







AI方法工作流程
AMPs(Anti-microbial )方面的研究方向主要分为两种:
- 从自然生成的肽序列中发现新的AMPs。
- 通过修改已知的AMP序列或者从头设计,来获得新的AMPs。
上述的研究工作都遵循下图的流程,首先对输入编码,其次构建AI算法模型,最后预测生物活性或生成新肽。
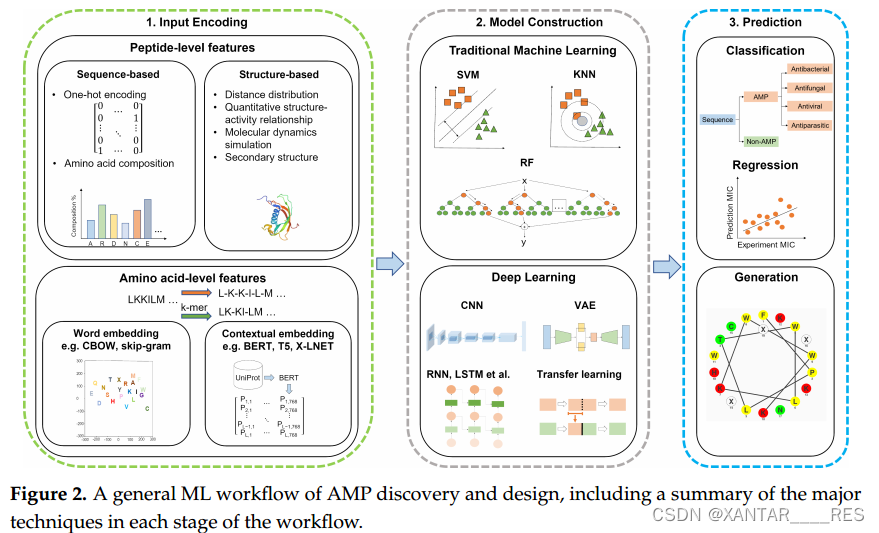
特征编码方法
AMPs最基础的数据就是序列,它包含了AMP的组成信息、物理化学信息等。将序列数据编码成数值信息的方法主要分为两类:基于肽特征的和基于氨基酸特征的。
一、基于肽特征的方法又进一步分为两种,即基于序列特征的和基于结构特征的。
1. 基于序列特征
- “one-hot encoding”,最受欢迎的方法之一,它可以根据肽序列保存肽的信息,通过一个20位长的序列,每个位置对应一个氨基酸。
- “General amino acid compositions”,编码得到20个氨基酸的出现频率。
- “Reduced amino acid compositions”,它不仅考虑20个氨基酸组成,还考虑了离散序列相关因子。
- “Pseudo-reduced amino acid compositions”,计算每一个相似氨基酸聚类群的出现频次。
- 还有同时使用one-hot编码和物理化学特征的组合方法。
2. 基于结构特征
- “Protein secondary structure”,将每一个氨基酸结构计为α-螺旋、β-片层和随机线圈。
- “QSAR(quantitative structure-activity relationship)”,它用于表示化学结构和生物活性之间的关系。
- “Distance distribution”,其描述了各类型原子之间的距离的分布。
- “SMILES(simplified molecular input-line entry system)”,用于标注化合物结构的化学编码,具体地就是编码化学物质的结构来得到其简单的文本字符串表示形式。
二、基于氨基酸特征的方法
肽的氨基酸特征就是肽的序列,即将每个氨基酸表示成一个字符后形成的序列。通常不直接使用序列作为输入(除一些基于RNN的方法),而是使用embedding layer提取有代表性的特征。常用的有word embedding(如Wrod2vec、Bag-of-Words)、contextualized embedding(如BERT),这些NLP技术可以在没有生物知识的前提下对序列中每一个字符创建1-D向量。
1. word embedding
- “Word2vec”,其创建一个包含字符的文本信息的查找表,即字符嵌入矩阵,它由字符和它们对应的表征组成。
- 两种使用浅神经网络的描述符生成方法:continuous Bag-of-Words algorithm和skip-gram algorithm。前者使用一个窗口(window)在字符中滑动,基于window中除最中间外其他的字符预测window最中间的氨基酸的表征;后者则是基于给定的字符来预测其周围的字符。
2. Contextual embedding
它学习到的每一个embedding都是输入序列的函数,具体地说,它从不同上下文中获取字符使用方式并且根据不同上下文中的相同字符来产生其不同的表征。
Deep learning相关工作
介绍了很多相关工作,DNNs、Deep Learning with CNN / RNN layers、Hybrid Learning等等。
后面还有一些AMP优化设计和从头设计的案例,这里不一一展示了。















 4340
4340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









