







1. 目的与意义
遥感己被广泛应用于地质监视,气象监测,军事情报收集,环境保护,农情普查等众多领域。遥感图像分割旨将遥感图像所描述的复杂地物信息中感兴趣的地物类别划分为具有语义的闭合区域。人工目视解译方法效率低下,且高度依赖于实地调查及先验知识,消耗巨大人力物力且不符合智能时代的需要。因此可以结合深度学习分割遥感图像。深度学习中,有关语义分割这一领域,神经网络的训练需要大量的数据集,最终才能在实际应用中产生很好的效果。问题便来了,数据集的制作实际上也是通过人工来制作的,这是非常费时费力的一件事,且精确度也无法保证。因此如何利用现有的资源去通过程序产生数据集便是本文的想法。
2. 现状
2.1 制作数据集(人工方法)
目前人工制作数据集一般也是使用软件,比如 Arcgis , 这里仅简要介绍一下,参考文章 利用Arcgis制作遥感图像深度学习语义分割标签 , 大概流程就是:选取图像、编辑图像(区域选择、形成闭环)、打标签、系统转化形成栅格化数据。

2.2 现有数据集
已有数据集有三十多个,参考博文:深度学习中的遥感影像数据集~持续更新
表格数据:
| 数据集名称 | 图像大小 | 类别数 | 图像总数 | 数据源 | 发布时间 | 发布组织 |
|---|---|---|---|---|---|---|
| Massachusetts Roads | 1500 × 1500 × 3 1500 \times 1500 \times 3 1500×1500×3 | 1 | 804 | 航空影像 | 2013 | University of Toronto |
| Massachusetts Builds | 1500 × 1500 × 3 1500 \times 1500 \times 3 1500×1500×3 | 1 | 151 | 航空影像 | 2013 | German Aerospace Center (DLR) |
| Zurich Summer | ( 600 ∼ 1600 ) × ( 600 ∼ 1600 ) × 4 (600\sim1600) \times (600\sim1600)\times 4 (600∼1600)×(600∼1600)×4 | 8 | 20 | QuickBird | 2015 | The University of Edinburgh, Scotland (UK) |
| ERM-PAIW | 400 0 ± × 400 0 ± × 3 4000_{\pm} \times 4000_{\pm}\times 3 4000±×4000±×3 | 1 | 41 | 航空影像 | 2015 | German Aerospace Center (DLR) |
| HD-Maps | 400 0 ± × 400 0 ± × 3 4000_{\pm} \times 4000_{\pm}\times 3 4000±×4000±×3 | 4 | 20 | 航空影像 | 2016 | German Aerospace Center (DLR) |
| BDCI2017 | 800 0 ± × 800 0 ± × 3 8000_{\pm} \times 8000_{\pm}\times 3 8000±×8000±×3 | 5 | 5 | 佳格天地 | 2017 | BDCI |
| Learning Aerial Image Segmentation From Online Maps | 300 0 ± × 300 0 ± × 3 3000_{\pm} \times 3000_{\pm}\times 3 3000±×3000±×3 | 2 | 1,671 | Google Maps、OpenStreetMap | 2017 | TH Zürich |
| 2018 Open AI Tanzania Building Footprint Segmentation Challenge(TBF) | 4000 0 ± × 4000 0 ± × 3 40000_{\pm} \times 40000_{\pm}\times 3 40000±×40000±×3 | 1 | 13 | 航空影像 | 2018 | SUZA |
| WHDLD | 256 × 256 × 3 256 \times 256 \times 3 256×256×3 | 6 | 4,940 | UC Merced | 2018 | 武汉大学 |
| DLRSD | 256 × 256 × 3 256 \times 256 \times 3 256×256×3 | 21 | 2,100 | USGS National Map | 2018 | 武汉大学 |
| DeepGlobe Land Cover Classification Challenge | 2448 × 2448 × 3 2448 \times 2448\times 3 2448×2448×3 | 7 | 803 | DigitalGlobe | 2018 | CVPR |
| DeepGlobe Road Detection Challenge | 1024 × 1024 × 3 1024\times 1024\times 3 1024×1024×3 | 1 | 6,226 | DigitalGlobe | 2018 | CVPR |
| Aeroscapes | 720 × 720 × 3 720\times 720\times 3 720×720×3 | 11 | 3,269 | 航空影像 | 2018 | Carnegie Mellon University |
| Map Challenge | 300 × 300 × 3 300\times 300\times 3 300×300×3 | 1 | 341,058 | Google Map | 2018 | crowdAI |
| 38-Cloud: A Cloud Segmentation Dataset | 384 × 384 × 4 384\times 384\times 4 384×384×4 | 1 | 8,400 | Landsat 8 | 2018 | Science Simon Fraser University |
| WHU Building Dataset,Satellite dataset Ⅰ (global cities) | 512 × 512 × 3 512\times 512\times 3 512×512×3 | 1 | 204 | QuickBird, Worldview series, IKONOS, ZY-3 | 2019 | 武汉大学 |
| WHU Building Dataset,Satellite dataset Ⅱ (East Asia) | 512 × 512 × 3 512\times 512\times 3 512×512×3 | 1 | 17,388 | QuickBird, Worldview series, IKONOS, ZY-3 | 2019 | 武汉大学 |
