






引言
大模型时代,我们会碰到非常多的新名词,如RAG、COT、A2A、MCP、Workflow、FunctionCall等,最近在思考如何体系化的记忆这些概念,在搭建Agent过程中,发现这些名词在建设Agent过程中都会用上,那不妨以Agent作为主线,整理下LLM相关的知识点
—1—
什么是Agent
一、Agent基础概念
Agent直译是代理,一般又喜欢叫做智能体
在理解Agent是什么之前,我们先来回顾下我们与大模型的交互,比如我们想让AI帮我们完成机票的预订:
输入:
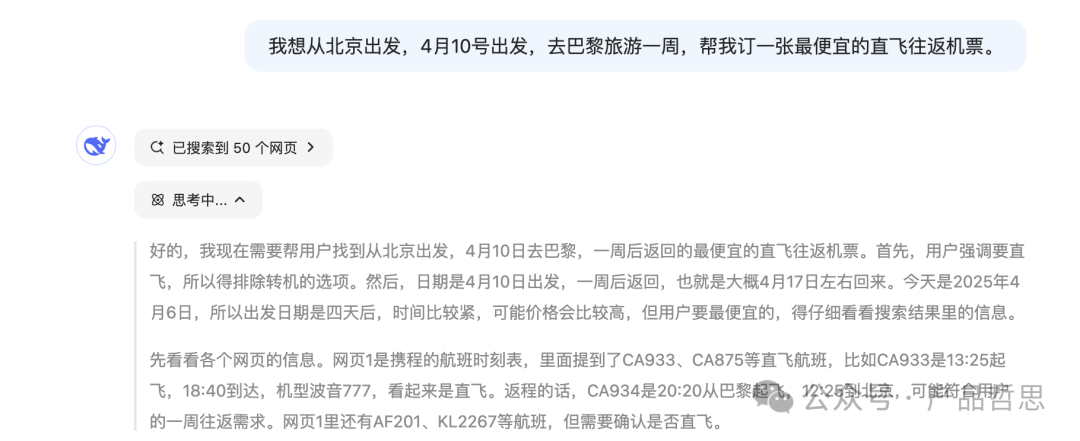
用户问:“我想从北京出发,4月10号出发,去巴黎旅游一周,帮我订一张最便宜的直飞往返机票。”
输出:
“你可以乘坐法国航空公司4月10日上午10:30从北京直飞巴黎的AF129航班,价格约为人民币2800元,4月17号返程航班是AF128。”
纯对话式大模型的问题:
如果你只是用一个纯语言模型(比如 ChatGPT)来回答这个问题,它可能会:
• 编造一个看起来合理但实际上不存在的航班信息(幻觉)
• 给出不准确的价格或错误的航司名称
• 无法处理实时变化的数据(航班、价格、可用性)
• 无法真正下单,最多只能“模拟”推荐
像这类复杂多步骤执行,得我们自己动手
一开始大模型大家更多是当一个高级搜索引擎用
人们开始思考,如何让AI自主完成任务,AI接到任务要自己想怎么去做,Agent便是为了完成更复杂的AI任务而被定义出来的。
引申出Agent经典定义:
1)能够感知环境——不止能读文字,还要能看图片、听音频、读文件;
2)独立做出决策——遇到复杂的任务要自己拆解成一个个可执行的小任务;
3)并且能主动执行行动的;
对AI产品经理而言,Agent可以理解为基于大模型能力构建的AI应用。
但是大语言模型本质是根据输入的文本,去预测下一个字符,那大模型又是靠什么去感知环境的?记忆又怎么存储?怎么去做规划?怎么采取行动?
—2*—*
理解Agent的四大能力
2.1感知能力——开眼看世界:
大模型是靠海量文本数据训练出来的,基础感知方式就是接收用户输入的文本
比如用户如果输入的是表情包、图片又要如何交流?中间方案先用OCR(一种识别图像中字符的技术)提取图像中的文本信息,再让大模型做解读,但是只提取文字会少掉很多信息,比如背景图案,人物表情等,那能不能让大模型能直接理解图片呢?
