







深度推荐模型
组合模型
Wide & Deep
Paper : Wide & Deep Learning for Recommender Systems
Wide & Deep
-
模型结构:结合简单模型“记忆能力”强与复杂模型“泛化能力”强的特点
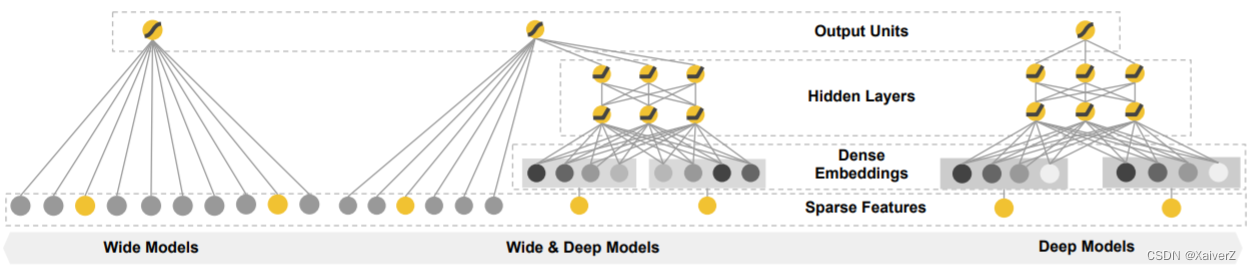

-
Deep部分输入的是全量的特征向量,Wide部分输入的是几类离散型特征
-
Wide部分使用交叉积变换(Cross Product Transformation)组合特征
ϕ k ( x ) = ∏ i = 1 d x i c k i c k i ∈ { 0 , 1 } \phi_{k}(\mathbf{x})=\prod_{i=1}^{d} x_{i}^{c_{k i}} \quad c_{k i} \in\{0,1\} ϕk(x)=i=1∏dxickicki∈{0,1}
c k i c_{ki} cki为布尔变量,当第 i i i个特征属于第 k k k个组合特征时, c k i c_{ki} cki的值为 1 1 1,否则为 0 0 0; x i x_i xi为第 i i i个特征值 -
Wide与Deep部分的输出共同输入最后的逻辑回归,融合两部分优势
-
Deep & Cross
Paper : Deep & Cross Network for Ad Click Predictions
DCN
-
模型结构
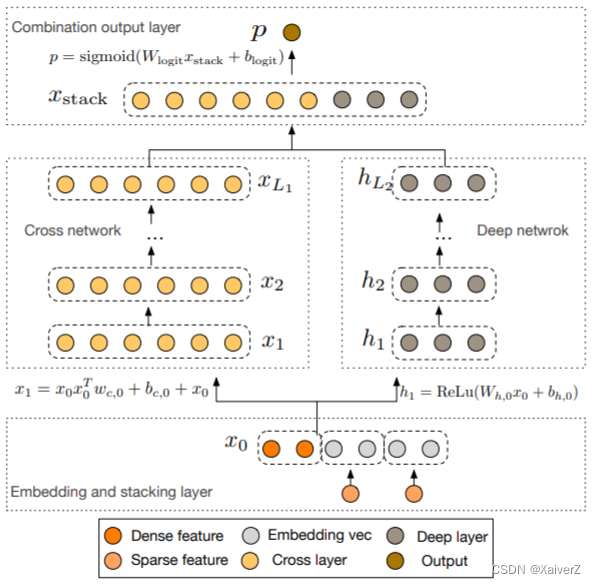
- DCN的Deep部分较Wide&Deep没有太多改动,主要是以Cross网络代替了Wide部分
-
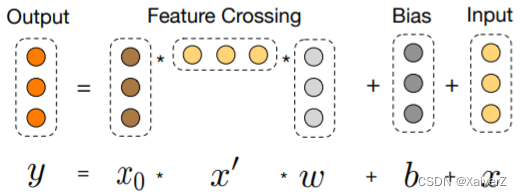
Cross部分的目的是增加特征之间的交互力度,使用多层交叉层(Cross Layer)对输入向量进行特征交叉
x l + 1 = x 0 x l T w l + b l + x l = f ( x l , w l , b l ) + x l \mathbf{x}_{l+1}=\mathbf{x}_{0} \mathbf{x}_{l}^{T} \mathbf{w}_{l}+\mathbf{b}_{l}+\mathbf{x}_{l}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l} xl+1=x0xlTwl+bl+xl=f(xl,wl,bl)+xl
DeepFM
Paper : DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM
-
模型结构
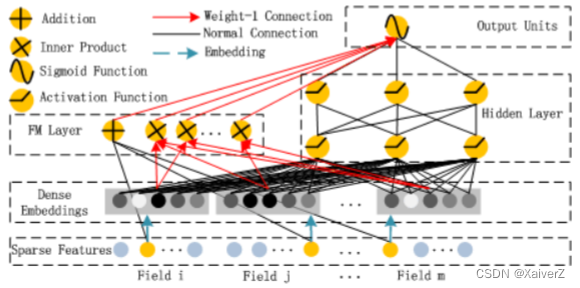
- DeepFM利用FM代替Wide部分对特征进行交叉组合,最后与Deep输出融合
xDeepFM