| WHU Building Dataset,Aerial imagery dataset | 512 × 512 × 3 512\times 512\times 3 512×512×3 | 1 | 8,189 | 未知 | 2019 | 武汉大学 |
| DroneDeploy | 600 0 ± × 600 0 ± × 3 6000_{\pm} \times 6000_{\pm}\times 3 6000±×6000±×3 | 7 | 35 train, 8 val, 12 test | 航空影像drones | 2019 | DroneDeploy |
| RoadTracer | 4096 × 4096 × 3 4096\times 4096\times 3 4096×4096×3 | 1 | 3,000 | Google earth、OSM | 2019 | MIT |
| ORSSD | 50 0 ± × 50 0 ± × 3 500_{\pm} \times 500_{\pm}\times 3 500±×500±×3 | 8 | 600train,200test | Google Earth | 2019 | 北京交通大学 |
| EORSSD | 50 0 ± × 50 0 ± × 3 500_{\pm} \times 500_{\pm}\times 3 500±×500±×3 | 8 | 1,400train, 600test | Google Earth | 2020 | 北京交通大学 |
| Land Cover from Aerial Imagery(landcover_ai) | 9000 × 9500 × 3 , 4200 × 4700 × 3 9000 \times 9500 \times 3,4200 \times 4700 \times 3 9000×9500×3,4200×4700×3 | 3 | 41 | public geodetic resource | 2020 | linuxpolska |
| UAVid | 4096 × 2160 × 3840 × 2160 × 3 4096 \times 2160 \times 3840 \times 2160 \times 3 4096×2160×3840×2160×3 | 8 | 300 | public geodetic resource | 2020 | linuxpolska |
| 95-Cloud: An Extension to 38-Cloud Dataset | 384 × 384 × 4 384 \times 384 \times 4 384×384×4 | 1 | 34,701 | Landsat 8 | 2020 | Simon Fraser University |
| AI+遥感影像 | 256 × 256 × 3 256 \times 256 \times 3 256×256×3 | 8 | 100,000 | 未知 | 2020 | 全国人工智能大赛组委会 |
| BDCI2020 | 256 × 256 × 3 256 \times 256 \times 3 256×256×3 | 7 | 145,981 | 未知 | 2020 | BDCI |
| mini Inria Aerial Image Labeling Dataset | 512 × 512 × 3 512\times 512\times 3 512×512×3 | 1 | 30,000 train, 2,500 test | 未知 | 2020 | 天池大赛 |
| Postdam | 6000 × 6000 × 3 6000 \times 6000 \times 3 6000×6000×3 | 6 | 38 | 航空影像 | 2012 | ISPRS |
| Vaihingen | ( 1000 ∼ 4000 ) × ( 1000 ∼ 4000 ) × 3 (1000\sim4000) \times (1000\sim4000)\times 3 (1000∼4000)×(1000∼4000)×3 | 6 | 33 | 航空影像 | 2012 | ISPRS |
| GID Fine Land-cover Classification_15classes | 7200 × 6800 × 4 , 7200 × 6800 × 3 7200\times 6800 \times 4,7200\times 6800 \times 3 7200×6800×4,7200×6800×3 | 15 | 10 | 高分2 | 2018 | 武汉大学 |
| GID Large-scale Classification_5classes | 7200 × 6800 × 4 , 7200 × 6800 × 3 7200\times 6800 \times 4,7200\times 6800 \times 3 7200×6800×4,7200×6800×3 | 5 | 150 | 高分2 | 2018 | 武汉大学 |
| UDD5 | 409 6 ± × 216 0 ± × 3 4096_{\pm} \times 2160_{\pm}\times 3 4096±×2160±×3 | 5 | 120 trian,40 val | 无人机数据(DJI Phantom 4) | 2018 | 北京大学 |
| UDD6 | 409 6 ± × 216 0 ± × 3 4096_{\pm} \times 2160_{\pm}\times 3 4096±×2160±×3 | 6 | 106 trian,35 val | 无人机数据(DJI Phantom 4) | 2018 | 北京大学 |
| BH-POOLS | 3840 × 2160 × 3 3840 \times 2160\times 3 3840×2160×3 | 1 | 200 | GoogleEarth | 2020 | Federal University of Minas Gerais |
| BH-WATERTANKS | 3840 × 2160 × 3 3840 \times 2160\times 3 3840×2160×3 | 1 | 200 | GoogleEarth | 2020 | Federal University of Minas Gerais |
| rscup | 7200 × 6800 × 4 7200 \times 6800\times 4 7200×6800×4 | 16 | train 8, val 2, test 10 | 高分二号MSS影像 | 2020 | rscup组委会 |
| suichang dataset | 256 × 256 × 4 256\times 256\times 4 256×256×4 | 10 | 16,017 | 高分系列 | 2021 | 浙江大学、天池大赛 |
| LRSNY | 1000 × 1000 × 3 1000 \times 1000 \times 3 1000×1000×3 | 1 | 716 train, 220 val, 432 test | 未知 | 2021 | IEEE |
2.3 分布图

