






文章目录
深度学习Week10——利用TensorFlow实现猴痘病识别
一、前言
二、我的环境
三、前期工作
1、配置环境
2、导入数据
四、数据预处理
1、加载数据
2、可视化数据
3、检查数据
4、配置数据集
五、构建CNN模型
五、编译模型
六、训练模型
七、预测与评估
1、Accuracy图
八、总结
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
学习深度学习的第九周,重新学习的第三周
二、我的环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.0
- 编译器:Pycharm2023.2.3
深度学习环境:TensorFlow
显卡及显存:RTX 3060 8G
三、前期工作
1、导入库并配置环境
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
这一步与pytorch第一步类似,我们在写神经网络程序前无论是选择pytorch还是tensorflow都应该配置好gpu环境(如果有gpu的话)
2、 导入数据
导入猴痘病与其他数据,依次分别为训练集图片(train_images)、训练集标签(train_labels)、测试集图片(test_images)、测试集标签(test_labels),数据集来源于K同学啊的网盘:数据集
data_dir = "E:\Deep_Learning\Data\Week4"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count)
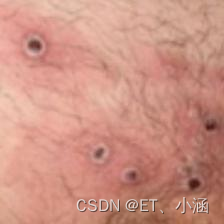
#查看第一张图片:
roses = list(data_dir.glob('sunrise/*.jpg'))
PIL.Image.open(str(roses[0]))
图片总数为: 2142
四、数据预处理
1、加载数据
batch_size = 32
img_height = 224
img_width = 224
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
tf.keras.preprocessing.image_dataset_from_directory()会将文件夹中的数据加载到tf.data.Dataset中,且加载的同时会打乱数据。
- class_names
- validation_split: 0和1之间的可选浮点数,可保留一部分数据用于验证。
- subset: training或validation之一。仅在设置validation_split时使用。
- seed: 用于shuffle和转换的可选随机种子。
- batch_size: 数据批次的大小。默认值:32
- image_size: 从磁盘读取数据后将其重新调整大小。默认:(256,256)。由于管道处理的图像批次必须具有相同的大小,因此该参数必须提供。
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:
https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split = 0.2,
subset = "training",
seed = 123,
image_size = (img_height, img_width),
batch_size = batch_size)
输出:
Found 2142 files belonging to 2 classes.
Using 1714 files for training.
这表示在 data_dir 目录中,有2142个图像文件,并且这些文件被组织成了2个类别:猴痘病与其他。
因为设置 validation_split = 0.2,将数据集按照8:2的比例分成了训练集和验证集,其中80%的数据被用作训练数据,而剩余的20%被用作验证数据。所以,2142个文件中的80%(即个1714文件)被用作训练数据。
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split = 0.2,
subset = "validation",
seed = 123,
image_size = (img_height, img_width),
batch_size = batch_size)
输出:
Found 2142 files belonging to 2 classes.
Using 428 files for validation.
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
[‘Monkeypox’, ‘Others’]
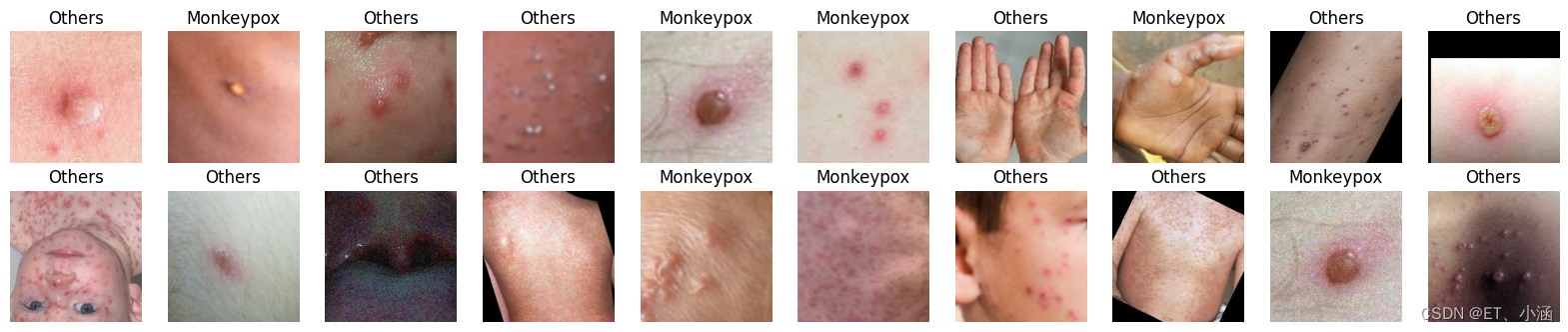
2、数据可视化
# 查看前20个图片
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
