







引言
在人工智能的浪潮中,大型语言模型(LLMs)展现出前所未有的能力。然而,驱动这些强大功能的往往是巨大的计算开销,尤其是在模型部署和实际应用(即推理)阶段。为了克服这一挑战,研究人员提出了“动态推理”的概念,其核心思想是让模型能够根据输入信息的复杂程度,灵活地调整所需的计算资源。而“条件计算”正是实现动态推理的关键技术之一。
1. 动态推理的意义:按需分配计算资源
动态推理的核心在于使模型具备“智慧”地分配计算资源的能力。如同我们人类在处理不同任务时会调整精力投入一样,动态推理旨在让模型能够:
- 减少不必要的计算: 对于简单的输入,模型可以采取更轻量级的计算路径,避免冗余操作,从而节省计算成本。例如,在处理简短、明确的问题时,模型可能只需要激活网络中的一部分关键模块即可获得答案,而无需进行完整的、耗时的前向传播。
- 提升推理速度: 计算量的减少直接转化为更快的响应速度,这对于需要实时交互的应用至关重要,例如在线聊天机器人、实时翻译等。更快的推理速度也意味着更高的用户体验。
- 更好地适应输入变化: 模型能够根据输入数据的特性(例如,文本的长度、主题的复杂性、甚至输入中是否存在歧义或噪声)动态地调整其内部计算流程,从而更高效地处理各种各样的输入。这种自适应性使得模型在面对不同难度的问题时都能保持良好的性能和效率。
2. 条件计算的奥秘:激活“专家”团队
条件计算是实现动态推理的一种重要手段。它允许模型在推理过程中,根据输入数据的特点,选择性地激活网络中的特定部分进行计算。这种“按需激活”的机制使得模型能够更高效地利用其内部的参数和计算资源。
2.1 Sparse MoE (Mixture-of-Experts) 稀疏 MoE 模型:构建“专家”团队
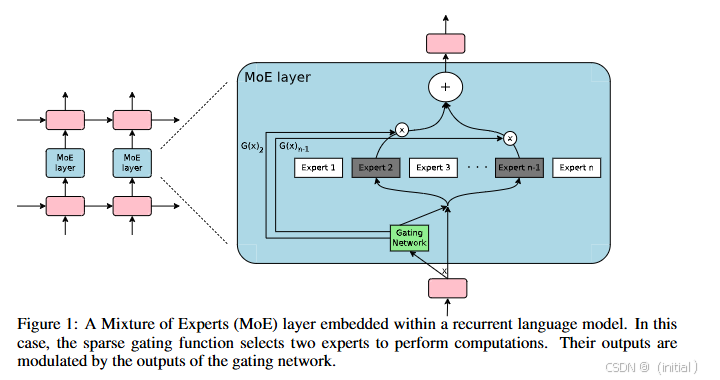
稀疏 MoE 模型的核心思想是将一个庞大的模型分解为多个小的、独立的子模型,称为“专家(Experts)”。每个专家都专注于学习数据中的不同模式或特征。当模型接收到输入时,一个被称为“门控网络(Gating Network)”的组件会根据输入的内容,决定应该激活哪些专家来处理当前的输入。
-
Expert 选择机制: 模型内部维护着一个包含多个专家(通常是前馈神经网络层)的集合。每个专家都拥有独立的参数,并专注于学习不同的数据分布,从而提高模型的整体容量。
-
门控网络 (Gating Network): 门控网络接收输入 x \mathbf{x} x,并使用一个通常包含线性层和 Softmax 激活的结构来计算每个专家的选择概率:
P ( Expert i ∣ x ) = softmax ( g ( x ) ) i = exp ( g i ( x ) ) ∑ j = 1 E exp ( g j ( x ) ) P(\text{Expert } i | \mathbf{x}) = \text{softmax}(\mathbf{g}(\mathbf{x}))_i = \frac{\exp(g_i(\mathbf{x}))}{\sum_{j=1}^{E} \exp(g_j(\mathbf{x}))} P(Expert i∣x)=softmax(g(x))i=∑j=1Eexp(gj(x))exp(gi(x))
其中 g ( x ) \mathbf{g}(\mathbf{x}) g(x) 是门控网络的输出, E E E 是 Expert 的数量。模型通常会选择概率最高的 k k k 个专家进行后续计算,这里的 k k k 是一个预先设定的超参数,控制着模型的稀疏性。
代码示例 (PyTorch):
import torch import torch.nn as nn class GatingNetwork(nn.Module): def __init__(self, input_dim, num_experts): super().__init__() self.fc = nn.Linear(input_dim, num_experts) self.softmax = nn.Softmax(dim=-1) def forward(self, x): return self.softmax(self.fc(x)) class SparseMoE(nn.Module): def __init__(self, input_dim, num_experts, expert_output_dim, num_selected_experts=2): super().