






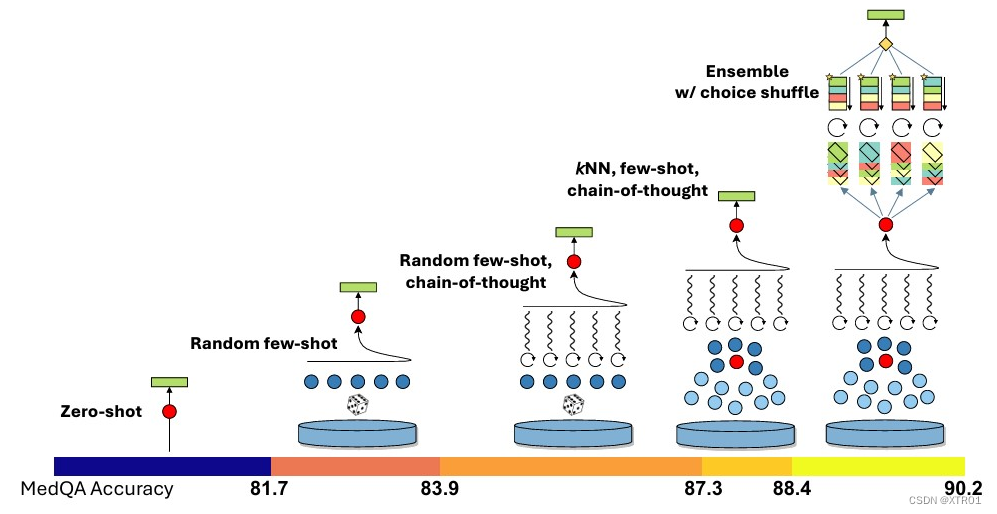
图1:Medprompt组件的可视化说明及其在MedQA基准测试中的性能附加贡献。
方法概述
在研究中,Medprompt方法通过结合三种主要技术:动态少样本选择(Dynamic Few-shot Selection)、自生成思维链(Self-generated Chain of Thought)和选项洗牌集成(Choice Shuffle Ensembling),来提升模型在医疗问答任务中的性能。以下是对每种技术的详细介绍及其在Medprompt方法中的综合应用。
1 动态少样本选择(Dynamic Few-shot Selection)
概念
- 少样本学习(Few-shot Learning):通过少量示例,使基础模型快速适应特定领域并学会任务格式。传统少样本示例在所有测试样本中保持不变,需选取具有广泛代表性的示例。
- 动态少样本选择:相较于固定的少样本示例,通过从训练集中选择与当前测试样本语义相似的示例,提高示例的代表性。
实施方法
- 使用text-embedding-ada-002模型将训练和测试问题嵌入为向量表示。
- 对于每个测试问题x,使用k-NN聚类在嵌入空间中选择k个最相似的训练示例。
- 计算每个测试问题与其邻近训练问题的余弦相似度,选择前k个相似示例。
2 自生成思维链(Self-generated Chain of Thought)
概念
- 思维链(Chain-of-Thought, CoT):通过自然语言陈述(如“让我们一步一步思考”)显式地引导模型生成一系列中间推理步骤,提高复杂推理能力。
实施方法
- 让GPT-4为训练示例生成思维链,提示内容如下:
## Question: {{question}}
{{answer_choices}}
## Answer
model generated chain of thought explanation
Therefore, the answer is [final model answer (e.g. A,B,C,D)]- 对于每个生成的思维链,验证其最终答案是否正确,不正确则丢弃该示例。
3 选项洗牌集成(Choice Shuffle Ensembling)
概念
- 选项偏好(Position Bias):模型在多选题中可能偏向某些选项。
- 自洽性(Self-consistency):通过在某些温度>0的设置下多次提示,生成多样化的推理路径,增加生成过程的随机性。
实施方法
- 洗牌测试问题的选项顺序,并生成不同排序下的推理路径。
- 选择最一致的答案,即对选项洗牌不敏感的答案。
- 生成中间CoT步骤时,也应用此技术,保留正确答案的示例。
方法整合
Medprompt结合了上述三种技术,具体步骤如下:
预处理阶段
- 对训练数据集中的每个问题进行嵌入,生成嵌入向量。
- 使用GPT-4生成每个问题的思维链和答案,答案正确则存储相应的数据。
推理阶段
- 对测试问题进行嵌入,并使用k-NN检索最相似的训练示例。
- 将这些示例及其思维链作为上下文传递给GPT-4。
- 对测试问题及其选项多次洗牌,并生成多条推理路径。
- 通过多数投票法选择最终答案。
结果与性能
- Medprompt方法在使用5个k-NN选择的少样本示例和5次API调用的情况下,达到良好的平衡,既提高了准确性又控制了推理成本。
- 增加少样本示例和集成步骤的数量,可以进一步提高性能,达到90.6%的新标准。
Medprompt算法解释
输入
- 开发数据 D:用于训练和生成示例的数据集。
- 测试问题 Q:需要回答的测试问题。
预处理步骤
- 遍历开发数据中的每个问题 q:
- 获取问题 q 的嵌入向量 vq。
- 使用LLM生成问题 q 的链式思考(Cq)和答案(Aq)。
- 如果答案 Aq 正确,则存储问题 q 的嵌入向量 vq、链式思考 Cq 和答案 Aq。
推理时间步骤
- 计算测试问题 Q 的嵌入向量 vQ。
- 选择最相似的5个示例:
- 使用KNN(K-最近邻)算法和余弦相似度,选择与测试问题 Q 最相似的5个预处理过的训练示例。
- 将这5个示例格式化为上下文 C,供LLM使用。
- 重复5次生成答案:
- 打乱测试问题的答案选项顺序。
- 使用LLM和上下文 C 生成链式思考(Ck_q)和答案(Ak_q)。
- 计算生成答案的多数票:
- 取生成的答案中出现频率最高的答案作为最终答案(AFinal)。
举例说明
输入示例
-
开发数据 D:包含问题和正确答案的集合,例如:
- 问题1:“地球上最大的沙漠是什么?”