3、再次检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 224, 224, 3)
(32,)
Image_batch是形状的张量(32,224,224,3)。这是一批形状224x224x3的32张图片(最后一维指的是彩色通道RGB。
Label_batch是形状(32,)的张量,这些标签对应32张图片
4、配置数据集
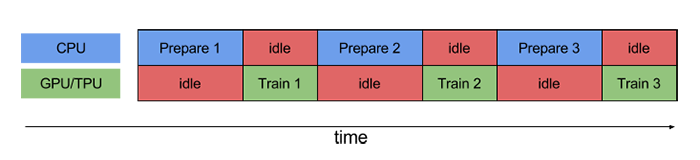
shuffle():打乱数据prefetch():预取数据,加速运行- cache():将数据集缓存到内存当中,加速运行
如果不使用prefetch(),CPU 和 GPU/TPU 在大部分时间都处于空闲状态:
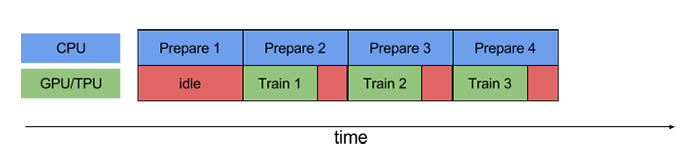
使用prefetch()可显著减少空闲时间:
五 、构建CNN模型
卷积神经网络(CNN)的输入是张量 (Tensor) 形式的
(image_height, image_width, color_channels),包含了图像高度、宽度及颜色信息。不需要输入batch size。color_channels 为 (R,G,B) 分别对应 RGB 的三个颜色通道(color channel)。在此示例中,我们的 CNN 输入形状是(224, 224, 3)。我们需要在声明第一层时将形状赋值给参数input_shape
这是一个重难点,在构建模型之前,我们先来看一看各层有什么作用以及网络结构图
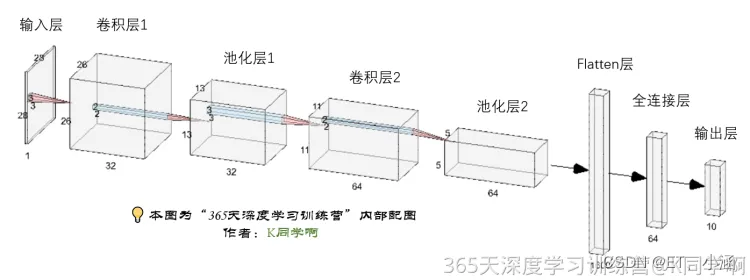
- 输入层:
输入层负责接收原始数据,将数据传递到网络中的第一层。 - 卷积层:
卷积层使用卷积核对输入数据进行滤波操作,以提取图像中的特征。 - 池化层:
池化层用于对卷积层的输出进行下采样,以减少数据的维度和计算量。 - Flatten层:
Flatten层用于将多维的输入数据(如卷积层的输出)压缩成一维的向量。
常用在卷积层到全连接层的过渡,将卷积层输出的特征图展平成一维向量,以便输入到全连接层中进行分类或回归等任务。 - 全连接层:
全连接层起到“特征提取器”的作用,将前面层的特征表示映射到输出层。 - 输出层:
输出层负责输出模型的预测结果。
ReLu函数作为激活励函数可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层;
相比其它函数来说,ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。
num_classes = 2
"""
关于卷积核的计算不懂的可以参考文章:https://blog.csdn.net/qq_38251616/article/details/114278995
layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/115826689
"""
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Dropout(0.3),
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.4),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(num_classes) # 输出层,输出预期结果
])
model.summary() # 打印网络结构
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 224, 224, 3) 0
conv2d (Conv2D) (None, 222, 222, 16) 448
average_pooling2d (Average (None, 111, 111, 16) 0
Pooling2D)
conv2d_1 (Conv2D) (None, 109, 109, 32) 4640
average_pooling2d_1 (Avera (None, 54, 54, 32) 0
gePooling2D)
dropout (Dropout) (None, 54, 54, 32) 0
conv2d_2 (Conv2D) (None, 52, 52, 64) 18496
dropout_1 (Dropout) (None, 52, 52, 64) 0
flatten (Flatten) (None, 173056) 0
dense (Dense) (None, 128) 22151296
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 22175138 (84.59 MB)
Trainable params: 22175138 (84.59 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
五、编译模型
具体函数解释参考第八周博客或者K同学啊的博客!
