






MMKGR: Multi-hop Multi-modalKnowledge Graph Reasoning(ICDE2023)

摘要
多模态知识图谱(MKG)不仅包括关系三元组,还包括相关的多模态辅助数据(即文本和图像),增强了知识的多样性。 然而,MKG 的天然不完整性极大地阻碍了其应用。 为了解决这个问题,现有的研究采用基于嵌入的推理模型在融合多模态特征后推断缺失的知识。 然而,这些方法的推理性能由于以下问题而受到限制:(1)多模态辅助特征融合不力; (2)缺乏复杂的推理能力,无法进行多跳推理,推断出更多缺失的知识。 为了克服这些问题,我们提出了一种名为 MMKGR(多跳多模态知识图推理)的新模型。 具体来说,该模型包含以下两个组成部分:(1)统一的门注意网络,旨在通过充分的注意交互和降噪来生成有效的多模态互补特征; (2) 一种互补的特征感知强化学习方法,该方法被提出,基于在组件(1)中获得的特征,通过执行多跳推理过程来预测缺失元素。
一、介绍
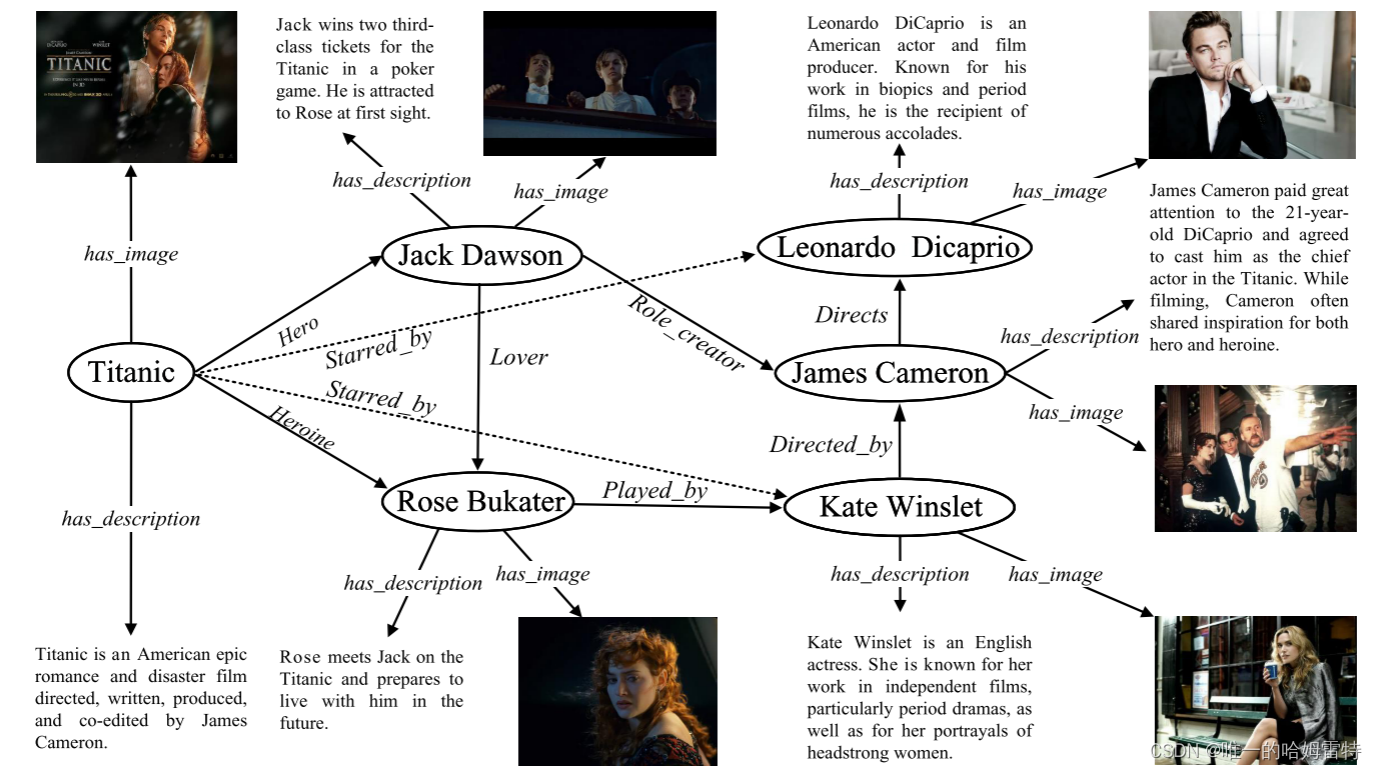
多模态知识图(MKG)不仅包含结构数据,还包含额外的多模态辅助数据(即文本和图像),与现实世界数据相比更符合现实世界数据的特征 。尽管MKG包含丰富的信息,但它仍然受到KG天然不完整性的影响,上图中遗漏了一个三元组(泰坦尼克号、主演、凯特·温斯莱特),这极大地阻碍了MKG的应用。
为了解决知识图谱自然不完整性的问题,人们提出了各种知识图谱推理方法。 这些方法的关键思想是通过有效整合图中现有信息来推断新知识,并且它们主要关注传统知识图谱,而不考虑多模态知识。一些推理模型[64][65][61][45][53][50]被提出来整合MKG上的多模态知识,但它们是基于模型TransE[3] 仅专注于完成单跳推理。 值得注意的是,单跳推理模型缺乏可解释性并且推理性能较低,因为知识图谱在多跳中具有最多的推断潜在知识[8]。 相应地,还有另一流专注于多跳推理的知识图谱推理方法。 该流中的代表性方法是基于强化学习(RL)的多跳推理,因为它能够利用知识图谱中关系的符号组合和传输[56],这使得整个推理过程可解释[58]。
