






U-FLOOD – Topographic deep learning for predicting urban pluvial flood water depth
摘要
这篇文章研究了如何使用深度学习预测城市内涝事件中的二维最大水深图。旨在快速预测训练集中没有包含的降雨事件和空间位置的积水深度。并对深度学习模型在预测二维洪水地图时应考虑哪些空间输入变量进行了综合评估。
正文
案例区域
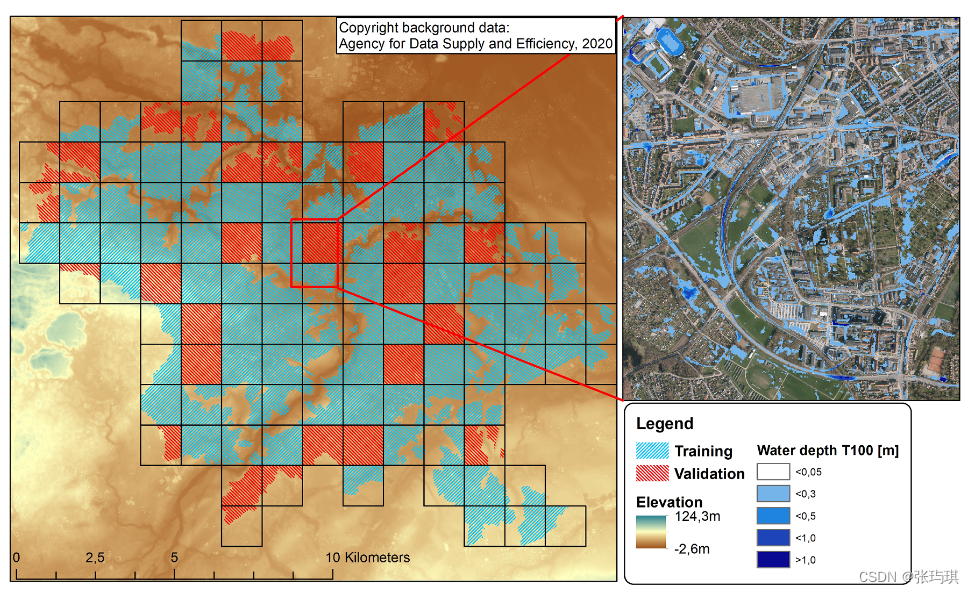
使用 MIKE 21对整个区域进行了二维水动力模拟。考虑二维表面每个像素的降雨情况,并对每个像素做径流计算(假设建筑物和道路 100%不透水,所有其他区域均为透水区域,计算每个像素点内部的透水和不透水区域。我们假设每次降雨的湿润损失为 0.6 毫米,不透水区域降水的最大下水道系统容量为 12 毫米/小时,透水区域降水的恒定下渗容量为 29.3 毫米/小时。在每个模拟时间步长内,通过从观测降雨量中减去上述损失,分别计算出透水区和不透水区的有效降水率。在每个象素中,将两个有效降水率乘以象素内的不透水和透水面积,然后求和得出象素的总径流量。随后,通过二维水动力模拟将径流流经地形表面。这种径流计算方法能生成逼真的洪水地图,可用于证明我们的深度学习方法的可行性。)
对53次降雨时间做水动力模拟,将0.05m以下的水深设为0,去除水坑(定义为由少于 5 个相连像素组成的水淹区域)
数据集
数据集包括53幅洪水地图(每个降雨事件一幅图),覆盖整个研究区域。对于模拟区域外的像素(图 1 中既非红色也非蓝色),输入和输出数据均设为零。
训练集是通过随机抽样降雨事件和256x256的网格创建的,通过以下方式进行10000次采样:
a) 从 48 个未用于验证的降雨事件中随机选取一个(重复采样,即无论该事件是否在之前的迭代中被选中);
b) 在研究区域内的任意位置随机选取一个网格(256x256 像素)。
然后检查该区域是否包含图 1 中蓝色区域以外的区域。这些区域要么不属于模拟区域,要么属于验证数据(图 1 中的红色区域),不参与训练,相应像素的输入数据和洪水深度被设为 0。如果网格中包含的有效像素少于 20%,则将其舍弃,并采样一个新网格。否则,该网格将被添加到训练数据集中。
验证集是将研究区域分为119个固定位置的256x256网格(图 1 ),每个网格至少包含20%模拟区域的像素(图 1 中的蓝色和红色),随后:
