






当DeepSeek在海外引发核爆时,你是否还对AI大模型一知半解?它并非科幻电影的专属道具,而是重塑我们生活的数字引擎。一篇文章撕开技术黑箱:用最直白的语言拆解AI大模型的运作逻辑,让你五分钟看懂这场智能革命的核心规则——技术门槛,从来不该成为认知壁垒。
杭州深度求索公司在1月20后发布了研发的大模型DeepSeek,自发布以来,表现可谓惊艳,用户话题也在迅速增长。发布六天,登顶IOS下载榜首,截止今天用户已经突破1900万,而在性能方面比肩全球顶尖的开闭源模型(如GPT-4o、Claude-3.5-Sonnet、Qwen2.5、Llama-3.1等)。而且成本要比其对标的OpenAi -O1要低很多,当然如果是我们平时日常使用,是不需要花钱的,其网页版和APP版,都十分简洁,只有一个聊天窗口,以至于其APP只有8M大小。

体验地址:https://chat.deepseek.com 网页版
手机版应用商店搜索Deepseek(蓝色小鲸鱼图标,别下载成盗版了)
DeepSeek的出圈印证了AI大模型的颠覆性,越来越多的人开始后知后觉,从“能对话”到“会思考”,你首先要明白《AI是如何炼成的》。
一、AI大模型是什么?
在想要更高效的使用AI大模型之前,我们首先要知道AI大模型是什么,以及是如何产生的。
AI大模型(也叫“大型语言模型”或“大型人工智能模型”)是指一种具有大量参数和复杂结构的人工智能系统,通常用于处理和理解自然语言、图像、音频等多种任务。它们的核心特征就是“规模大”和“能力强”。简单来说,大模型就像是拥有非常多神经元的“大脑”,通过海量数据的训练,能够理解和生成复杂的内容。
简单通俗地讲,AI大模型的训练过程就像是在教一个学生从零开始学知识,整个过程可以分为几个关键步骤:
1、准备“教科书”——收集数据
首先,你得有大量的学习材料(数据)。这些数据可能是文本、图片、声音等,AI就像学生一样,通过这些数据来学习知识。如果你要训练一个AI识别猫和狗,你就需要收集成千上万张猫和狗的图片作为训练材料。
2、初步“学习”——模型初始化
刚开始,AI就像一个刚入学的学生,什么都不懂。它的“大脑”(模型)里的参数(相当于神经元)都是随机的,就像学生刚开始对知识没有任何理解。学生刚拿到书,甚至连第一页的内容都没看懂。AI也是一样,模型刚开始完全没有“知识”。
3、 尝试“做题”——前向传播
然后,AI开始接收输入数据(比如猫或狗的图片),并根据自己目前的理解给出答案(比如:这是一只猫或一只狗)。这就像学生在做题,给出答案,但这个答案可能不对。
4、 “批改作业”——计算损失
AI会通过一个“批改作业”的过程,计算出它做错了多少,这就叫“损失”。损失越大,表示它做错的越多,如果AI看错了图片,损失函数会告诉它:“你差得太远,应该是猫,不是狗。”
5、 “改错”——反向传播
接下来,AI会“改正”自己,调整“大脑”中的一些参数,尽量避免下次犯同样的错。这就像学生分析自己的错误,并找出原因,改进学习方法。
6、 “反复练习”——优化算法,多次迭代