- 正确答案:南极沙漠
- 问题2:“太阳系中最小的行星是哪个?”
- 正确答案:水星
- 问题1:“地球上最大的沙漠是什么?”
-
测试问题 Q:“人类平均体温是多少?”
预处理步骤
假设开发数据 D 包含以下问题:
-
问题1:“地球上最大的沙漠是什么?”
- 嵌入向量 v1
- LLM生成的链式思考:解释沙漠的定义,指出南极沙漠最大。
- 答案:南极沙漠(正确)
-
问题2:“太阳系中最小的行星是哪个?”
- 嵌入向量 v2
- LLM生成的链式思考:解释太阳系的组成,指出水星最小。
- 答案:水星(正确)
推理时间步骤
-
计算测试问题 Q 的嵌入向量 vQ。
-
选择最相似的5个示例:
- 使用KNN算法和余弦相似度,选择与 Q 最相似的5个示例,假设选出的问题是上面的“问题1”和“问题2”及其他3个问题。
-
将这5个示例格式化为上下文 C,供LLM使用。
-
重复5次生成答案:
- 第一次:
- 打乱答案选项顺序:a) 36.5°C, b) 37.0°C, c) 38.0°C, d) 36.0°C
- LLM生成链式思考和答案:链式思考解释人体温度的正常范围,答案:37.0°C
- 第二次:
- 打乱答案选项顺序:a) 37.0°C, b) 36.0°C, c) 38.0°C, d) 36.5°C
- LLM生成链式思考和答案:链式思考解释人体温度的正常范围,答案:37.0°C
- 重复5次,得到5个答案。
- 第一次:
-
计算生成答案的多数票:
- 假设5次生成的答案都是37.0°C
- 最终答案:37.0°C
输出
最终答案 AFinal 是 37.0°C。
多个COT举例说明(个人理解:因为在生成训练样本的中间CoT步骤中应用了选项混洗技术。对于每个样本,进行多次混洗选项,并为每个变体生成一个CoT,最终只保留具有正确答案的样本。因此我认为每一个训练样本示例都有多个COT,导致最后结果输出时,每一次输出应该都包含多个COT。):
### CoT Example 1:
## Question: What is the capital of Italy?
- A) Berlin
- B) Madrid
- C) Rome
- D) Paris
## Answer
Let's think step by step.
1. Italy is a country in Europe.
2. Rome is a well-known city in Italy.
3. It has been the capital since the country was unified.
Therefore, the answer is C) Rome.
### CoT Example 2:
## Question: What is the capital of Germany?
- A) Berlin
- B) Madrid
- C) Paris
- D) Rome
## Answer
Let's consider the options.
1. Germany is a European country.
2. Berlin is a famous city in Germany.
3. It is known for its history and as the capital.
Therefore, the answer is A) Berlin.
### CoT Example 3:
## Question: What is the capital of Spain?
- A) Berlin
- B) Madrid
- C) Paris
- D) Rome
## Answer
Let's think through this.
1. Spain is located in Europe.
2. Madrid is a major city in Spain.
3. It is the political and cultural center.
Therefore, the answer is B) Madrid.
## Test Question:
## Question: What is the capital of France?
- A) Berlin
- B) Madrid
- C) Paris
- D) Rome
## Answer
### CoT 1:
Let's think step by step.
1. France is a country in Europe.
2. Paris is a renowned city in France.
3. It has been the capital for centuries.
Therefore, the answer is C) Paris.
### CoT 2:
Let's analyze the options.
1. Berlin is the capital of Germany, not France.
2. Madrid is the capital of Spain.
3. Rome is the capital of Italy.
4. Paris is the capital of France.
Therefore, the answer is C) Paris.
### CoT 3:
Consider the following reasoning.
1. France's most famous city is Paris.
2. It is known for landmarks like the Eiffel Tower.
3. It serves as the country's cultural and political center.
Therefore, the answer is C) Paris.
避免过拟合:
直观上,一个为特定基准问题示例创建的提示,在这些问题上自然会表现得比未见过的问题更好。在传统机器学习中解决这个问题的常见技术是创建“测试”集,这些测试集仅在模型选择过程的最后进行评估。我们采用了机器学习研究中健全测试方法学的这一重要方面,并随机将每个基准数据集的20%作为“不可见”拆分部分,这些部分在最终测试阶段之前完全不参与考虑。也就是说,这些数据在最终阶段之前一直保持隐藏状态。在提示工程过程中,这些数据不会被检查或优化。
局限性:
- 我们注意到,基础模型可能会生成错误的信息(有时被称为幻觉),这可能会破坏生成的内容和建议。虽然改进提示策略可能会减少幻觉并提高整体准确性,但这也可能使任何剩余的幻觉更难被检测出来。有前景的方向包括努力对生成的内容进行概率校准,为最终用户提供对输出可信赖的置信度度量。
- 我们也必须意识到基础模型输出中的偏见。我们还不了解追求顶级性能的优化如何影响其他目标,如公平的性能。在追求整体准确性的同时,平衡不同子群体之间的公平性能至关重要,以避免加剧医疗保健中现有的不平等现象。















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









