







Multi-modal Knowledge-aware Reinforcement Learning Network for Explainable Recommendation(用于可解释推荐的多模态知识感知强化学习网络)

摘要
知识图谱(KGs)可以为推荐系统提供丰富的结构化信息,提高准确性并执行显式推理。深度强化学习(RL)也引起了对个性化推荐的极大兴趣。两者的结合在进行可解释的因果推断程序和改进基于图结构的推荐性能方面有很大的潜力。然而,大多数基于KG的推荐系统侧重于异构知识图谱中实体之间丰富的语义关系,因此未能充分利用与实体对应的图像信息。为了解决这些问题,我们提出了一种新颖的多模态知识感知强化学习网络(MKRLN),它通过在多模态知识图(MKG)中提供实际路径来将推荐和可解释性结合起来。MKRLN可以通过组合实体的结构信息和视觉信息生成路径表示,并利用MKG中路径的序列依赖性推断代理-MKG交互的潜在合理性。此外,由于KG具有太多的属性和实体,它们与RL的结合导致强化学习空间中有太多的动作空间和状态,这使得动作空间的搜索变得复杂。此外,为了解决这个问题,我们提出了一种新的分层注意力路径,使用户将注意力集中在他们感兴趣的项目上。这减少了知识图谱中的关系和实体,进而减少了RL中的动作空间和状态,缩短了到目标实体的路径,并提高了推荐的准确性。
一、介绍