a)随机选择其中 29 个正方形(研究区域的 1/4)(在图 1 中用红色标记);
b)手动选择五个降雨事件,这些事件反映了不同的降雨强度和时间降雨模式。
总的来说,验证数据集由 29*5 = 145 个洪水图组成。
模型
概述
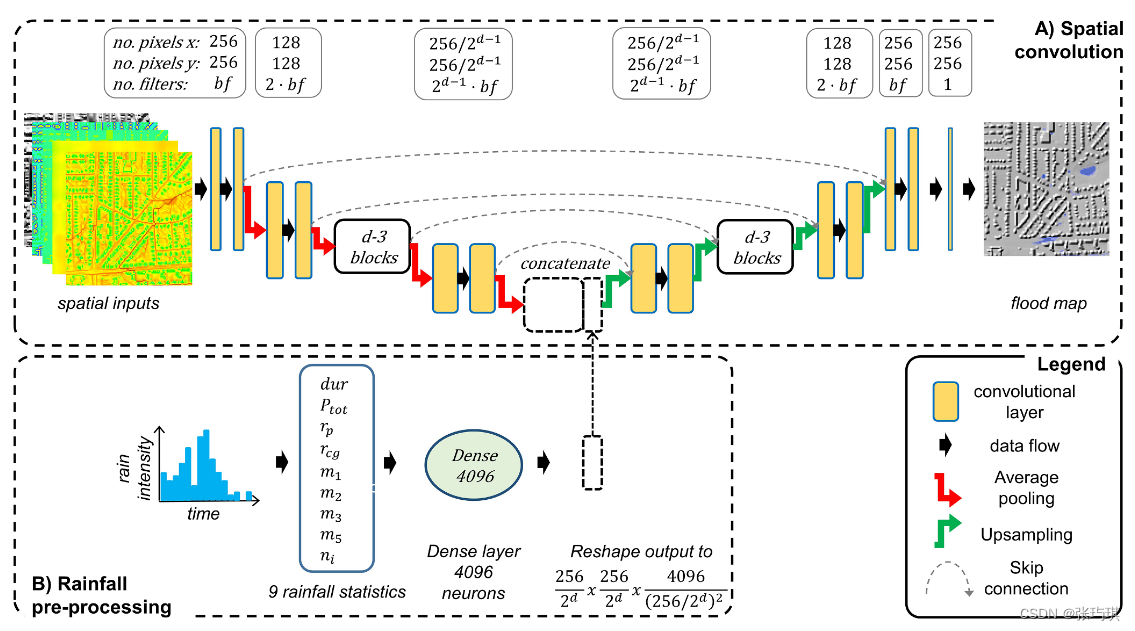
总体结构类似于 (Guo, Z., Leit ̃ao, J.P., Sim ̃oes, N.E., Moosavi, V., 2021. Data-driven flood emulation: speeding up urban flood predictions by deep convolutional neural networks. J. Flood Risk Manag. 14, e12684. https://doi.org/https://doi.org/10.1111/jfr3.12684.)提出的框架,但做了一些改动:
1.残差连接将空间卷积中的编码块的输出连接到相应解码块的输入,从而绕过网络较深部分的编码步骤。
2.在将输入降雨序列输入神经网络之前,我们将输入降雨序列转换为一组 9 个降雨事件特征(直接输入会因为长雨事件参数过多,且峰值时间点不定而难以训练)。
3.用平均池化而非最大池化。
三个超参数:
d - 网络深度,本文为5
bf - 第一个编码步骤的卷积层的过滤器数量,每个编码步骤过滤器数量变成2倍,最大512,本文为64
k - 卷积核边长(以像素为单位),本文为3
特征选择
将降雨数据分解:
rp - 降雨峰值相对于事件总持续时间的时间指数
rcg - 累积降雨量中位数相对于事件总持续时间的时间指数
m1 - 降雨峰值前后累积降水量之比
m2 - 最大降雨强度(10 分钟间隔)与总降雨深度之比
m3 - 事件前三分之一时间段降雨深度与总降雨深度之比
m5 - 事件前半段降雨深度与总降雨深度之比
ni - 最大雨强(10 分钟间隔)与平均雨强之比
从地理数据中导出11个空间变量:
DEM - 包括建筑物在内的表面高程
ASP - 地形上的流向
CURV - 地形的凹性/凸性
DEM_L - DEM 减去半径 100 米内 DEM 的焦点平均值,即积水应与当地的海拔高度变化有关
SDEPTH - 水槽的水深,根据水槽出口点高程与地形高程之差计算,所有汇水区外的网格均为 0。
IMP - 每个网格(raster cell,像素?)的不透水度
SLOPE - 地形坡度
FLACC - 流入指定像素的单元数(cells)?没太懂,我的理解是一个区域内可能受到洪水影响的像素点数量
