






点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

来源丨泡泡机器人SLAM
作者丨泡泡机器人
标题:CodedStereo: Learned Phase Masks for LargeDepth-of-Field Stereo
作者:Shiyu Tan, Yicheng Wu, Shoou-I Yu, Ashok Veeraraghavan
机构:Rice University,Facebook Reality Labs
来源:CVPR2021
编译 : 张海晗
审核:李璟
摘要

大家好!今天要介绍的文章是来自美国莱斯大学和脸书实验室合作的一篇文章。对于大尺度景深双目视觉的学习相位掩模。由于孔径大小对双目视觉的成像体积和信噪比的影响相互矛盾,因此传统双目视觉需要在两个变量之间进行根本性的权衡。受现场相机扩展深度的启发,这篇文章是受扩展景深相机的启发,提出了一种新颖的基于端到端学习的技术来克服上述矛盾。方法是在立体成像系统中的相机孔径平面引入相位掩模。相位掩模创建了一个与深度相关但数值可逆的点扩散函数,使该系统能够在传统立体扩展景深相机(EDOF)上恢复更清晰的图像纹理和立体对应。相位掩模模式、EDOF 图像重建和立体视差估计都使用端到端学习的深度神经网络一起训练。本文对所提出的方法进行理论分析和表征,并显示可以在模拟中将成像的体积增加了 6 倍。除此之外,本文还构建了一个实验原型,并且使用该原型系统获得的实际结果来验证该方法。
背景与贡献

主要贡献:
传统双目视觉需要在光照水平、曝光时间、重建量和 SNR 之间进行权衡。由于特征不一致,传统的 EDOF 立体效果会导致 3D 重建伪影。CodedStereo 的关键思想是在立体相机的光圈中引入相位掩模,这使系统能够在不牺牲景深的情况下增加相机的光圈尺寸。
1.本文提出了一种编码双目技术,可以在光线有限的环境中重建大体积、高质量和高分辨率的三维模型。
2.本文开发了一个端到端的学习框架来联合优化相位掩码和算法,用于 RGB 图像和视差重建。
3.本文展示了CodedStereo 在模拟和使用原型系统中的显着性能优势。
算法流程