Paper : xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
xDeepFM
-
模型结构
- Linear部分类似于Wide部分,DNN部分类似于Deep部分
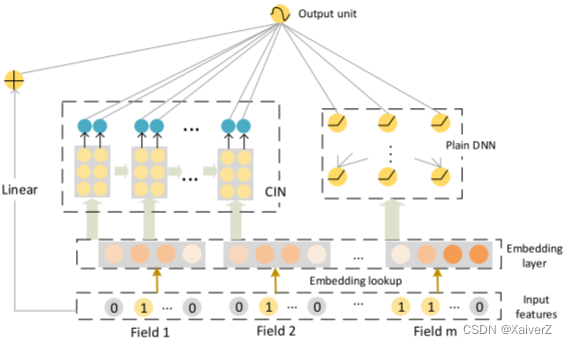
-
CIN(Compressed Interaction Network)
-
CIN首先通过下式计算每一层的输出
X h , ∗ k = ∑ i = 1 H k − 1 ∑ j = 1 m W i j k , h ( X i , ∗ k − 1 ∘ X j , ∗ 0 ) \mathbf{X}_{h, *}^{k}=\sum_{i=1}^{H_{k-1}} \sum_{j=1}^{m} \mathbf{W}_{i j}^{k, h}\left(\mathbf{X}_{i, *}^{k-1} \circ \mathbf{X}_{j, *}^{0}\right) Xh,∗k=i=1∑Hk−1j=1∑mWijk,h(Xi,∗k−1∘Xj,∗0)
X i , ∗ k − 1 ∘ X j , ∗ 0 \mathbf{X}_{i, *}^{k-1} \circ \mathbf{X}_{j, *}^{0} Xi,∗k−1∘Xj,∗0生成 H k − 1 x m H_{k-1}xm Hk−1xm个vector,然后再通过与权重矩阵的相乘,“压缩”成一张feature map: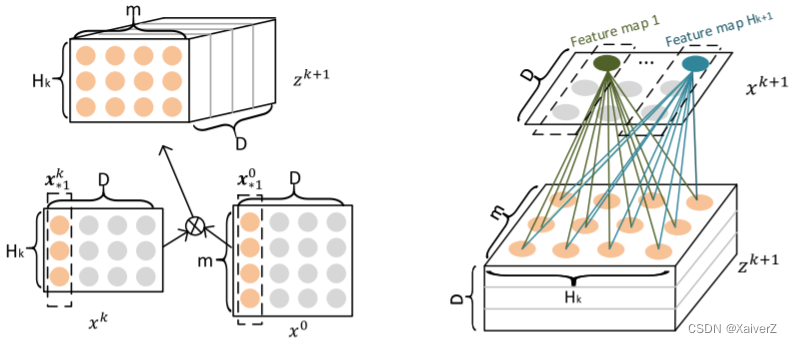
-
CIN先通过特征交叉产生若干 h i h_i hi feature map,最后通过sum pooling输出,拼接,最后与其余模块融合一起分类

-
FM模型的深度学习演化版本
NFM
Paper : Neural Factorization Machines for Sparse Predictive Analytics
Neural Factorization Machine
-
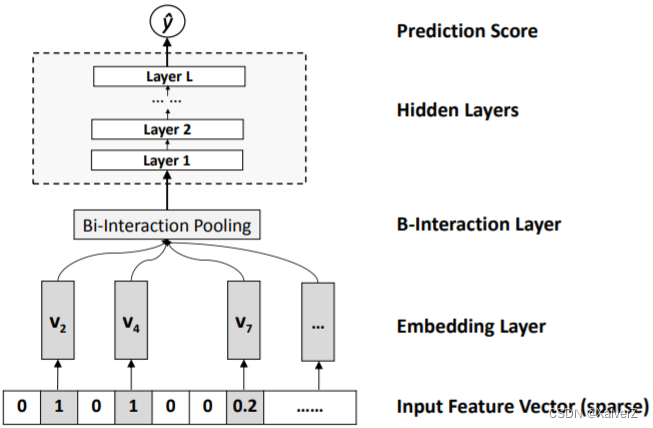
NFM用神经网络代替FM中二阶交叉的部分
y ^ F M ( x ) = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n v i T v j ⋅ x i x j \hat{y}_{F M}(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n} \mathbf{v}_{i}^{T} \mathbf{v}_{j} \cdot x_{i} x_{j} y^FM(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑nviTvj⋅xixj
