训练轨迹采样(我们在附录C.2的注释1中对其进行了细化)。
基于平面度分析的局限性。为了解释这一成功,Cha等人[14]认为平坦最小值的泛化效果更好;事实上,WA使损失情况趋于平缓。然而,如附录B所示,这个分析并不能完全解释WA在DomainBed上的惊人结果。首先,平坦度不影响分布位移,因此OOD误差的上界是不受控制的(见附录B.1)。其次,该分析并没有阐明为什么WA在OOD泛化方面优于锐度感知最小化器(SAM)[30],尽管SAM直接优化了平面度(见附录B.2)。最后,它不能解释为什么WA和SAM结合在IID中成功[31],而在OOD中失败(见附录B.3)。这些观察结果激发了对WA的新分析;我们在下面提出一个更好地解释这些结果的方法。
2.3 偏差-方差-协方差局部分解
我们现在引入我们的偏方差-协方差-局域分解,它将偏方差分解[32]扩展到WA。在本理论部分的其余部分,为简单起见,l为均方误差:然而,我们的结果可以扩展到其他损失,如[33]。在这种情况下,权值为
θ
(
l
S
)
\theta(l_S)
θ(lS)的模型的期望误差w.r.t.学习过程
l
S
l_S
lS 在[32]中被分解为:
E
l
S
ε
T
(
θ
(
l
S
)
)
=
E
(
x
,
y
)
∼
p
T
[
b
i
a
s
2
(
x
,
y
)
+
v
a
r
(
x
)
]
,
(
B
V
)
\mathbb{E}_{l_S}\varepsilon _T(\theta(l_S))=\mathbb{E}_{(x,y)\sim p_T}[bias^2(x,y)+var(x)], (BV)
ElSεT(θ(lS))=E(x,y)∼pT[bias2(x,y)+var(x)],(BV)bias, var 分别是模型关于样本的偏差和方差,稍后在公式(BVCL)中定义。为了分解WA的误差,我们利用WA和功能集成(ENS)之间的相似性(已经在[13]中强调)[15,34],这是一种更传统的组合权重集合的方法。更准确地说,ENS平均了这些预测,
f
E
N
S
≜
f
E
N
S
(
,
˙
{
θ
m
}
m
=
1
M
)
≜
1
/
M
∑
m
=
1
M
f
(
,
˙
{
θ
m
}
m
=
1
M
)
)
f_{ENS}\triangleq f_{ENS}(\dot, \{\theta_m\}_{m=1}^M)\triangleq 1/M\sum_{m=1}^Mf(\dot, \{\theta_m\}_{m=1}^M))
fENS≜fENS(,˙{θm}m=1M)≜1/M∑m=1Mf(,˙{θm}m=1M)). 引理 1 表明在
{
θ
m
}
m
=
1
M
\{\theta_m\}_{m=1}^M
{θm}m=1M 在权重空间中是紧密的时候
f
W
A
f_{WA}
fWA 是
f
E
N
S
f_{ENS}
fENS 的一阶逼近。
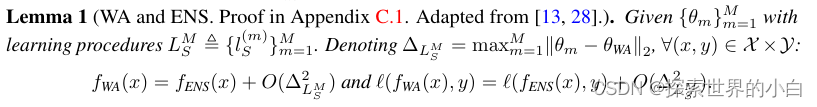
这种相似性是有用的,因为方程(BV)在[18,35]中被扩展为ENS的偏差-方差-协方差分解。然后,我们可以推导出WA的预期测试误差的以下分解。考虑到M个平均权重,期望是在描述M个同分布(id)学习过程
L
S
M
≜
{
l
S
(
m
)
}
m
=
1
M
L_S^M\triangleq \{l_S^{(m)}\}_{m=1}^M
LSM≜{lS(m)}m=1M的联合分布上.

