







Deep Hough Transform for Semantic Line Detection
主页:https://mmcheng.net/dhtline/
论文:http://mftp.mmcheng.net/Papers/21PAMI-DHT-line.pdf
代码:https://github.com/Hanqer/deep-hough-transform
南开大学计算媒体实验室在机器学习顶刊 IEEE TPAMI 发表论文提出”深度霍夫变换“ (deep hough transform, 简称 DHT),通过在深度特征上进行霍夫变换,从而兼顾CNN的特征学习能力和霍夫变换的高效性。该论文同时收集了一个包含室内/室外场景的大型语义线检测数据集 NKL (NanKai Lines)。NKL数据集有6,500张图像以及超过1万根语义线标注,为该领域目前最大的公开数据集。
该论文第一作者为原南开大学博士生,现腾讯优图实验室赵凯研究员;通讯作者为南开大学程明明教授。南开大学硕士研究生韩琦为文章共同第一作者。
语义线
检测图像中的直线(线段)是一个历史悠久的计算机视觉问题,图像中的线结构是一种有用的中间层表示(mid-level representation),在人类视觉中从底层到高层语义信息转换中有着重要作用 [1]。
自然图像中的“语义线”指的是图像中能够勾勒出图像内容结构的直线,例如不同区域的分割线,建筑物的中轴线等等。语义线检测在摄影构图[2, 3],图像处理[4]等下游任务中有着广泛应用。如图1所示,将图像中的语义线置于照片的黄金分割比位置能拍出视觉效果更好的图片 [2]。

图1:左图为原图,右图将语义线置于画面的黄金分割比位置,能得到视觉效果更好的照片[2]。
深度霍夫变换算法
霍夫变换[6]是一种经典的直线检测方法,它通过将任意直线转换到参数空间,从而将图像空间的线检测问题简化为参数空间的点检测问题。例如,平面上的任意直线都可以用 y = k x + b 来表示,因此任意一条直线都可以表示为参数空间中的一个点(k, b)。
传统的霍夫变换需要先用边缘检测算法(例如canny算子)对图像进行边缘检测,然后在边缘检测的结果之上进行霍夫变换,最后在变换空间通过寻找局部最大值来检测直线。
直线参数化
为了进行霍夫变换,首先要定义直线参数化的规则。
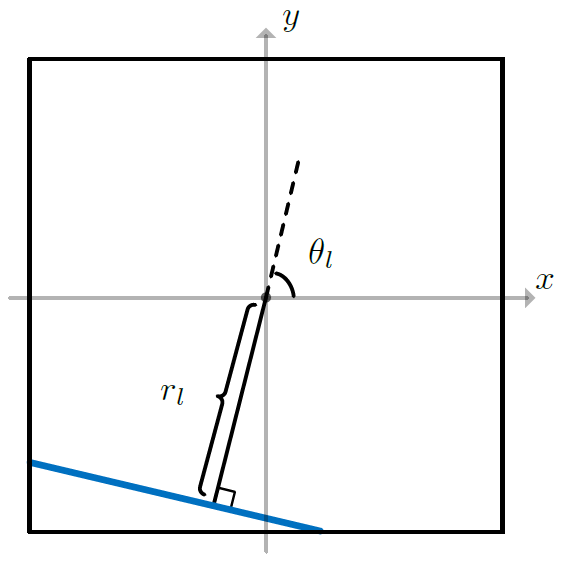
图2:直线的参数化
如上图所示,对任意一条直线,用其角度 theta 和直线到原点的距离 r 作为直线的参数,这样做的好处是可以参数化任意角度/位置的直线(用y = kx + b 无法参数化与 y 轴平行的直线)。
