







 本文介绍了如何使用onnxruntime在VS2019环境中部署Yolov8-seg模型,包括环境配置、代码注释和GPU支持的详细步骤。模型输出包括目标检测和分割掩码,通过矩阵运算生成实例分割结果。
本文介绍了如何使用onnxruntime在VS2019环境中部署Yolov8-seg模型,包括环境配置、代码注释和GPU支持的详细步骤。模型输出包括目标检测和分割掩码,通过矩阵运算生成实例分割结果。
0、前言
在之前博客中已经实现用onnxruntime来部署yolov8的目标检测模型(cpu和gpu皆可)。感兴趣的可以看看:【yolov8部署实战】VS2019环境下使用Onnxruntime环境部署yolov8目标检测|含源码
今天为大家带来的是yolov8-seg分割模型用onnxruntime如何部署,详细注释的代码将给出。
一、部署yolov8分割模型
1.1:环境依赖
主要依赖就是Onnxruntime,如果需要调用Gpu的话还需要配置cuda+cudnn的环境!这里再补充一些:
首先要强调的是,有两个版本的onnxruntime,一个叫onnxruntime,只能使用cpu推理,另一个叫onnxruntime-gpu,既可以使用gpu,也可以使用cpu。
如果自己安装的是onnxruntime,需要卸载后安装gpu版本。
使用onnxruntime调用gpu除了下载gpu版本的onnxruntime之外,还要配置好与之匹配的cuda+cudnn环境:
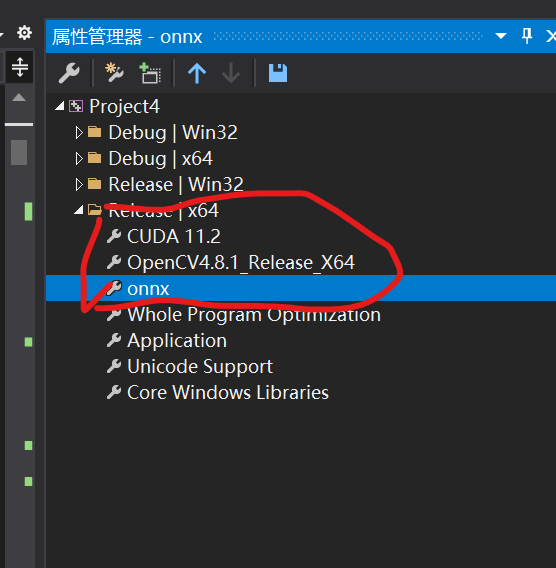
在代码方面,只需要在创建session会话时,加上配置信息:
//Ort::SessionOptions用于配置Onnx Runtime会话的选项(如图优化级别、执行器等)
Ort::SessionOptions sessionOption;
if (cudaEnable) {
OrtCUDAProviderOptions cudaOption;
cudaOption.device_id = 0;
sessionOption.AppendExecutionProvider_CUDA(cudaOption);
}
//为会话设置图优化级别
sessionOption.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
//决定在执行模型操作说内部(单个操作)可以并行运行的线程数
sessionOption.SetIntraOpNumThreads(IntraOpNumThreads);
//设置日志严重级别
sessionOption.SetLogSeverityLevel(LogSeverityLevel);
//创建一个会话(session),用于加载模型并设置会话选项
Session* session = new Session(env, wstring(model_path.begin(), model_path.end()).c_str(), sessionOption);
报错以及解决方法
onnxruntime调用gpu报错:
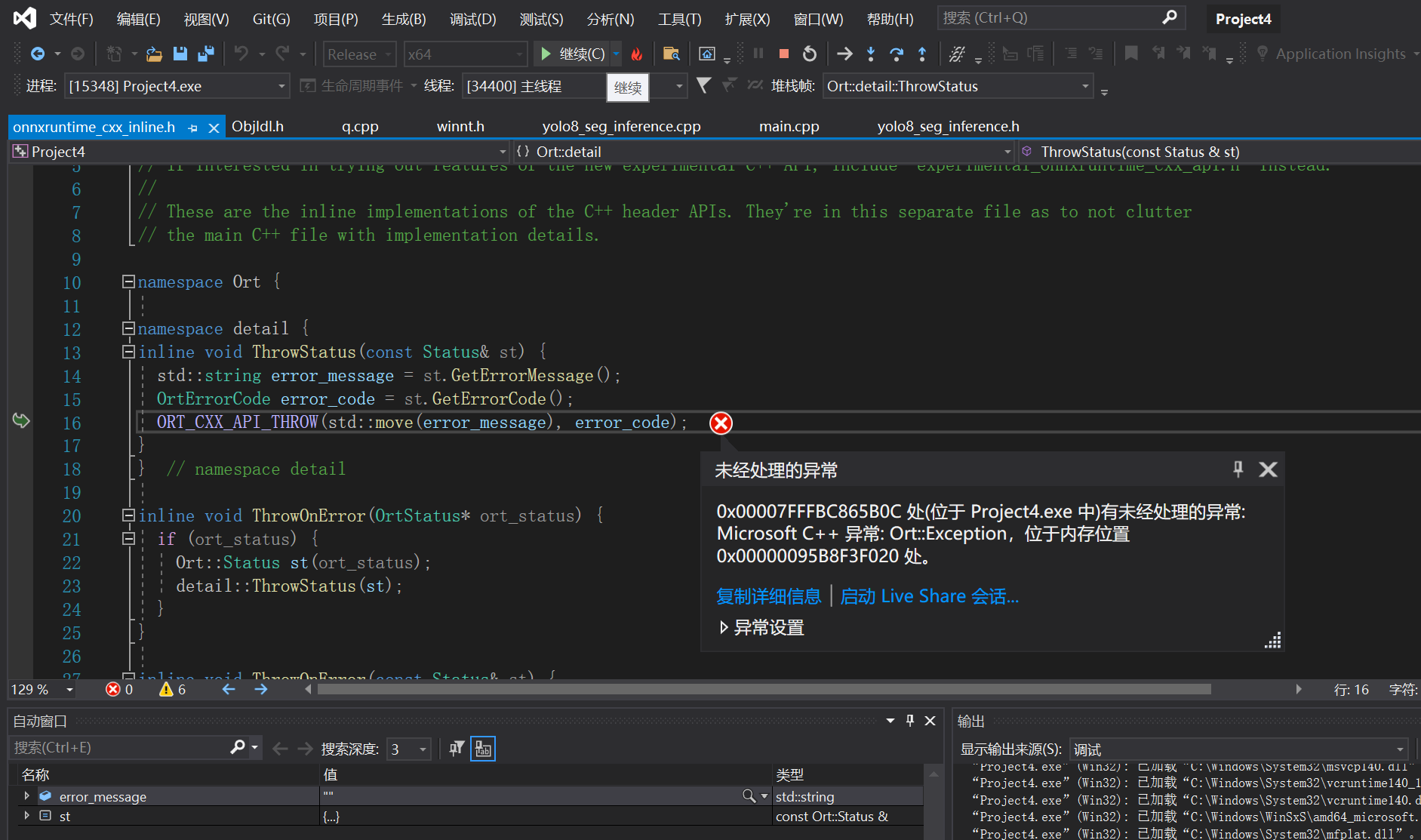
可能是Onnxruntime结果不匹配的问题:
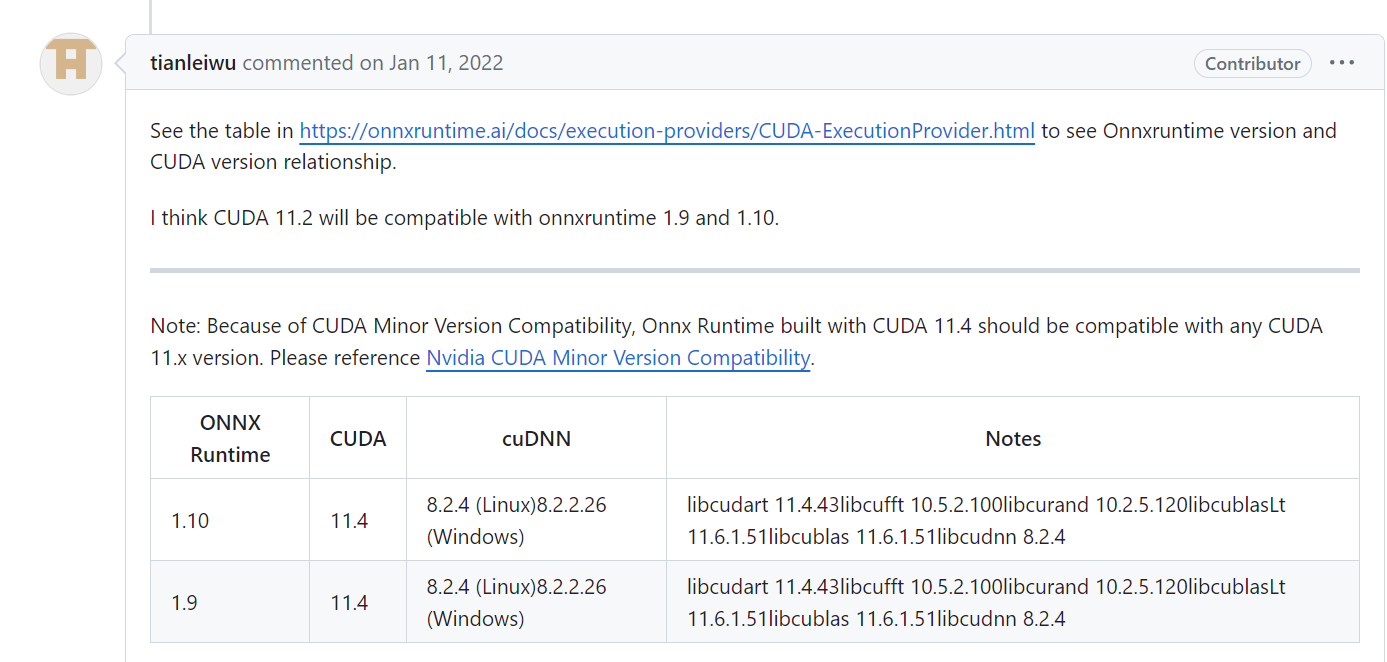
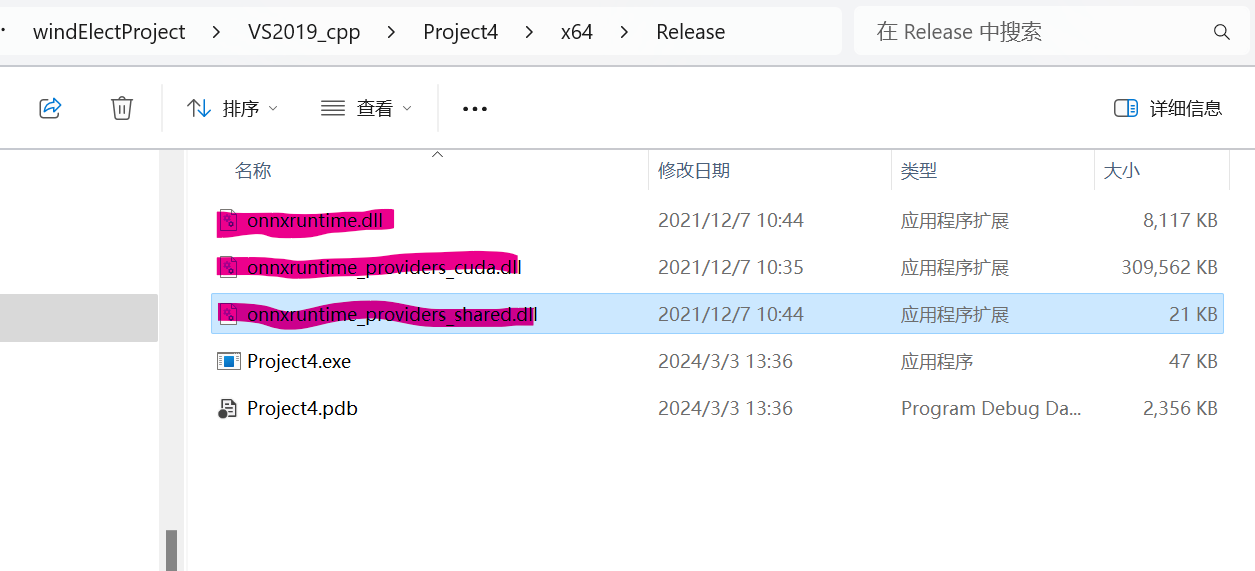
这里要去核查一下,我换成匹配版本后,还是报内存错误!最后解决方法如下:
- 调用GPU的话onnxruntime的动态库其实需要onnxruntime.dll、 onnxruntime_providers_cuda.dll、onnxruntime_providers_shared.dll这3个,而且一定要放对位置,否则会出各种内存异常的问题
1.2:详细注释代码
yolo8_seg_inference.h
#pragma once
#include<opencv2/opencv.hpp>
//#include<opencv2/cudaimgproc.hpp>
//#include <opencv2/cudafilters.hpp>
#include<iostream>
#include<memory>
#include <chrono>
#include<onnxruntime_cxx_api.h>
#include<math.h>
using namespace Ort;
//用于保存分割结果实例
struct Result {
int id = 0;
float accu = 0.0;
cv::Rect bound;
cv::Mat mask;
};
class Inference
{
public:
//构造函数
Inference(const std::string& onnxModelPath, bool cuda);
//共有成员函数,用于执行分割
std::vector<Result> detect_seg_ort(const cv::Mat& input);
cv::Mat draw_result(cv::Mat img, std::vector<Result>& result, std::vector<cv::Scalar> color);
std::vector< std::string> class_names = { "line" };
bool cudaEnable = false;
int width = 640, height = 640;//图片的宽高
//指针检测的3个关键点
cv::Point line_point; //指针指向点
cv::Point center2; //表盘中心点
cv::Point zero;//存储img中模版图像中心点
//私有成员函数和成员变量,用于内部操作
private:
int seg_ch = 32;
int seg_w = 160, seg_h = 160;
int net_w = 640, net_h = 640;
float accu_thresh = 0.25, mask_thresh = 0.5;
std::string model_path;
//为onnxruntime的session创建时所配置的
int LogSeverityLevel = 3;
int IntraOpNumThreads = 1;
struct ImageInfo {
cv::Size raw_size;
cv::Vec4d trans;
};
void decode_output(cv::Mat& output0, cv::Mat& output1, ImageInfo para, std::vector<Result>& results);
void get_mask(const cv::Mat& mask_info, const cv::Mat& mask_data, const ImageInfo& para, cv::Rect bound, cv::Mat& mast_out);