方程(BVCL)将WA的OOD误差分解为四项。偏差与它的每个id成员的偏差相同。将WA的方差分为其每id个成员的方差除以M和一个协方差项。最后一个局部性项约束了权重,以保证近似的有效性。综上所述,组合M模型将方差除以M,但引入了协方差和局部性项,这些项需要沿偏差控制,以保证低OOD误差。
2.4 偏差-方差-协方差-局部分解分析
我们现在分析方程(BVCL)中的四个项。我们发现,偏差在相关性移位(第2.4.1节)下占主导地位,而方差在多样性移位(第2.4.2节)下占主导地位。然后,我们讨论了用不同模型减少的协方差(第2.4.3节)和当权重相似时减少的局部性项(第2.4.4节)之间的权衡。分析表明,当M较大时,当其成员在权重空间上多样但接近时,WA对多样性偏移是有效的。
2.4.1 偏差和相关偏移(和支持错配)

我们通过注意到
f
T
(
x
)
≜
E
p
T
[
Y
∣
X
=
x
]
f_T(x)\triangleq \mathbb{E}_{p_T}[Y|X=x]
fT(x)≜EpT[Y∣X=x] 和
f
S
(
x
)
≜
E
p
S
[
Y
∣
X
=
x
]
f_S(x)\triangleq \mathbb{E}_{p_S}[Y|X=x]
fS(x)≜EpS[Y∣X=x] 来分析第一项。该表达式证实了我们的相关移位项测量源和目标之间后验分布的移位,如[19]所示。它在存在虚假相关性时增加:例如,在colordmnist[8]上,颜色/标签的相关性在测试时是相反的。第二项是由源和目标之间的支持不匹配引起的。在[36]中对其进行了分析,并在他们的“学习DG的表示没有免费的午餐”中显示了不可约性。然而,如果我们将分析转置到特征空间而不是输入空间中,就可以解决这个问题。这促使将源域和目标域编码到共享的潜在空间中,例如,通过在具有最小领域特定信息的任务上预训练编码器,如[36]所示。
这个分析解释了为什么WA在相关偏移下失败,如附录h中的ColoredMNIST所示。的确,组合不同的模型并不能减少偏差。第2.4.2节解释了WA对多样性转移是有效的。
2.4.2 方差与多样性转移
已知OOD中的方差很大[5],并导致一种称为规格不足的现象,即尽管测试IID精度相似,但在OOD中模型的行为却不同。我们现在在一个简化的环境中将OOD方差与多样性转移[19]联系起来。我们修复了源数据集
d
S
d_S
dS(具有输入支持
X
d
S
X_{d_S}
XdS)、目标数据集
d
T
d_T
dT(具有输入支持
X
d
T
X_{d_T}
XdT)和网络初始化。在假设2和假设3下,我们得到了所有其他随机性来源的方差的封闭表达式。
假设 2 (内核机制)
f
f
f 符合内核机制【37,38】
这表明
f
f
f 表现为高斯过程(GP);如果它是一个广泛的网络是合理的[37,39]。相应的核K为神经切线核(NTK)[37],仅取决于初始化。GP是有用的,因为它们的方差有一个封闭的表达式(附录C.4.1)。为了简化方差的表达式,我们现在做假设3。
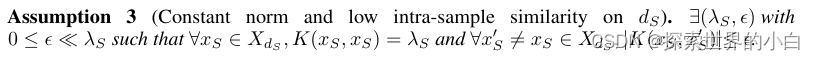
这表明训练样本具有相同的范数(遵循标准实践[39,40,41,42])并且弱交互[43,44]。附录C.4.2进一步讨论并放宽了这一假设。当
ϵ
→
0
\epsilon \rightarrow 0
ϵ→0时,我们现在可以把方差和多样性联系起来。

MMD根据经验估计输入边际的移位,即
p
S
(
X
)
p_S(X)
pS(X)和
p
T
(
X
)
p_T(X)
pT(X)之间的移位。因此,我们的方差表达式类似于[19]中的多样性移位公式:MMD取代了[19]中使用的L1散度。其他项,
λ
T
\lambda _T
λT 和
β
T
\beta _T
βT,都涉及到对目标数据集
d
T
d_T
dT的内部依赖:它们是常量w.r.t.
