






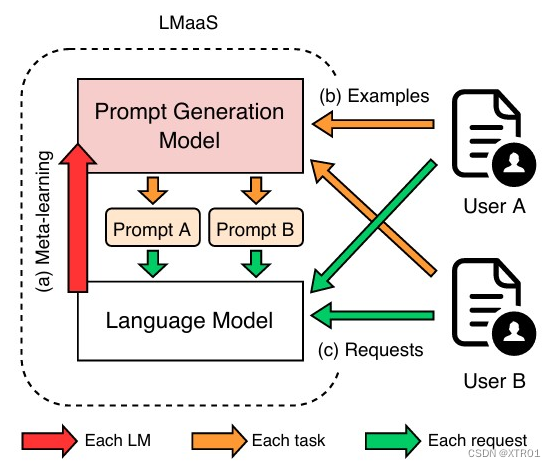
图 1:LMaaS 上的 MetaL-Prompt 工作流程。
使用过程:
- 模型提供商首先在离线阶段使用我们的元学习算法训练一个PGM(图1(a))。
- 一旦服务开始运行,训练好的PGM就会根据用户提供的少量示例生成合适的提示,而无需进行额外的训练(图1(b))。
- 生成的提示将被保存并持续重用,以满足对该任务后续的所有用户请求(图1(c))。
MetaL-Prompt: 方法理解与举例说明
方法概述
MetaL-Prompt是一种用于轻量级提示生成的元学习方法。其目标是生成能够增强语言模型(LM)上下文学习能力的提示。MetaL-Prompt包含三个主要部分:
-
提示生成模型(PGM)的元训练:
PGM被初始化为目标语言模型,通过元训练生成有效提示。这一过程称为元学习,因为PGM学会生成能引导目标LM学习有效上下文的提示。 -
可训练填充(Trainable Padding):
为减少提示生成过程中多次前向传递的开销,MetaL-Prompt提出了可训练填充。这使PGM可以同时生成多个提示标记。 -
提示设计:
MetaL-Prompt探索了四种不同类型的提示:离散提示(Discrete)、加权和提示(Weighted Sum)、隐藏状态提示(Hidden State)和前缀提示(Prefix)。
方法详解
-
提示生成模型(PGM)的元训练:
-
目标函数:
- 目标函数如下所示:
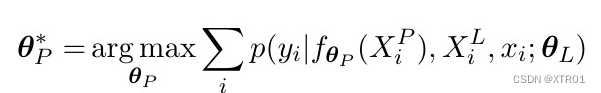
- 其中,θL和θP分别是LM和PGM的参数,yi是输入文本xi的预期答案,XPi = {xPi,0,yPi,0,xPi,1,yPi,1,...} 和 XLi = {xLi,0, yLi,0, xLi,1, yLi,1, ...} 是示例的拼接。XP和XL由来自不同NLP任务的示例组成。提示生成过程fθP可以以不同的方式实现,一个直接的例子就是使用PGM预测的概率来选择最可能的下一个标记。
- 目标函数如下所示:
-
参数训练:
- 参数θP被初始化为目标LM的参数,以利用LM对各种NLP任务的现有理解。
- 采用LoRA(Low-Rank Adaptation)方法进行参数高效的微调,而不是全参数微调。LM在元学习过程中是冻结的,只有PGM被调整。(因此,PGM的参数量会小于LM。)
-
服务阶段:
- 当用户提供少量样本时,MetaL-Prompt将它们分为两个子集:XP和XL。
- PGM利用XP生成一个适当的提示,这个提示与额外的演示样本XL相结合,并使用组合的输入来处理未来的用户请求。
- XL可以是空集,这种情况下,只有提示和用户请求的输入被输入到LM中,实现最快的推理速度。
-
基于梯度的提示调整:
- 生成的提示可以直接用于LM,但在可以接受额外计算成本的情况下,可以通过基于梯度的提示调整方法进一步增强提示。
-
-
可训练填充(Trainable Padding):
-
可训练的嵌入:
- MetaL-Prompt将可训练的嵌入添加到给定的示例 XP 中。
- 这些嵌入是可训练的向量,它们在训练过程中不断调整,以便生成更有效的提示。
-
利用隐藏状态:
- PGM能够利用每个填充位置对应的隐藏状态,同时生成多个提示标记。(结合提示设计进行理解。)
-
重新参数化:
- 类似于其他提示调整方法,MetaL-Prompt对可训练的填充进行了重新参数化。
- 重新参数化的方法论是P-tuning,通过在输入中插入一些可训练的标记,来调整模型对提示的理解。使用LSTMs来生成这些可训练的标记,这些标记能够动态地捕捉到输入数据中的模式和结构。
-
-
提示设计:
-
离散提示(Discrete):由PGM预测的最可能的自然语言标记组成。为了训练用于离散型提示的PGM,我们采用了Gumbel-Softmax重参数化及离散化(“直通”技巧)。
- 输入序列:"The movie was great."