std::unique_ptr<Env> env; // ONNX Runtime环境
std::unique_ptr<Session> session; // ONNX Runtime会话
//用于存储ONNX模型的输入和输出节点的名称,这对于在ONNX Runtime中运行模型推理是必要的。
std::vector<const char*> input_names = { "images" };
std::vector<const char*> output_names = { "output0","output1" };
};
yolo8_seg_inference.cpp
#include<opencv2/opencv.hpp>
//#include<opencv2/cudaimgproc.hpp>
//#include <opencv2/cudafilters.hpp>
#include<iostream>
#include<memory>
#include <chrono>
#include<onnxruntime_cxx_api.h>
#include<math.h>
#include"yolo8_seg_inference.h"
using namespace cv::dnn;
using namespace Ort;
using namespace std;
using namespace cv;
Inference::Inference(const std::string& onnxModelPath, bool cuda) {
//使用make_unique创建智能指针
env = std::make_unique<Env>(OrtLoggingLevel::ORT_LOGGING_LEVEL_ERROR, "yolov8");
SessionOptions sessionOption;
if (cuda) {
OrtCUDAProviderOptions cudaOption;
cudaOption.device_id = 0;
sessionOption.AppendExecutionProvider_CUDA(cudaOption);
}
sessionOption.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
sessionOption.SetIntraOpNumThreads(IntraOpNumThreads);
sessionOption.SetLogSeverityLevel(LogSeverityLevel);
session = std::make_unique <Session>(*env, std::wstring(onnxModelPath.begin(), onnxModelPath.end()).c_str(), sessionOption);
}
void Inference::draw_result(Mat img, vector<Result>& result, vector<Scalar> color)
{
Mat mask = img.clone();
for (int i = 0; i < result.size(); i++)
{
int left, top;
left = result[i].bound.x;
top = result[i].bound.y;
int color_num = i;
rectangle(img, result[i].bound, color[result[i].id], 8);
