






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
基于注意力的多步超短期农业电力负荷预测分解策略与注意力长短期记忆网络研究
二、注意力长短期记忆网络(Attention-LSTM)的结构特点
💥1 概述
基于注意力的多步超短期农业电力负荷预测分解策略与注意力长短期记忆网络研究
农业电力负荷预测对于农业生产和电力供应具有重要意义。为了提高预测准确性和效率,可以结合注意力机制和长短期记忆网络进行预测研究。
通过EEMD对原始目标序列进行分解,生成衍生的变量序列。然后将它们一起存储在 eemd.csv 中。这是 DARNN 预测模型的代码,该模型使用上述派生变量作为模型的输入来预测未来的农业电力负荷。
首先,可以采用注意力机制对农业电力负荷进行分解,将其分解为多个时间步长的子序列。这样可以更好地捕捉负荷的变化规律和周期性,提高预测的精度。同时,注意力机制可以帮助模型自动学习并关注对预测结果影响较大的时间段和特征,从而提高模型的泛化能力和鲁棒性。
其次,可以采用注意力长短期记忆网络(Attention-based LSTM)进行农业电力负荷预测。这种网络结合了长短期记忆网络(LSTM)和注意力机制,能够更好地捕捉序列数据中的长期依赖关系和重要特征。通过引入注意力机制,模型可以自适应地学习不同时间步长的重要信息,提高了预测的准确性和鲁棒性。
可以构建一个基于注意力的多步超短期农业电力负荷预测分解策略和注意力长短期记忆网络的预测模型。该模型可以充分利用注意力机制和LSTM网络的优势,提高农业电力负荷预测的准确性和效率,为农业生产和电力供应提供更可靠的支持。
一、多步超短期农业电力负荷预测的分解策略
-
分解方法的核心作用
农业电力负荷具有强波动性、非线性和受气象因素显著影响的特性(如温室大棚需调节温湿度)。分解策略通过将原始负荷序列分解为高频、低频或趋势分量,降低序列复杂度,提高模型对关键特征的捕捉能力。常用方法包括:- 经验模态分解(EEMD) :通过自适应分解生成多个本征模态函数(IMF),缓解模态混叠问题。例如,某研究采用EEMD将负荷分解为多个IMF,再结合注意力LSTM进行预测,R²达0.96,MAE降低至1.23%。
- 变分模态分解(VMD) :基于频域自适应分解,优于小波分析和EEMD,尤其在独立性和有效性指标上提升显著。VMD-CNN-LSTM模型通过分解负荷为8组子序列,结合气象特征提取,误差降低19.49%。
- 互补集合经验模态分解(CEEMD) :结合高频LSTM与低频多元线性回归(MLR),解决非平稳序列的预测难题。
-
分解策略的优化方向
- 模态重组与特征筛选:通过样本熵(SE)或排列熵(PE)合并相似分量,减少计算冗余。例如,VMD-PE-IPOA-LSTM模型通过熵值重组模态,MAPE降低59.16%。
- 参数优化:采用粒子群优化(PSO)或改进鹈鹕算法(IPOA)优化VMD的分解层数和惩罚因子,提升模态质量。
- 融合外部因素:将气象数据(温度、湿度)与分解后的模态组合输入模型,增强特征关联性。
二、注意力长短期记忆网络(Attention-LSTM)的结构特点
-
LSTM的时序建模能力
LSTM通过输入门、遗忘门、输出门控制信息流,记忆单元(Cell State)保留长期依赖关系。双向LSTM(Bi-LSTM)进一步整合前向与后向信息,增强上下文理解。 -
注意力机制的增强作用
-
特征权重分配:通过Softmax计算注意力分数,聚焦关键时间步。例如,在编码器-解码器框架中,注意力层为历史负荷分配动态权重,减少无关噪声干扰。
-
多尺度注意力:自适应选择不同时间分辨率(如小时、日、周),捕捉季节性周期44。
-
并行注意力设计:InParformer等模型在时间与频率域并行计算注意力,提升对复杂模式的提取效率。
-
-
Attention-LSTM的典型架构
