







首先讲讲:什么是计算机视觉?
计算机视觉是一门让计算机学会“看”的学科,研究如何自动理解图像和视频中的内容。
其次讲讲:计算机视觉有哪些任务?我们所要讲的图像分割位于什么地位?
计算机视觉的三大经典任务:分类、检测、分割 (其他任务还有:目标跟踪、图像描述、场景文本识别、图像问答、图像内容生成、以图搜图、以文字搜图等)
分类:图像为单目标,从已知的类别标签集合中为给定的图像目标确定类别。

检测:图像可为多目标,检测到图像中目标的具体位置以及置信度。

分割:像素级对前景和背景进行分类,将背景剔除。分为语义分割、实例分割、全景分割。

其中,语义分割 是指 给图像中的每个像素分配一个类别,得到物体类别的mask。(仅考虑像素类别,不分割同一类的不同实体。)
实例分割 是指 对特定的物体进行分类,与目标检测输出物体的边界框不同,实例分割输出的是特定物体的mask和类别。(对特定的物体进行分类,仅考虑前景物体。)
全景分割 是指 语义分割+实例分割 plus。 (背景仅考虑类别,前景需要区分实例。)
图像分割应用场景有哪些?
1.无人驾驶:感知汽车周围的环境,例如车辆、行人。

2.人像分割:换背景、扣人像。

3.智能遥感:分析地表农作物->水域、道路、农田分布、船舶等。

4.医疗影像分析:x光、CT等肿瘤分析。

然后讲讲,语义分割算法的 演进历程 与 ~~有哪些?
经典的语义分割算法如下:
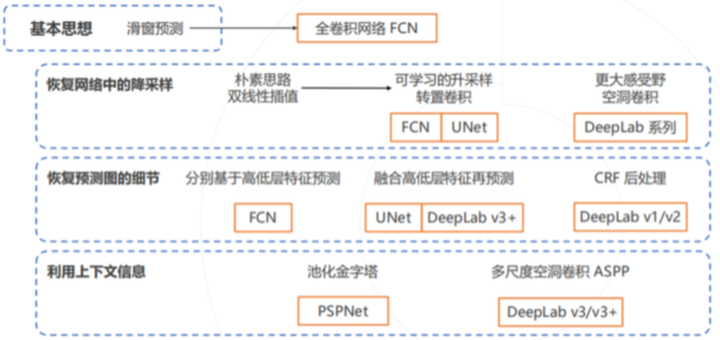
传统模式识别下的语义分割
按颜色分割
根据先验知识,得物体内部颜色相近,边界颜色变化。-> 按颜色相近的色块进行聚类。如下图 将红色的衣服抠出来。

存在问题
1.可以实现抠图,但是不能得到语义。
2.先验知识不完全准确。
3.不同物体内部颜色可能相近,物体内部可能包含多个颜色。
逐像素分类
其步骤如下:
1.提取一个卷积窗口图像。
2.把这个图像输入卷积神经网络中预测一个类别,该类别作为提取图像的中心点坐标类别。
3.返回1,继续滑动窗口进行预测下一个像素。

优点
可以充分利用CNN模型
缺点
存在大量重复计算的重叠区域
重复区域优化
两个相邻的滑窗中间的重叠区域卷积后表现为相同特征,因此这一块可以被优化,在滑窗上计算卷积等于在原图上计算卷积,因此可以在原图上先计算一次卷积,然后复用这个结果。-> 先卷积再滑窗,减少重复计算。

在讲深度学习的语义分割之前,讲讲语义分割数据集。
深度学习下语义分割的数据集
VOC数据集
voc数据集重要介绍
PASCAL VOC 2007数据集的简单介绍![]() https://blog.csdn.net/XiaoyYidiaodiao/article/details/113897617Segmentation文件下对应的.txt文件如:
https://blog.csdn.net/XiaoyYidiaodiao/article/details/113897617Segmentation文件下对应的.txt文件如:
Segmentation (目标分割图像信息)
|
|----train.txt 训练集(1464)
|----val.txt 验证集(1449)
|----trainval.txt 训练集+验证集(2913)例如,图像2007_000323.jpg

在SegmentationClass中找到相应的标注图像,例如,2007_000323.png

在语义分割中,标注的图像,是P模式 -> 单通道的图像。在背景处的像素值为0(转化为三通道(0,0,0)),目标边缘处的像素值为255 (转化为三通道为(224,224,129))。因为目标为人这个类,所以在人目标的像素位置存的是人在voc数据集的序号15。