if (result[i].mask.rows && result[i].mask.cols > 0)
{
mask(result[i].bound).setTo(color[result[i].id], result[i].mask);
}
string label =format("{}:{:.2f}", class_names[result[i].id], result[i].accu);
putText(img, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 2, color[result[i].id], 4);
}
addWeighted(img, 0.6, mask, 0.4, 0, img); //add mask to src
resize(img, img, Size(640, 640));
imshow("img", img);
waitKey();
}
void Inference::get_mask(const Mat& mask_info, const Mat& mask_data, const ImageInfo& para, Rect bound, Mat& mast_out)
{
//获取图像到网络尺寸的转换参数
Vec4f trans = para.trans;
//将边界框的坐标,从原始图像尺寸,转换到分割掩码的尺寸
int r_x = floor((bound.x * trans[0] + trans[2]) / net_w * seg_w);
int r_y = floor((bound.y * trans[1] + trans[3]) / net_h * seg_h);
//计算分割掩码的宽度和高度
int r_w = ceil(((bound.x + bound.width) * trans[0] + trans[2]) / net_w * seg_w) - r_x;
int r_h = ceil(((bound.y + bound.height) * trans[1] + trans[3]) / net_h * seg_h) - r_y;
//确保掩码的宽度和高度至少为1
r_w = MAX(r_w, 1);
r_h = MAX(r_h, 1);
//如果掩码超出了分割掩码尺寸的边界,则进行剪裁
if (r_x + r_w > seg_w) //crop
{
seg_w - r_x > 0 ? r_w = seg_w - r_x : r_x -= 1;
}
if (r_y + r_h > seg_h)
{
seg_h - r_y > 0 ? r_h = seg_h - r_y : r_y -= 1;
}
vector<Range> roi_rangs = { Range(0, 1) ,Range::all() , Range(r_y, r_h + r_y) ,Range(r_x, r_w + r_x) };
Mat temp_mask = mask_data(roi_rangs).clone();
Mat protos = temp_mask.reshape(0, { seg_ch,r_w * r_h });
Mat matmul_res = (mask_info * protos).t();
Mat masks_feature = matmul_res.reshape(1, { r_h,r_w });
Mat dest;