X
d
T
X_{d_T}
XdT,不依赖于分布移位。在固定
d
T
d_T
dT和我们的假设下,式(4)表明,当
X
d
S
X_{d_S}
XdS和
X
d
T
X_{d_T}
XdT更接近时(对于内核K2定义的MMD距离),
d
T
d_T
dT的方差减小,当它们偏离时,
d
T
d_T
dT的方差增大。直观地说,
X
d
T
X_{d_T}
XdT离
X
d
S
X_{d_S}
XdS越远,模型对
X
d
T
X_{d_T}
XdT的预测在拟合
d
S
d_S
dS后受到的约束就越小。
该分析表明,WA减少了多样性转移的影响,因为组合M个模型将每M的方差分开。这是一个不需要来自目标域的数据就能实现的强大特性。
2.4.3 协方差和多样性
当 { f ( , ˙ θ m ) } m = 1 M \{f(\dot, \theta_m)\}_{m=1}^M {f(,˙θm)}m=1M的预测相关联时,协方差项增加。在所有预测都相同的最坏情况下,协方差等于方差,WA不再有用。另一方面,协方差越低,WA对其成员的增益越大;这是通过比较公式(BV)和(BVCL)得出的,详见附录C.5。它通过鼓励成员做出不同的预测来激励协方差的解决,从而实现功能的多样化。多样性是一个在集合文献中被广泛分析的概念[15],为此引入了许多测量方法[45,46,47]。在第3节中,我们的目标是去相关的学习过程,以增加成员的多样性和减少协方差项。
2.4.4 局部性和线性模式连通性
为了确保WA近似于ENS,最后一个局部性项 O ( Δ ˉ 2 ) O(\bar{\Delta}^2) O(Δˉ2)约束权重接近。然而,在第2.4.3节中分析的协方差项是拮抗的,因为它激发了功能多样化的模型。总的来说,为了减少WA在OOD中的误差,我们在多样性和局部性之间寻求一个很好的权衡。在实践中,我们认为这个局部性项的主要目标是确保权重是平均的,尽管在NN中存在非线性,使得WA的误差不会爆炸。这就是为什么在第3节中,我们根据经验放宽了局域性约束,简单地要求权重在损失图中是线性可连通的,就像在线性模式连通性中一样[24]。我们在稍后的图1中经验验证,即使在这种情况下,近似 f W A ≈ f E N S f_{WA}\approx f_{ENS} fWA≈fENS仍然有效。
3 DiWA:多样性权重平均
3.1 动机:从不同的运行中平均权重,以获得更多的多样性
以前的WA方法的局限性。我们在第2.4.1节和2.4.2节中的分析表明,偏差和方差项主要由手边的分布移位固定。相比之下,协方差项可以通过加强从学习过程
{
l
S
(
m
)
}
m
=
1
M
\{l_S^{(m)}\}_{m=1}^M
{lS(m)}m=1M中获得的模型之间的多样性来减少(第2.4.3节)。然而,以前的方法[14,29]只在单次运行中获得平均权重。这对应于高度相关的过程,它们共享相同的初始化、超参数、批处理顺序、数据增强和噪声,只是训练步骤的数量不同。因此,这些模型在很大程度上是相似的:这并没有充分利用WA的潜力。
DiWA。我们的多样化加权平均方法旨在减少式(BVCL)中的OOD预期误差通过减少预测间的协方差来消除学习过程的关联。我们的权重是由
M
≥
1
M\ge 1
M≥1次不同的运行获得的,学习过程不同:它们具有不同的超参数(学习率、权重衰减和退出概率)、批处理顺序、数据增强(例如,随机作物、水平翻转、颜色抖动、灰度化)、随机噪声和训练步骤数。因此,相应的模型在T /域上更加多样化[21],并且在M较大时减小了方差的影响。然而,如果权重太过遥远,这可能会打破2.4.4节中分析的局部性要求。经验表明,DiWA在两种条件下工作:共享初始化和温和的超参数范围。
