






来源丨 计算机视觉深度学习和自动驾驶
arXiv在2021年10月3日上传论文“Translating Images into Maps“,作者来自英国University of Surrey和德国亚马逊分公司。

瞬时地图,将图像转换为俯视世界地图,作为一个变换问题。在单个端到端网络用一种transformer网络将图像和视频直接映射到世界俯视图或鸟瞰图 (BEV)。假设图像的垂直扫描线与俯视图中穿过相机位置的射线之间存在 1-1 对应关系,这样将图像的地图生成定义为一组序列到序列转换。
将问题视为转换,可允许网络在解释每个像素作用时采用图像的上下文,得到的是一个限制的transformer网络,只在水平方向做卷积。
代码将公开:https://github.com/avishkarsaha/translating-images-into-maps
如图所示是网络架构图:(A) 模型架构。前端(frontend)提取多尺度空间特征,编码器-解码器transformer将空间特征从图像转换为 BEV,可选的动态模块(dynamic module)用过去的空间 BEV 特征来学习时-空 BEV 表征,BEV segmentation network(分割网络)处理 BEV 表征生成多尺度占用格。(B) 平面间注意机制。在基于注意的模型中,图像的垂直扫描线被一条条地传递到transformer编码器,创建一个“内存(memory)”表征,解码为 BEV 极向射线(polar ray)。
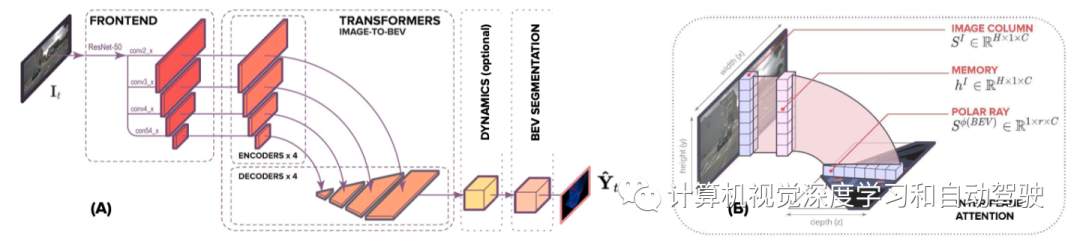
这个端到端方法实现的任务包括:(1) 在图像平面构建表征,对语义和深度(depth)知识进行编码;(2) 图像平面表示转换为 BEV, 这种映射可以看作是语义目标从图像平面到其BEV平面射线的位置分配;和 (3) 语义上分割 BEV 表征。
作者通过注意机制学习输入扫描线和输出极向射线之间的对齐,包括两种方式:(1)平面间注意,最初将特征从扫描线分配给射线;(2)极向射线自注意,全局推理跨射线的位置分配。这是一种软对齐,其中极向射线的每个像素都被分配了图像列元素的组合,即上下文向量。具体来说,生成每个径向元素时,根据图像列元素的凸组合和沿极向射线的径向位置赋予上下文。在注意机制中,内存(memory)中的输入序列和查询通过输入序列的元素与其径向位置的对齐生成上下文。
以这种方式生成上下文,允许每个径向元素独立地从图像列中收集相关信息,表示从图像到其 BEV 位置组件的初始分配。这种初始分配类似于根据深度(depth)提升像素到3D。然而,被提升到深度的分布,能够克服稀疏和细长目标视锥体的常见缺陷。这意味着每个径向元素的图像上下文与其和相机的距离分离。
鉴于每个上下文缺乏全局推理,沿射线的特征空间分布不太可能与局部或全局的目标形状一致。需要沿射线做全局操作,让指定的扫描线特征推断在整个射线上下文的位置,以生成相干目标形状的方式聚合信息。
单调注意(MA)最初提议用于计算同步机器翻译的对齐问题。然而,源和目标序列之间的“硬”分配意味着忽略了重要的上下文,导致具有无限回溯MA (MAIL) 的 发展,将硬单调注意与软注意相结合。作者采用 MAIL 作为约束注意机制的一种方式,忽略图像垂直扫描线的冗余上下文,潜在地防止过拟合。采用 MAIL 的主要目的是了解图像某个点下面的上下文是否比上面的更有帮助。
模型架构包含三个主要组件:一个标准的 CNN 主干网提取图像平面的空间特征,编码器-解码器transformer将特征从图像平面转换为 BEV,最后是一个将 BEV 特征解码为语义图的分割网络。其中Transformer编码器和解码器对每个序列-到-序列的转换用相同的投影矩阵,具有沿 x 轴卷积的结构。
实验的基线方法包括
VPN(“Cross-view semantic segmentation for sensing surroundings,” IEEE Robotics and Automation Letters, 2020)
VED(“Monocular semantic occupancy grid mapping with convolutional variational encoder–decoder networks,” IEEE Robotics and Automation Letters, 2019.)