exp(-masks_feature, dest);//sigmoid
dest = 1.0 / (1.0 + dest);
int left = floor((net_w / seg_w * r_x - trans[2]) / trans[0]);
int top = floor((net_h / seg_h * r_y - trans[3]) / trans[1]);
int width = ceil(net_w / seg_w * r_w / trans[0]);
int height = ceil(net_h / seg_h * r_h / trans[1]);
Mat mask;
cv::resize(dest, mask, Size(width, height));
mast_out = mask(bound - Point(left, top)) > mask_thresh;
}
void Inference::decode_output(Mat& output0, Mat& output1, ImageInfo para, vector<Result>& results) {
//清空结果向量,准备存储新的检测结果
results.clear();
//定义几个向量来存储检测结果的不同部分
vector<int> class_ids;// 类别ID
vector<float> accus;// 置信度
vector<Rect> boxes;// 存储边界框
vector<vector<float>> masks;// 分割掩码
//计算每行数据的宽度,包括:类别数、边界框、分割掩码的32个值
int data_width = class_names.size() + 4 + 32;
//获取output0的行数,每行代表一个检测对象
int rows = output0.rows;
//获取指向output0数据的指针
float* pdata = (float*)output0.data;
//遍历每行数据,解析检测到的对象
for (int r = 0; r < rows; ++r)
{
//获取当前的得分,并找到最高分的类别
Mat scores(1, class_names.size(), CV_32FC1, pdata + 4);
Point class_id;
double max_socre;
minMaxLoc(scores, 0, &max_socre, 0, &class_id);
//如果最高分大于等于阈值,则认为检测有效
if (max_socre >= accu_thresh)
{
//存储分割掩码数据
masks.push_back(vector<float>(pdata + 4 + class_names.size(), pdata + data_width));
//计算边界框的宽度和高度
float w = pdata[2] / para.trans[0];
float h = pdata[3] / para.trans[1];
//计算边界框的左上角坐标
int left = MAX(int((pdata[0] - para.trans[2]) / para.trans[0] - 0.5 * w + 0.5), 0);
int top = MAX(int((pdata[1] - para.trans[3]) / para.trans[1] - 0.5 * h + 0.5), 0);
//存储类别ID、置信度、和边界框
