






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:cv3d001,备注:方向+单位+昵称,拉你入群。文末附行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),星球内汇总了众多3D视觉实战问题,以及各个模块的学习资料,包括20+门独家视频课程、100+场顶会直播讲解、最新顶会论文分享、计算机视觉书籍、优质3D视觉算法源码、3D视觉入门环境配置教程、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0.这篇文章干了啥?
这篇文章系统介绍了BOP 2024挑战赛的整体设置、评估方法、参赛算法以及实验结果,重点围绕基于模型的与模型无关的6D物体姿态估计与检测任务展开。作者首次引入了BOP-H3数据集用于测试更具挑战性的现实场景,增加了模型自由的2D检测任务,并提出了多个新评估指标用于量化检测与姿态估计的性能。实验部分展示了多种最新算法(如FreeZeV2.1、GigaPose、MUSE等)在不同数据集和任务下的表现,表明当前方法在处理未见物体时的精度已接近已见物体,同时也指出仍需提升实时性与模型无关方法的精度。文章还预告了BOP 2025将进一步引入工业级数据集与多视角设置,推动6D姿态估计在工业机器人中的实际应用。
下面一起来阅读一下这项工作~
1. 论文信息
论文题目:AD-Det: Boosting Object Detection in UAV Images with Focused Small Objects and Balanced Tail Classes
作者:Zhenteng Li, Sheng Lian等
作者机构:Fuzhou University等
论文链接:https://arxiv.org/pdf/2504.05601
2. 摘要
我们展示了2024年BOP挑战赛的评估方法、数据集和结果,这是一个旨在展示6D物体姿态估计及相关任务最新进展的公开竞赛系列中的第六届。在2024年,我们的目标是将BOP挑战从实验室环境转向真实世界场景。首先,我们引入了新的无模型任务,其中没有3D物体模型可用,方法需要仅凭提供的参考视频来进行物体的识别。其次,我们定义了一个新的、更实用的6D物体检测任务,在该任务中,测试图像中可见物体的身份信息不作为输入(与经典的6D定位任务不同)。第三,我们引入了新的BOP-H3数据集,这些数据集使用高分辨率传感器和AR/VR头戴设备录制,紧密模拟真实世界场景。BOP-H3包括3D模型和入门视频,支持基于模型和无模型任务。参赛者在七个挑战赛轨道中竞争,每个轨道由任务(6D定位、6D检测、2D检测)、物体入门设置(基于模型、无模型)和数据集组(BOP-Classic-Core,BOP-H3)定义。值得注意的是,2024年最佳的无见物体6D定位方法(FreeZeV2.1)在BOP-Classic-Core上比2023年最佳方法(GenFlow)提高了22%的准确性,并且仅比2023年最佳方法(GPose2023)慢了4%(每张图像24.9秒对比2.7秒)。一种更实用的2024年方法是Co-op,它每张图像仅需0.8秒,比GenFlow快了25倍,并且准确度提高了13%。在6D检测任务上,方法排名与6D定位相似,但(如预期)运行时间更长。在无见物体的基于模型的2D检测中,2024年最佳方法(MUSE)相比2023年最佳方法(CNOS)提高了21%的相对精度。然而,无见物体的2D检测准确性仍然明显低于见物体(-53%),因此2D检测阶段成为现有6D物体姿态估计管道的主要瓶颈。在线评估系统仍然开放,网址为:bop.felk.cvut.cz。
3. 效果展示
新的BOP-H3数据集,具有用于无模型任务的对象加载序列。前三列显示了来自新数据集的样本图像,地面实况姿态中的3D对象模型的轮廓以绿色绘制。第四列显示了静态(顶部)和动态(底部)加载序列,这些序列在BOP-H3中可用,并用于新引入的无模型任务中的学习对象。

HOPEv2的入门视频示例。前两行显示了静态入轨视频中的示例帧,一行对象直立,另一行对象倒立。第三行显示了来自动态入职视频的样本帧,其中对象由手操纵。为所有静态帧提供地面实况姿态(以绿色轮廓显示),但仅为动态载入视频的第一帧提供地面实况姿态(参见第2.4以取得详细数据)。