基于强化学习的多跳KG推理模型不仅具有语义可解释性,而且比单跳推理模型具有更高的推理性能[27][18][81],这促使我们的研究重点关注多跳KG推理模型。 MKG 中的跳跃推理。 需要注意的是,现有的知识图谱领域的多跳推理方法目前还没有集成多模态信息。
挑战一是知识图谱推理领域缺乏细粒度的多模态信息利用方法。
多项多模态研究表明,细粒度特征有利于在推理任务中获得准确的结果[24]、[73]。 通常,大多数现有的 MKG 推理方法除了结构信息之外,仅学习一种模态信息(例如文本或图像)的单独注意力分布。
例如,我们仅从“泰坦尼克号”这个实体的形象就可以推断出《泰坦尼克号》是一部关于两个人互相拥抱的爱情电影。 最后但并非最不重要的一点是,一些不相关的噪声(例如图像中的黑色背景)和冗余噪声(与 Rose Bukater 的图像相比,Kate Winslet 的图像高度相似且包含的有用信息较少)损害了模型的鲁棒性和泛化性。 模型[4],[25]。 如何通过同时解决上述问题来学习细粒度的知识在 MKG 推理领域中并非易事。
挑战二在于直接将基于RL的KG推理方法扩展到MKG推理很容易产生一些错误的推理路径并降低推理性能。 这是因为多模态辅助数据的引入进一步加剧了稀疏奖励问题,从而导致强化学习的决策偏差。
大多数状态下缺乏反馈奖励和盲目推理[27]。 一些KG推理方法试图缓解这个问题,但它们仍然存在以下技术局限性:(1)奖励函数中没有充分考虑密度、探索和约束的一般设计原则,导致无法收敛训练后期。(2)缺乏奖励平衡机制,防止推理模型重复获取局部奖励而忽略最终目标。 (3)强化学习中缺乏感知和利用多模态特征的范式。
MMKGR(多跳多模态知识图推理)的新模型
MMKGR不仅有效地提取和利用多模态辅助特征,而且还完成了MKG中的多跳推理。 具体来说,该模型包含以下两个组成部分。 (1)为了解决挑战I,设计了一个统一的门注意网络来生成具有充分交互和较少噪声的多模态互补特征。 其注意力融合模块提取细粒度的多模态特征,以同时完成模态间注意力交互(即跨不同模态的共同注意力)和模态内注意力交互(即每种模态内的自我注意力)。
该网络的不相关过滤模块进一步过滤掉不相关的特征,并输出更可靠的多模态互补特征。 请注意,统一的门注意网络同时聚合低噪声信息,以从模态内和模态间获得与三元组查询相关的细粒度表示。
(2) 为了解决挑战 II,提出了一种互补的特征感知 RL 方法,通过执行多跳推理过程来预测丢失的元素。