- 分解-预测框架:先通过VMD/EEMD分解负荷,再将各分量输入Attention-LSTM独立预测,最后重构结果。
- 端到端融合:如DeepFS模型将自注意力与傅里叶分解结合,显式学习趋势和周期性。
三、研究现状与模型性能对比
-
主流模型对比
模型 分解方法 预测网络 关键优势 性能指标(示例) EEMD-Attention-LSTM EEMD 注意力LSTM 抗模态混叠,R²达0.96 MAE: 1.23%, RMSE: 2.15% VMD-CNN-LSTM VMD CNN-LSTM融合 融合气象特征,误差降低19.49% MAPE: 3.2% CEEMD-LSTM-MLR CEEMD LSTM+MLR 高频LSTM+低频MLR,适应非平稳数据 RMSE: 55.72 MW FEDAF 傅里叶去噪 频率增强注意力 处理随机成分,空间效率提升12.8% 交通预测改进19.49% -
性能优化方向
- 误差分析:VMD-PSO-LSSVM模型的最大相对误差较传统方法降低3.36%,表明参数优化对分解效果至关重要。
- 计算效率:稀疏编码(SC)与ESAX距离筛选字典原子,减少70%计算量。
四、农业电力负荷数据特征的影响因素
-
关键影响因素
- 季节性:作物生长周期(如播种期用电高峰)导致负荷周期性波动。
- 气象条件:温度、湿度、日照时数与温室用电强相关(相关系数>0.7)。
- 经济与政策:农村电气化政策推广及农业机械化提升负荷基线。
-
特征工程策略
- 特征筛选:随机森林(RF)评估特征重要性,剔除冗余变量(如空气质量、露点温度)。
- 多模态输入:将分解后的负荷模态与气象数据并行输入CNN-LSTM,提取空间-时序联合特征。
五、未来研究方向
- 动态分解与在线学习:开发自适应分解算法,实时调整模态数量以应对负荷突变。
- 可解释性增强:结合注意力权重可视化,解析模型对气象或季节因素的敏感度44。
- 跨区域泛化能力:构建迁移学习框架,适应不同农业区的负荷模式差异。
📚2 运行结果
2.1 需要的第三方库:
import torch
import argparse
import numpy as np
import pandas as pd
from torch import nn
from torch import optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
from matplotlib import rcParams
from torch.autograd import Variable
from utils import *
from model import *
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score, mean_absolute_percentage_errorimport torch import argparse import numpy as np import pandas as pd from torch import nn from torch import optim import torch.nn.functional as F import matplotlib.pyplot as plt from matplotlib import rcParams from torch.autograd import Variable from utils import * from model import * from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score, mean_absolute_percentage_error
2.2 读取数据
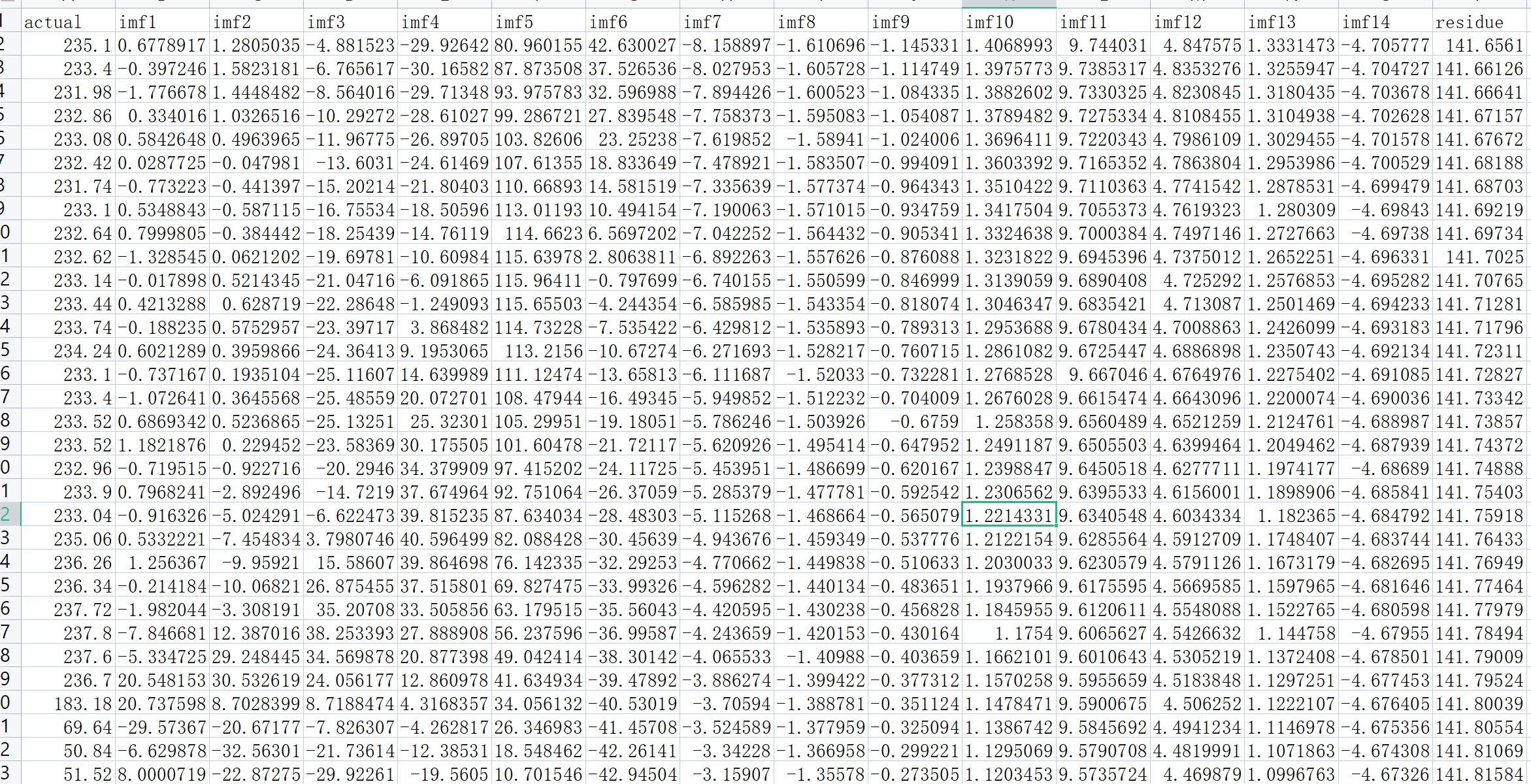 .....
.....

