






1. Python的调用
from ultralytics import YOLO
import os
def detect_predict():
model = YOLO('../weights/yolo11n.pt')
print(model)
results = model('../ultralytics/assets/bus.jpg')
if not os.path.exists(results[0].save_dir):
os.makedirs(results[0].save_dir)
for result in results:
filename = result.path.split("\\")[-1]
filedir = result.save_dir + "\\" + filename
result.save(filedir)
运行结果:

模型训练,基于coco8数据:
from ultralytics import YOLO
def detect_train():
model = YOLO("yolo11l.pt") # Load a model
train_results = model.train( # Train the model
data="coco8.yaml", # path to dataset YAML
epochs=100, # number of training epochs
imgsz=640, # training image size
device="0", # device to run on, i.e. device=0 or device=0,1,2,3 or device=cpu
)
metrics = model.val() # Evaluate model performance on the validation set
results = model("../ultralytics/assets/bus.jpg") # Perform object detection on an image
results[0].show()
# Export the model to ONNX format
path = model.export(format="onnx") # return path to exported model
2. 网络结构图

图2-1 yolo11-detection网络结构图
其中depth参数控制C3k2,即C3k2_X中,X*depth.
3. 损失函数
3.1 损失函数的定位
ultralytics中损失函数定位:ultralytics.engine.train()-->ultralytics.engine.trainer.train()--> ultralytics.engine.trainer._do_train(),其中以下为调用损失位置:

即模型的前向推理过程触发损失函数计算。同debug到该处,获取模型名称如下:

DetectionModel类中的函数如下:

其中DetectionModel函数继承自BaseModel,损失调用如下

经debug调用self.loss函数,其中ultralytics.utls.loss.v8DetectionLoss函数是具体损失计算位置

self.criterion(preds, batch)形式调用,即v8DetectionLoss类中的__call__函数,具体如下

3.2 损失函数具体分析
(1) 前向推理与anchor构造
前向处理分成三个尺度:![]() ,其中B表示batch_size,
,其中B表示batch_size,
![]() 。通过debug模式三个尺度生成的list如下:
。通过debug模式三个尺度生成的list如下:

需要把三个尺度分成预测类别(80个类别)和检测框,其中![]() ,具体如下:
,具体如下:

以三个尺度构造anchor,其中以每个方格中心点作为anchor_point,三个尺度总共有8400个anchor_point,如图3-1所示。通过debug获取全部anchor_points与anchor_points对应的stride_tensor,如下:

图3-1 anchor_point的构造

(2) GT目标框与预测框构建
GT目标框的构建,包括batch_idx,cls,bboxes,得到![]() ,其中n表示batch中的标注的目标框数量,6=1+4+1。
,其中n表示batch中的标注的目标框数量,6=1+4+1。

self.preprocess函数的作用是输出![]() ,构建B个
,构建B个![]() 的矩阵,其中
的矩阵,其中![]() 表示B个图像中标注框最大的数量,不足最大数量的行设置为全0,5表示cls+bbox
表示B个图像中标注框最大的数量,不足最大数量的行设置为全0,5表示cls+bbox

预测框的构建主要是函数bbox_decode,即对前向推理的pred_distri根据anchor_points对pred_distri做解码操作。解码时,pred_distri由![]() 变为
变为![]() ,具体是16个预测值做softmax后与[0,1,2,…,15]做矩阵乘法,如下
,具体是16个预测值做softmax后与[0,1,2,…,15]做矩阵乘法,如下

然后pred_dist得到的是左上角、右下角距离每个anchor_point中心点的距离,通过dist2bbox转换为xyxy形式的坐标,如下所示。anchor_points为中心点的坐标,最后得到预测bboxes。