- 生成logits:PGM生成logits [2.5,1.0,3.0,...,0.5][2.5, 1.0, 3.0, ..., 0.5][2.5,1.0,3.0,...,0.5]。
- 加入Gumbel噪声:得到noisy_logits [3.3,1.3,4.5,...,0.7][3.3, 1.3, 4.5, ..., 0.7][3.3,1.3,4.5,...,0.7]。
- Softmax转换:得到概率分布 [0.1,0.05,0.6,...,0.02][0.1, 0.05, 0.6, ..., 0.02][0.1,0.05,0.6,...,0.02]。
- 离散化选择:选择概率最大的单词 w3w_3w3 对应的“excellent”。
- 加权和提示(Weighted Sum):通过将PGM预测的标记概率与目标LM的单词嵌入相乘获得。
- 隐藏状态提示(Hidden State):直接使用PGM中头层(即输入层)的输入隐藏状态作为连续型提示。
- 前缀提示(Prefix):前缀提示是在Transformer架构中,在自注意力层的键(keys)和值(values)之前添加提示,而不是将提示添加到输入序列之前。
- 提取键和值:从PGM的每一层中,在可训练填充位置提取自注意力层的键和值。
- 添加到目标LM:将这些提取的键和值添加到目标LM相应层的键和值之前。
-
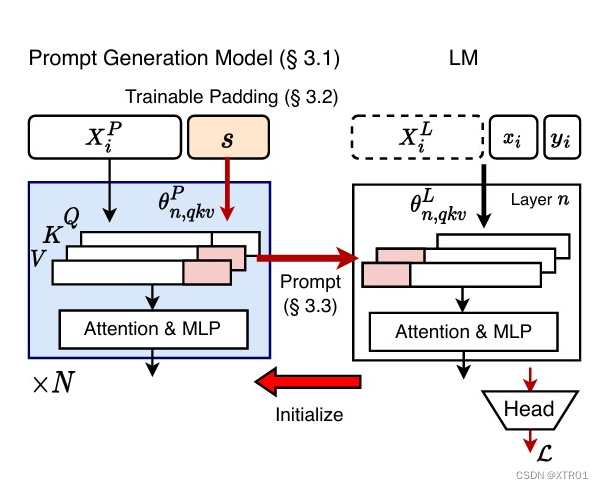
图 2:提示生成模型的元学习图示。
局限性:
- 演示数量的灵活性
在特定训练设置(即示例分割)下训练的提示生成模型(PGM)无法直接转移到不同的测试设置中。因此,当我们试图通过在cls→cls设置中包含更多演示来提高预测质量时,我们需要为每个特定设置训练多个PGM,通过调整演示的数量来灵活权衡推理速度和预测质量。然而,训练和管理多个PGM对LMaaS(Language Model as a Service,语言模型即服务)提供商构成了挑战。(没有使用演示训练的PGM不能转移到带有演示的测试设置。)
- 更多示例的提示生成
在我们的实验中,提示生成模型(PGM)受到序列大小限制的约束。因此,如果用户提供了过多的示例,并且这些示例的拼接超过了序列大小限制,PGM可能无法处理如此大的集合。然而,值得注意的是,最近的语言模型已经开始采用更长的序列大小,这有助于缓解这一限制。更长的序列大小的引入使PGM能够更有效地处理更大规模的示例集。此外,我们还探索了一种迭代方法来改进提示,通过将先前生成的提示与新示例拼接起来。然后,这个拼接的上下文被用作PGM的输入,以生成一个增强的提示,允许PGM通过迭代处理示例子集来容纳任意数量的示例。这种迭代方法增强了提示生成的可扩展性,使PGM能够有效地处理不同数量的示例。















 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









