






范数(norm)是数学中的一个基本概念,直观上可以理解为某个空间中的点到该空间原点的距离。
在函数分析中,范数用来衡量函数的“大小”。在Lp空间中,函数的范数定义为其绝对值函数的p次幂在整个定义域上的积分的p次根。
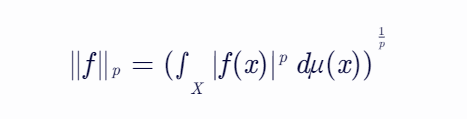
在机器学习中,常用的范数有L0范数、L1范数(有时也被称为稀疏规则算子)、L2范数(欧几里得范数)、L∞范数(最大范数)等。
-
L0范数:
L0范数定义为向量中非零元素的个数。例如,对于向量[0, 1, 2, 0, 3],其L0范数为3,因为该向量中有3个非零元素(即1、2和3)。L0范数常常用来表示模型的复杂性或者模型的稀疏性。然而,L0范数的问题在于它是非凸的,这使得相关的优化问题变得非常困难。 -
L1范数:
L1范数,也被称为曼哈顿距离或者绝对值和,是向量中所有元素的绝对值之和。例如,对于向量[1, -2, 3, -4],其L1范数为|1| + |-2| + |3| + |-4| = 1 + 2 + 3 + 4 = 10。在线性回归模型中,L1范数可以用来进行特征选择和生成稀疏模型。 -
L2范数:
L2范数,也称为欧几里得范数,是向量元素的平方和的平方根。例如,对于向量[3, 4],其L2范数为√(3² + 4²) = √(9 + 16) = √25 = 5。在机器学习中,L2范数经常用于模型正则化和特征归一化。通过在损失函数中添加L2范数的正则化项,可以降低模型的复杂度,避免过拟合。 -
L∞范数:
L∞范数是指一个向量中绝对值最大的元素。例如,对于向量[1, -3, 5, -7],其L∞范数为7,因为该向量中绝对值最大的元素是-7(注意,这里取的是绝对值最大的元素,因此不考虑符号)。L∞范数在很多领域都有应用,比如在信号处理、控制论等方面。*注意,L∞范数只满足齐次性和三角不等式,而不满足正定性。这意味着在L∞空间中存在一些非零向量的范数为0的情况,这些向量被称为奇异向量。。

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