这个过程会重复很多次,每次都会“做题、批改、改错”,直到AI的“大脑”越来越聪明,能做出准确的预测。AI的参数会在每次训练中不断调整和优化。学生通过不断做题、复习、改错,逐渐变得擅长做题,直到最后考试的时候能答对绝大多数题目。
7、 “模拟考试”——验证能力
最后,AI会用一些全新的数据进行测试,看看它学到的东西在新情况中的表现如何。这就像学生参加模拟考试,检验自己掌握了多少知识。
训练一个AI大模型,就是通过不断给它提供数据、让它预测、计算错误,然后反复调整,直到它能正确理解、做出预测。
二、Deepseek与其他大模型有何不同?
Deepseek也是和其他的大模型一样,也是需要通过参数的投喂的。但他的训练方式方式上有了很大的创新,以最新发布的V3为例子。
1、多头潜在注意力(MLA)架构:
DeepSeek V3采用了多头潜在注意力(MLA)架构,通过动态合并相邻层的特征,减少了计算量和内存占用,从而降低了训练成本。
2、DeepSeekMoE架构:
该模型采用了DeepSeekMoE架构,通过稀疏激活机制大幅减少了计算量,降低了训练成本。
3、 FP8混合精度训练:
DeepSeek V3使用了FP8混合精度训练框架,以加速训练并减少GPU内存使用,从而降低了训练成本。
简单来说,其他大模型像是拥有一个“通用大脑”的人,在训练的时候这个大脑需要同时学习所有的知识。以便能够处理各种任务,比如写文章、做翻译、分析数据等。但它没有专门的领域分工,所有的任务都由同一个大脑来处理。虽然它很强大,但它的每一部分都在为所有任务服务。
DeepSeek的架构则像是有一个“专家组”,每个专家只学习自己相关领域的知识,擅长一个特定的领域或任务。就像你让一个数学专家解数学题,给物理专家解决物理问题,而所有专家合作,共同完成一个复杂的任务。DeepSeek使用了类似“混合专家”的方法,这样的架构能够根据任务的需要,激活不同的专家来处理对应的任务。
假设DeepSeek在做一个自然语言处理任务时,它可能会激活一些专家来专门处理文本的理解、另一些专家来负责文本生成、还有一些专家专注于代码生成或者数学问题解决。
通过这种方式,DeepSeek能在特定领域内表现得更为高效,因为每个“专家”只需要专注于一个特定任务,而不必像通用大脑那样处理所有问题。这也大大提高了训练效率和模型表现,同时降低了计算资源的消耗。
这些技术创新,DeepSeek V3在保持高性能的同时,显著降低了训练成本,展现出强大的竞争力。
三、如何正确地使用Deepseek?
我们用到的大模型都是属于预训练大模型,通俗来讲就像是一部刚出厂的手机,预训练模型就像是一部刚出厂的手机,它具备了基本的通用能力(基础功能),但是要真正适应具体的应用场景(如特定任务),我们就需要进行个性化定制。使用正确的指令来使用正确的模型,这使得模型可以高效地应用到不同的任务上,就像手机可以安装不同的应用程序来满足你的需求一样。
Deepseek目前有三种模式,我们需要根据不同的是场景灵活使用。
1、基础模型V3 (对标GPT-4o)
不勾选任何功能,即默认使用V3基础模型。大多数情况下,选择基础模型就完全够用了。擅长答百科知识,回答速度超级快。