FLIMP - 给定单元(cell)上游的不透水总面积
FLSLO - 每个单元中按 SLOPE 加权的流量累积。用于表示路径上的平均流速
TWI - 入渗和径流比例,衡量一个地区积聚径流的趋势。
好像经过验证后只用了ASP, CURV, DEM_L, IMP, FLACC
实验

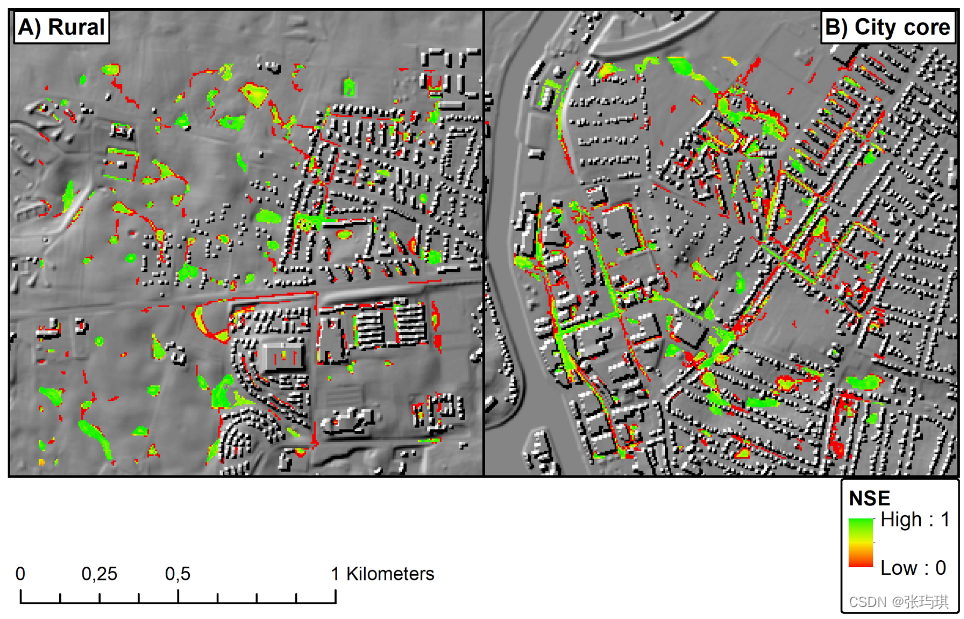
10 号降雨事件(验证集)。神经网络未能预测水深大于 0.05 米的区域用红色标出,而神经网络错误预测水深大于 0.05 米的区域用黄色标出。左图是市区,右图是郊区,从这两幅图中可以明显看出神经网络预测的几个特点:
1.神经网络并没有预测出完全不合理的水深。这一点很重要,因为神经网络的数学公式没有考虑质量平衡等物理限制因素。
2.神经网络可以识别积水的洪水易涝点,并能准确预测这些地点的水位。
3.该网络无法准确表示沿运输路段(即汇水区外)的浅洪水。这种情况在下图中尤为明显,在下图中,NSE 值较低的位置集中在道路沿线的水流路径上,这也是神经网络持续低估洪水总面积的原因。
分析了验证集5种降雨事件的积水结果,44和47号尽管最大雨强分别为34mm/hr和16mm/hr,但是不会出现积水,9和10号准确,39号积水量较低,这是由于所有降雨事件中只有39号有两个强度相似的降雨峰值,即还是要提供更多有代表性的降雨事件去训练。
讨论
预测洪水水深的 RMSE 分数(0.08 米)与现有筛选方法相似,CSI 分数较低,约为 0.5。值得注意的是,我们的结果是针对自然降雨事件和训练阶段未考虑的地点得出的,这与其他侧重于人工设计暴雨或已知地点的研究不同。洼地中的水深一般都能很好地预测,而洼地外地表水流路径上浅层洪水的预测仍然是一个挑战。
局限性
如下所述,这些因素限制了 UFLOOD 当前配置的可移植性:
1.考虑不同的渗透率需要额外的空间输入数据集。
2.降雨量在空间的非均匀分布。需要注意的是,U-FLOOD 的训练目的是预测流域范围在 2 km 左右的冲积洪水。在这样的尺度上,通常假定降雨在空间上是均匀的,以便在基础设施设计中进行洪水筛选,而气象模型(作为洪水预警系统的输入)几乎不会生成分辨率小于几千米的预报。
3.下水道系统容量不均匀
4.训练中排除了河流洪水

















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