设计了 目的地奖励、 距离奖励和 多样化奖励。
本文贡献
第一个研究如何有效利用多模态辅助特征在知识图谱领域进行多跳推理的问题,该研究为知识图谱推理提供了新的视角。
为了解决上述问题,我们提出了一种新的模型MMKGR,它包含一个统一的门注意网络,可以以较少的噪声构建足够的注意交互,以及一个补充的特征感知RL方法,旨在缓解奖励稀疏的问题和 在 MKG 中进行多跳推理。
二、相关工作
目前,实际的互联网数据呈现出多模态特征[18]。 MKGs被提议将多模态数据整合到KGs中[41][45]。 MKG 由结构数据(即关系三元组)和多模态辅助数据(即文本和图像)组成。
多模态学习的融合策略
早期的多模态研究仅通过向量串联融合所有模态的全局特征。 该方法的局限性在于多模态噪声影响关键特征的提取[14]。 因此,一些多模态研究[71][30][65]采用传统的注意力模型来提取辅助模态的重要特征。 与早期的融合方法相比,传统的注意力机制聚合了必要的信息以获得关键的局部表示[68]。 此外,考虑到传统的注意力机制无法同时在所有模态中执行特征交互,一些研究提出了共同注意力模型来同时分配和聚合所有模态的基本信息[74][77]。 尽管共同注意力被扩展到同时学习所有模态,但这些模型与传统的注意力机制一样,仍然学习所有模态之间的粗略交互。 为了解决多模态交互不足的问题,MCAN[73]和PSAC[24]应用自注意力机制[54]和共同注意力来完成模态内和模间注意力交互。
上述方法具有足够的交互性,但忽略了以下细节:(1)冗余和不相关的特征会损害模型的泛化性和鲁棒性[25]; (2)同一训练阶段仅考虑self-attention或co-attention,限制了样本的利用和细粒度特征的有效提取[54]。 现有方法的不足促使我们的多模态融合目标以统一且低噪声的方式同时完成模内和模间交互。
知识图谱推理
现有的知识图推理模型的
些研究专注于MKG的单跳推理,采用传统的注意力模型或级联来融合多模态特征,然后采用TransE来推断缺失元素。
最先进性能的MTRL[45]通过连接关系三元组的特征和综合包含文本和视觉特征的多模态辅助特征来执行单跳推理。
目前研究无法同时学习视觉和文本注意力以充分理解两种模态的语义。 这种粗糙的交互导致多模态特征的无效融合。
概念定义
多模态知识图谱