3.2 方法:共享初始化,温和的超参数搜索和权重选择
初始化共享。共享初始化条件如下[25]:当模型从共享预训练模型进行微调时,它们的权值可以沿着线性路径连接,误差保持在较低的水平[24]。按照DomainBed[12]的标准实践,我们的编码器在ImageNet[48]上进行预训练;这种预训练是关键,因为它控制偏差(通过定义特征支持不匹配,见第2.4.1节)和方差(通过定义内核K,见附录C.4.4)。关于分类器初始化,我们测试了两种方法。首先是随机初始化,这可能会扭曲特征[49]。第二种是线性探测(Linear Probing, LP)[49]:它首先学习分类器(同时冻结编码器)作为共享初始化。然后,LP在随后的M次运行中一起微调编码器和分类器;局部性项越小,权重越接近(见[49])。
轻度超参数搜索。如图5所示,极端的超参数范围导致权重的平均值可能表现不佳。事实上,从极端不同的超参数得到的权重可能不是线性可连通的;它们可能属于损失景观的不同区域。因此,在我们的实验中,我们使用表7中定义的温和搜索空间,该空间首次在SWAD中引入[14]。这些超参数范围产生了不同的模型,这些模型在权重上是平均的。
权重选择。我们方法的最后一步(在算法1中总结)是选择在可用的权重中平均哪些权重。我们探讨了两个简单的权重选择协议,如[28]。第一个均匀地取所有权重的平均值;这是实用的,但可能表现不佳,当一些运行是有害的。第二个限制([28]中的贪心)通过限制所选权重的数量来解决这个缺点:权重按照验证精度降序排列,只有当它们提高了DiWA的验证精度时才依次添加。
在接下来的章节中,我们用实验验证了我们的理论。首先,第4节证实了我们在OfficeHome数据集[50]上的发现,其中多样性转移占主导地位19。然后,第5节表明DiWA是DomainBed上的最新技术[12]。
4 对我们的理论见解进行实证验证
我们考虑在OfficeHome[50]中的“Clipart”、“Product”和“Photo”域上训练了几个权重
{
θ
m
}
m
=
1
M
(
2
≤
M
<
10
)
\{\theta_m\}_{m=1}^M(2\leq M <10)
{θm}m=1M(2≤M<10)的集合,这些集合具有共享的随机初始化和温和的超参数范围。这些权重首先从单次运行(每50批)或从不同的运行中独立取样。他们会在OfficeHome的第四个域名“Art”上进行评估。
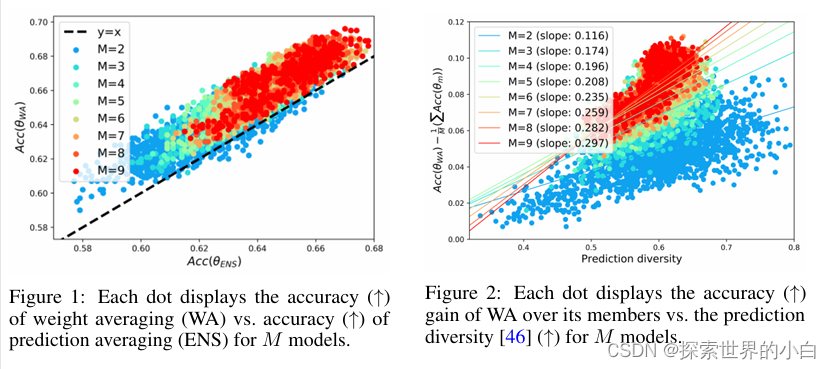
图1验证了引理1和
f
W
A
≈
f
E
N
S
f_{WA}\approx f_{ENS}
fWA≈fENS。更准确地说,
f
W
A
f_{WA}
fWA 略微但持续地改善了
f
E
N
S
f_{ENS}
fENS:我们在附录D中讨论了这一点。 且,更大的 M 提升结果;根据公式(BVCL),这促使对尽可能多的权重进行平均。相比之下,在测试时,大 M 对于ENS来说在计算上是不切实际的,需要M个转发。
多样性和准确性。我们在图2中验证了
f
W
A
f_{WA}
fWA 受益于多样性。在这里,我们用误差比来衡量多样性[46],即对
{
f
(
,
˙
θ
m
)
}
m
=
1
M
\{f(\dot, \theta_m)\}_{m=1}^M