(3) 任务分配器
任务分配器即ultralytics.utils.tal.TaskAlignedAssigner类,主要实现以该类的forward函数。其中主要的函数为get_pos_mask、select_highest_overlaps、get_targets。
1) get_pos_mask:获取anchor预测真实框的mask
def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):
"""Get in_gts mask, (b, max_num_obj, h*w)."""
mask_in_gts = self.select_candidates_in_gts(anc_points, gt_bboxes) # mask_in_gts:4x7x8400
# Get anchor_align metric, (b, max_num_obj, h*w)
align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_in_gts * mask_gt)
# Get topk_metric mask, (b, max_num_obj, h*w)
mask_topk = self.select_topk_candidates(align_metric, topk_mask=mask_gt.expand(-1, -1, self.topk).bool())
# Merge all mask to a final mask, (b, max_num_obj, h*w)
mask_pos = mask_topk * mask_in_gts * mask_gt
return mask_pos, align_metric, overlaps
select_candidates_in_gts函数的主要作用是根据真实框lt、rb距离anchor_point的距离初步筛选获取mask_in_gts。其中筛选的条件是四个距离值大于1e-9,如图3-2所示。该函数输出如下:
![]()
其中mask_in_gts表示0或1的矩阵。
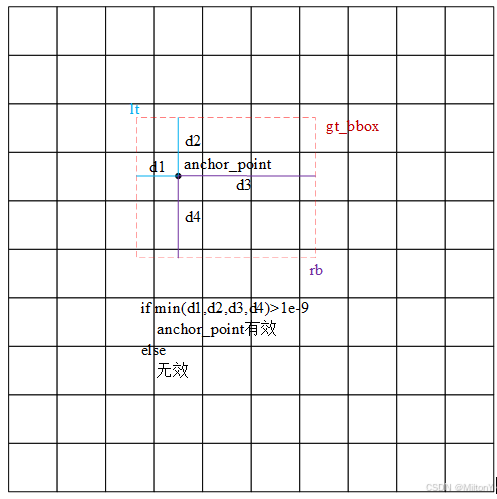
图3-2 有效anchor_point的筛选
get_box_metrics主要是计算预测框与一个batch的GT框的CIOU,以及一个batch的GT类别位置处预测score,通过这两个计算得到align_metric。其中该函数的mask_gt的计算由select_candidates_in_gts获取的mask_in_gts与一个batch的mask_gt(xyxy坐标不为0则表示有目标,否则没有目标)相乘得到,mask_in_gts:![]() ,mask_gt:
,mask_gt:![]() 。然后得到新的mask_gt:
。然后得到新的mask_gt:![]() ,如下所示,后续的score与box框的筛选都根据新mask_gt获取。
,如下所示,后续的score与box框的筛选都根据新mask_gt获取。

构造batch_idx与cls_idx,如下

根据构造的idx从pd_scores(bx8400x80)中获取mask_gt相应位置值,然后赋值给bbox_scores,mask_gt的其余部分为0,如下

分别扩展pd_bboxes、gt_bboxes(原始pd_bboxes:bx8400x4,原始gt_bboxes:bx7x4),使其两则维度相同,然后通过新mask_gt筛选预测框与真实框,通过CIOU计算overlaps,如下

最后计算align_metric,其中bbox_scores: bx7x8400, overlaps: bx7x8400,计算公式如下
![]()
alpha=0.5,beta=6.0。
select_topk_candidates由align_metric筛选top10候选mask_topk。其中该函数的输入topk_mask由mask_gt:![]() 复制topk中的k=10份得到topk_mask:
复制topk中的k=10份得到topk_mask:![]() 。筛选align_metric中top10的值与idx,如下
。筛选align_metric中top10的值与idx,如下
![]()
其中topk_idxs的值域为[0,8400),topk_metrics,topk_idxs,topk_mask尺寸都为![]() 。返回mask_topk的尺寸为
。返回mask_topk的尺寸为![]()

最后merge所有的mask返回为mask_pos,其中mask_topk、mask_in_gts大小为![]() ,mask_gt大小为
,mask_gt大小为![]() ,具体代码如下
,具体代码如下