多跳推理

多模态辅助特征


三、方法
模型框架
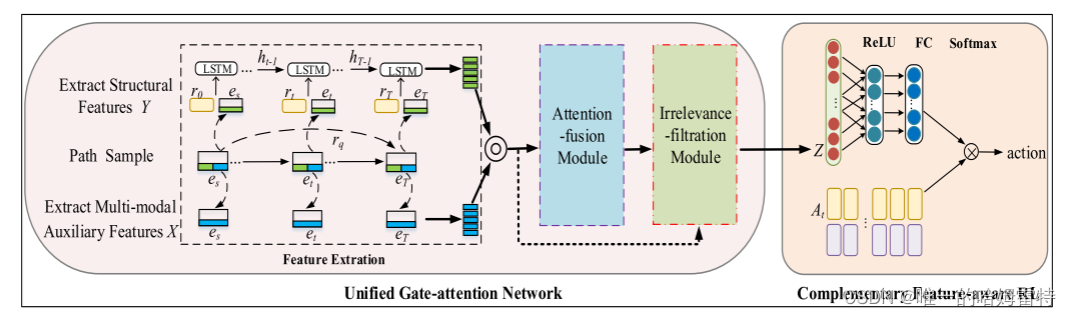
模型组件
统一的门-注意力网络,旨在进行充分的注意力交互并过滤噪声,以生成更有效和可靠的多模态互补特征,编码所有模态的相关知识。
互补特征感知的强化学习框架,旨在通过精心设计的奖励机制和有用的多模态互补特征,在多跳推理过程中预测缺失元素。
统一门注意力网络
现有MKG推理方法中多模态交互不足和噪声干扰严重限制了多模态数据的利用[73][36]。 为了解决这个问题,引入了一种新颖且统一的门注意网络来从多模态数据中学习。 该网络主要受到以下启发:
(1)模式内注意交互对细粒度特征的显着影响[54]
(2)有效过滤噪声的门网络[77]。 基于此,统一门注意力网络在线选择不同模态的特征,同时完成具有噪声鲁棒性的模内和模间注意力交互。
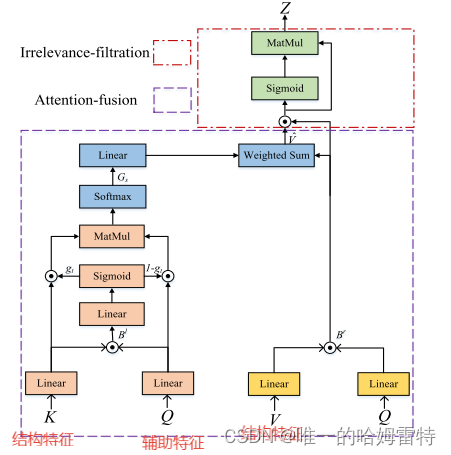
统一的门注意力网络包括特征提取、注意力融合模块和无关过滤模块。 所有模态提取的特征都被输入到注意力融合模块中,该模块通过精心设计的细粒度注意力方案将结构特征和多模态辅助特征融合在一起。 然后,不相关过滤模块丢弃不相关甚至误导性信息,并生成噪声鲁棒的多模态互补特征。
特征提取
1)使用TransE算法[3]从所有实体和关系中初始化具有ds维度的结构特征。 源实体 es 和查询关系 rq 分别表示为密集向量嵌入 es 和 rq。
由访问的实体和关系组成的推理路径的历史定义为 ht = (es, r0, e1, r1,…,et)。 接下来,我们利用 LSTM 将具有 ds 维度的历史信息向量 ht 整合为结构特征。

注意力融合模块
为了获得用于强化学习的互补特征,我们需要融合在特征提取中生成的结构特征Y和多模态辅助特征X。然而,冗余特征往往会对多模态融合过程中的预测产生负面影响。具体来说,冗余特征要么是与三元查询相关的特征的平移版本,这些冗余特征增加了计算复杂度,并引起了共线性问题。因此,我们提出了注意力融合模块,旨在有效地融合结构特征和多模态辅助特征。



通过设计注意力融合模块,我们可以同时统一完成模态内和模间特征交互。 这是因为该模块的输入是来自结构特征和多模态辅助特征的对,其中一对的每个向量可以从相同模态或不同模态学习。
不相关过滤模块
Complementary Feature-aware Reinforcement Learning
稀疏奖励(即智能体在短时间内无法获得足够的奖励)更容易产生错误的推理路径,而这些路径上实体的多模态辅助特征加剧了噪声的引入,从而进一步影响性能 的推理。 为了解决这个问题,提出了一种新颖的奖励机制。
(1) 提出了一种精心设计的 3D 奖励机制,将奖励设计原则与 KGR 领域知识相结合,以消除奖励稀疏性。
(2)在强化学习中首次引入了一种将策略函数用作多模态感知接口的新方法,以充分利用多模态特征。