__init__() self.gating_network = GatingNetwork(input_dim, num_experts) self.experts = nn.ModuleList([nn.Linear(input_dim, expert_output_dim) for _ in range(num_experts)]) self.num_selected_experts = num_selected_experts def forward(self, x): gate_outputs = self.gating_network(x) # 选择 Top-k 个专家 top_k_values, top_k_indices = torch.topk(gate_outputs, self.num_selected_experts, dim=-1) expert_outputs = for i in range(x.size(0)): selected_experts = top_k_indices[i] # 获取被选中专家的输出 current_expert_outputs = torch.stack([self.experts[idx](x[i]) for idx in selected_experts]) # 使用门控网络的输出进行加权 weights = top_k_values[i].unsqueeze(-1) weighted_output = torch.sum(weights * current_expert_outputs, dim=0) expert_outputs.append(weighted_output) return torch.stack(expert_outputs) -
负载均衡: 为了避免某些专家被过度使用而其他专家利用不足,MoE 模型通常会引入辅助损失函数来鼓励门控网络更均匀地选择不同的专家。一种常见的负载均衡损失是基于专家被选择的频率与均匀分布之间的差异进行惩罚。
2.2 Switch Transformer:简化路由的“开关”
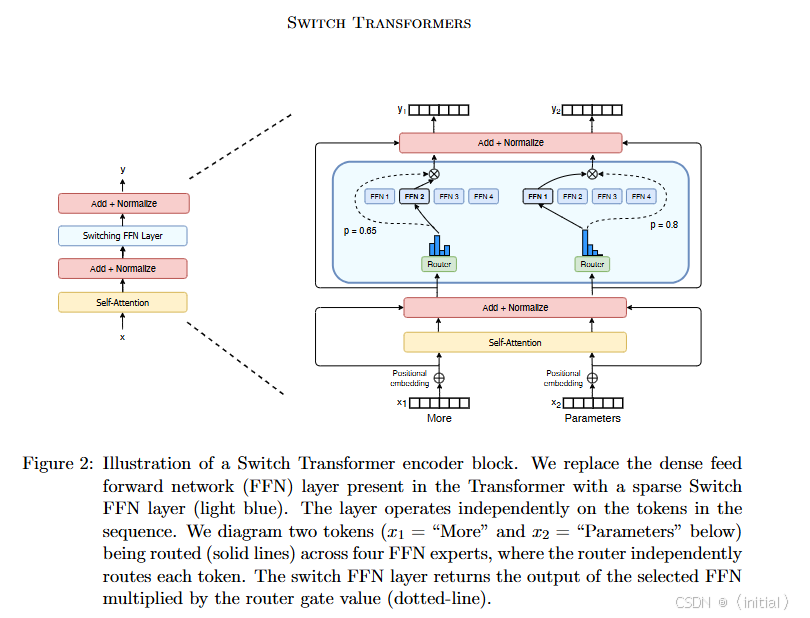
Switch Transformer 是 MoE 的一个变体,它采用了更简化的路由机制。每个输入 token 通常只会被路由到唯一一个最合适的专家。路由选择基于门控网络的输出:
Expert Index = argmax j ( g ( x ) ) j \text{Expert Index} = \text{argmax}_j (\mathbf{g}(\mathbf{x}))_j Expert Index=argmaxj(g(x))j
其中 x i \mathbf{x}_i xi 是输入序列中的第 i i i 个 token。这种简化牺牲了一定的灵活性,但带来了更低的计算开销和更高的推理速度。
代码示例 (PyTorch - 概念性):
class GatingNetwork(nn.Module): # 假设已经定义
def __init__(self, input_dim, num_experts):
super().__init__()
self.fc = nn.Linear(input_dim, num_experts)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
return self.softmax(self.fc(x))
class SwitchTransformerLayer(nn.Module):
def __init__(self, input_dim, num_experts, expert_output_dim):
super().__init__()
self.gating_network = GatingNetwork(input_dim, num_experts)
self.experts = nn.ModuleList([nn.Linear(input_dim, expert_output_dim) for _ in range(num_experts)])
def forward(self, x):
gate_outputs = self.gating_network(x)
routed_outputs =
for i in range(x.size(0)):
expert_index = torch.argmax(gate_outputs[i]).item()
routed_outputs.append(self.experts[expert_index](x[i]))
return torch.stack(routed_outputs)