巧了,目前主流大模型都是采用的Transformer架构,这种架构天然支持处理各种类型的序列数据,多模态大模型闪亮登场。
你可以把多模态大模型看成一个超级语言模型,只是它的“语言”不只限于文字,而是把图片、语音、视频等也翻译成“序列”:
- 📷 图像 → 分成小块(Patch)或编码成Token序列
- 🔊 音频 → 划分帧,提取频谱或用音频Tokenizer编码成序列
- 📹 视频 → 看作图像帧序列 + 时间信息
- 📝 文本 → 原本就是Token序列
那么大模型又是如何学会多模态能力的?这里面有个关键技术叫模态对齐(Modality Alignment)
为了让模型理解“图+文”甚至“图+语音+文”的组合,必须让不同模态的数据共享或映射到相似的语义空间。常见方法包括:
不同的模态(比如图片、文字、语音)本质上是不同形式的信息,
要让大模型理解它们之间的关系,就要把它们对齐到同一个**“理解空间”**里,
也就是让模型知道:“图里是只狗” 和 “文字里说有只狗” 是一回事。

怎么做到模态对齐?
方法1:CLIP式对比学习
把图像和文字分别编码成向量,然后训练模型去拉近配对的图文向量,拉远错配的向量。就像玩“图文连连看”——对的拉近,错的推开。
方法2:跨模态对齐损失
在训练过程中设计一种“惩罚机制”,让模型更喜欢图文对得上的组合,不喜欢搭不上的组合(比如“图片是猫,但文字说是狗”)
效果就是输入图片可以理解图片上所有信息,如颜色、物体等,现在大多数平台都支持多模态能力,大家可以自行体验

多模态应用到语音方面,还能识别方言语气语调,所以说多模态能力相当于大模型有了眼睛耳朵
感知环境的能力有了,但是我们发现大模型应用一遇到复杂问题就歇菜,怎么让大模型能聪明些?
2.2规划能力——独立思考:
阶段1:初步规划能力的萌芽(CoT与ToT)
如果公司新来了一个实习生,对公司流程并不熟悉,如果要让他上手工作,最直接的就是告诉他每一步应该怎么做,这就是COT思维链方法:让模型给出答案前按什么步骤去拆解问题
比如订机票任务:可以告诉大模型,你要先查询航班,再筛选最低直飞价格,最后跟用户确认时间
更进一步的方法TOT如思维树:让大模型想好几种不同的思路,选最好的那个
但我们不希望大模型一直是个实习生,我们希望他能自己思考怎么去实现复杂任务,不要人手把手教
阶段2:人为干预(Workflow和多智能体架构)
既然一个大模型自己想的不够好,人们想了一种方法,让大模型各司其职分不同的岗位协作完成任务,一个负责规划,一个负责协调,一个负责反思等,这种就叫multi-agent(多智能体模式),再让这些Agent以一个固定流水线的方式工作,举个例子比如拍一部电影,有以下Agent
- 导演Agent——负责总体规划,调度资源,确保影片符合预期。
- 演员Agents——扮演角色,按照剧本表演。
- 摄影师Agent——负责拍摄镜头,调整角度和光线。
- 编剧Agent——撰写剧本,为演员提供台词和故事框架。
- 制片人Agent——管理预算、安排人员、确保拍摄顺利进行。
- 剪辑师Agent——后期剪辑,将拍摄素材拼接成完整的电影。
- 配乐师Agent——创作配乐,增强电影氛围。
但由于Agent间的协作方式,包括Agent本身都是人为定制好的,一旦面对的任务有所改变,整套流程就没法用了,比如让上面这套Agent去造火箭,那么能不能让大模型自己去思考每一步应该怎么做?自己思考每个Agent之间应该怎么合作呢?
阶段3:专门的推理模型(O1和R1)
为了让大模型真正有规划能力,openai推出了o1,Deepseek推出R1模型,让大模型内化学会在每一次回答前,有一个自主的推理过程
现在再输入开头的问题,我们会看到模型输出回复之前,会有一段自主推理的过程:
阶段4:端到端训练的“模型即Agent”(DeepResearch)
基于这个推理能力,openai出了Deep Research功能,端到端训练后的o3模型,模型自主决定什么时候要搜索信息,什么时候要整理信息,什么时候应该进入深度搜索再分析总结。
智谱的GLM、Grok中都可以体验DeepSearch功能
到这里,Agent的规划思考能力有了,如何让他更好地执行呢?