class_ids.push_back(class_id.x);
accus.push_back(max_socre);
boxes.push_back(Rect(left, top, int(w + 0.5), int(h + 0.5)));
}
//指针移动到下一行数据
pdata += data_width;//next line
}
//使用非极大值抑制来过滤掉重复边界框
vector<int> nms_result;
NMSBoxes(boxes, accus, accu_thresh, mask_thresh, nms_result);
//遍历非极大值抑制的结果
for (int i = 0; i < nms_result.size(); ++i)
{
int idx = nms_result[i];
//保证边界框不超出原始图像的大小
boxes[idx] = boxes[idx] & Rect(0, 0, para.raw_size.width, para.raw_size.height);
//创建一个Result对象
Result result = { class_ids[idx] ,accus[idx] ,boxes[idx] };
//获取分割掩码并添加到result对象
get_mask(Mat(masks[idx]).t(), output1, para, boxes[idx], result.mask);
results.push_back(result);
}
}
std::vector<Result> Inference::detect_seg_ort(const cv::Mat& input) {
//创建一个image用于存储跳转大小后的图像
Mat image;
//将图像调整为640*640的大小
resize(input, image, Size(640, 640));
//定义输入张量的形状
std::vector<int64_t> input_shape = { 1, 3, 640, 640 };
//将图像数据转换成一个张量,这个过程称为blob化,同时进行归一化处理
Mat blob = blobFromImage(image, 1 / 255.0, Size(640, 640), Scalar(0, 0, 0), true, false);
//创建一个输入张量
Value input_tensor = Value::CreateTensor<float>(MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault),
(float*)blob.data, 3 * 640 * 640, input_shape.data(), input_shape.size());
//记录推理开始时间
auto start = std::chrono::high_resolution_clock::now();
//运行模型进行推理,获取输出
auto outputs = session->Run(RunOptions{ nullptr },
input_names.data(), &input_tensor, 1, output_names.data(), output_names.size());
//记录推理结束时间
auto end = std::chrono::high_resolution_clock::now();
//计算并输出推理结束时间