在深度特征上进行霍夫变换
如图3所示,对于一个输入图片,先通过CNN 特征提取器得到空间特征X,“深度霍夫变换”遍历图像中所有可能的直线并沿着直线将特征聚合到参数空间中对应的点上。在实现中,使用简单的求和操作实现特征聚合。
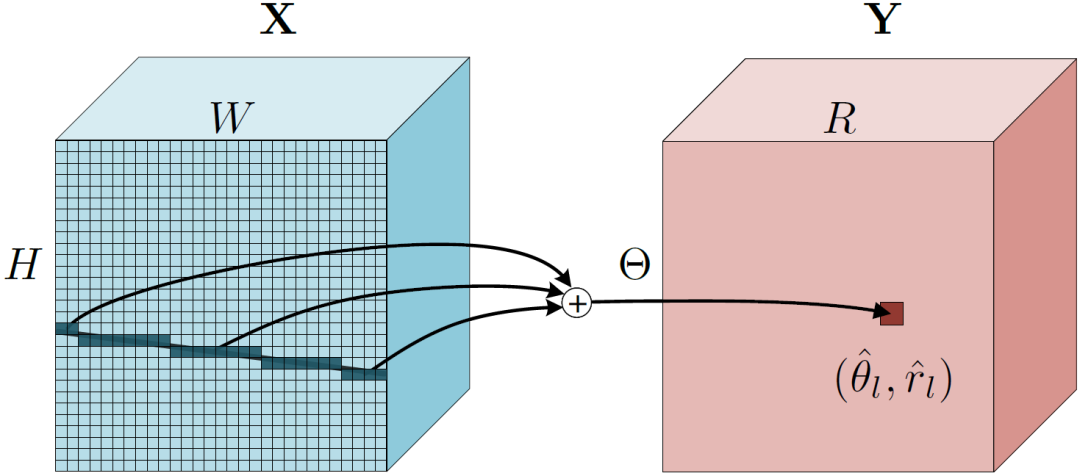 图3 左:深度霍夫变换沿着图像空间中的直线将特征”聚合“到参数空间中的一个点。
图3 左:深度霍夫变换沿着图像空间中的直线将特征”聚合“到参数空间中的一个点。
经过深度霍夫变换,原特征空间 X 上的一根直线对应参数空间 Y 上的一个点。在很多视觉任务中,特征的上下文(context)对于检测结果十分重要,深度霍夫变换将直线转化为点,因此提取相邻直线的上下文信息对应于在参数空间中提取相邻点的特征,大大简化和上下文信息提取的效率。
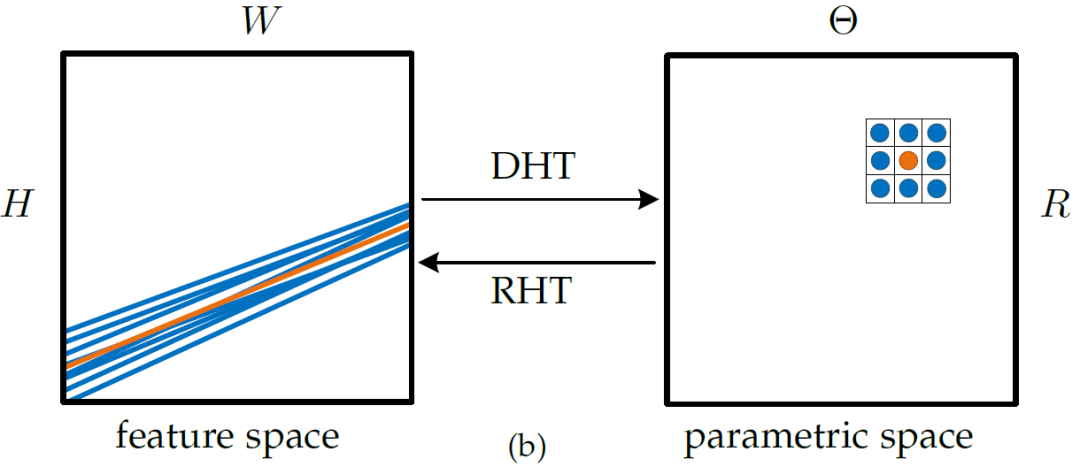 图4:图像空间中的线对应参数空间的一个点,一个简单的 3x3 卷积即可提取中心橙色线的上下文信息。
图4:图像空间中的线对应参数空间的一个点,一个简单的 3x3 卷积即可提取中心橙色线的上下文信息。
如图4所示,在原图像中提取橙色线的上下文信息需要复杂的索引操作;经过霍夫变换之后,只需要一个简单的 3x3 卷积即可提取中心线周围直线的特征。
总的来说,DHT 算法有如下几个优点:
高度可并行化,相比基于目标检测的SLNet方法加速了接近20 倍;
无需非极大值抑制;
高效的上下文直线信息提取;
实验结果
定量对比
论文主要在 SEL 和 NKL 数据集上进行试验,对比了 HED边缘检测 + 霍夫变换,SLNet 两种语义线检测方法。实验结果表明深度霍夫变换算法检测精度显著高于其他两种算法,同时大幅提高检测速度。
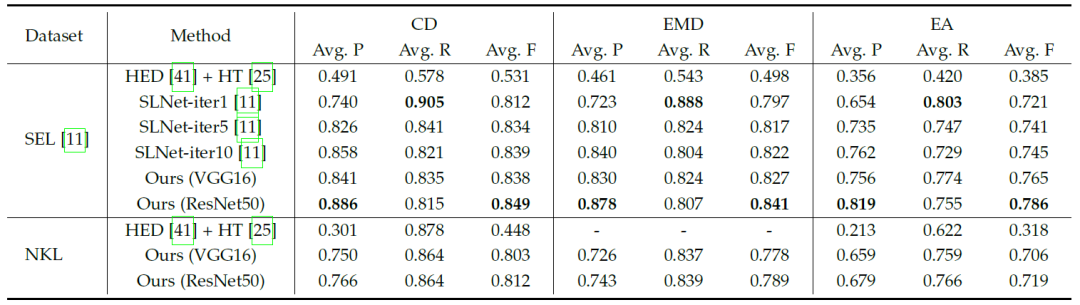 表1:不同方法在 SEL 和 NKL 数据集上的定量对比。
表1:不同方法在 SEL 和 NKL 数据集上的定量对比。
表1记录了不同方法在 SEL 和 NKL 数据集上的定量对比。CD,EMD 和 EA 分别指的是 Chamfer distance, earth-mover's distance 和 EA-score 三种评价直线之间相似度的度量。Avg P, R, F分别表示平均 precision,recall 和 F-measure。
可视化结果展示

上图是SEL数据集上不同方法检测结果的可视化对比,最后一行为 ground-truth。