2.3 可视化分析
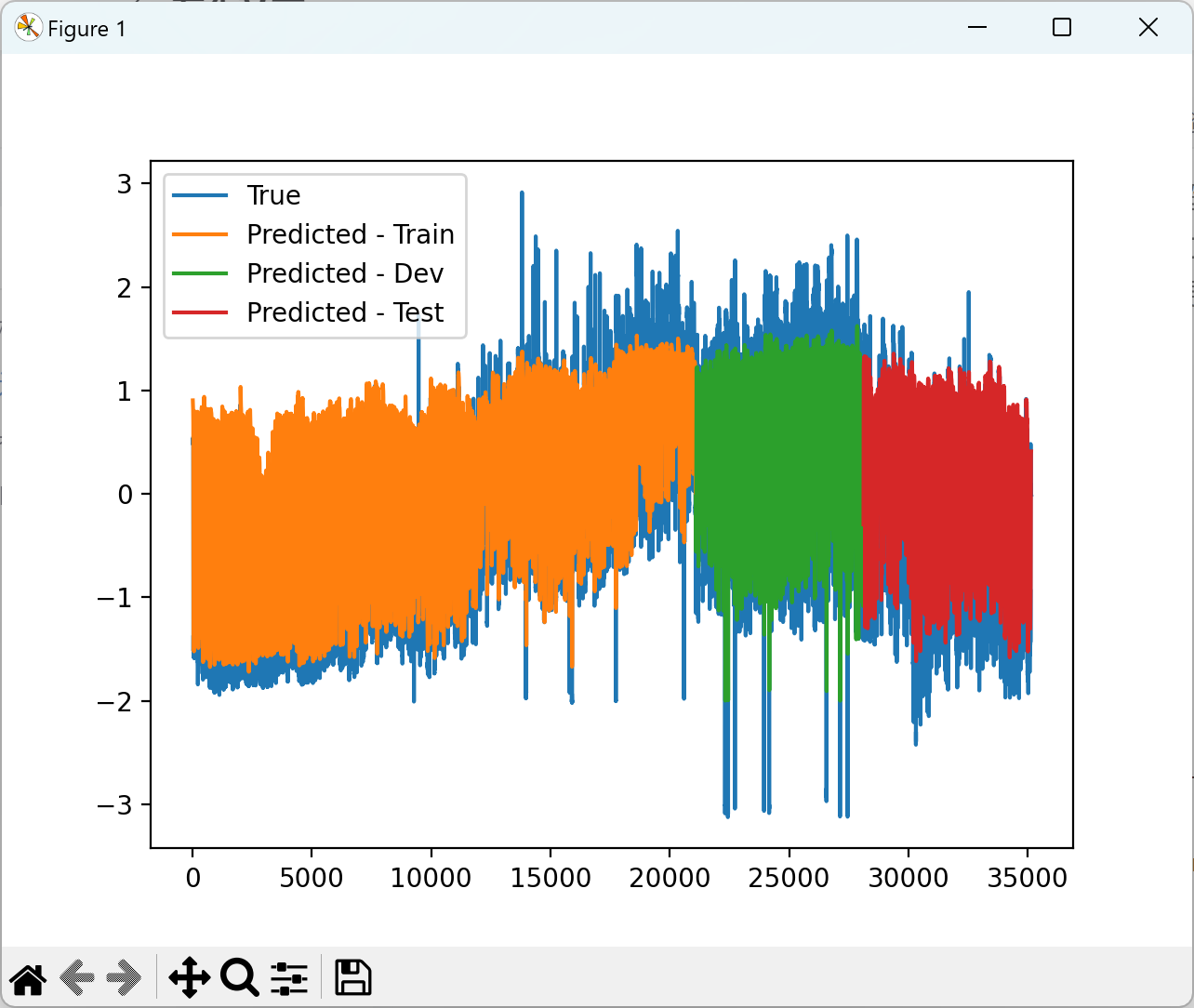
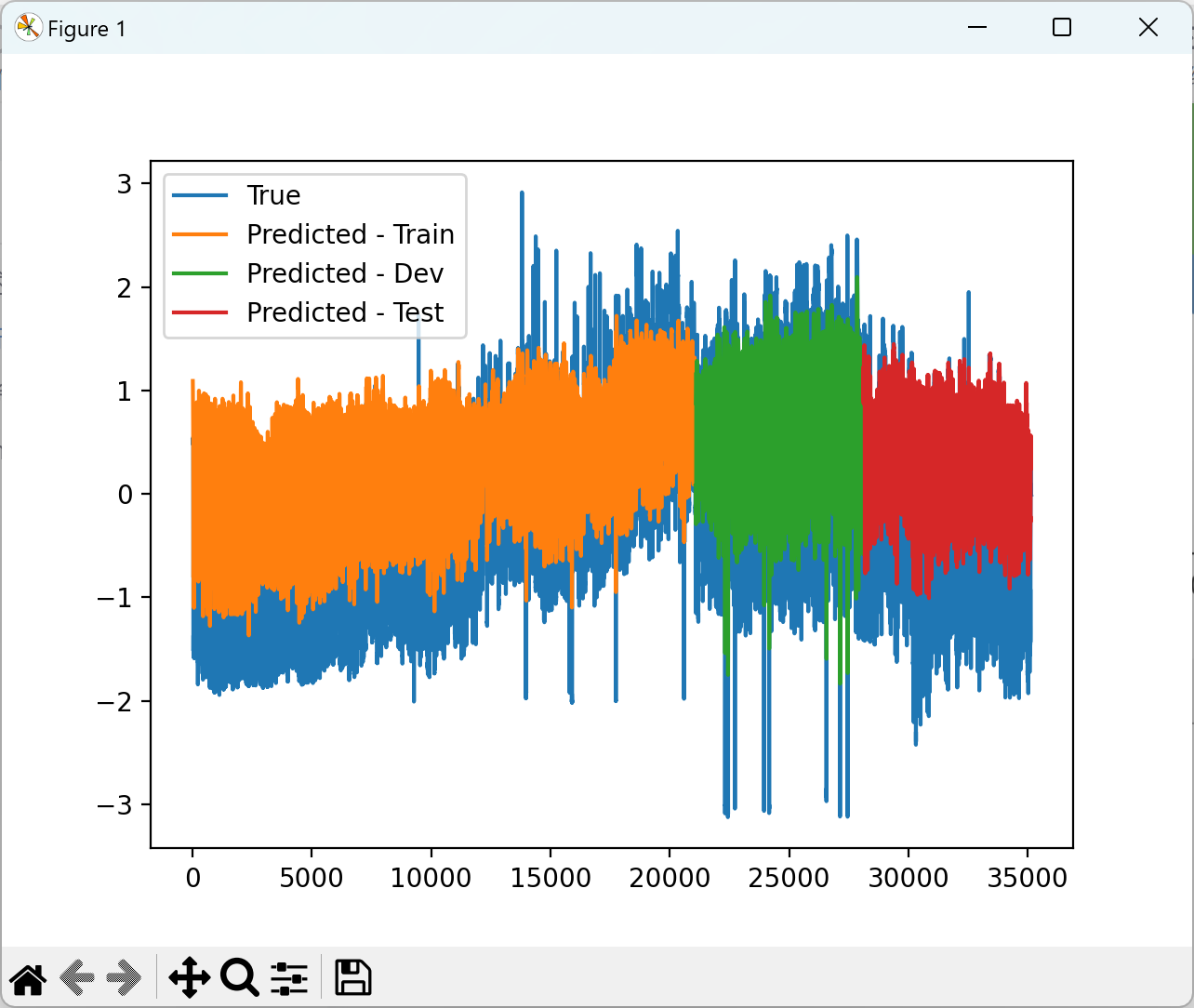
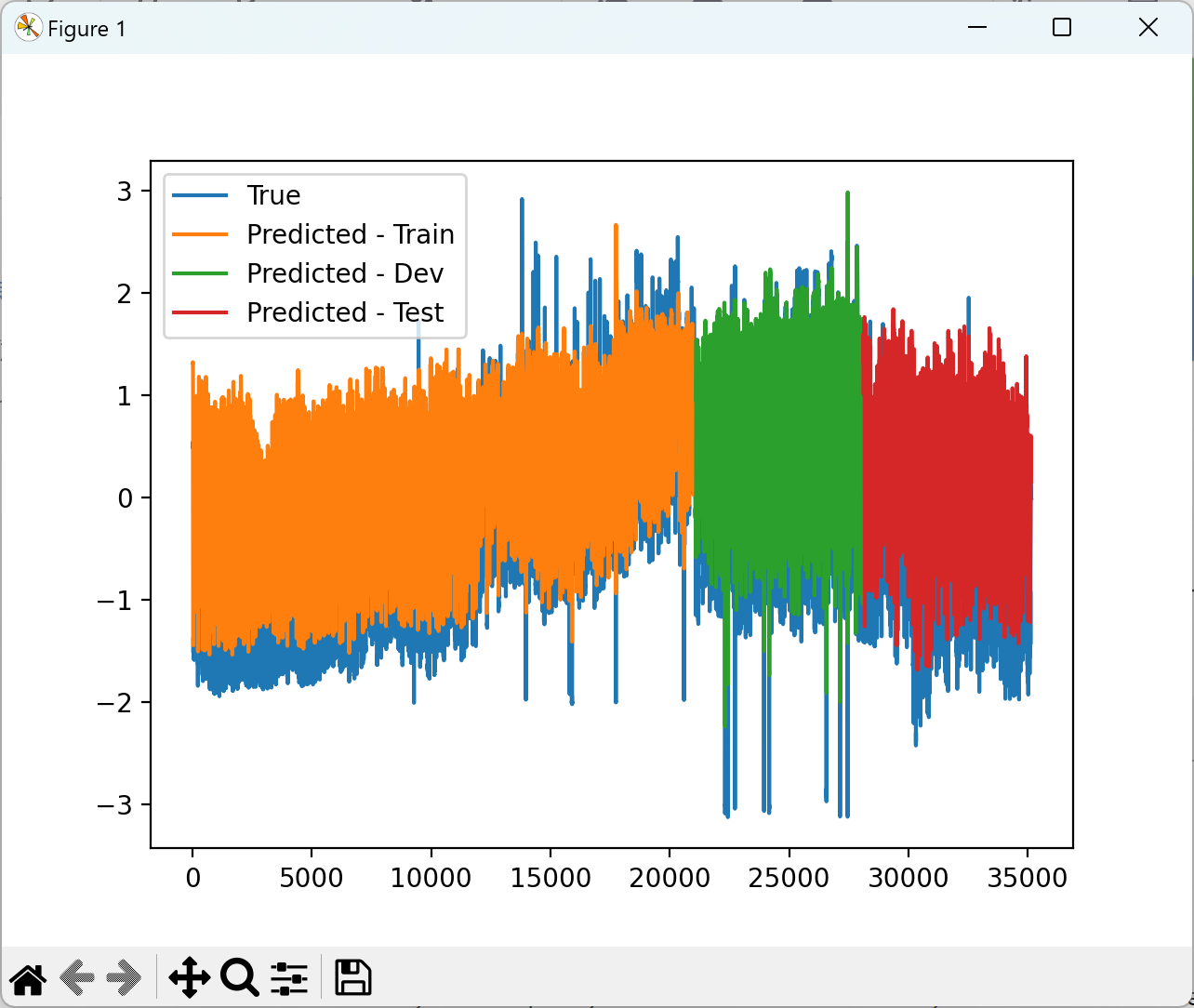
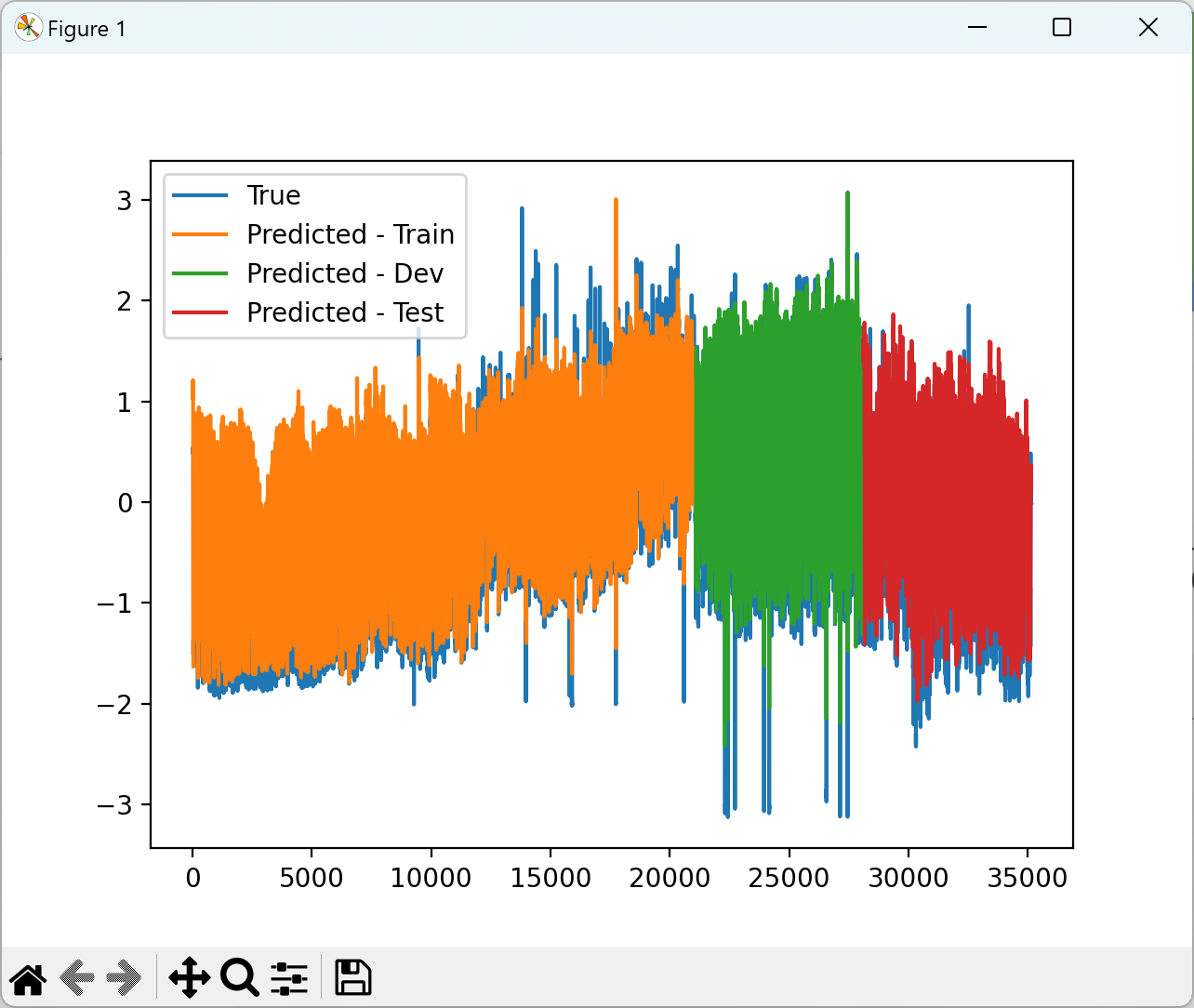
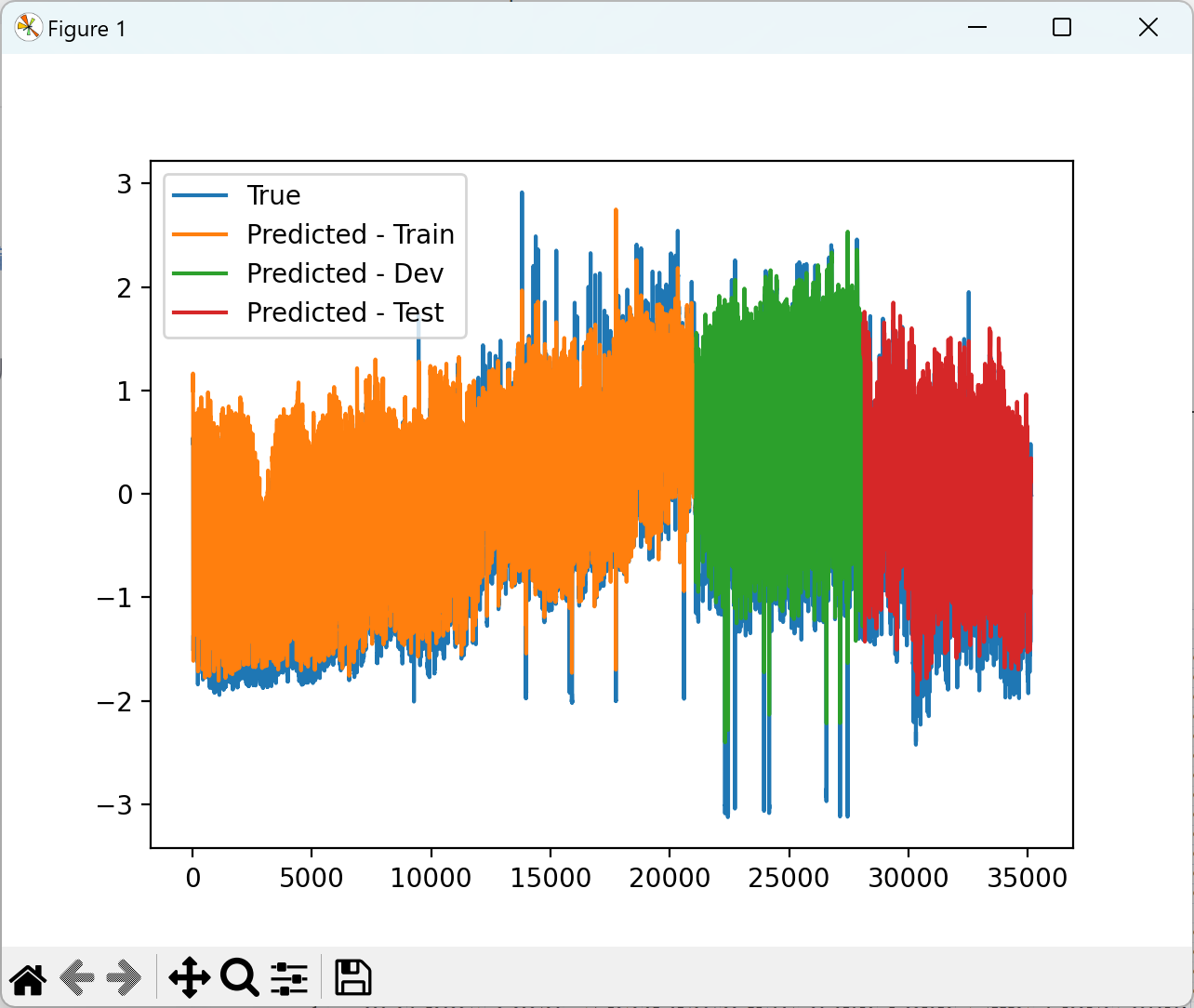
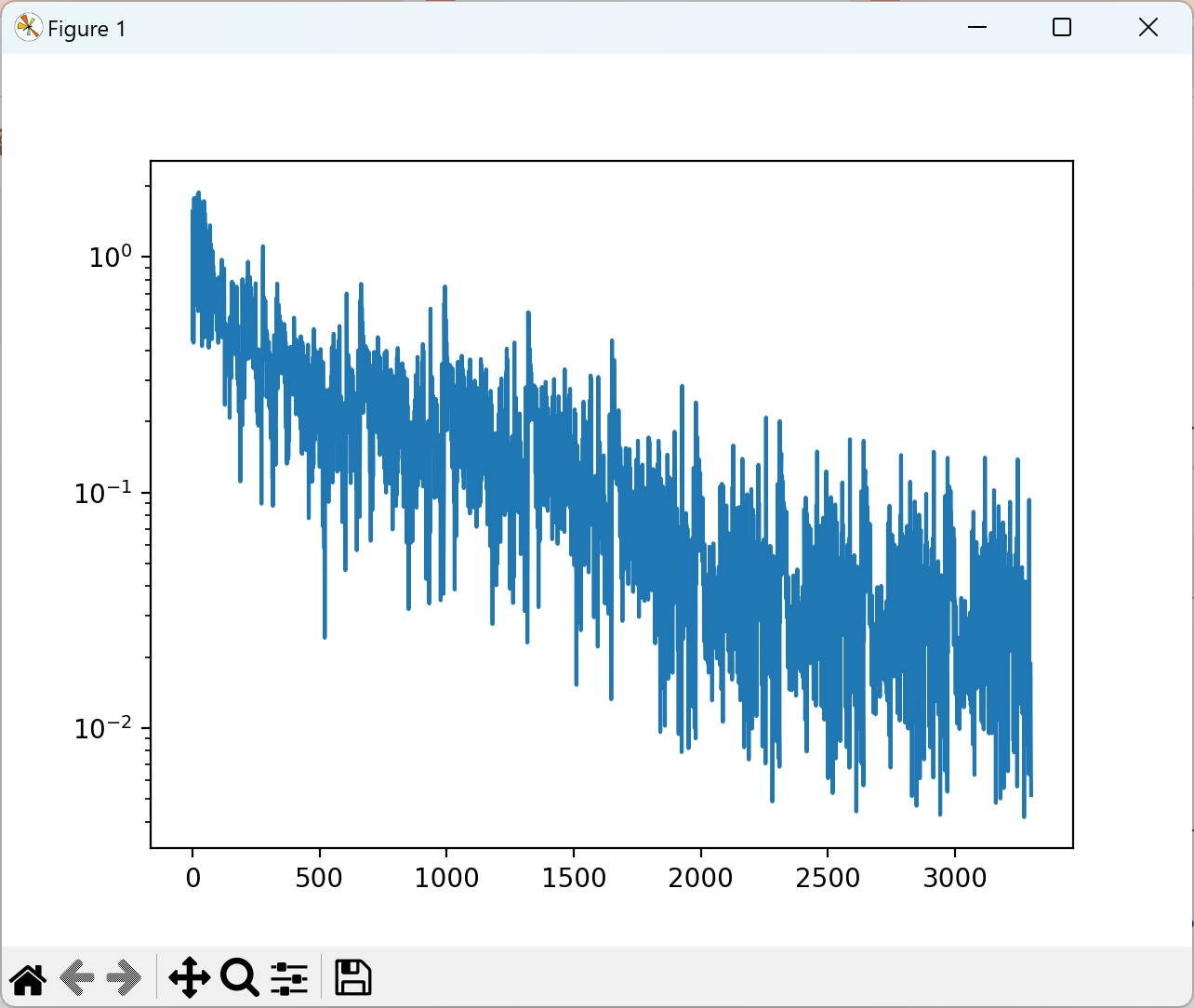
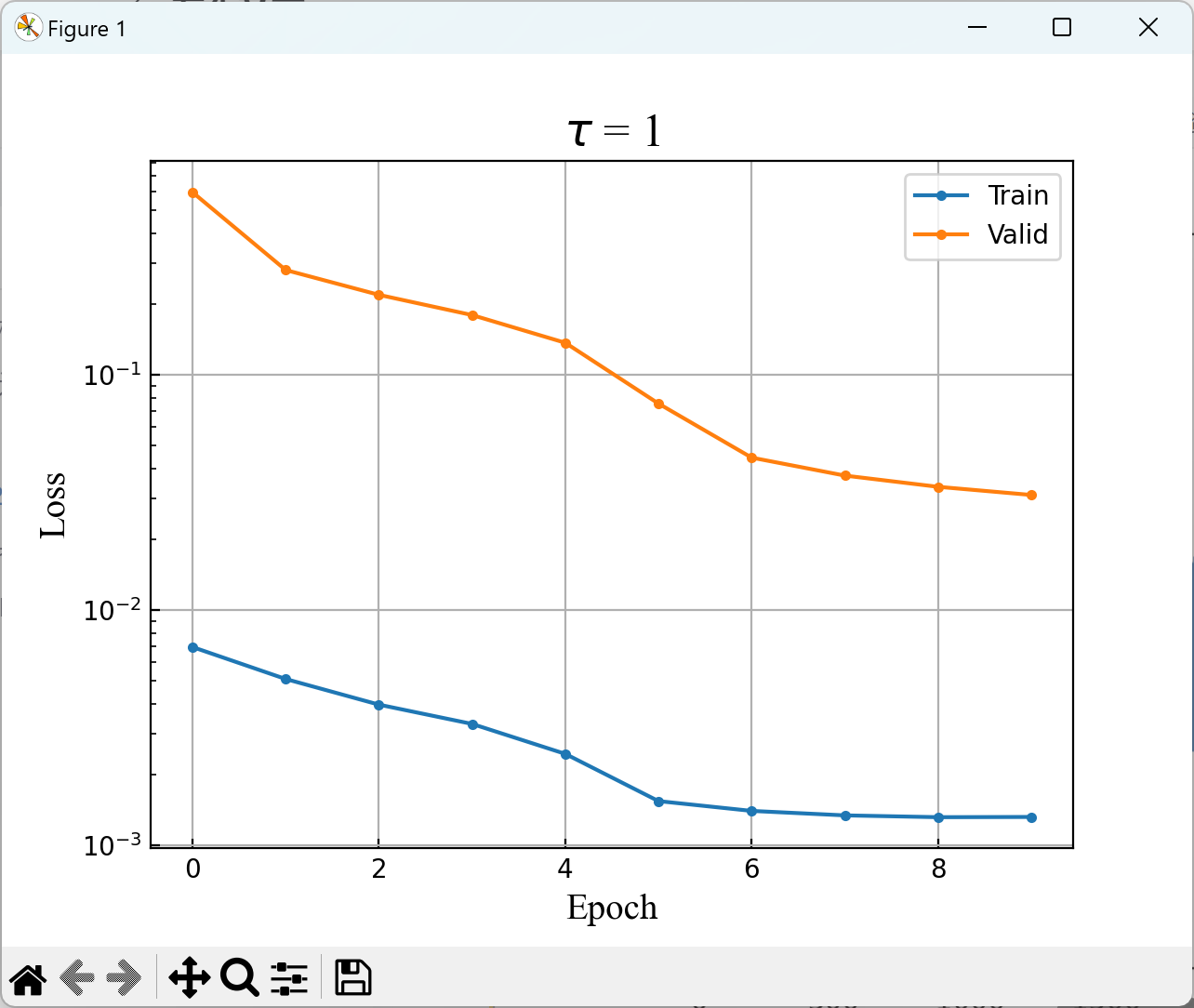
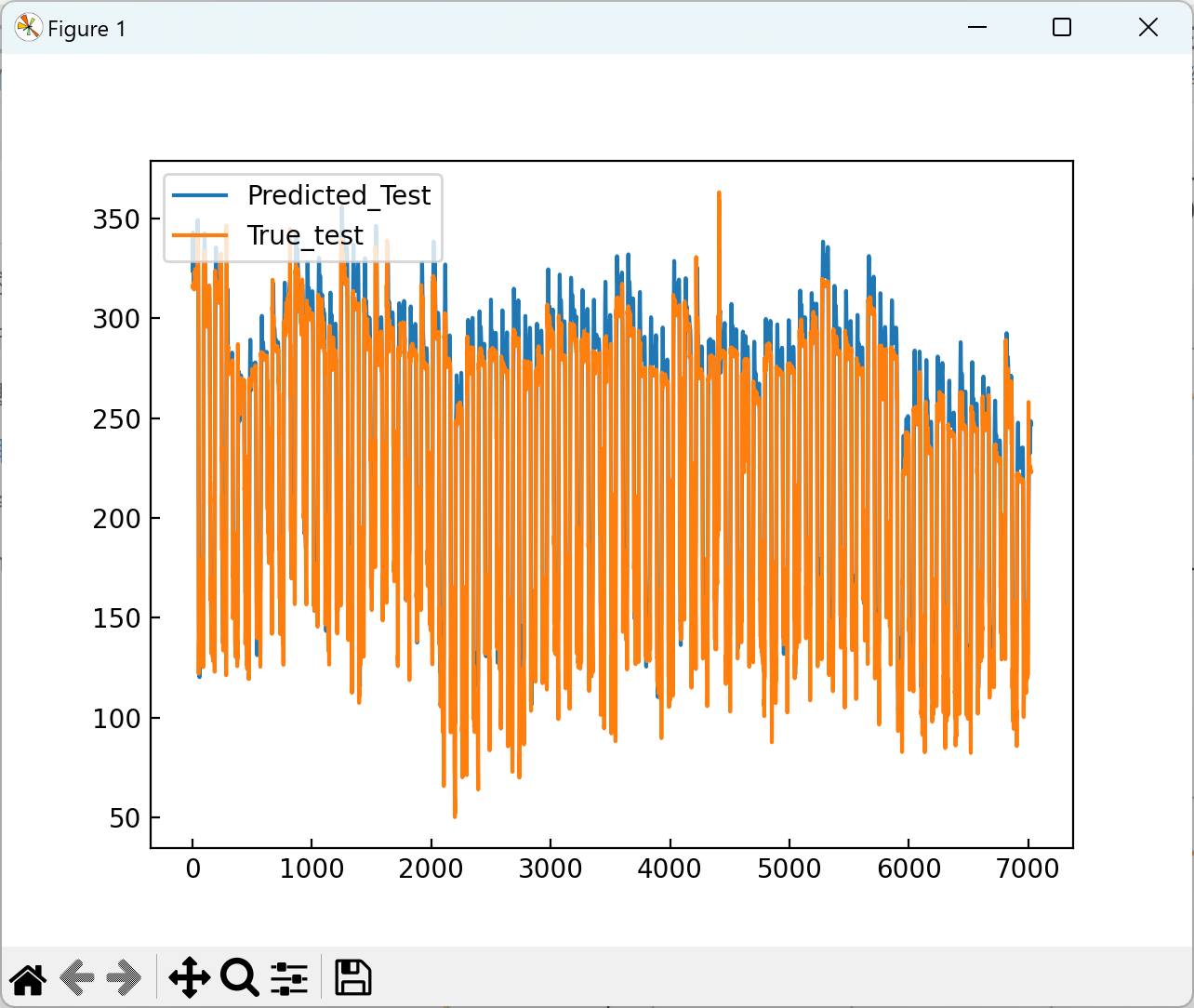
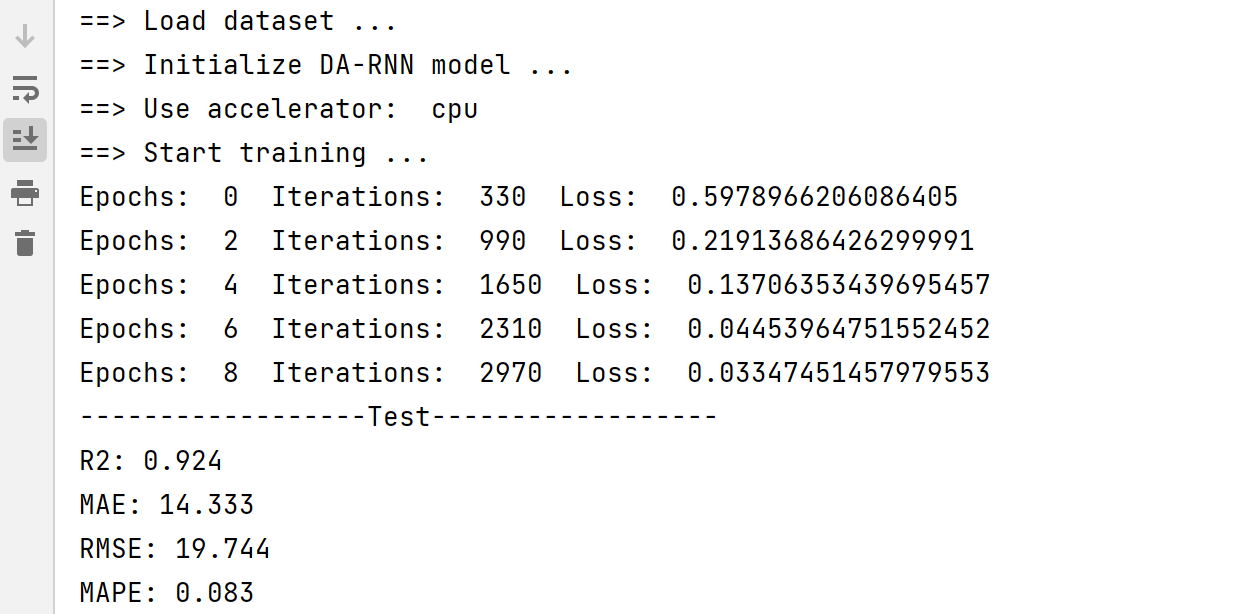
2.4 训练结果

2.5 代码展示
部分代码:
y_train_pred,train_attention_encoder,train_attention_decoder = model.train()
y_test_pred,test_attention_encoder,test_attention_decoder = model.test()
#可视化
fig1 = plt.figure()