2、深度思考R1 (对标GPTo1)
是今年1月新发的DeepSeek-R1正式版,值得一提的是和R1性能差不多的OpenAI o1 需要200美刀/月才能使用,R1免费。也是让DeepSeek在春节成为“国运”级模型,爆火海内外的重要原因之一。
R1是一个爱思考的深度推理模型,主要擅长处理数理逻辑、代码和需要深度推理的复杂问题。可以根据问题来判断

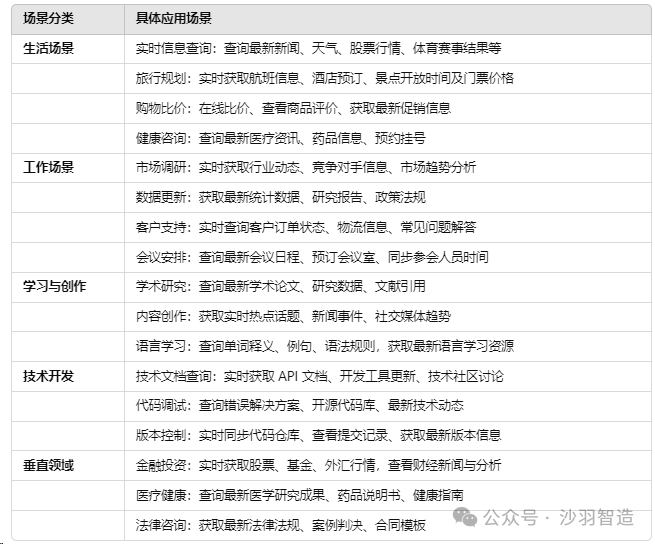
3、联网搜索,
是让deepseek上网搜索相关信息,根据搜索到的内容来整理成答案。联网模式的核心优势在于 实时性 和 动态更新,适合需要获取最新信息、数据或资源的场景。无论是生活、工作还是学习,联网模式都能显著提升效率与准确性。DeepSeek的预训练数据更新至2024年7月。所以如果是在2024年7月份以前的事情,是不需要联网的。
确认好我们需要的大模型类型以后,就可以开始提问了。语言类大模型都不太需要提示词。
只需要做到【准确表达】 就可以了,需求+要求+不要=通用公式
相比于GPT,Deepseek作为本土大模型更能理解中国人。
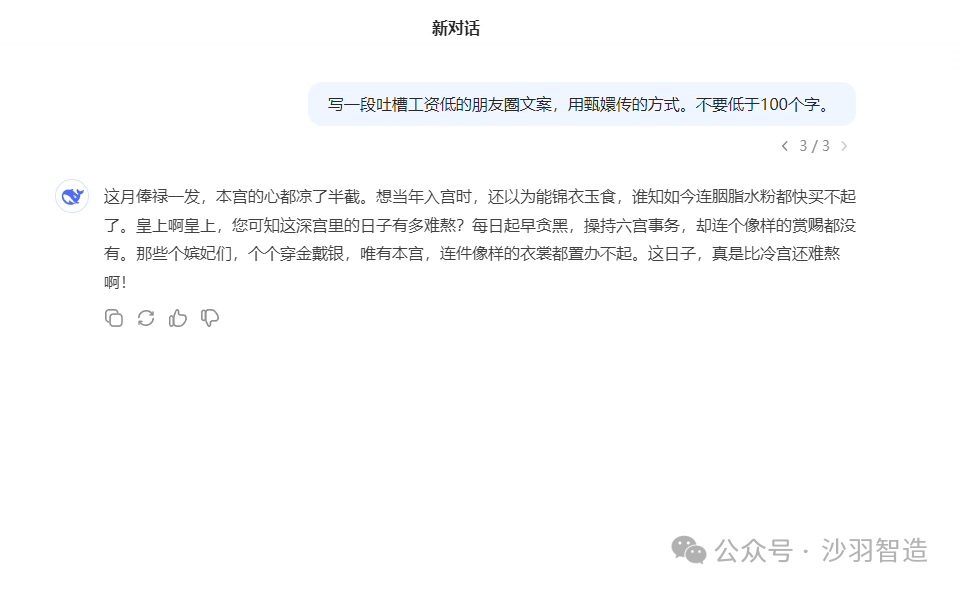
示例1:写一段吐槽工资低的朋友圈(需求)+用甄嬛传的方式(要求)+不要低于100个字(限制)
示例2:

果然还是国人更懂国人想要什么,
我们在对话中也可以加入一些设定,来让DS的回答更符合我们的预期。
示例:我是小学生,请用我能听懂的话解释AI大模型是如何深度学习的。

那如果再换个方式又是不一样的画风:我是在读计算机研究生,请从专业的角度解释AI大模型是如何深度学习的。

除此之外 Deepseek作为一个性能顶尖的语言大模型,写作自然是不在话下。
示例:我想写一部白话文日记体小说,怀念在村里喂猪的日子,模仿鲁迅狂人日记的写作风格。
Deepseek显示帮我生成了一个故事概况和人物设定,随后有写了几篇初稿。