2.3执行能力——学会使用工具
Function Calling(大模型函数调用)
我们自己在开发一个APP时,通常不会所有能力都自己开发,而是会接入一些外部能力,但原本大模型只能理解文字,如何让他知道怎么使用工具(API接口)?
怎么发信号大模型也不是出厂就知道的,人们发现通过示例去做监督微调(SFT),让模型学会了去调用工具,让他知道要调用工具的时候,去生成一段调用文本:调用什么接口,传什么参数

有SFT和无SFT对比
比如计算就可以调用计算器,传入算式,获得生成的结果
再后来人们发现每个工具都要单独接入,单独开发实在太麻烦了
于是Claude发布了MCP(模型上下文协议)
调用工具时,因为每个工具有自己的规范,意味着每接入一个新的工具,要单独开发适配的代码,MCP就像一个多孔TypeC转接头,一套协议兼容各种工具。
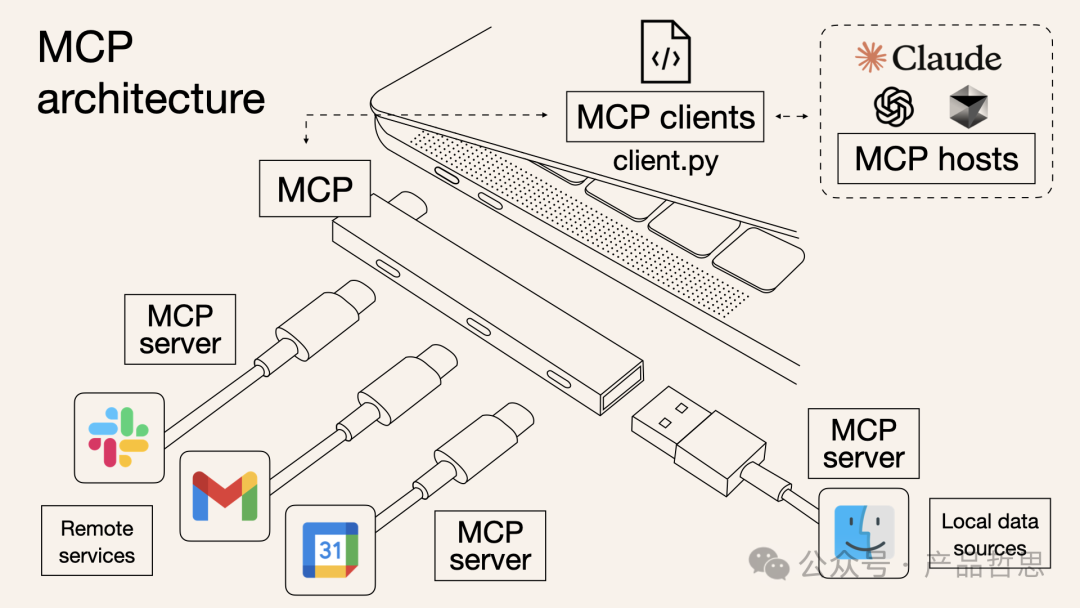
最近Google还开放了一个协议A2A,用于Agent之间的信息交换
关于A2A、MCP和Function Call的概念后续会出一篇文章单独讲解
有了上述的三大能力,一个能说会道、会思考、能干活的Agent跃然纸上,但这还不够,要让Agent真正具备“智能”,它还需要一个至关重要的能力
2.4记忆能力——长期/短期
通过记忆,Agent才能在与环境的持续交互中不断学习和进化,避免重复犯错、理解用户偏好、乃至形成长期目标。
早期大模型一次能接受的文本量(上下文窗口)是有限的,聊两句就不记得之前说的话
业界解决这个问题有两个路径:
一是增加模型能接受的上下文长度即短期记忆能力,但是光上下文长度也不够,有的东西我们还是希望他不要忘记
所以还有另一个方案:RAG(检索增强生成)
既然一次性没法全部记住,那给不如给大模型挂一个“搜索引擎”,不知道的答案先去搜一下,找出对应的内容再参考回答
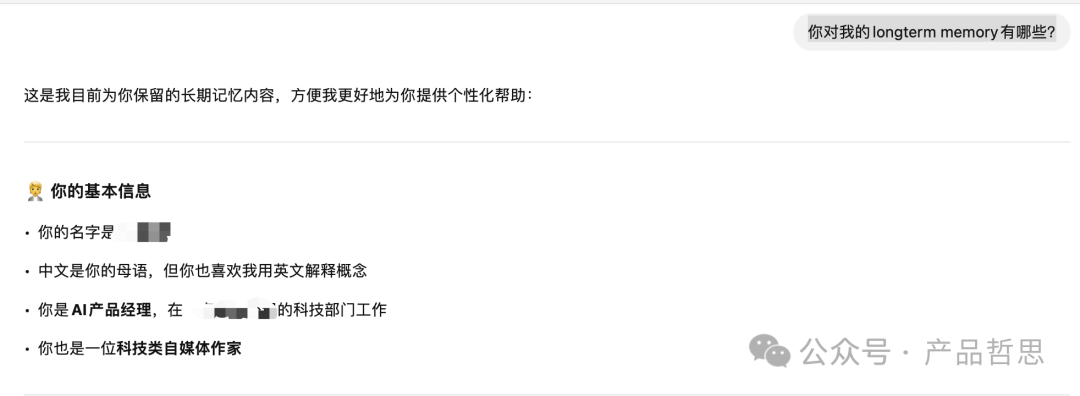
现在主流的大模型应用会在对话中提炼关键记录的信息,大家可以尝试对大模型说:你记住了我的哪些信息?
最后,作为产品的我们,肯定会好奇Agent能力如何评估呢?
目前公认的测试基准是GAIA: A Benchmark for General AI Assistants
之前小火了一段时间的Manus,就是在这个榜单上取得了领先。
GAIA从现实使用角度出发,设计了一系列代表真实场景的任务。
GAIA设计任务时关注四种通用能力,统称为 FACT:
Factuality(事实正确性)、Analysis(分析推理)、Creativity(创造力)、Task Completion(任务完成度)
这些维度强调模型在回答复杂指令时的可靠性、推理能力、生成能力和实用性。
— 3 —
总结
我认为,在当前阶段,“Agent”更多地体现为一种 AI产品的开发范式。以大模型为基础,它不仅是能力提供者,更是信息流转的桥梁。在某些垂类场景中,例如 Cursor 这类AI编码工具,其本质上就是由多个Agent协同组成,通过对业务流程的重构,实现特定类型任务的智能化处理。
一个理想的Agent系统,应该具备分解复杂任务、自主做出合理决策,并最终高效执行用户指令的能力。在构建这类系统时,“感知—决策—执行—记忆” 是不可或缺的四大核心能力。它们分别对应着:
• 感知:对环境、用户需求、上下文等信息的理解与建模能力;
• 决策:在目标导向下进行任务规划、优先级判断与路径选择的能力;
• 执行:将计划转化为具体行动,并与系统或工具交互以实现结果的能力。
**• 记忆:**在与环境的持续交互中不断学习和进化,避免重复犯错、理解用户偏好、乃至形成长期目标。
这三者既是Agent系统的基本组成,也是其智能涌现的根基。
对AI产品的启示在于:当我们希望将某个应用“Agent化”时,不能仅仅追求功能自动化或交互智能化,而应该系统性地思考在“感知、决策、执行”三个维度上如何与业务深度融合,推动产品能力的跃迁。
再比如,一个面向销售的Agent系统,可以:
• 感知客户画像、行为轨迹与沟通语境;
• 决策销售话术、推荐商品组合或跟进节奏;
• 执行电话拨打、邮件撰写、CRM系统更新等具体动作;
• 记住用户的偏好,关注什么,并应用在关键的沟通上。
这些维度的结合,决定了Agent的智能化水平,也决定了产品是否真正具备“自主协作”的能力。
因此,产品经理在设计Agent产品时,可以围绕这三大核心维度设问:
• “我的Agent真正理解了用户和任务吗?”
• “它能不能根据情况自主做出选择?”
• “它是否能和系统高效协同,顺利完成任务链条?”
这种思考方式,能够帮助我们从功能视角转向系统视角,从而设计出更具生命力和可扩展性的AI产品。
从某种意义上说,Agent化的过程,就是让AI应用从“工具”走向“伙伴”的过程 —— 它不再只是“帮你做”,而是“替你想、为你做”。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1499
1499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