主要算法介绍
整个系统主要包含一个单独的优化相位掩模,并且可以将该相位掩模作为立体对插入到一对相机的光圈中。插入这些相位掩模后,这些相机的光圈可以保持大开,通过提高成像信噪比而获取更大的光收集。插入这些相位掩模引起的深度相关模糊与视差和图像重建一起得到优化。这里称之为“CodedStereo”技术。整个系统可同时在大景深中获得清晰的图像纹理和立体对应,而不会牺牲 SNR 或光通量。
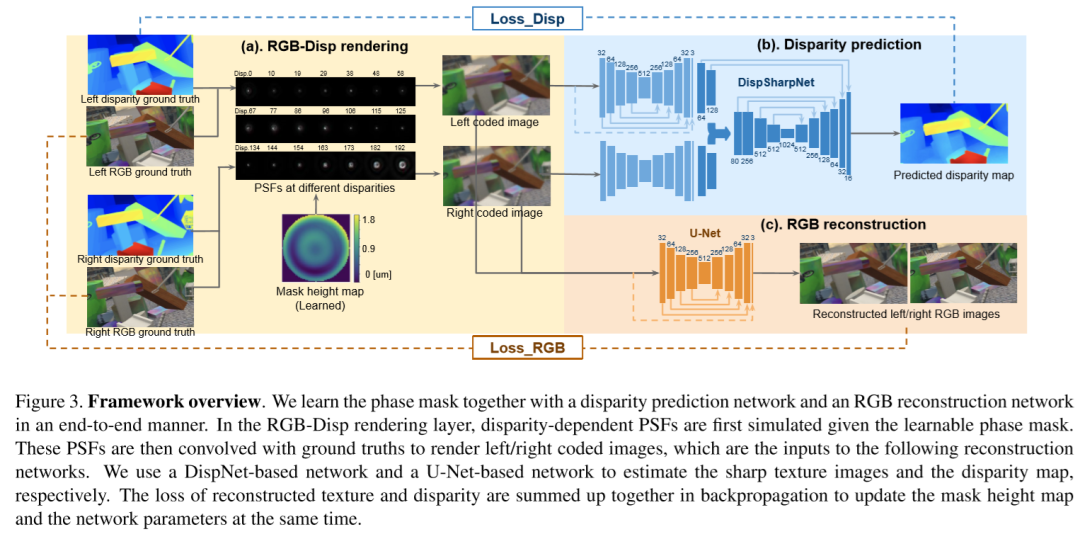
如图 3 所示,端到端训练管道由三个不同的部分组成:(a) 渲染:一个 RGB-Disp 模拟器,使用纹理和深度作为输入渲染左/右编码图像(同时考虑深度相关的特定相位掩码的散焦效果)(b) 视差预测:基于 DispNet 的深度网络,用于从编码对估计视差,以及 (c) RGB 图像重建:用于重建清晰图像的 UNet。接下来将详细介绍下每个不同部分的原理。
A. 使用RGB-Disp模拟器的渲染
在传统双目视觉中,整个场景都被假设在景深内。然而,当其不在景深内时,在捕获的图像上的散焦模糊明显依赖于场景点的深度值,也可以看作两个相机视图的对应点之间的差异。此外,当相位掩模插入孔径平面时,视差相关点扩散函数 (PSF) 也取决于相位掩模图案。渲染层内的目标是在 CodedStereo 系统中准确模拟相位掩模图案和视差对捕获的左右图像的影响。RGB-Disp 渲染基于傅立叶光学理论,并且完全可微以实现端到端训练。每个相机的点扩散函数 (PSF) 模拟为瞳孔函数傅立叶变换的平方幅度(取决于相位掩模图案)。
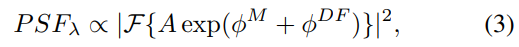
λ是波长。在瞳函数中,A为孔径的圆形振幅函数,φM为相位掩模引起的相移(与掩模高度图成正比),φDF为离焦相位。离焦相位可以进一步推导为视差d的函数
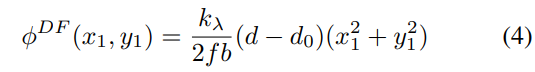
其中kλ = 2π/λ为波数,f为焦距,b为两个视图之间的基线。(x1, y1)为掩模平面上的空间坐标,d0为对焦深度处的视差值。然后,通过将地面真实RGB纹理与视差和波长依赖的PSF进行卷积来渲染编码图像。
B. RGB及视差重建
本文使用两个独立的网络来重建视差图和清晰的纹理图像。纹理重建网络基于改进的残差U-Net,其中学习了编码图像和基准真相图像(即残差图像)之间的差异。学习残差图像的优点是鼓励高频信息恢复,如边缘和细节纹理,因此这种残差学习技术被广泛用于逐像素估计问题,如去模糊。对于视差预测,本文采用了DispNetc结构。这里通过添加额外的反卷积层对视差图进行上采样来对其进行修改,以便最终输出与输入的左/右编码图像大小相同。由于在 DispNetC 之前的额外的编码器-解码器模块可以有利于立体对的特征提取,尤其是在具有大量离焦模糊的图像区域。因此,本文通过共享加权的编码器 - 解码器层和两个卷积层分别处理编码的左/右图像以提取特征,然后水平关联特征。本文考虑了 64 个像素的最大位移,这对应于原始编码图像中的 192 个像素。这里将视差预测网络称为 DispSharpNet,因为它可以使用额外的细节和更清晰的边界进行视差估计。
C.损失函数
在训练过程中,损失函数被定义为视差预测误差和RGB重建误差的组合。本文对估计的 RGB 图像I和不同分辨率i下的预测视差di都使用了均方根误差。
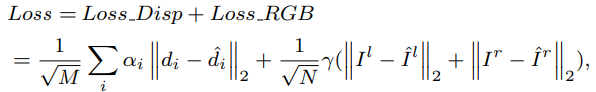
其中αi、γ是相应的权重,M、N分别是RGB图像和视差图中的像素数。l 表示左边,r 表示右边。对于稳定的特征匹配,类似于 DispNet,本文采用了一个损失权重,仅以最低分辨率损失开始训练,并逐渐增加分辨率更高的损失权重。
实验结果