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate = 0.001)
model.compile(optimizer = opt,
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits = True),
metrics = ['accuracy'])
六、训练模型
# 设置输入训练数据集(图片及标签)、验证数据集(图片及标签)以及迭代次数epochs(10个)
from tensorflow.keras.callbacks import ModelCheckpoint
epochs = 50
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer])
Epoch 1/50
54/54 [==============================] - ETA: 0s - loss: 0.7548 - accuracy: 0.5368
Epoch 1: val_accuracy improved from -inf to 0.53972, saving model to best_model.h5
54/54 [==============================] - 41s 728ms/step - loss: 0.7548 - accuracy: 0.5368 - val_loss: 0.6750 - val_accuracy: 0.5397
Epoch 2/50
54/54 [==============================] - ETA: 0s - loss: 0.6599 - accuracy: 0.6126
Epoch 2: val_accuracy improved from 0.53972 to 0.62383, saving model to best_model.h5
54/54 [==============================] - 38s 710ms/step - loss: 0.6599 - accuracy: 0.6126 - val_loss: 0.6519 - val_accuracy: 0.6238
Epoch 3/50
54/54 [==============================] - ETA: 0s - loss: 0.6331 - accuracy: 0.6464
Epoch 3: val_accuracy did not improve from 0.62383
54/54 [==============================] - 37s 691ms/step - loss: 0.6331 - accuracy: 0.6464 - val_loss: 0.6993 - val_accuracy: 0.5981
Epoch 4/50
54/54 [==============================] - ETA: 0s - loss: 0.5924 - accuracy: 0.6826
Epoch 4: val_accuracy improved from 0.62383 to 0.68925, saving model to best_model.h5
54/54 [==============================] - 38s 697ms/step - loss: 0.5924 - accuracy: 0.6826 - val_loss: 0.5898 - val_accuracy: 0.6893
Epoch 5/50
54/54 [==============================] - ETA: 0s - loss: 0.5645 - accuracy: 0.7112
Epoch 5: val_accuracy did not improve from 0.68925
54/54 [==============================] - 37s 688ms/step - loss: 0.5645 - accuracy: 0.7112 - val_loss: 0.6221 - val_accuracy: 0.6869
Epoch 6/50
54/54 [==============================] - ETA: 0s - loss: 0.5340 - accuracy: 0.7351
Epoch 6: val_accuracy improved from 0.68925 to 0.73131, saving model to best_model.h5
54/54 [==============================] - 38s 706ms/step - loss: 0.5340 - accuracy: 0.7351 - val_loss: 0.5262 - val_accuracy: 0.7313
Epoch 7/50
54/54 [==============================] - ETA: 0s - loss: 0.4988 - accuracy: 0.7625
Epoch 7: val_accuracy did not improve from 0.73131
54/54 [==============================] - 38s 714ms/step - loss: 0.4988 - accuracy: 0.7625 - val_loss: 0.5699 - val_accuracy: 0.6986
Epoch 8/50
54/54 [==============================] - ETA: 0s - loss: 0.4743 - accuracy: 0.7730
Epoch 8: val_accuracy improved from 0.73131 to 0.74766, saving model to best_model.h5
54/54 [==============================] - 37s 692ms/step - loss: 0.4743 - accuracy: 0.7730 - val_loss: 0.4822 - val_accuracy: 0.7477
Epoch 9/50
54/54 [==============================] - ETA: 0s - loss: 0.4525 - accuracy: 0.7923
Epoch 9: val_accuracy improved from 0.74766 to 0.79206, saving model to best_model.h5
54/54 [==============================] - 37s 687ms/step - loss: 0.4525 - accuracy: 0.7923 - val_loss: 0.4429 - val_accuracy: 0.7921
Epoch 10/50
54/54 [==============================] - ETA: 0s - loss: 0.4241 - accuracy: 0.8168