2024年挑战中使用的BOP-H3数据集中的对象概述。
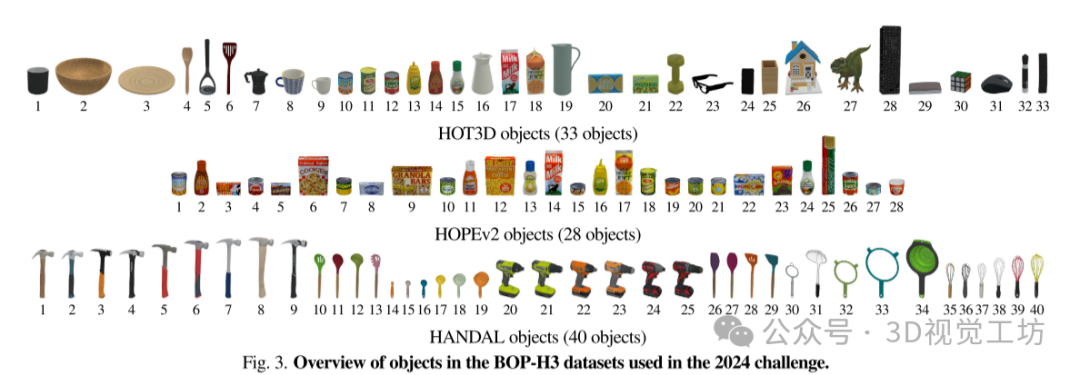
4. 主要贡献
6D定位精度的提升:2024挑战赛中,针对未见物体的6D定位方法几乎达到了已见物体的方法精度。这一进展使得6D姿态估计在更广泛的应用中变得更加准确和可靠。
实时性能的优化:部分针对未见物体的方法已经能够在不到1秒的时间内完成计算,尽管如此,仍需进一步优化以满足实时应用的需求。
引入模型自由任务:2024年挑战赛引入了模型自由的6D姿态估计任务,为未来的应用开辟了新的方向。这将推动更加实际的应用场景,如工业机器人中的物体姿态估计。
BOP-Industrial数据集和多视角问题设置:在BOP'25中,将引入BOP-Industrial数据集及多视角问题设置,旨在代表工业机器人中的实际应用,推动学术界和工业界的融合。推荐课程:国内首个面向具身智能方向的理论与实战课程。
公开评估系统:评估系统bop.felk.cvut.cz保持开放,所有方法的原始结果都可公开访问,确保研究结果的透明性和公平性,为研究者提供可复现的结果支持。
5. 基本原理是啥?
BOP(Benchmark for Object Pose Estimation)挑战赛的核心任务是评估物体姿态估计方法的性能,特别是在6D定位(3D位置和方向)和检测任务中:
6D定位与检测:
6D定位:这是指在三维空间中确定物体的位置(X, Y, Z)和方向(旋转,通常由欧拉角或者四元数表示)。目标是通过给定的2D图像来推算物体在三维空间中的姿态。
6D检测:除了估计物体的姿态外,检测任务还要求在图像中检测并定位物体实例,即确定每个物体的边界框和其在三维空间中的6D姿态。
模型基础与模型自由方法:
模型基础方法(Model-based methods):这些方法使用预先渲染的3D物体模型,通过与2D图像中的特征进行匹配来估计物体的姿态。这些方法通常需要对物体进行训练并使用固定的超参数设置。
模型自由方法(Model-free methods):与模型基础方法不同,模型自由方法不依赖于物体的预先3D模型,而是通过其他手段(例如,从视频中重建3D模型)来估计姿态。
数据集与训练:
BOP数据集:BOP挑战赛使用了包含多个物体类别和测试场景的数据集,这些数据集提供了测试图像和物体的Ground Truth(GT)数据(如物体的实际姿态)。这些数据集用于训练和评估不同方法的性能。
在训练过程中,物体的3D位置信息和方向通过图像中的特征提取来实现估计,评估时,系统会将物体的姿态与实际的GT进行比较,计算准确率和其他评估指标。
图像特征提取与匹配:
物体的姿态估计通常依赖于图像中的特征提取和匹配技术,如SIFT(尺度不变特征转换)、SURF(加速稳健特征)、DINOv2(一个新的视觉模型)等,这些特征帮助从2D图像中识别物体并进行匹配。
通过这些特征,系统能够计算物体在图像中的投影位置,并推断其在三维空间中的位置和旋转角度。
优化与后处理:
对于大多数方法,物体姿态估计通常采用两阶段流程:第一阶段是检测图像中的物体(2D检测),第二阶段是根据检测结果估计物体的6D姿态。
后处理技术,如ICP(迭代最近点算法)和对称感知的精细调整等,通常用于优化姿态估计,进一步提高准确性。
6. 实验结果
在2024年BOP挑战赛中,针对不同任务和数据集的物体姿态估计方法进行了广泛的评估:
模型基础的6D定位(BOP-Classic-Core)
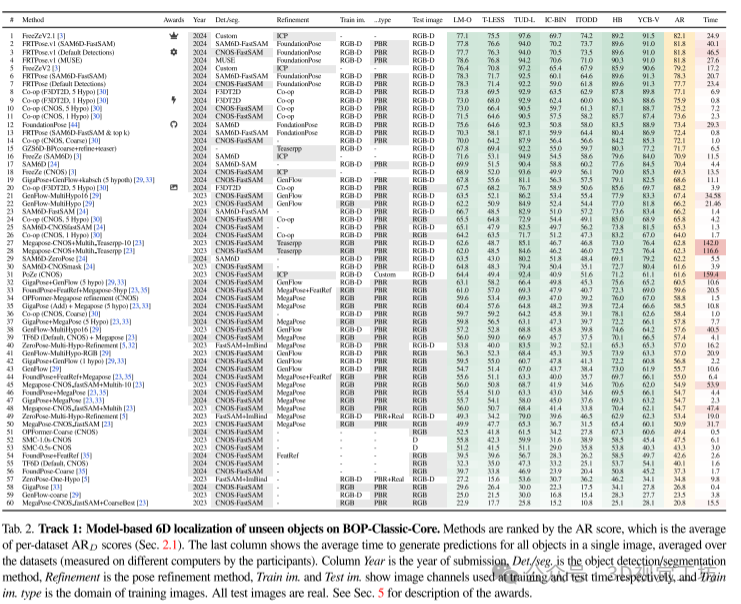
对未见物体的模型基础6D定位结果如表2所示。在2024年提交的44个新方法中,有20个方法超越了2023年挑战赛的最佳方法GenFlow。其中,表现最好的方法FreeZeV2.1达到了82.1的AR(准确率),比GenFlow高出22%,且运行时间比GenFlow快28%。此外,FreeZeV2.1离2023年最佳方法GPose2023的结果(针对已见物体)仅差4%。
FreeZeV2.1结合了来自冻结DINOv2的2D特征和GeDi的3D特征,通过SAM6D、NIDS和CNOS的检测来进行姿态估计。