y ^ N F M ( x ) = w 0 + ∑ i = 1 n w i x i + f ( x ) \hat{y}_{N F M}(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+f(\mathbf{x}) y^NFM(x)=w0+i=1∑nwixi+f(x)
-
NFM在Embedding层(这里的Embedding层是全连接层)与MLP之间加入了特征交叉池化层(Bi-Interaction Pooling Layer)
f B I ( V x ) = ∑ i = 1 n ∑ j = i + 1 n x i v i ⊙ x j v j f_{B I}\left(\mathcal{V}_{x}\right)=\sum_{i=1}^{n} \sum_{j=i+1}^{n} x_{i} \mathbf{v}_{i} \odot x_{j} \mathbf{v}_{j} fBI(Vx)=i=1∑nj=i+1∑nxivi⊙xjvj
其中 V x = { x 1 v 1 , … , x n v n } \mathcal{V}_{x}=\left\{x_{1} \mathbf{v}_{1}, \ldots, x_{n} \mathbf{v}_{n}\right\} Vx={x1v1,…,xnvn}是所有特征域的Embedding集合(只包括了非零输入元素的Embedding Vector)
FNN
Paper : Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction
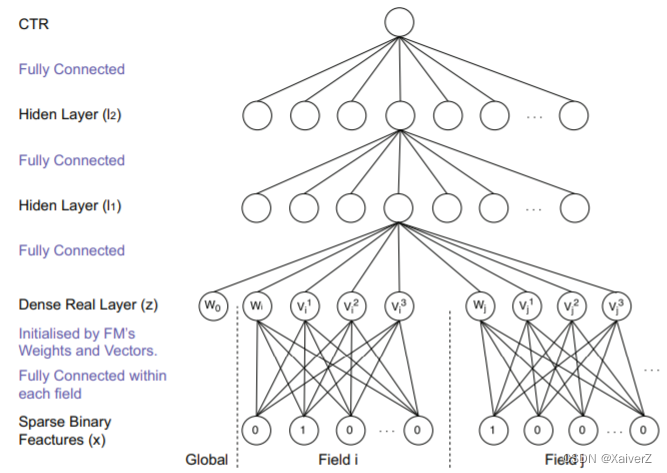
Factorization-machine supported Neural Network
-
使用FM训练出的特征隐向量权重初始化Embedding层权重(实际上是初始化Embedding神经元与输入神经元之间的连接权重)
y F M ( x ) : = sigmoid ( w 0 + ∑ i = 1 N w i x i + ∑ i = 1 N ∑ j = i + 1 N ⟨ v i , v j ⟩ x i x j ) y_{\mathrm{FM}}(\boldsymbol{x}):=\operatorname{sigmoid}\left(w_{0}+\sum_{i=1}^{N} w_{i} x_{i}+\sum_{i=1}^{N} \sum_{j=i+1}^{N}\left\langle\boldsymbol{v}_{i}, \boldsymbol{v}_{j}\right\rangle x_{i} x_{j}\right) yFM(x):=sigmoid(w0+i=1∑Nwixi+i=1∑Nj=i+1∑N⟨vi,vj⟩xixj)















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