2) select_highest_overlaps:当一个anchor分配多个检测框时,选择overlap最大的
def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
"""Select anchor boxes with highest IoU when assigned to multiple ground truths."""
# Convert (b, n_max_boxes, h*w) -> (b, h*w)
fg_mask = mask_pos.sum(-2)
if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes
mask_multi_gts = (fg_mask.unsqueeze(1) > 1).expand(-1, n_max_boxes, -1) # (b, n_max_boxes, h*w)
max_overlaps_idx = overlaps.argmax(1) # (b, h*w)
is_max_overlaps = torch.zeros(mask_pos.shape, dtype=mask_pos.dtype, device=mask_pos.device)
is_max_overlaps.scatter_(1, max_overlaps_idx.unsqueeze(1), 1)
mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos).float() # (b, n_max_boxes, h*w)
fg_mask = mask_pos.sum(-2)
# Find each grid serve which gt(index)
target_gt_idx = mask_pos.argmax(-2) # (b, h*w)
return target_gt_idx, fg_mask, mask_pos
mask_pos:![]() ,overlaps:
,overlaps:![]() ,mask_multi_gts获取一个anchor预测多个gt框的位置,max_overlaps_idx每个anchor中overlap值最大的位置获取,通过torch.where更新mask_pos,即一个anchor分配多个框时,选择overlap最大GT,分配到该anchor上。最后返回fg_mask(anchor中分配GT框的mask)、target_gt_idx(anchor中分配GT框的idx)、
,mask_multi_gts获取一个anchor预测多个gt框的位置,max_overlaps_idx每个anchor中overlap值最大的位置获取,通过torch.where更新mask_pos,即一个anchor分配多个框时,选择overlap最大GT,分配到该anchor上。最后返回fg_mask(anchor中分配GT框的mask)、target_gt_idx(anchor中分配GT框的idx)、![]()
尺寸大小的mask_pos。
3) get_targets:
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
# Assigned target labels, (b, 1)
batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w) 值域[0,b*n_max_boxes)
# gt_labels.long.flatten() (b*n_max_boxes,)
target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w) # 每个anchor预测的类别号
# Assigned target boxes, (b, max_num_obj, 4) -> (b, h*w, 4)
target_bboxes = gt_bboxes.view(-1, gt_bboxes.shape[-1])[target_gt_idx] # 每个anchor预测框的坐标bbox
# Assigned target scores
target_labels.clamp_(0)
# 10x faster than F.one_hot()
target_scores = torch.zeros(
(target_labels.shape[0], target_labels.shape[1], self.num_classes),
dtype=torch.int64,
device=target_labels.device,
) # (b, h*w, 80)
target_scores.scatter_(2, target_labels.unsqueeze(-1), 1)
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0) # 通过fg_scores_mask限制target_scores
return target_labels, target_bboxes, target_scores
target_gt_idx是[0,n_max_boxes-1]的值,更新索引值,不同batch_idx索引唯一,如下

构造one-hot的target_scores,每个anchor都是one-hot,长度为80,如下

最后返回![]() 的target_labels,
的target_labels,![]() 的target_bboxes,
的target_bboxes,![]() 大小one-hot的target_scores。
大小one-hot的target_scores。
任务分配器最后步骤是做归一化处理,如下所示。
# Normalize
align_metric *= mask_pos
pos_align_metrics = align_metric.amax(dim=-1, keepdim=True) # [b, max_num_obj, 1]
pos_overlaps = (overlaps * mask_pos).amax(dim=-1, keepdim=True) # [b, max_num_obj, 1] 值域[0,1]
# align_metric/pos_align_metrics值域[0,1],尺寸为b, max_num_obj, 8400
norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1) # [b, 8400, 1]
target_scores = target_scores * norm_align_metric # [b,8400,80] * [b,8400,1]
最终TaskAlignedAssigner返回五个参数,如下

(4) 损失计算
Cls loss通过BCE计算,pred_scores与target_scores的尺寸为![]() ,其中BCE的计算公式如下:
,其中BCE的计算公式如下:


Box loss计算loss_iou与loss_dfl,具体的计算如下
# Bbox loss
if fg_mask.sum():
target_bboxes /= stride_tensor # [b,8400,4] / [8400,1]
loss[0], loss[2] = self.bbox_loss( # 计算loss_iou, loss_dfl
pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
)
loss[0] *= self.hyp.box # box gain = 7.5
loss[1] *= self.hyp.cls # cls gain = 0.5
loss[2] *= self.hyp.dfl # dfl gain = 1.5
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
bbox_loss中的计算代码如下,其中包括loss_iou与loss_dfl两部分。
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1) # 计算权重,target_scores:b,8400,80, fg_mask:b,8400
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True) # 在fg_mask下,计算真实框与预测框CIoU
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum # iou损失计算
# DFL loss
if self.dfl_loss:
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.dfl_loss.reg_max - 1) # box转换成距中心点距离 [b, h*w, 4]
# pred_dist[fg_mask]:210x64-->840x16, target_ltrb[fg_mask]:210x4
loss_dfl = self.dfl_loss(pred_dist[fg_mask].view(-1, self.dfl_loss.reg_max), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum # 与iou损失一样,除以target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl
然后DFLoss如下,主要是对预测距离与真实距离做交叉熵,并加权平均计算值。其中左右权重的计算遵循距离值越大,权重就越小的原则。
# pred_dist: n*4x16, target: nx4
target = target.clamp_(0, self.reg_max - 1 - 0.01) # n, 4
tl = target.long() # target left 真实框向左取整
tr = tl + 1 # target right 真实框向右取整
wl = tr - target # weight left 向右取整-目标得到左边的权重
wr = 1 - wl # weight right 向左取整-目标得到右边的权重
return ( # 左右预测距离与真实距离做交叉熵计算,并乘以权重
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr
).mean(-1, keepdim=True)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