另一种值得注意的方法是FRTPose.v1,在AR上排名第二,达到了81.8。
模型基础的6D检测(BOP-Classic-Core)
表3显示了20个提交的模型基础6D检测结果。在Track 1和Track 2之间的排名一致:表现最好的方法是FreeZeV2.1,其次是FRTPose.v2和Co-op 。在6D检测中,FreeZeV2.1相较于Co-op的相对改进为18.8%(排名1和7),而在6D定位中的改进仅为6.5%(排名1和8)。
Co-op使用了三阶段的流程:粗略估计通过预训练的CrocoV2,然后通过光流进行精细化处理,最后使用类似于MegaPose的网络进行评分。结果表明,当模板和裁剪的对象不一致时,粗略结果的表现优于精细化处理的结果。
模型基础的2D检测(BOP-Classic-Core)
表4展示了模型基础2D检测的结果。最好的方法是MUSE,其采用了一种新颖的相似性度量,基于类别和补丁嵌入,并通过von Mises Fisher分布加权3D模板视图的贡献。MUSE在精度上达到了52.0 AP,比2023年挑战赛中最佳方法CNOS高出21%。
尽管如此,MUSE仍然落后于针对已见物体的最佳方法GDet2023,落后53%。
模型基础的6D检测(BOP-H3)
表5展示了BOP-H3数据集上模型基础6D检测的结果。所有方法均使用RGB/单色图像,因为HOT3D和HANDAL数据集没有深度信息。GigaPose和GigaPose+GenFlow分别在BOP-H3数据集上达到了9.4和31.2的AP,相较于BOP-Classic-Core数据集上的12.3和50.4的AP有所下降。
OPFormer是一种新方法,采用DINOv2模板描述符和transformer与3D位置嵌入结合,并通过RANSAC-PnP进行姿态预测。在HOPEv2数据集上,OPFormer比GigaPose高出110%,但经过精细化处理后,其表现略逊于GigaPose+GenFlow,差距为5%。
模型基础的2D检测(BOP-H3)
表6展示了BOP-H3数据集上模型基础2D检测的结果。类似于在BOP-Classic-Core数据集上的结果,MUSE仍然超越了CNOS,但相对改进有所不同:在BOP-H3数据集上,MUSE比CNOS准确度高出33.1%。
模型自由的2D检测(BOP-H3)
新的任务——模型自由的2D检测(表7)展示了3个提交的结果。GFreeDet引入了一种新的模型自由的2D检测方法,通过高斯溅射重建物体,然后使用DINOv2进行模板匹配。GFreeDet在HOPEv2数据集上的表现比CNOS高出5%(36.4 vs 34.5 AP)。
定性结果
图4展示了BOP-Classic-Core(Track 2)和BOP-H3(Track 6)上最好的方法——FreeZeV2.1和GigaPose+GenFlow的定性结果。值得注意的是,FreeZeV2.1在ITODD数据集上的假阳性数量明显多于其他数据集。

7. 总结 & 未来工作
在BOP 2024中,未见对象的6D定位方法几乎达到了与已见对象相当的精度。尽管一些未见对象的方法现在运行时间已少于1秒,但仍需要进一步改进以支持实时应用。我们希望2024挑战赛中引入的模型自由任务将开启新类型的应用,使得对象姿态估计变得更加实用。在BOP'25中,我们将引入BOP-Industrial数据集和多视角问题设置,以代表工业机器人中的实际应用。位于bop.felk.cvut.cz的评估系统仍然开放,所有方法的原始结果都可公开访问。
本文仅做学术分享,如有侵权,请联系删文。


3D硬件专区

「3D视觉从入门到精通」知识星球
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),已沉淀7年,星球内资料包括:3D视觉系列视频近20+门、100+场直播顶会讲解、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~


















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