VOC数据集的类别如下,从0开始数序列,person为15。
VOC_CLASSES = [
"aeroplane",
"bicycle",
"bird",
"boat",
"bottle",
"bus",
"car",
"cat",
"chair",
"cow",
"diningtable",
"dog",
"horse",
"motorbike",
"person",
"pottedplant",
"sheep",
"sofa",
"train",
"tvmonitor",
]COCO数据集
coco针对图像中的每一个目标都记录了多边形坐标polygons,比如下图的人在annotation中记为
[428.19,219.47,430.94,209.57,430.39,210.12,421.32,216.17,412.8,
217.27,413.9,214.24,422.42,211.22,429.29,201.6,430.67,181.8,...]其中一个坐标为x,一个坐标为y,例如428.19为x坐标,219.47为y坐标,(428.19,219.47)一对。430.94为x坐标,209.57为y坐标,(430.94,209.57)一对。
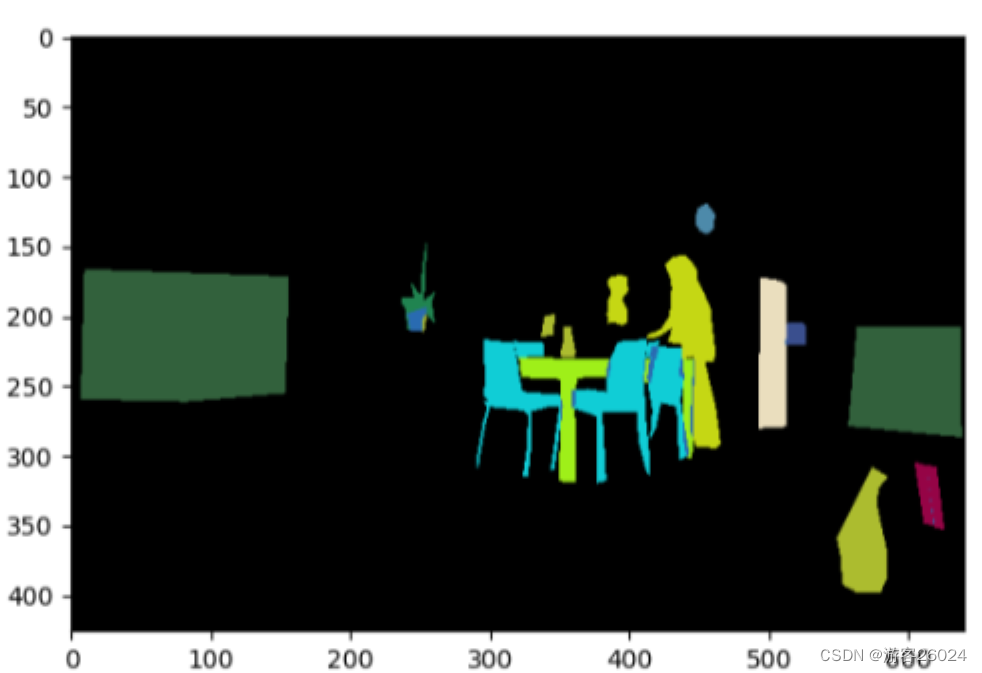
将其读出来后,换为单通道图,目标的每个像素点的xy坐标存入coco数据集的80个类的序列号,背景还是0,但是目标边界的像素值不为255了,就是目标的coco序列号。

如图,语义分割的单通道标记图像。
深度学习下的语义分割
全连接卷积化
1×1 的卷积核等价于全连接(来源:原来是 VGG 中提出的)-> 反向量化。
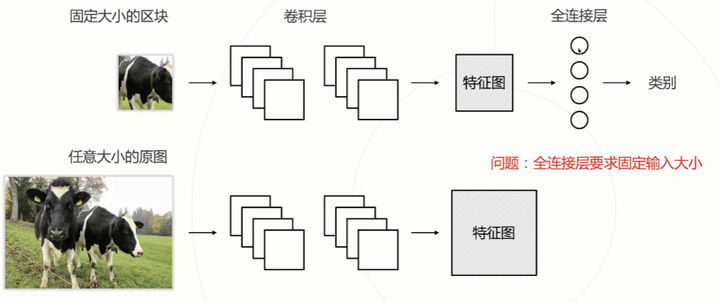
问题
全连接层的输入是固定的,但是输入的图像是随机大小的,这样导致特征图大小也是随机的。
解决
卷积取代全连接层。
兼容任意尺寸的图,没有全连接层,每个通道代表了一个类别概率。

应用
FCN (CVPR 2015)

升采样 双线性插值和转置卷积
池化 卷积降采样
参考博文
下一话
讲讲,语义分割的评价指标
分割2——语义分割评价指标![]() https://blog.csdn.net/XiaoyYidiaodiao/article/details/125149509之后讲讲 转置卷积(升采样)
https://blog.csdn.net/XiaoyYidiaodiao/article/details/125149509之后讲讲 转置卷积(升采样)
分割3-转置卷积可逆吗?![]() https://blog.csdn.net/XiaoyYidiaodiao/article/details/131705741
https://blog.csdn.net/XiaoyYidiaodiao/article/details/131705741
再将FCN
未完...














 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