图1. 与传统基线的比较(在模拟中)。(a) 使用小孔径常规 F32 镜头。(b) 使用openaperture 常规F8 镜头。(c) 我们的优化掩码。为了进行比较,我们将相同的重建网络应用于 F32 和 F8 系统,即用于 RGB 图像估计的 U-Net 和用于视差预测的 DispSharpNet。结果表明,我们的设计在具有清晰细节和锐利边缘的高质量、高分辨率重建方面优于传统设计。
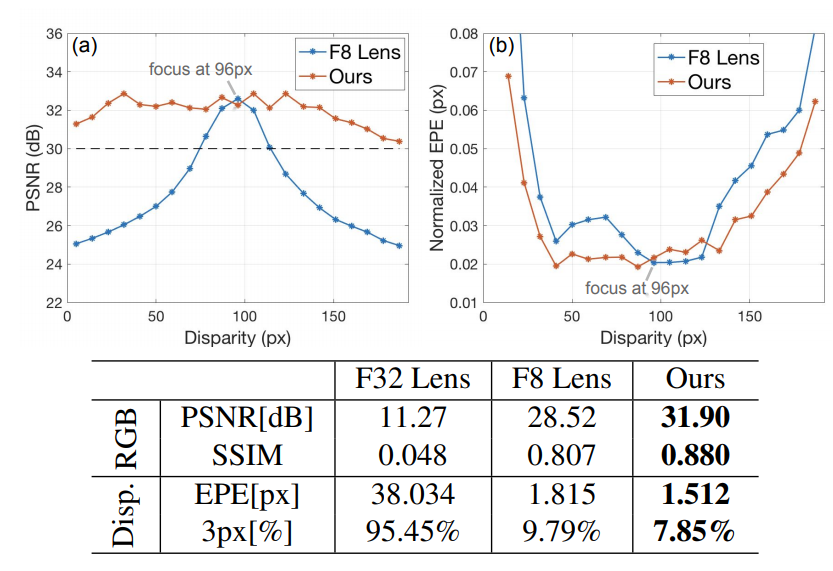
图2,与传统镜片比较。上图:重建的PSNR和EPE(归一化到视差地面真实值)随视差的变化。我们的方法明显优于传统的基线,特别是在离焦范围,导致景深增加6(黑色虚线表示PSNR阈值在30dB)。底部:纹理重建评价采用平均PSNR和SSIM(越高越好),视差预测评价采用平均EPE和3像素错误率(越低越好)。
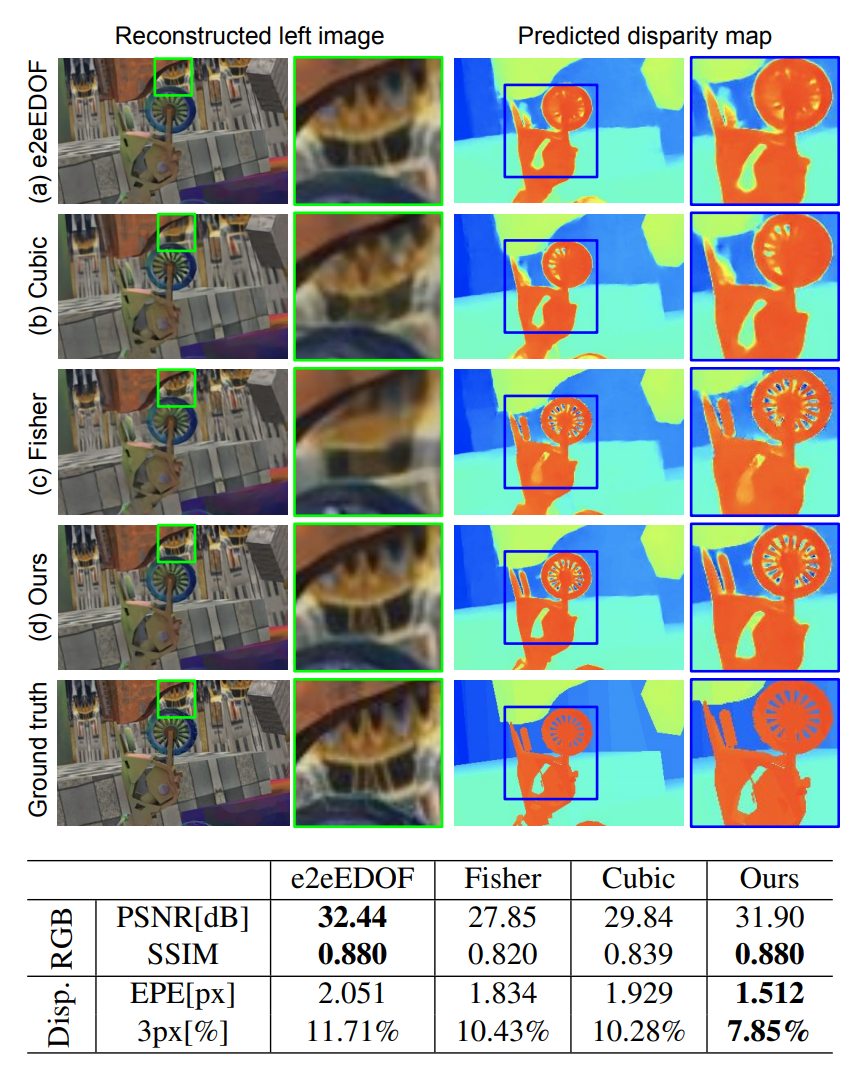
图3,仿真中与其他掩模的比较。e2eEDOF掩模采用端到端训练,直接从EDOF图像对

图4. 用我们的CodedStereo原型的各种真实场景的实验结果。重建结果显示了真实场景的均匀背景和非均匀背景(最后一列,纹理/深度变化)。
点击阅读原文, 即可获取本文下载链接。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 2528
2528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