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << "ort time: " << duration << " millis.";
//获取第一个输出张量的数据和形状
float* all_data = outputs[0].GetTensorMutableData<float>();
auto data_shape = outputs[0].GetTensorTypeAndShapeInfo().GetShape();
//创建一个Mat对象来存储第一个输出张量的数据,并转置
Mat output0 = Mat(Size((int)data_shape[2], (int)data_shape[1]), CV_32F, all_data).t();
//获取分割掩码输出张量的形状
auto mask_shape = outputs[1].GetTensorTypeAndShapeInfo().GetShape();
std::vector<int> mask_sz = { 1,(int)mask_shape[1],(int)mask_shape[2],(int)mask_shape[3] };
//创建一个Mat对象来存储分割掩码的数据
Mat output1 = Mat(mask_sz, CV_32F, outputs[1].GetTensorMutableData<float>());
//创建一个结构体来存储图像信息,包括原始大小和缩放因子
ImageInfo img_info = { input.size(), { 640.0 / input.cols ,640.0 / input.rows,0,0 } };
//创建一个向量来存储结果
std::vector<Result> results;
//调用decode_output函数来处理输出数据,并填充结果向量
decode_output(output0, output1, img_info, results);
//返回结果
return results;
}
main.cpp
#include<opencv2/opencv.hpp>
//#include<opencv2/cudaimgproc.hpp>
//#include <opencv2/cudafilters.hpp>
#include<iostream>
#include<memory>
#include <chrono>
#include<onnxruntime_cxx_api.h>
#include<math.h>
#include"yolo8_seg_inference.h"
//#include "yolov8_ort.h"
using namespace cv::dnn;
using namespace Ort;
using namespace std;
using namespace cv;
int main(int argc, char* argv[])
{
srand(time(0));
vector<Scalar> color;
string model_path = "D:/CollegeStudy/AI/windElectProject/VS2019_cpp/models/pump_best.onnx";
Inference inf(model_path,true);
for (int i = 0; i < inf.class_names.size(); i++)
{