{f(,˙θm)}m=1M中的一对进行测试时,不同误差数Nain与同时误差数
N
s
i
m
u
l
N_{simul}
Nsimul的比值
N
d
i
r
r
/
N
s
i
m
u
l
N_{dirr}/N_{simul}
Ndirr/Nsimul。平均水平高于2)配对意味着成员在相同的输入上出错的可能性较小。具体来说,随着多样性的增加,的增益比平均个体精度
1
M
∑
m
=
1
M
A
c
c
(
θ
m
)
\frac{1}{M}\sum_{m=1}MAcc(\theta_m)
M1∑m=1MAcc(θm)增加。此外,这种现象随着M的增大而加剧:线性回归的斜率(即每单位多样性的精度增益)随着M的增大而增加。这与方程(BVCL)中cov(z)的(M-1)/M因子一致,如附录E.1.2中进一步强调的那样。最后,在附录E.1.1中,我们证明了这一结论也适用于另一种已建立的多样性度量CKAC[47]。
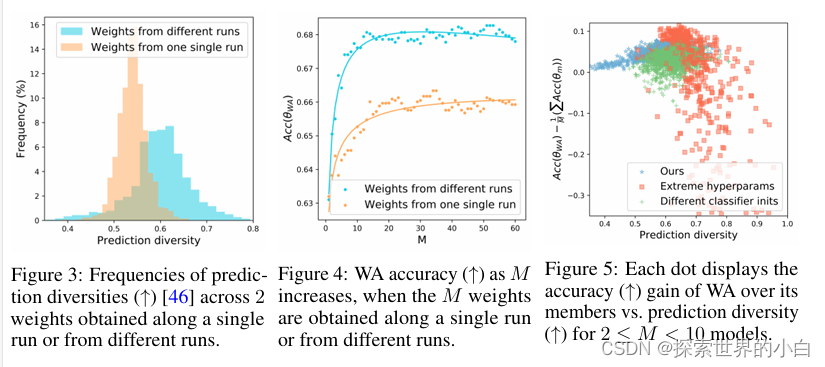
通过不同的运行增加多样性从而提高准确性。现在我们研究从单次运行和从不同运行中采样权重之间的区别。图3首先显示,当权重来自不同的运行时,多样性会增加。其次,在图4中,这反映在OOD的准确性上。在这里,我们根据验证精度对(1)从60个不同的运行获得的60个权重进行排序,(2)沿着1个运行良好的运行获得的权重。然后,当M从1增加到60时,我们考虑前M个权重的WA。两者的初始性能相同,并随着M的增加而提高;然而,不同运行的加权加权逐渐优于单次运行的加权加权。最后,图5显示,这只适用于温和的超参数范围和共享初始化。否则,当超参数分布非常极端时(如表7所定义),或者当分类器没有进行类似的初始化时,由于违反局部性条件,DiWA的性能可能比其成员差。这些实验证实,只要权重保持平均,多样性是关键。
5 实验结果 DomainBed benchmark
数据集。我们现在在DomainBed上给出我们的评估[12]。通过强加代码、训练过程和ResNet50[52]架构,DomainBed可以说是最公平的面向对象泛化基准。它包括5个多域真实世界数据集:PACS[51]、VLCS[53]、OfficeHome[50]、Terralncognita[54]和DomainNet[55]。[19]表明,在这些数据集中,多样性转移占主导地位。每个域被依次视为目标T,而其他域被合并到源S中。验证数据集从S中采样,即我们遵循DomainBed的训练域模型选择。实验设置在附录G.1中有进一步描述。我们的代码可在https://github.com/alexrame/diwa上获得。
基线。ERM是标准的经验风险最小化。Coral[10]是基于域不变性的最佳方法。SWAD (Stochastic Weight Averaging dense,随机加权平均)[14]和MA (Moving Average,移动平均)[29]在一个训练轨迹上平均权重,但在权重选择策略上有所不同。SWAD[14]是目前最先进的(SoTA),由于它的“过拟合感知”策略,但代价是每个数据集调整了三个额外的超参数(患者参数,过拟合患者参数和容差率)。相比之下,MA[29]很容易实现,因为它简单地将从第100批开始直到训练结束的所有检查点统一地组合在一起。最后,我们报告了在[29]中为昂贵的深度集成(DENS)15获得的分数:我们在附录D中讨论了其他集成策略。