plt.semilogy(range(len(model.iter_losses)), model.iter_losses)
plt.savefig("1.png")
plt.show()
#plt.close(fig1)
fig2 = plt.figure()
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
plt.semilogy(range(len(model.epoch_dev_losses)), model.epoch_dev_losses, label="Train", marker = 'o', ms = 3)
plt.semilogy(range(len(model.epoch_train_losses)), model.epoch_train_losses, label="Valid", marker = 'o', ms = 3)
plt.title(r'$\tau$ = 1', fontproperties = 'Times New Roman', size=18)
plt.legend(loc='upper right')
plt.xlabel('Epoch', fontproperties = 'Times New Roman', size=14)
plt.ylabel("Loss", fontproperties = 'Times New Roman', size=14)
plt.grid()
plt.savefig("2.png")
plt.show()
#plt.close(fig2)
y_test_true = model.y[model.train_timesteps + model.dev_timesteps:model.train_timesteps + model.dev_timesteps+model.test_timesteps]
zy_test_pred = y_test_pred * model.std_test_y + model.mean_test_y
zy_test_true = y_test_true * model.std_test_y + model.mean_test_y
fig3 = plt.figure()
plt.plot(zy_test_pred, label='Predicted_Test')
plt.plot(zy_test_true, label="True_test")
plt.legend(loc='upper left')
plt.savefig("3.png")
plt.show()
#plt.close(fig3)
pd.DataFrame(np.hstack((zy_test_true.reshape(-1,1), zy_test_pred.reshape(-1,1))), columns=['y_true', 'y_pred']).to_csv('DARNN_result.csv')