color.push_back(Scalar(rand() % 128 + 128, rand() % 128 + 128, rand() % 128 + 128));
}
Mat img1 = imread("D:/CollegeStudy/AI/windElectProject/VS2019_cpp/data/pump/pump.jpg");
Mat img2 = img1.clone();
vector<Result> result= inf.detect_seg_ort(img2);
if (result.size()>0)
{
inf.draw_result(img2, result, color);
}
return 0;
}
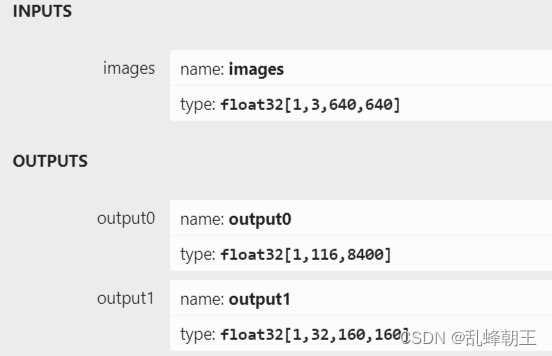
二、yolov8-seg模型输出介绍
YOLOv8-seg模型一共有两个输出:
第一个输出:“output0”;type:float32[1,116,8400]。其中116的前84个列与 YOLOv8目标检测模型输出定义一样,即cx,cy,w,h这4项再加80个类别的分数;后32列用于计算掩膜数据。
第二个输出:“output1”;type:float32[1,32,160,160]。output0后32个字段与output1的数据做矩阵乘法后得到的结果,即为对应目标的掩膜数据。
第二个输出:“output1”;type:float32[1,32,160,160]。output0后32个字段与output1的数据做矩阵乘法后得到的结果,即为对应目标的掩膜数据。
掩码(Mask)通常是一个与图像大小相同的矩阵,每个元素的值表示对应像素是否属于某个目标。在二值掩码中,值通常是0或1,表示像素不属于或属于目标。在实例分割中,每个检测到的对象都有一个唯一的掩码来区分它与其他对象或背景。
在我们的代码中
- 第一个输出
output0: 这个输出包含每个检测到的对象的位置(cx, cy, w, h),以及相应的类别得分(80个or多少个类别)。此外,每个对象还附带了32个额外字段,这些字段不代表直接可用的掩码,而是用于进一步计算每个对象的分割掩码的特征向量。 - 第二个输出
output1: 这个输出包含了一个32通道的160x160的特征图,这个特征图是用来生成具体对象的分割掩码的基础数据。
output0 中的后32个字段与 output1 的32通道特征图之间的联系是这样的:output0 中为每个检测到的对象提供了一个32维的特征向量,这个向量与 output1 中的32通道特征图进行矩阵乘法操作,以生成该对象的分割掩码。
在给定的 get_mask 函数中,这个操作的具体步骤包括:
- 从 output0 中提取32个额外字段,这些字段是一个特征向量,表示与检测到的对象相关的分割信息。
- 从 output1 中取出与对象位置相对应的特征图部分,这部分特征图是一个32通道的特征区域。
- 执行这两个向量(output0 的特征向量和 output1 的特征图区域)之间的矩阵乘法操作。这一操作将特征向量的信息投射到特征图上,生成了一个单通道的响应图,即对象的原始分割掩码。
- 该响应图通过sigmoid函数转换成了一个二值掩码,其中高响应值表示对象的一部分,低响应值表示背景或其他对象。
三、结果展示
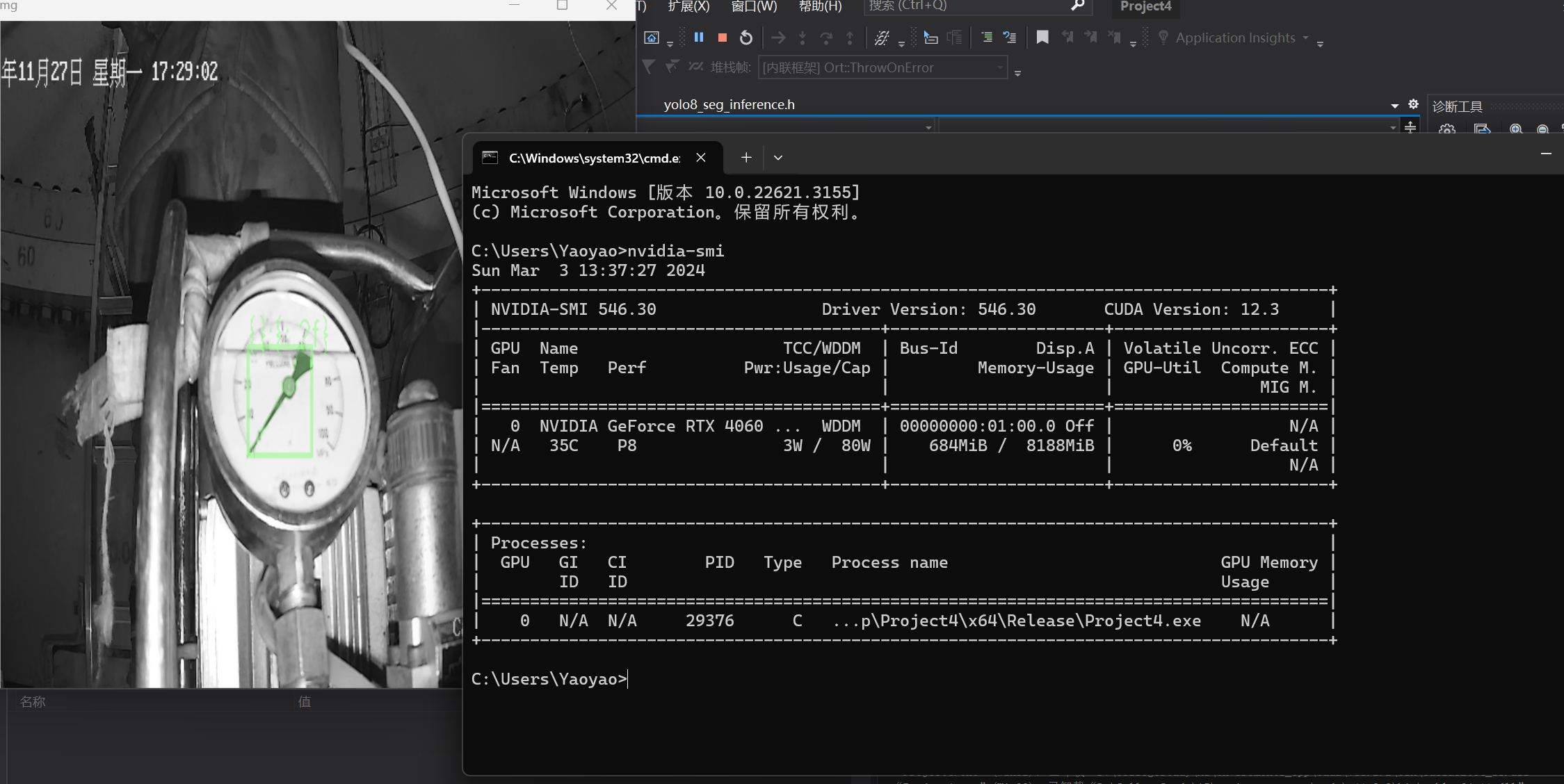
















 1752
1752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