推理耗时对比
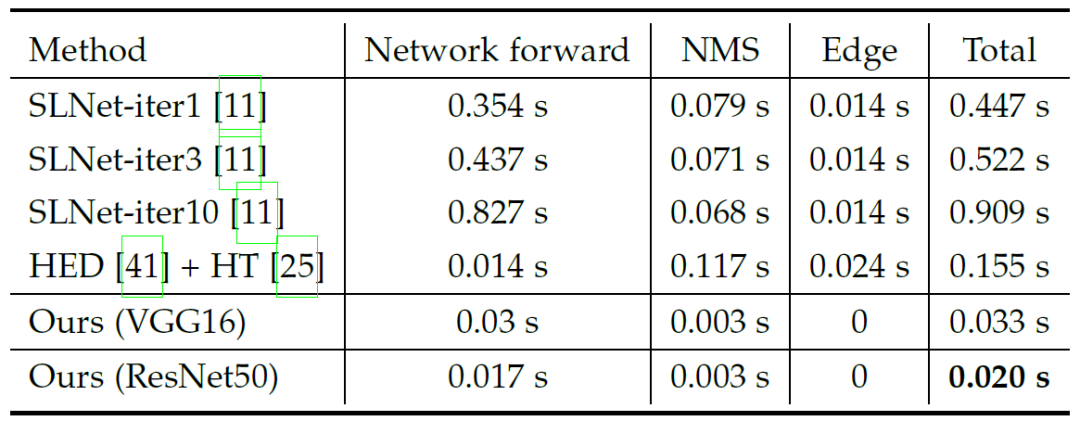
DHT算法不仅能取得更高的检测精度,同时也能极大地降低检测耗时。这主要归功于 DHT 算法的高度可并行化。
下表统计了不同方法在 Titan XP 显卡上的平均推理耗时,SLNet 最快需要0.447秒,HED+霍夫变换的方法需要0.155秒,而DHT 算法仅需0.020秒。
NKL:新的语义线检测数据集
在提出深度霍夫变换算法的同时,改论文还同时构建了新的语义线检测数据集 NKL (NanKai Lines)。NKL数据集包含6,500张样本,共有13,148根人工标注的语义线。相比当前最大的语义线检测数据集 SEL,NKL不论是在样本数,标注数目还是场景多样性上都要更丰富。读者可以访问 http://kaizhao.net/nkl 下载和了解 NKL 数据集相关的信息。
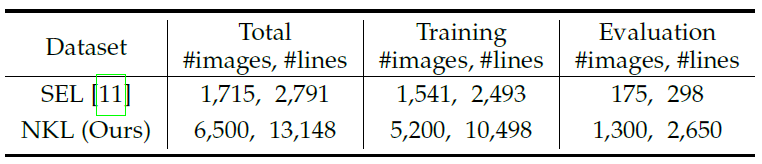 表2:SEL 数据集和 NKL 数据集对比。
表2:SEL 数据集和 NKL 数据集对比。
为了验证 NKL 数据集在图像场景中的多样性,该论文使用在 Places365 数据集上预训练的模型分别对 NKL 和 SEL 数据集中的样本进行推理,预测的分类结果如图5所示:
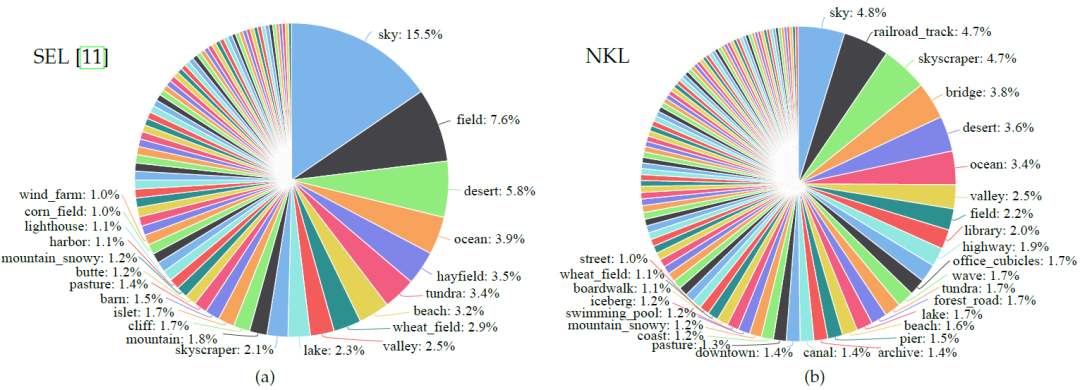 图5:SEL和论文新构建的 NKL 数据集的场景分布
图5:SEL和论文新构建的 NKL 数据集的场景分布
从图5可以看出,SEL 的大部分样本集中在天空、场地等少数场景,而NKL数据集中样本的分布更为多样化,同时场景类别也更多。
使用“计图”框架加速推理
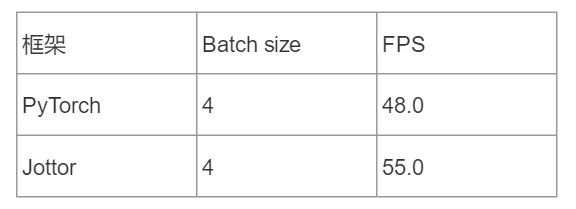
该论文同时也提供了基于清华大学自主研发的“计图”(jittor)框架的推理代码,得益于Jittor框架“元算子融合”和“统一计算图”两项新技术,DHT 算发无需任何优化情况下推理速度相比PyTorch 就有显著提升。
在 Titan XP 显卡上使用 batch size=4进行前向预测,PyTorch 框架下的 FPS 为 48,而同条件下计图可达到每秒 55 帧。
[1] J. B. Burns, A. R. Hanson, and E. M. Riseman, “Extracting straight lines,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 8, no. 4, pp. 425–455, 1986.
[2] L. Liu, R. Chen, L. Wolf, and D. Cohen-Or, “Optimizing photo composition,” Comput. Graph. Forum, vol. 29, no. 2, pp. 469–478, 2010.
[3] M. Freeman, The photographer’s eye: composition and design for better digital photos. CRC Press, 2007
[4] M.-M. Cheng, X.-C. Liu, J. Wang, S.-P. Lu, Y.-K. Lai, and P. L. Rosin, “Structure-preserving neural style transfer,” IEEE Trans. Image Process., vol. 29, pp. 909–920, 2020.
[5] J.-T. Lee, H.-U. Kim, C. Lee, and C.-S. Kim, “Semantic line detection and its applications,” in Int. Conf. Comput. Vis., 2017, pp. 3229–3237.
[6] R. O. Duda and P. E. Hart, “Use of the hough transformation to detect lines and curves in pictures,” Sri International Menlo Park Ca Artificial Intelligence Center, Tech. Rep., 1971.
[7] Hu, Shi-Min, et al. "Jittor: a novel deep learning framework with meta-operators and unified graph execution." Science China Information Sciences 63.12 (2020): 1-21.
转载自:CVer
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

















 1698
1698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









