







文章目录
前言
我们现在生活的时代是一个数据时代,近年来随着互联网的高速发展,每分每秒都在产生数据。那么产生的这些数据如何进行存储和相应的分析处理呢?各大公司纷纷研发和采用一批新技术来应对日益庞大的数据处理需求,主要包括分布式文件系统、分布式计算框架等,这些都是我们需要学习和掌握的。
要想学习一门技术,我通常先从全局的角度出发,首先建立起对这门技术的认识,了解其发展现状,以及技术体系,然后循序渐进的去了解这项技术应用到的知识,把它们梳理清楚,串联起来。
1 大数据技术体系
- 基础技术:大数据基础技术为应对大数据时代的多种数据特征而产生。大数据时代,数据量大、数据源异构多样、数据实效性高等特征催生了高效完成海量异构数据存储与计算的技术需求。
- 数据管理技术:企业与组织内部的大量数据因缺乏有效的管理普遍存在着数据质量低、获取难、整合不易、标准混乱等问题,使得数据后续的使用存在众多障碍。在此情况下,用于数据整合的数据集成技术,以及用于实现一系列数据资产管理职能的数据管理技术随之出现。
- 数据分析应用技术:数据分析应用技术发掘数据资源的内蕴价值。在拥有充足的存储计算能力以及高质量可用数据的情况下,如何将数据中蕴涵的价值充分挖掘并同相关的具体业务结合以实现数据的增值成为了关键。用以发掘数据价值的数据分析应用技术,包括以BI Business Intelligence )工具为代表的简单统计分析与可视化展现技术,及以传统机器学习、基于深度神经网络的深度学习为基础的挖掘分析建模技术纷纷涌现,帮助用户发掘数据价值并进一步将分析结果和模型应用于实际业务场景中。