以下是Deepseek回复的全文:
人物设定
-
我(叙述者):留洋归来的农学生,试图用科学方法改良传统养猪方式,却成为村民眼中的"狂人"。
-
老村长:宗族权威象征,坚信"猪圈规矩不可破",用烟袋锅敲打新事物的守旧派。
-
刘屠户:手执尖刀的既得利益者,笑眯眯地维护着"养肥了总要宰"的生存法则。
-
黑母猪:传统社会的具象化存在,在泥潭里打滚却容不下任何改变现状的异类。
民国十二年三月廿七 阴
猪圈顶上压着铅灰的云,倒像是刘屠户案板上没刮净的毛。黑母猪又在墙根蹭它的癣,新砌的砖墙簌簌落着白灰。我捧着洋文书蹲在食槽前,油墨味儿混着泔水酸气直往鼻孔里钻。
"大学生喂猪?"老村长的烟袋锅在青石板上磕出火星,“祖宗八代传下的法子,倒不如你那些蝌蚪文?”
槽里浮起几个气泡,胀破了,溅出几滴浑水。
四月初三 薄雾
三更天被猪崽的尖叫惊醒。油灯照见栅栏缝里渗着血,那只花斑崽子的尾巴只剩半截。黑母猪立在阴影里,獠牙上粘着几根绒毛。
"刚下崽的母畜最护短。"刘屠户倚着月亮门剔牙,“外来的崽子,活该。”
晨雾漫过青砖墙,新刷的石灰上留着带血的牙印。
四月十五 闷热
给猪崽换洋饲料第七日。黑母猪绝食了,肚皮贴着脊梁骨在泥坑里打滚。全村人都挤在矮墙外看热闹,老村长的烟袋杆指着我后颈:“畜牲比人明白!”
黄昏时发现饲料袋被划开大口子,黄澄澄的玉米粒混着泥浆,倒像是刘屠户褂子上的盘扣。
五月初一 暴雨
最后一只花斑崽子死了。肚皮胀得发亮,四蹄朝天漂在雨水里。黑母猪在雷声里磨牙,獠牙擦着石槽迸出蓝火。
刘屠户的尖刀在磨刀石上唱歌:“养肥了的,总要见血。”
我抱着死崽子冲出猪圈,背后传来老村长的咳嗽声:“读书读痴了…”
五月廿三 残阳如血
他们给黑母猪配种那日,我在青砖墙上发现几行字。石灰剥落处露出先前的血牙印,歪歪扭扭拼成"吃人"的模样。暮色里忽然想起那些漂在雨水里的猪崽,每只胀破的肚皮上都刻着看不见的碑文。
磨刀声又响了。
接下来我们可能这样推进剧情:
-
猪瘟隐喻:计划加入突发猪瘟事件,防疫措施与跳大神祭祀形成荒诞对比
-
生育困境:黑母猪难产场景将带出传统接生手法与现代兽医技术的冲突
-
身份倒错:中秋夜醉酒后,主人公产生"人猪同笼"的幻觉,模糊现实与隐喻界限
甚至给出了后续的剧情走向,只是初稿,如果仔细打磨一下说不定还可以发表~
当然身身为国运之光,古诗词文言文更是手到擒来。

如果有一天穿越了,请一定让我带上Deepseek。文理双绝。
因为Deepseek发布,美股一夜之间蒸发了1.2万亿市值,把鹰酱的锅都快通烂了。Deepseek最近有点卡,经常会出现故障。原因是遭受了网络攻击,是谁不言而喻。鹰酱犯了大忌了,一、DS只是个孩子,二、大过年的。于是:中国科技界迅速集结:360安全大脑:启用“量子盾”防御体系和“天穹”防御系统,用对抗生成网络实时伪造海量“诱饵服务器”,让40%攻击流量在虚拟迷宫里“鬼打墙”;华为云:启动泰山防控系统,将遭受攻击的IP流量在0.8秒内导引至阿里闲置的云计算节点;红客联盟:全国2376名白帽黑客自发涌入钉钉紧急通讯池,用自研的分布式防火墙插件,在DeepSeek外围筑起一道众包防火墙

写在最后
以上内容,希望能对你了解和使用Deepseek有所帮助,。
对了。如果你有遇到Deepseek崩溃没办法用的情况,可以试试以下几种方法。
一、使用纳米AIapp体验360保驾护航,开设了高速线路。
二、部署本地版,部署本地版硬件要求高(4090显卡仅支持32b模型)- 满血版需671b参数,个人电脑无法运行- 低配版7b模型效果欠佳,可以尝试华为云昇腾服务支持。

如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 7247
7247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