Epoch 10: val_accuracy did not improve from 0.79206
54/54 [==============================] - 38s 699ms/step - loss: 0.4241 - accuracy: 0.8168 - val_loss: 0.4530 - val_accuracy: 0.7874
Epoch 11/50
54/54 [==============================] - ETA: 0s - loss: 0.3941 - accuracy: 0.8355
Epoch 11: val_accuracy did not improve from 0.79206
54/54 [==============================] - 38s 706ms/step - loss: 0.3941 - accuracy: 0.8355 - val_loss: 0.4621 - val_accuracy: 0.7804
Epoch 12/50
54/54 [==============================] - ETA: 0s - loss: 0.3520 - accuracy: 0.8541
Epoch 12: val_accuracy improved from 0.79206 to 0.79439, saving model to best_model.h5
54/54 [==============================] - 39s 718ms/step - loss: 0.3520 - accuracy: 0.8541 - val_loss: 0.4222 - val_accuracy: 0.7944
Epoch 13/50
54/54 [==============================] - ETA: 0s - loss: 0.3355 - accuracy: 0.8594
Epoch 13: val_accuracy improved from 0.79439 to 0.83879, saving model to best_model.h5
54/54 [==============================] - 45s 828ms/step - loss: 0.3355 - accuracy: 0.8594 - val_loss: 0.4036 - val_accuracy: 0.8388
Epoch 14/50
54/54 [==============================] - ETA: 0s - loss: 0.3159 - accuracy: 0.8699
Epoch 14: val_accuracy did not improve from 0.83879
54/54 [==============================] - 38s 697ms/step - loss: 0.3159 - accuracy: 0.8699 - val_loss: 0.4134 - val_accuracy: 0.8131
Epoch 15/50
54/54 [==============================] - ETA: 0s - loss: 0.2853 - accuracy: 0.8856
Epoch 15: val_accuracy did not improve from 0.83879
54/54 [==============================] - 39s 722ms/step - loss: 0.2853 - accuracy: 0.8856 - val_loss: 0.4902 - val_accuracy: 0.7944
Epoch 16/50
54/54 [==============================] - ETA: 0s - loss: 0.2680 - accuracy: 0.8921
Epoch 16: val_accuracy did not improve from 0.83879
54/54 [==============================] - 37s 685ms/step - loss: 0.2680 - accuracy: 0.8921 - val_loss: 0.3883 - val_accuracy: 0.8224
Epoch 17/50
54/54 [==============================] - ETA: 0s - loss: 0.2530 - accuracy: 0.9020
Epoch 17: val_accuracy improved from 0.83879 to 0.85748, saving model to best_model.h5
54/54 [==============================] - 39s 730ms/step - loss: 0.2530 - accuracy: 0.9020 - val_loss: 0.3817 - val_accuracy: 0.8575
Epoch 18/50
54/54 [==============================] - ETA: 0s - loss: 0.2263 - accuracy: 0.9113
Epoch 18: val_accuracy did not improve from 0.85748
54/54 [==============================] - 39s 729ms/step - loss: 0.2263 - accuracy: 0.9113 - val_loss: 0.3805 - val_accuracy: 0.8435
Epoch 19/50
54/54 [==============================] - ETA: 0s - loss: 0.2455 - accuracy: 0.8991
Epoch 19: val_accuracy did not improve from 0.85748
54/54 [==============================] - 39s 718ms/step - loss: 0.2455 - accuracy: 0.8991 - val_loss: 0.4362 - val_accuracy: 0.8248
Epoch 20/50
54/54 [==============================] - ETA: 0s - loss: 0.2127 - accuracy: 0.9113
Epoch 20: val_accuracy did not improve from 0.85748
54/54 [==============================] - 38s 713ms/step - loss: 0.2127 - accuracy: 0.9113 - val_loss: 0.3948 - val_accuracy: 0.8551
Epoch 21/50
54/54 [==============================] - ETA: 0s - loss: 0.2036 - accuracy: 0.9189