- 数据安全流通技术:数据安全流通技术助力安全合规的数据使用及共享。在数据价值的释放初现曙光的同时,数据安全问题也愈加凸显,数据泄露、数据丢失、数据滥用等安全事件层出不穷,对国家、企业和个人用户造成了恶劣影响,如何应对大数据时代下严峻的数据安全威胁,在安全合规的前提下共享及使用数据成为了备受瞩目的问题。访问控制、身份识别、数据加密、数据脱敏等传统数据保护技术正积极向更加适应大数据场景的方向不断发展,同时,侧重于实现安全数据流通的隐私计算技术也成为了热点发展方向。
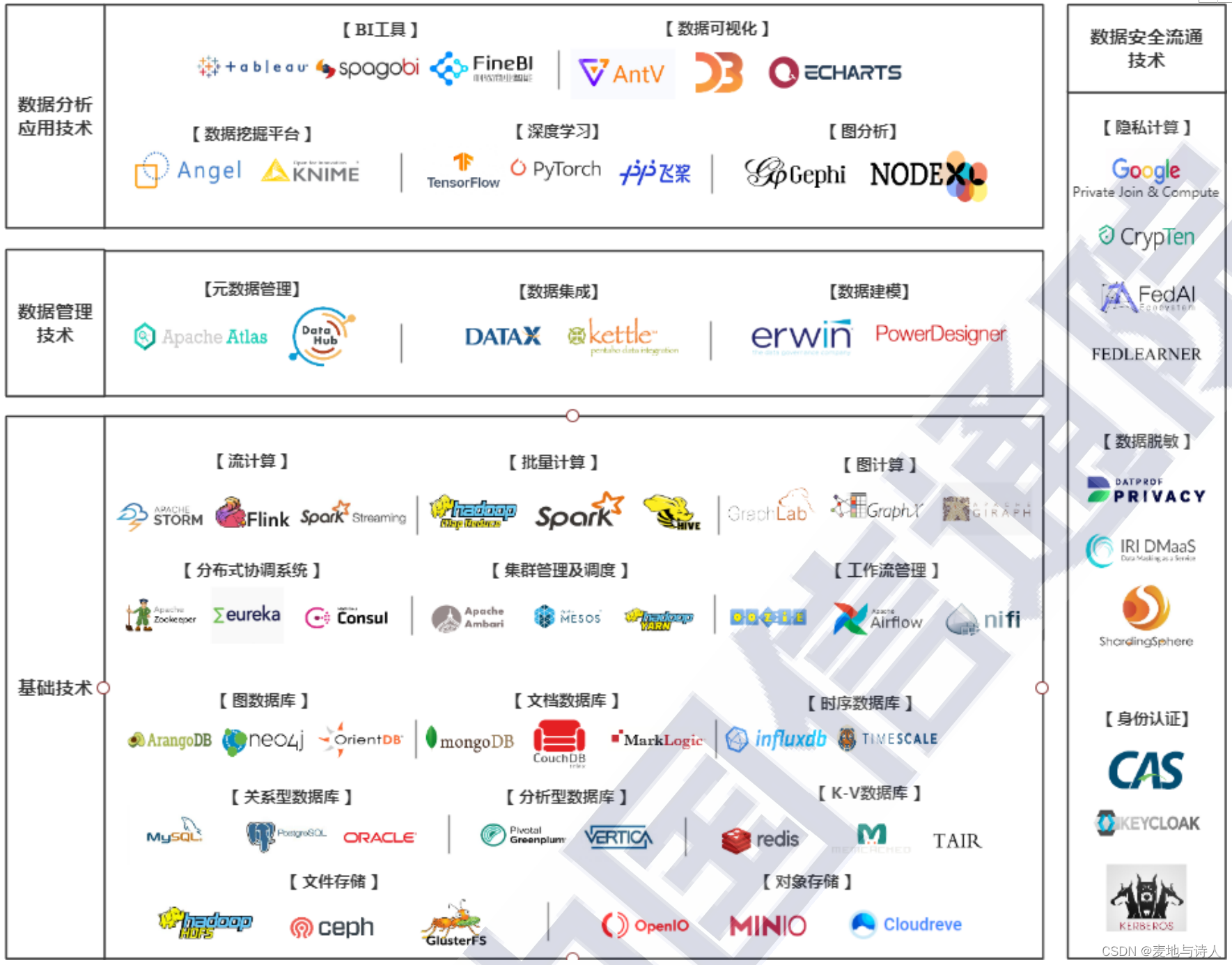
摘自中国信通院出版的《大数据白皮书(2020年)》
2 大数据平台演变
大数据技术体系的核心始终是面向海量数据的存储、计算、处理等基础技术。
2000年前后,在互联网高速发展的时代背景下,数据量急剧增大、数据类型愈加复杂、数据处理速度需求不断提高,大数据时代全面到来。
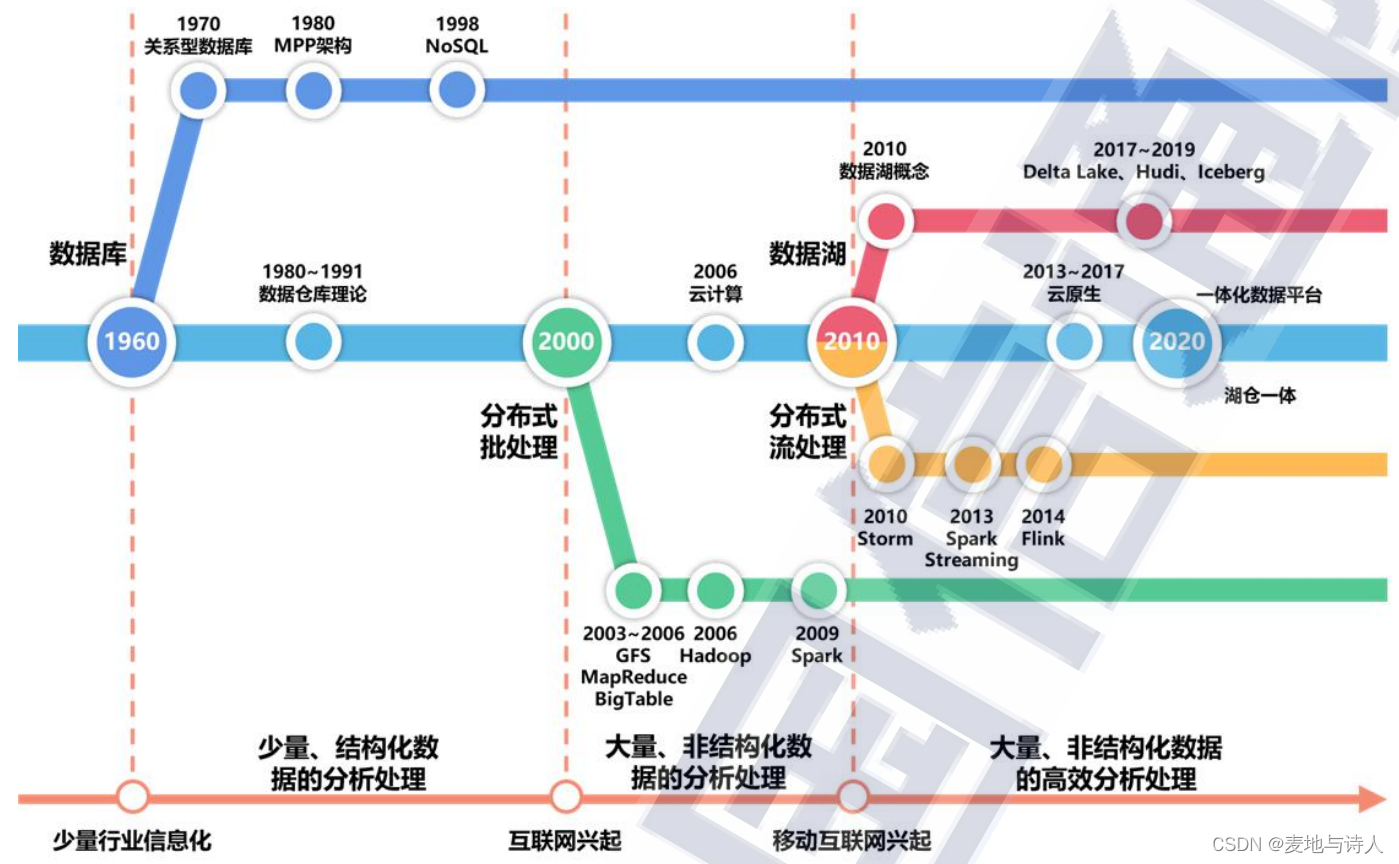
摘自中国信通院出版的《大数据白皮书(2021年)》
3 Hadoop
Hadoop是较早出现的一种分布式架构,得到了大量的应用。
Hadoop四大基本组件:
- Hadoop基础功能库:支持其他Hadoop模块的通用程序包。
- HDFS:一个分布式文件系统,能够以高吞吐量访问应用的数据。
- YARN:一个作业调度和资源管理框架。
- MapReduce:一个基于YARN的大数据并行处理程序。