我们的运行。ERM和DiWA在DomainBed中共享相同的训练协议:然而,与网格搜索只保持一次运行不同,DiWA利用了M次运行。在实践中,我们从表1中详细描述的超参数分布中抽样了20个配置,并报告了3个数据分割的平均值和标准差。对于每次运行,我们选择具有最高验证精度的epoch的权重。ERM和MA在20次运行中选择具有最高验证精度的模型,遵循DomainBed的标准实践。集成(ENS)平均所有M=20模型的预测(共享初始化)。DiWA-restricted用算法1选择1 < M < 20个权值,而DiWA-uniform对所有M= 20个权值进行平均。DiWAt对所有3个数据分割的M =3 x 20=60权重进行均匀平均。DiWAt受益于更大的M(没有额外的推理成本)和数据多样性(见附录E.1.3)。然而,由于计算原因,我们无法报告DiWAt的标准差。此外,DiWAt不能利用受限制的权重选择,因为验证不能在具有不同数据分割的所有60个权重之间共享。
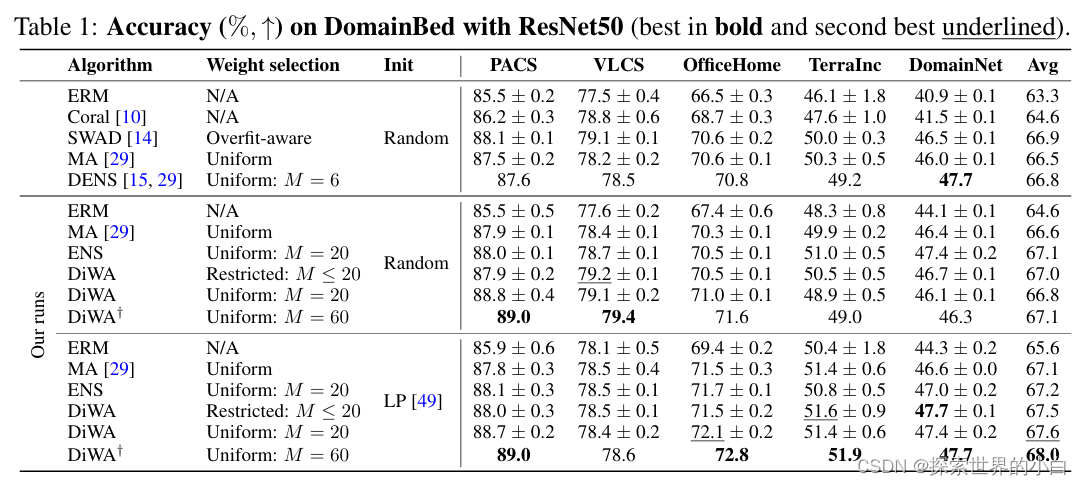
5.1 DomainBed 上的结果
我们在表1中报告了我们的主要结果,每个领域的详细信息见附录G.2。在随机初始化分类器的情况下,DiWA-uniform在PACS、VLCS和OfficeHome上是最好的,DiWA-uniform在PACS和OfficeHome上是第二好的。在TerraIncognita和DomainNet上,DiWA被一些糟糕的运行所惩罚,在DiWA限制中过滤,这改善了这些数据集上的结果。线性探测(LP)的分类器初始化[49]改进了OfficeHome、Terralncognita和DomainNet上的所有方法。在这些数据集上,DiWAt分别使MA提高了1.3点、0.5点和1.1点。平均后,DiWAt与LP建立了68.0%的新SoTA,将SWAD提高了1.1个点。
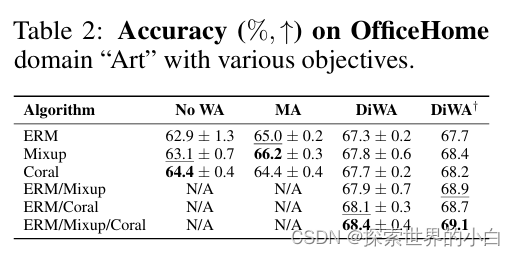
DiWA有不同的目标。到目前为止,我们使用的ERM没有利用域信息。表2显示了DiWA-uniform受益于Interdomain Mixup[56]和Coral[10]训练的平均权重:随着我们添加更多的目标,准确性逐渐提高。事实上,正如附录E.1.3所强调的那样,DiWA受益于各种目标带来的增加的多样性。这表明用不同目标训练的模型之间存在一种新的线性连通性;
5.2 DiWA 的结果
尽管取得了这样的成功,DiWA还是有一些局限性。首先,DiWA不能从额外的多样性中获益,因为这会破坏权重之间的线性连接——如附录d所述。其次,DiWA(像所有的WA方法一样)可以解决多样性转移,但不能解决相关性转移:这个特性在第2.4节中首次解释,并在附录H中对ColoredMNIST进行了说明。
7 结论
在本文中,我们提出了一种新的解释,即利用其集成特性来解释WA在OOD中的成功。我们的分析是基于新的偏差-方差-协方差-局部性分解的WA,其中我们从理论上将偏差与相关位移和方差与多样性位移联系起来。这也表明多样性是提高泛化的关键。这激发了我们的DiWA方法,即在独立训练的权重模型中取平均值。DiWA提高了DomainBed(面向对象泛化的参考基准)的技术水平。关键的是,DiWA没有额外的推理成本,消除了标准集成的一个关键限制。我们的工作可能会鼓励社区进一步创建不同的学习程序和目标-其模型可以在权重上平均。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