Epoch 21: val_accuracy improved from 0.85748 to 0.86916, saving model to best_model.h5
54/54 [==============================] - 39s 727ms/step - loss: 0.2036 - accuracy: 0.9189 - val_loss: 0.4097 - val_accuracy: 0.8692
Epoch 22/50
54/54 [==============================] - ETA: 0s - loss: 0.1976 - accuracy: 0.9247
Epoch 22: val_accuracy did not improve from 0.86916
54/54 [==============================] - 38s 712ms/step - loss: 0.1976 - accuracy: 0.9247 - val_loss: 0.3882 - val_accuracy: 0.8668
Epoch 23/50
54/54 [==============================] - ETA: 0s - loss: 0.1804 - accuracy: 0.9370
Epoch 23: val_accuracy did not improve from 0.86916
54/54 [==============================] - 40s 734ms/step - loss: 0.1804 - accuracy: 0.9370 - val_loss: 0.3877 - val_accuracy: 0.8645
Epoch 24/50
54/54 [==============================] - ETA: 0s - loss: 0.1748 - accuracy: 0.9312
Epoch 24: val_accuracy did not improve from 0.86916
54/54 [==============================] - 44s 819ms/step - loss: 0.1748 - accuracy: 0.9312 - val_loss: 0.4003 - val_accuracy: 0.8551
Epoch 25/50
54/54 [==============================] - ETA: 0s - loss: 0.1531 - accuracy: 0.9446
Epoch 25: val_accuracy did not improve from 0.86916
54/54 [==============================] - 43s 795ms/step - loss: 0.1531 - accuracy: 0.9446 - val_loss: 0.4497 - val_accuracy: 0.8341
Epoch 26/50
54/54 [==============================] - ETA: 0s - loss: 0.1602 - accuracy: 0.9417
Epoch 26: val_accuracy did not improve from 0.86916
54/54 [==============================] - 40s 741ms/step - loss: 0.1602 - accuracy: 0.9417 - val_loss: 0.4121 - val_accuracy: 0.8692
Epoch 27/50
54/54 [==============================] - ETA: 0s - loss: 0.1310 - accuracy: 0.9586
Epoch 27: val_accuracy did not improve from 0.86916
54/54 [==============================] - 117s 2s/step - loss: 0.1310 - accuracy: 0.9586 - val_loss: 0.3973 - val_accuracy: 0.8645
Epoch 28/50
54/54 [==============================] - ETA: 0s - loss: 0.1171 - accuracy: 0.9656
Epoch 28: val_accuracy improved from 0.86916 to 0.88551, saving model to best_model.h5
54/54 [==============================] - 71s 1s/step - loss: 0.1171 - accuracy: 0.9656 - val_loss: 0.4002 - val_accuracy: 0.8855
Epoch 29/50
54/54 [==============================] - ETA: 0s - loss: 0.1239 - accuracy: 0.9592
Epoch 29: val_accuracy did not improve from 0.88551
54/54 [==============================] - 48s 888ms/step - loss: 0.1239 - accuracy: 0.9592 - val_loss: 0.4041 - val_accuracy: 0.8762
Epoch 30/50
54/54 [==============================] - ETA: 0s - loss: 0.1188 - accuracy: 0.9597
Epoch 30: val_accuracy did not improve from 0.88551
54/54 [==============================] - 45s 844ms/step - loss: 0.1188 - accuracy: 0.9597 - val_loss: 0.4186 - val_accuracy: 0.8598
Epoch 31/50
54/54 [==============================] - ETA: 0s - loss: 0.1179 - accuracy: 0.9627
Epoch 31: val_accuracy did not improve from 0.88551
54/54 [==============================] - 49s 913ms/step - loss: 0.1179 - accuracy: 0.9627 - val_loss: 0.4767 - val_accuracy: 0.8808
Epoch 32/50
54/54 [==============================] - ETA: 0s - loss: 0.0950 - accuracy: 0.9697