4 Hadoop生态圈
除了基本组成部分,Hadoop生态圈中还有很多其他的工具组件,Hadoop生态圈就是为了处理大数据而产生的解决方案。本问主要介绍:
- Hive:一个基于Hadoop的数据仓库工具;
- Hbase:一款分布式数据库;
- Kafka:一种消息中间件;
- Zookeeper:一个用于分布式应用的高性能协调服务;
4.1 Hive:一个基于Hadoop的数据仓库工具
Hive,构建在Hadoop大数据平台之上,是一个基于Hadoop的数据仓库工具,它可以把结构化的数据文件映射为一张数据仓库表,并提供简单的SQL(StructuredQuery Language)查询功能,后台将SQL语句转换为MapReduce任务来运行。使用Hive,能够帮助用户屏蔽掉复杂的Map Reduce逻辑,可以满足一些不懂MapReduce但懂SQL的数据库管理员的需求,让他们能够平滑地使用大数据分析平台。
具体地说,Hive数据存储依赖于HDFS,HiveSQL的执行引擎依赖MapReduce、Spark、Tez等分布式计算引擎,Hive作业的资源调度依赖于YARN、Mesos等大数据资源调度管理组件。
所以到底为什么要使用Hive?
使用Hadoop的Map Reduce进行数据处理时面临着人员学习成本太高、项目周期要求太短、Map Reduce实现复杂逻辑开发难度太大等问题。这就是我们使用Hive的原因所在了。当我们使用Hive时,操作接口采用类SQL语法,提供了快速开发的能力,避免了写Map Reduce,减少了开发人员的学习成本,而且扩展功能很方便。
Hive和传统数据库的区别?
Hive具有SQL数据库的很多类似功能,但应用场景完全不同,Hive只适合做批量数据统计分析。