2.3 Conditional Computation 在 Transformer 中的应用
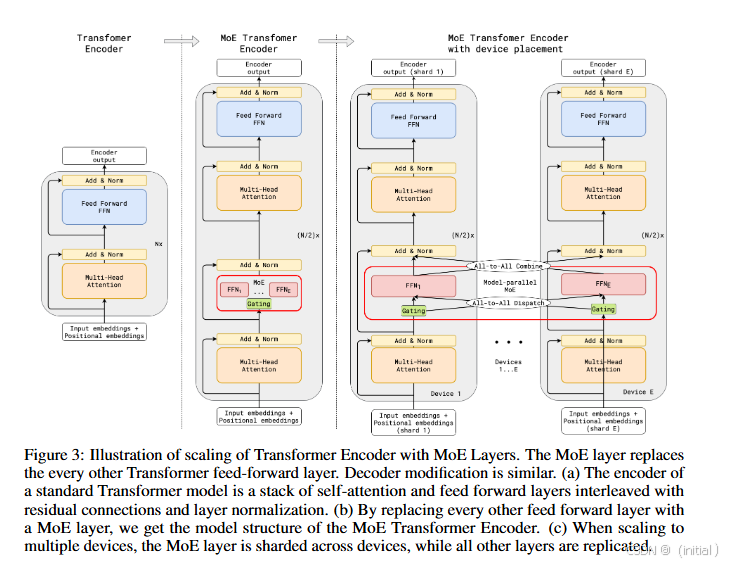
在 Transformer 模型中,条件计算最常应用于模型的前馈网络(FFN)层。标准的 Transformer 层对所有输入都执行相同的 FFN 计算,而引入条件计算后,模型可以根据输入 token 的不同,动态地选择激活不同的 FFN 子网络(即 Experts)。这使得模型能够针对不同的输入特征采用不同的非线性变换,从而提高模型的效率和表达能力。例如,对于输入序列中的每个位置,模型可以根据其上下文信息,决定是否需要激活一个更复杂的 FFN 子网络,或者只需要一个更简单的计算路径。
3. 动态推理的优势与局限性分析
动态推理和条件计算为大型模型带来了显著的优势,但也存在一些需要克服的挑战:
- 显著的性能提升: 通过只激活网络中与当前输入最相关的部分,动态推理可以大幅减少推理所需的计算资源和时间,从而提高吞吐量并降低延迟。这对于部署大规模 LLM 应用至关重要,能够支持更多的并发用户和更快的响应速度。
- 模型容量的扩展: MoE 模型通过引入大量的专家,可以在不显著增加单个样本的计算成本的情况下,极大地扩展模型的参数量和容量,从而提升模型的性能上限,使得模型能够学习更复杂的模式和知识。
- 更高的模型复杂度: 引入额外的门控网络和多个专家模型使得整体模型的参数量和结构更加复杂,这增加了模型存储和管理的难度,同时也可能使得模型的部署和维护更加复杂。
- 训练的挑战: 训练稀疏激活的模型需要更精细的策略来确保各个专家能够学习到不同的知识,并且门控网络能够有效地进行路由。训练的稳定性也可能受到影响,需要仔细调整超参数和训练流程。
- 推理的额外开销: 虽然动态推理可以减少整体的计算量,但门控网络的计算以及路由决策本身也会带来一定的额外开销。在某些情况下,如果模型不够稀疏或者路由机制过于复杂,这些额外开销可能会抵消掉一部分性能提升。
4. 动态推理的未来发展趋势
动态推理是当前人工智能研究的热点方向,未来的发展趋势可能包括:
- 更高效的路由机制: 研究人员正在探索更高效、更精确的路由算法,例如基于更复杂的注意力机制或强化学习的方法,以进一步降低路由开销并提高专家利用率。
- 更细粒度的条件计算: 未来的模型可能会在更细的粒度上实现条件计算,例如在神经元级别或注意力头级别进行动态激活,从而实现更精细的计算控制。
- 自适应的专家容量: 模型可能会根据任务的难度或输入的特性,动态地调整激活的专家数量或专家的容量,实现更灵活的资源分配。
- 与硬件的协同优化: 针对动态推理特点的硬件加速器的设计,例如支持稀疏计算的专用芯片,将进一步提升推理效率。
- 在更多模型架构中的应用: 除了 Transformer,动态推理的思想也有望应用于其他类型的神经网络架构中,例如卷积神经网络和图神经网络。
结论
动态推理与条件计算是提升大型语言模型推理效率和扩展模型容量的关键技术。通过使模型能够根据输入动态地调整计算路径,我们正在构建更加智能、高效且易于部署的 AI 系统。随着研究的不断深入,我们有理由相信,动态推理将在未来的人工智能领域发挥越来越重要的作用。
内容同步在我的微信公众号: 智语Bot
参考文献
- [1] Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. R. (2012). Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580.
- [2] Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q. V., Hinton, G. E., & Dean, J. (2017). Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538.
- [3] Lepikhin, D., Mobahi, H., گردان, A., Alistarh, D., & Agarwal, M. (2020). Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668.
- [4] Fedus, W., Zoph, B., & Shazeer, N. (2021). Switch transformers:
. arXiv preprint arXiv:2101.03961.



















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