Epoch 32: val_accuracy did not improve from 0.88551
54/54 [==============================] - 43s 796ms/step - loss: 0.0950 - accuracy: 0.9697 - val_loss: 0.4413 - val_accuracy: 0.8785
Epoch 33/50
54/54 [==============================] - ETA: 0s - loss: 0.1027 - accuracy: 0.9708
Epoch 33: val_accuracy did not improve from 0.88551
54/54 [==============================] - 40s 748ms/step - loss: 0.1027 - accuracy: 0.9708 - val_loss: 0.4702 - val_accuracy: 0.8738
Epoch 34/50
54/54 [==============================] - ETA: 0s - loss: 0.0927 - accuracy: 0.9708
Epoch 34: val_accuracy did not improve from 0.88551
54/54 [==============================] - 36s 666ms/step - loss: 0.0927 - accuracy: 0.9708 - val_loss: 0.4335 - val_accuracy: 0.8668
Epoch 35/50
54/54 [==============================] - ETA: 0s - loss: 0.0791 - accuracy: 0.9767
Epoch 35: val_accuracy did not improve from 0.88551
54/54 [==============================] - 35s 654ms/step - loss: 0.0791 - accuracy: 0.9767 - val_loss: 0.4674 - val_accuracy: 0.8762
Epoch 36/50
54/54 [==============================] - ETA: 0s - loss: 0.0741 - accuracy: 0.9813
Epoch 36: val_accuracy did not improve from 0.88551
54/54 [==============================] - 37s 690ms/step - loss: 0.0741 - accuracy: 0.9813 - val_loss: 0.4544 - val_accuracy: 0.8762
Epoch 37/50
54/54 [==============================] - ETA: 0s - loss: 0.0774 - accuracy: 0.9778
Epoch 37: val_accuracy did not improve from 0.88551
54/54 [==============================] - 36s 666ms/step - loss: 0.0774 - accuracy: 0.9778 - val_loss: 0.4678 - val_accuracy: 0.8692
Epoch 38/50
54/54 [==============================] - ETA: 0s - loss: 0.0825 - accuracy: 0.9749
Epoch 38: val_accuracy did not improve from 0.88551
54/54 [==============================] - 36s 672ms/step - loss: 0.0825 - accuracy: 0.9749 - val_loss: 0.4570 - val_accuracy: 0.8621
Epoch 39/50
54/54 [==============================] - ETA: 0s - loss: 0.0602 - accuracy: 0.9854
Epoch 39: val_accuracy did not improve from 0.88551
54/54 [==============================] - 36s 660ms/step - loss: 0.0602 - accuracy: 0.9854 - val_loss: 0.4896 - val_accuracy: 0.8762
Epoch 40/50
54/54 [==============================] - ETA: 0s - loss: 0.0694 - accuracy: 0.9767
Epoch 40: val_accuracy did not improve from 0.88551
54/54 [==============================] - 37s 686ms/step - loss: 0.0694 - accuracy: 0.9767 - val_loss: 0.4774 - val_accuracy: 0.8598
Epoch 41/50
54/54 [==============================] - ETA: 0s - loss: 0.0633 - accuracy: 0.9813
Epoch 41: val_accuracy did not improve from 0.88551
54/54 [==============================] - 37s 684ms/step - loss: 0.0633 - accuracy: 0.9813 - val_loss: 0.4926 - val_accuracy: 0.8738
Epoch 42/50
54/54 [==============================] - ETA: 0s - loss: 0.0648 - accuracy: 0.9819
Epoch 42: val_accuracy did not improve from 0.88551
54/54 [==============================] - 40s 747ms/step - loss: 0.0648 - accuracy: 0.9819 - val_loss: 0.5151 - val_accuracy: 0.8715
Epoch 43/50
54/54 [==============================] - ETA: 0s - loss: 0.0562 - accuracy: 0.9866
Epoch 43: val_accuracy did not improve from 0.88551