用户通常先看海报再看介绍,最后决定看不看该电影,说明图片含有信息,有利于更好的推荐。
一种用于解释推荐系统的多模态方法。代理从用户开始,并在多模态知识图(MKGs)上进行多跳逻辑路径,以发现适合向目标用户推荐的项目。如果代理基于逻辑路径向用户推荐项目,解释推理过程会很容易,因为可以解释导致每个推荐的MKG上的推理过程。因此,系统可以提供两方面的因果证据,即视觉和知识,支持推荐项目。因此,我们系统的目标不仅是为用户推荐候选项目,还要提供相应的解释逻辑路径在MKG中。逻辑路径包含视觉和知识,作为解释给定推荐的理由。
我们提出了一种多模态知识图谱结合强化学习网络(MKRLN)模型,即一个深度RL模型,结合多模态进行多维解释和推理。然后,我们设计了一种新颖的层次注意力路径,可以大大减少动作空间和过滤噪声。
设计的推荐方法具有三个优点:
首先,我们可以从视觉和知识两个方面提供解释,这两个方面是互补的。代理从用户开始(即链接到一个实体),并进行搜索,以发现沿着知识图谱路径的合适项目。这些多步路径可以提供逻辑原因和深入解释,说明如何向用户推荐项目。图像可以从视觉角度解释原因,而知识可以从外部知识角度解释推荐。
其次,在典型的知识图谱中,一个实体可以与具有相同属性的大量邻居相连接。在这方面,我们提出使用注意力邻居和注意力路径,大大减少大型动作空间和实体的数量。
第三,面对大量项目,用户很难关注他们最关心的项目,因此注意力路径机制可以探索用户真正的偏好并过滤掉多余的信息。
本文贡献
我们提出了一种多模态 KG 与深度 RL 相结合的个性化推荐。 该模型可以从视觉和知识两个方面解释逻辑推理,使解释变得多维度。
我们在多模态知识图谱上设计了一种新颖的层次注意力路径方法,它可以大大减少动作空间、实体的数量,并过滤掉噪音,使用户能够专注于他们最关心的项目。
我们强调了多模态知识图谱对于评估推荐系统性能的重要性,该推荐系统能够使用外部信息对图像内容进行更高知识水平和更明确推理的推荐。
二、相关工作
1.基于知识图谱的推荐
一个方向研究集中在使用知识图嵌入模型进行推荐。
另一个研究方向是根据知识图谱中的实体和路径信息做出可解释的推荐。
2.多模态
3.强化学习
三、方法
1.模型框架
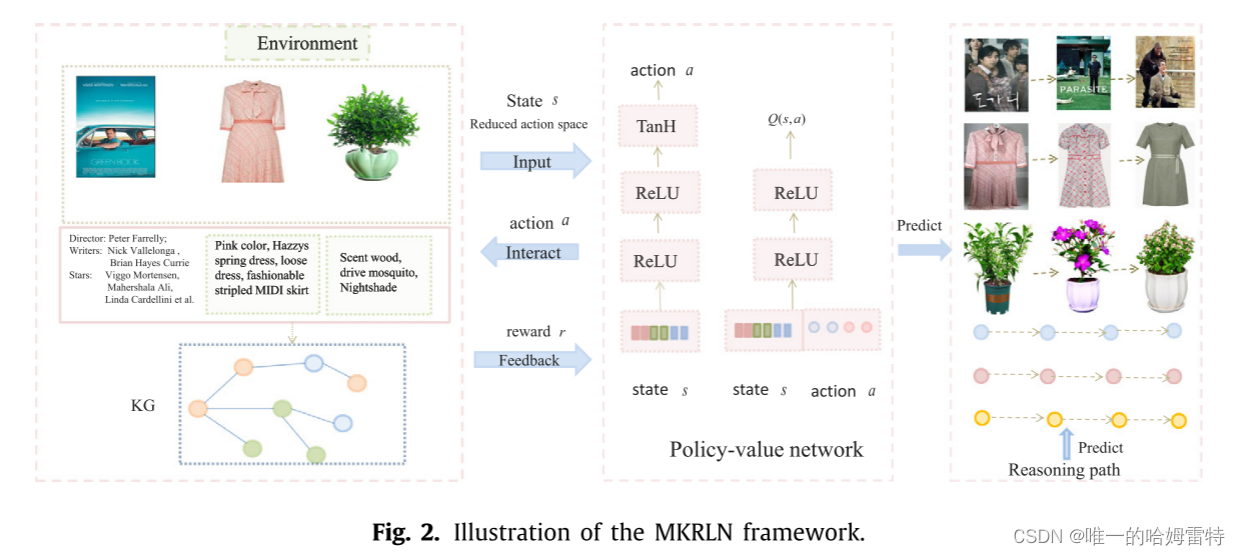
首先,从起始用户选择状态 s 开始,初始状态 s 由实体和图像的级联嵌入组成,然后将状态 s 输入到策略中 网络。 在用户项对之间,通过注意力机制计算用户的暴露邻居的注意力权重,这大大减少了动作空间。 应用两个 ReLU 层和 TanH 层,并且价值网络生成动作 a 后,代理与 MKG 进行交互。 外部环境MKG生成奖励r作为反馈信号,代理选择下一个状态(项目)。 然后 推荐一个项目(下一个状态),并且在项目与其邻居(项目-项目对)之间使用分层注意路径。 最后,在某些情节之后,代理被用来有效地为每个用户推理通向推荐项的路径。 当然,视觉和知识的逻辑路径可以作为推荐项目的解释。
2.基本概念
逆向边
自环边
状态、动作、奖励、状态转移函数

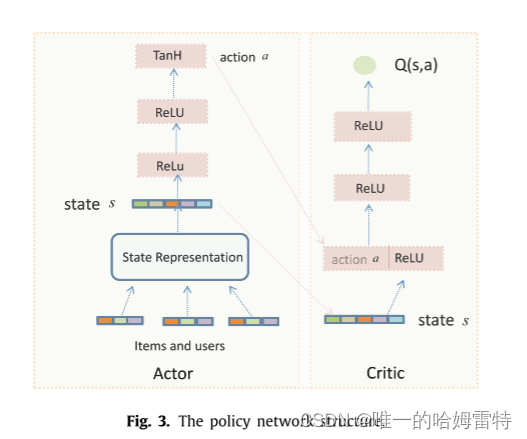
3.多模态知识图嵌入
知识图表示学习
在现实世界的知识图谱中,一个实体可以通过相同的关系链接链接到大量邻居。 通过该链接,该实体可以到达许多相邻实体。 给定结构化 KG,我们使用 Metapath2Vec [4] 进行知识图实体表示,其中实体及其邻居表示为连续的低维向量空间。 在知识图谱中,两个相似的实体可以通过它们之间公共属性的多条路径连接起来。 对于两个结构和语义相关的实体,Metapath2Vec 将它们紧密地嵌入到低维向量空间中。 一个实体的多个属性通常在结构和语义上与其他实体密切相关。 为了帮助了解每个实体的潜在表示,提取额外的上下文信息来补充实体识别。 除了学习实体的表示之外,我们还包括其属性; 例如,在电影数据集中,我们包括导演、演员、流派和国家,在图书数据集中,我们包括作者、出版商、费率和 ISBN。 通常,实体的上下文表示被计算为其多个属性的平均值:

视觉模态表示
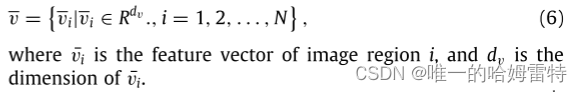
为了滤除噪声并找出与当前实体高度相关的区域 vi ∈ Rdv,我们应用了实体引导视觉注意模块。 给定一个实体 e,特征 e 可以通过等式(5)获得。 图像特征 v 由式 (6) 获得。 通过单层神经网络和 softmax 函数输入它们,在图像的 N 个区域上生成注意力影响权重:

逻辑路径推理和分层注意力路径
我们探索了MKG上的注意机制,以从关系和实体中提取更多有用的信息。
在状态 st ,实体 et 的嵌入、相应的视觉嵌入 vt 和用户 u 的嵌入被连接起来。 为了表征用户的不同兴趣,使用注意力网络 来模拟邻居节点的不同影响。 具体来说,对于节点 et 及其邻居 N(et ),应用 softmax 函数计算从 et 到邻居 e′ t ∈ N(et ) 的归一化影响权重:
这样可以选择用户最关心的实体e′t。
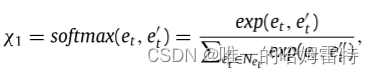
层次结构注意力路径
从当前实体et中选择实体e‘t作为下一状态暴露给用户,我们需要决定来自其邻居N(e’t)的哪一项应该是下一状态。在现实的KGS中,一个实体可以链接到具有相同关系链接的大量邻居。从项目节点e‘t到目标实体,将存在多个中间项目(实体)。此外,由于智能体在搜索路径的同时会在丰富的异质信息环境中进行推荐,因此KGS中可能存在多条路径。为了减少路径上的关系和实体的数量,我们提出了一种新的层次关注路径,以减少动作空间的大小,并将注意力集中在最重要的项目上:
在每一跳中都使用注意力机制,减少了动作空间大小,无需进行动作减枝和邻居剪枝。
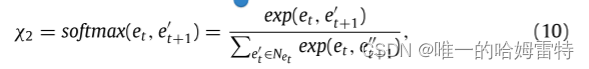
分层注意力路径推理
最后一步是通过训练有素的策略价值网络引导分层注意力路径机制来解决 MKG 上的推荐问题。 回想一下,给定用户 u,目标是找到一组候选项 {cn } 和相应的逻辑推理路径 {Pn(u, cn)}。 一种直接的方法是让代理在具有大量实体的大型动作空间中探索由动作引导的路径。 然而,这种方法很可能会导致多路径和低效率,我们引入了分层注意力路径作为该问题的解决方案。
对于获取的候选路径,如果没有分层注意力路径机制,则用户u和项目cn之间可能存在多条路径。 有了注意力机制,路径的数量就会减少。 因此,对于候选集中的每一对(u, cn),我们选择从具有最高注意力权重的PT开始的路径作为解释为什么项目cn被推荐给u的推理过程。
特别地,注意力权重最高的项目是用户最关心的项目,但用户最关心的项目也是有限的,从而减少了路径数量,更适合解释。 因此,我们可以从知识和图像的角度来解释为什么推荐它们。 最后,我们根据 RT 中的路径奖励对选定的可解释路径进行排序,并向用户推荐相应的项目。

使用REINFORCE方法设计共享相同特征层的策略网络和价值网络来解决这个问题,策略网络从状态向量 s 获取输入,并且策略网络输出 = π(a|s) 处的动作。 价值网络Qπ(s,a)反映了策略网络生成的策略的优劣。 即价值网络得到最优价值函数,策略网络利用价值网络并得到下一个状态来选择动作。
策略梯度∇θJ(θ)定义为:
















 145
145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