结合表格和上图总结了一下它们的异同.
共同点:
- 同一粒度下,数据集数量不是很多,比如分辨率超过4k的数据集几乎数量不超过100,当然也有极个别还是很多的,但是仔细观察会发现它们的类别很少,如果只是看细粒度,比如 256×256 的数据集,这种数据量就比较大了,但是对于大图来说,切割成小图后同样可以产生这样的效果,因此这里主要以大尺寸图像来衡量数据集的大小。
- 类别数量不是很多,要么是对单一对象进行识别,比如道路或者水域,要么就是其它特定的物体,更细致的一些对象,比如飞机、车等等。
不同点:
- 图像针对的对象差异还是挺大的,其中道路的类别最多,至于其它类别就五花八门了。
3. 应用场景
结合上述的异同点,可以看出现有的数据集要么是针对识别频率较高的一些对象,要么是具体的一些特定对象(比如海域中就牵扯到一些船只的识别),因此当涉及到各领域的具体问题时,上述公开的数据集无法满足实际任务的需求,比如在地球物理中,当需要获取地质信息时需要布设炮点,其位置需要避开障碍物,因此我们可以利用遥感影像识别出障碍物以找到合适的位置布置炮点。对于炮点的布置,通常来说环境是处在比较偏远的一些地方,因此障碍物的类别主要其实就是房屋、水域、道路,但是这里会涉及的更加细致。比如道路类别下有铁路、公路、小路等等,每种类别对于炮点的布置影响都是不一样的。所以数据集的类别需要更具体、更可变。
4. 想法
第一节已经提到通过程序去制作数据集,那么从数据集制作再到应用的一个流程如下:

4.1 数据集制作的效果

4.2 模型预测效果
目前使用的模型是DeepLabV3Plus,整个网络模型的结构图如下:

空洞卷积:
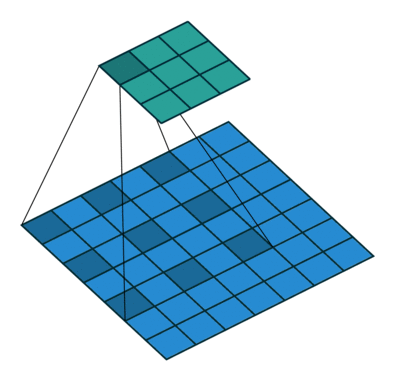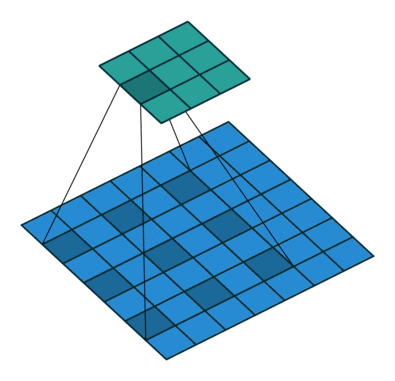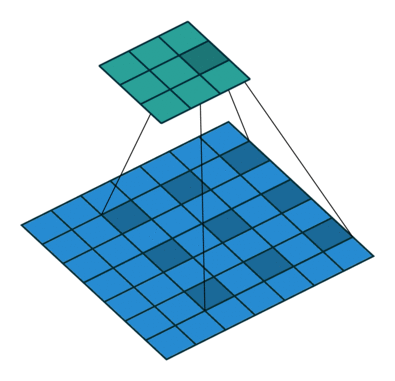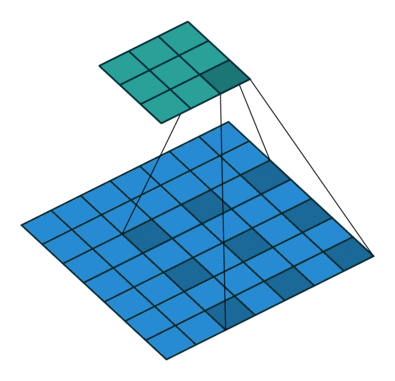
训练数据使用了五张原始图像,切割成小图后大概有七万多张,由于模型还未训练完成,因此只取用了当前跑完epoch的权重用来预测,效果如下:

5. 优点以及问题
对于上述所说的具体任务,由于原图和电子地图是由软件产生的,因此可以结合软件的功能,将里面的道路按级别划分,包括建筑物以及河流都有更细致的类别,满足实际任务的需要,对于哪种目标需要识别出来,我们就可以针对这类物体制作对应的数据集,再用于训练模型,最终投入应用。
问题也有,比如电子地图并不是标注的特别准确,比如 效果 这一节中的电子地图,可以看到里面的水域以及一些道路并未标注出来,因此选取合适的区域对于数据集的制作也很重要。
6. 衡量标准
目前仅是粗略想法,通过与上述列出的数据集做对比试验,在不同的数据集上针对同一类别物体的识别,最后看其精度以及效果如何。
7. 意义
该方法主要是为了减少数据集制作这一步骤所花费的人力物力,利用现有的电子地图转化为标签图,最终投入到神经网络的训练中去,因此也可以理解为一个数据生成器,不过该数据的好坏主要取决于地图源,并且通常来说不管什么地图源,对于城市的标注都比较精细,但是对于偏远地区的标注就不是那么准确了,因此,数据集制作集中在城市及其周边的区域。
8. 后续问题及思考(由老板指出)
8.1 任务定位
8.1.1 识别问题,不是布局设计问题
8.1.2 基础识别 (电子地图) 用自己的方法,还是已有的
8.1.3 数据制作 vs. 物体识别
8.2 任务 1: 基于人机交互的地图标注
8.2.1 基本思想
8.2.1.1 模型 (如神经网络) 的效果不是 100% 正确, 需要人工进行干预。或者说,计算机辅助打标签。
8.2.1.2 以前的带标签地图越多,神经网络的效果越好。
8.2.1.3 带冷启动的主动学习 (开始的时候没有带标签数据,只有使用无监督学习算法;随着人机交互,带标签数据越来越多,就可以用半监督学习)
8.2.2 总体思路
8.2.2.1 根据智能算法(无监督或半监督),将地图进行基础识别 (打标签)
8.2.2.2 人工参与,进行标签的修正,并进行迭代
8.2.2.3
- 评价指标 1:最终标签的质量 (计算误差点所占的比例)
- 评价指标 2:打标签修正的次数 (越少越好)
8.2.3 任务的挑战
8.2.3.1 无监督的识别算法 (有现成的,但只有电子地图软件,要找源代码)
8.2.3.2 半监督的识别算法 (自己的重点)
8.2.4 目的
8.2.4.1 进行所给地图的标注
8.2.4.2 对其它地图的标注提供训练数据
8.2.5 价值
8.2.5.1 有实际意义, 为某一个实际领域做基础性、开创性的工作
8.2.6 难点
2.6.1 对于人工产生标注,算法如何进行调整?要么修改原始数据 (颜色、灰度进行区域的填充等),要么修改学习算法的机制 (避障).
2.6.2 如何融合图像分割算法 (无监督) 与神经网络的识别算法 (有监督)?
8.3. 任务 2: 数据集制作
3.1 评价指标: 与其它的数据集质量比较, 很难评价















 5842
5842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