54/54 [==============================] - 42s 772ms/step - loss: 0.0562 - accuracy: 0.9866 - val_loss: 0.4880 - val_accuracy: 0.8785
Epoch 44/50
54/54 [==============================] - ETA: 0s - loss: 0.0429 - accuracy: 0.9924
Epoch 44: val_accuracy did not improve from 0.88551
54/54 [==============================] - 40s 733ms/step - loss: 0.0429 - accuracy: 0.9924 - val_loss: 0.5103 - val_accuracy: 0.8762
Epoch 45/50
54/54 [==============================] - ETA: 0s - loss: 0.0625 - accuracy: 0.9802
Epoch 45: val_accuracy did not improve from 0.88551
54/54 [==============================] - 39s 726ms/step - loss: 0.0625 - accuracy: 0.9802 - val_loss: 0.5094 - val_accuracy: 0.8762
Epoch 46/50
54/54 [==============================] - ETA: 0s - loss: 0.0406 - accuracy: 0.9930
Epoch 46: val_accuracy did not improve from 0.88551
54/54 [==============================] - 45s 833ms/step - loss: 0.0406 - accuracy: 0.9930 - val_loss: 0.5123 - val_accuracy: 0.8808
Epoch 47/50
54/54 [==============================] - ETA: 0s - loss: 0.0365 - accuracy: 0.9918
Epoch 47: val_accuracy did not improve from 0.88551
54/54 [==============================] - 52s 967ms/step - loss: 0.0365 - accuracy: 0.9918 - val_loss: 0.5309 - val_accuracy: 0.8692
Epoch 48/50
54/54 [==============================] - ETA: 0s - loss: 0.0417 - accuracy: 0.9889
Epoch 48: val_accuracy did not improve from 0.88551
54/54 [==============================] - 44s 816ms/step - loss: 0.0417 - accuracy: 0.9889 - val_loss: 0.5105 - val_accuracy: 0.8808
Epoch 49/50
54/54 [==============================] - ETA: 0s - loss: 0.0395 - accuracy: 0.9895
Epoch 49: val_accuracy did not improve from 0.88551
54/54 [==============================] - 48s 903ms/step - loss: 0.0395 - accuracy: 0.9895 - val_loss: 0.5339 - val_accuracy: 0.8785
Epoch 50/50
54/54 [==============================] - ETA: 0s - loss: 0.0292 - accuracy: 0.9942
Epoch 50: val_accuracy did not improve from 0.88551
54/54 [==============================] - 41s 761ms/step - loss: 0.0292 - accuracy: 0.9942 - val_loss: 0.5552 - val_accuracy: 0.8738
七、预测
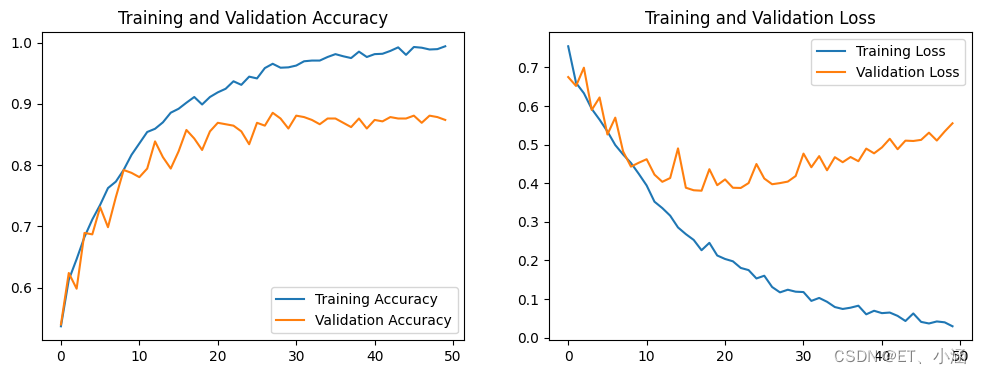
1、Accuracy图与Loss图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize = (12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label = 'Training Accuracy')
plt.plot(epochs_range, val_acc, label = 'Validation Accuracy')
plt.legend(loc = 'lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label = 'Training Loss')
plt.plot(epochs_range, val_loss, label = 'Validation Loss')
plt.legend(loc = 'upper right')
plt.title('Training and Validation Loss')
plt.show()
结果:
2、指定图片预测
model.load_weights('best_model.h5')
img = Image.open("E:\Deep_Learning\Data\Week4\Monkeypox\M01_01_08.jpg") #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])
img_array = tf.expand_dims(image, 0)
predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])
1/1 [==============================] - 0s 27ms/step
预测结果为: Monkeypox
八、总结
本周主要是被配置环境耽误了许久,由于自己python先前使用的一直都是3.11,tensorflow版本不匹配,导致keras一直报错,这周重新配置了3.8的python版本也是成功解决了问题,同时,这周的选题也比较简单,基本上对上周所学习到的内容的巩固!















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