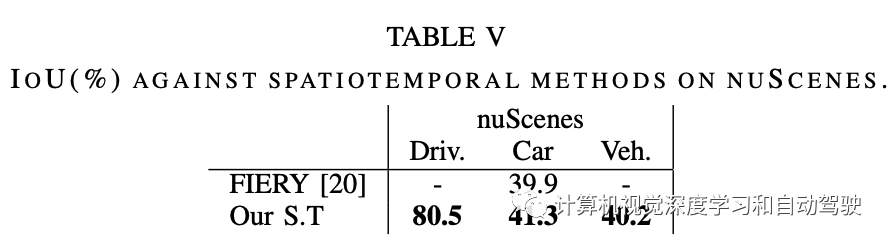
PON(“Predicting semantic map representations from images using pyramid occupancy networks,” CVPR 2020)
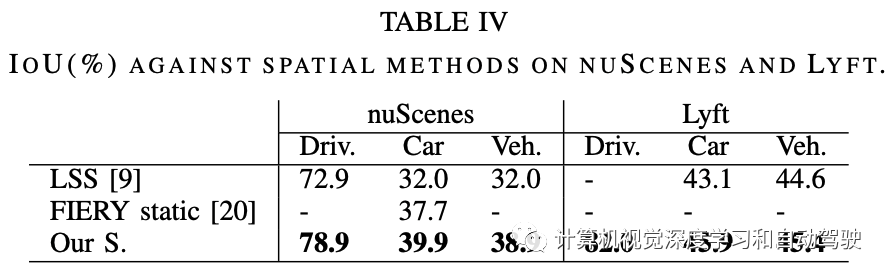
LSS(“Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” ECCV, 2020)
STA-S(“Enabling spatio- temporal aggregation in birds-eye-view vehicle estimation,” ICRA, 2021.)
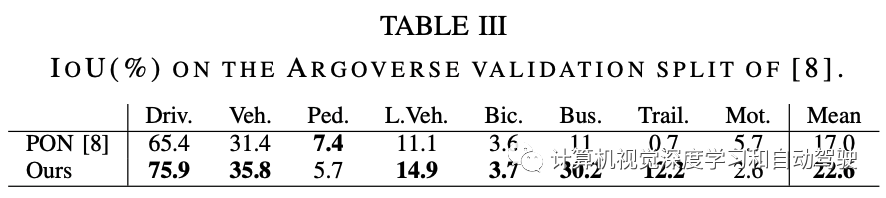
FIERY(“FIERY: Future instance segmentation in bird’s-eye view from surround monocular cameras,” ICCV, 2021)
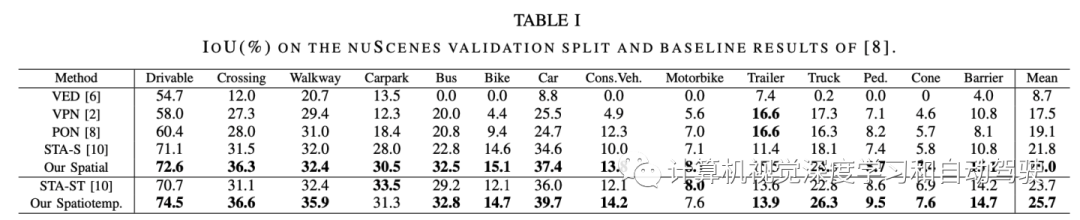
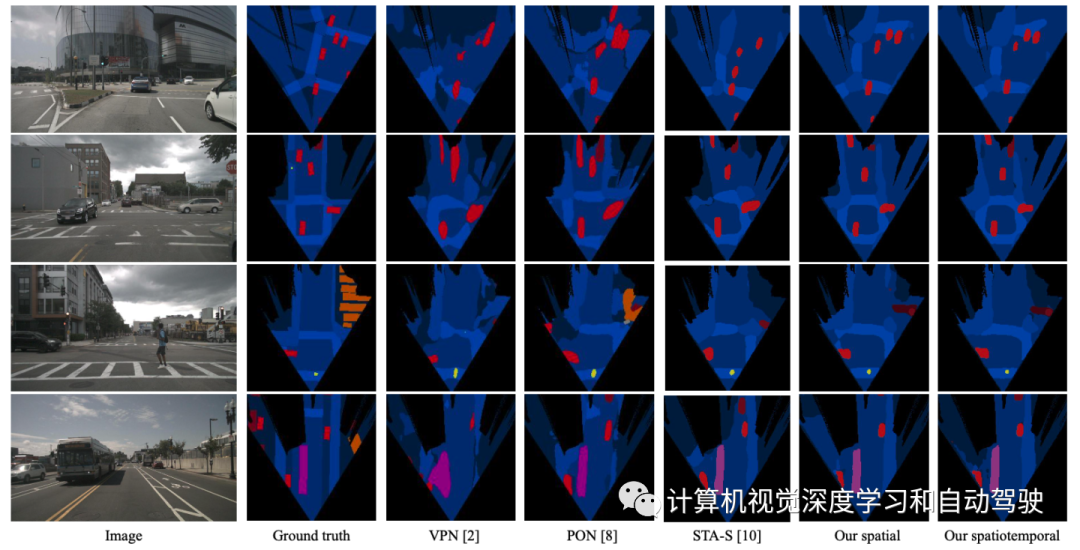
实验比较结果如下:
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