print('------------------Test------------------')
print('R2: %.3f' % r2_score(zy_test_true, zy_test_pred))
print('MAE: %.3f' % mean_absolute_error(zy_test_true, zy_test_pred))
print('RMSE: %.3f' % np.sqrt(mean_squared_error(zy_test_true, zy_test_pred)))
print('MAPE: %.3f' % mean_absolute_percentage_error(zy_test_true, zy_test_pred))
_,train_attention_encoder,train_attention_decoder = model.test('train')
_,dev_attention_encoder,dev_attention_decoder = model.test('dev')
print("训练集的encoder attention权重: ")
print(torch.mean(train_attention_encoder,dim=0))
print("验证集的encoder attention权重: ")
print(torch.mean(dev_attention_encoder,dim=0))
print("测试集的encoder attention权重: ")
print(torch.mean(test_attention_encoder,dim=0))
print("训练集的decoder attention权重: ")
print(torch.mean(train_attention_decoder,dim=0))
print("验证集的decoder attention权重: ")
print(torch.mean(dev_attention_decoder,dim=0))
print("测试集的decoder attention权重: ")
print(torch.mean(test_attention_decoder,dim=0))
if __name__ == '__main__':
main()
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1] Huang Y , Yang L , Liu S ,et al.Multi-Step Wind Speed Forecasting Based On Ensemble Empirical Mode Decomposition, Long Short Term Memory Network and Error Correction Strategy[J].Energies, 2019, 12(10):1822.DOI:10.3390/en12101822.
[2] Nguyen H P , Baraldi P , Zio E ,et al.Ensemble empirical mode decomposition and long short-term memory neural network for multi-step predictions of time series signals in nuclear power plants[J]. 2021.
[3]王健,易姝慧,刘浩,等.基于注意力机制优化长短期记忆网络的短期电力负荷预测[J].中南民族大学学报:自然科学版, 2023, 42(1):73-81.
[4]魏骜,茅大钧,韩万里,等.基于EMD和长短期记忆网络的短期电力负荷预测研究[J].热能动力工程, 2020, 35(4):7.DOI:10.16146/j.cnki.rndlgc.2020.04.028.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