摘自《Hadoop与Spark的大数据开发实战》,2018年出版
4.2 HBase:一款分布式数据库
HBase(Hadoop Database)是Hadoop平台中重要的非关系型数据库,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,它通过线性可扩展部署,可在廉价PC上搭建起大规模结构化存储集群,可以支撑PB级数据存储与处理能力。作为非关系型数据库,HBase适合于非结构化数据存储,它的存储模式是基于列的。
HBase,使用HDFS作为底层文件存储系统,在其上可以运行MapReduce批量处理数据,使用ZooKeeper作为协同服务组件。
HDFS可以存储海量数据,但访问和查询速度比较慢,HBase可以提供给用户毫秒级的实时查询服务,它是一个基于HDFS的分布式数据库。
HBase还是一种非关系型数据库,即NoSQL数据库。作为NoSQL家庭的一员,HBase的出现弥补了Hadoop只能离线批处理的不足,同时能够存储小文件,提供海量数据的随机检索,并保证一定的性能。而这些特性也完善了整个Hadoop生态系统,泛化其大数据的处理能力,结合其高性能、稳定、扩展性好的特行,给使用大数据的企业带来了福音。
NoSQL在大数据中扮演的角色
NoSQL,是Not only SQL的缩写,泛指非关系型的数据库。与关系型数据库相比,NoSQL存在许多显著的不同点,其中最重要的是NoSQL不使用SQL作为查询语言。其数据存储可以不需要固定的表模式,也通常会避免使用SQL的JOIN操作,一般又都具备水平可扩展的特性。NoSQL的实现具有两个特征:使用硬盘和把随机存储器作存储载体。
Hive和Hbase的关系:在大数据架构中,Hive和HBase是协作关系,数据流一般如下:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
参考:
- 《Hbase企业应用开发实战》2014
- 《Hbase原理与实践》2019
4.3 Kafka:一种消息中间件
(1)先了解:什么是消息中间件?
在计算机领域,但凡在两个不同应用或系统间传递的数据,都可以称为消息。
这些消息可以表现为字符串、JSON对象或AVRO对象等。当在两个业务逻辑处理单元间传递消息时,需要先将这些消息对象序列化为字节数组,然后经网络传递,最后由消息消费方接收并反序列化,恢复为最初的消息模样。
(2)消息中间件的工作模式
- 点对点模式(Point-to-Point,P2P)
点对点模式,是消息中间件最简单的工作模式。
用Java中的BlockingQueue来描述点对点模式是非常合适的,消息生产者将消息发送到消息中间件的某个队列中,同时消息消费者从这个队列的另一端接收消息。生产者和消费者之间是相互独立的。点对点模式的消息中间件支持多个消费者,但是一条消息只能由一个消费者消费。图展示了消息中间件点对点模式的工作原理。

2. 发布/订阅模式
发布/订阅模式是消息中间件的另一种工作模式。发布订阅模式的功能更强,使用场景更多,是大多数消息中间件的主要工作模式。
在发布订阅模式中,我们先定义好一个具有特定意义的主题( topic),消息生产者将所有属于这个主题的消息发送到消息中间件中代表这个主题的消息队列上,然后任何订阅了这个主题、对该主题感兴趣的消息消费者都可以接收这些消息。发布订阅模式使得消息生产者和消息消费者之间的通信不再是一种点到点的传输,而是由消息中间件作为代理人统一管理消息的接收、组织、存储和转发,这样减少了系统中所有生产者和消费者之间的连接数量,从而降低整个系统的复杂度。和点对点方式不同,发布到主题的消息会被所有订阅者消费。图8-2展示了消息中间件发布/订阅模式的工作原理。

(3)Kafka:消息中间件的一种
Kafka是由LinkedIn开源的一个用于管理和处理流式数据的发布/订阅消息系统。它具备超高性能、分布式、错误容忍等优良特性,非常适合用于实时传输流式大数据。可以说,Kafka是我们构建流计算系统的必备利器。

摘自《实时流计算系统与实现》,2021,推荐这本书!
4.4 ZooKeeper:一个用于分布式应用的高性能协调服务
Hadoop生态圈中很多组件使用动物来命名,形成了一个大型“动物园”,ZooKeeper是这个动物园的管理者,主要负责分布式环境的协调。

4.5 YARN,另一种资源协调者
Apache Hadoop YARN(Yet Another Resource Negotiator,另一种资源协调者)是从Hadoop 0.23进化来的一种新的资源管理和应用调度框架。
基于YARN,可以运行多种类型的应用程序,例如MapReduce、Spark、Storm等。YARN不再具体管理应用,资源管理和应用管理是两个低耦合的模块。
YARN从某种意义上来说,是一个云操作系统(Cloud OS)。基于该操作系统之上,程序员可以开发多种应用程序,例如批处理MapReduce程序、Spark程序以及流式作业Storm程序等。这些应用,可以同时利用Hadoop集群的数据资源和计算资源。
5 Spark
Spark是基于内存计算的大数据并行计算框架,因为它基于内存计算,所以提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
Spark提供了一个强有力的一栈式通用的解决方案。使用Spark能完成批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、图计算(Graph X)及机器学习(MLlib)。Spark内部的这些组件都可以在一个Spark应用程序中无缝对接、综合使用。

Spark与Hadoop的关系
首先这两个名字后面都代表了业界先进的大数据技术生态圈,从这个角度上来说,两者肯定是存在竞争关系的,但在实际情况中,由于Hadoop存量用户数太多,加之Spark生态圈技术成熟度的一些问题,因此,更多情况下,Spark和Hadoop会互补形成生产环境的解决方案,它们之间的关系是竞争与合作并存。
Spark执行的特点Hadoop中包含计算框架MapReduce和分布式文件系统HDFS。Spark是MapReduce的替代方案,而且兼容HDFS、Hive等分布式存储层,融入Hadoop的生态系统,并弥补MapReduce的不足。
—《spark大数据分析实战》
6 Flink
在大数据领域,现在已经不缺少数据处理框架了,但是没有一个框架能够完全满足不同的处理需求。
批处理与流处理一般被认为是两种截然不同的任务,一个大数据框架一般会被设计为只能处理其中一种任务。比如,Storm只支持流处理任务,而MapReduce、Spark只支持批处理任务。SparkStreaming是ApacheSpark之上支持流处理任务的子系统,这看似是一个特例,其实不然。
但是,Flink是一款新的大数据处理引擎,目标是统一不同来源的数据处理。这个目标看起来和spark和类似。没错,flink也在尝试解决spark在解决的问题。这两套系统都在尝试建立一个统一的平台可以运行批量,流式,交互式,图处理,机器学习等应用。所以,flink和spark的目标差别并不大,他们最主要的区别在于实现的细节。

6 结尾
以上整理的内容,均是摘自看过的书中,书中介绍的内容远不止此,有兴趣的童鞋可以根据书名,继续深入探索哟。后续也会一边学习,一边整理。
如果你觉得这篇文章有用,请给我个赞吧,我不要钱,只想要个赞开心一下啦哈哈~

















 8665
8665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