奖励
奖励是影响所有基于强化学习的模型性能的关键因素[47]。 由于直接将基于RL的KG推理方法扩展到MKG推理会加剧稀疏奖励并降低推理性能,我们提出了一种3D奖励机制(目的地奖励、距离奖励和多样化奖励)
Destination reward(目的地奖励):当智能体达到eT或最大步长T时,智能体将收到返回的目的地奖励。 对于现有的基于 RL 的方法,如果 eT 是真实目标实体 ed,则目标奖励为 1。 否则,目的地奖励为0。我们认为,随着推理路径长度的增加,这种设置使得奖励变得更加稀疏。
为了缓解这个问题,我们使用奖励塑造技巧[27]来设计未达到 ed 时的奖励。
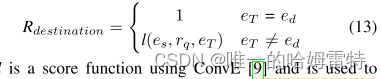
where L is a score function using ConvE [9] and is used to evaluate the probability over (es, rq, eT)。
Distance reward(距离奖励):奖励的稀疏程度往往与推理路径的长度呈正相关,事实上,当跳数超过3时,推理性能可能面临下降的风险[8]。 因此,我们使用 Rdistance 作为奖励函数的一部分,以减轻较短路径内的稀疏奖励。
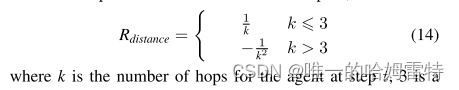
Diverse reward(多样化奖励):缺乏探索进一步加剧了奖励稀少的情况。 早期发现的路径会有偏差,这限制了对新路径的探索。 因此,基于高斯核的 Rdiversity 被鼓励探索一组多样化的路径,并防止代理陷入对奖励产生负面影响的局部最优路径。

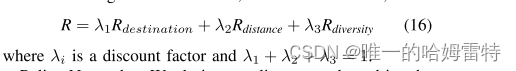
策略网络输入多模态特征Z,输出下一个动作的概率分布

五、实验

基线

对比实验
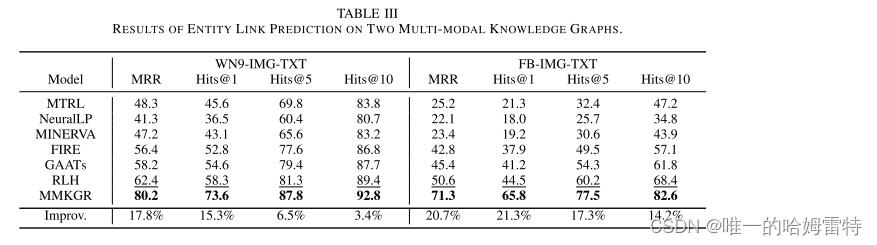
Relation Link Prediction
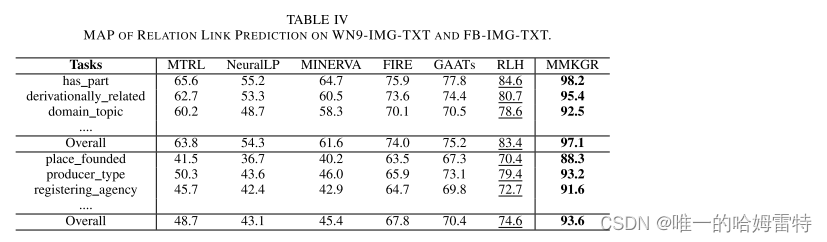
消融实验
1.Impact of Different Components in the Unified Gate-attention Network(不同的统一门控单元的影响)
(1) FAKGR:该变体版本中删除了无关过滤模块。
(2) FGKGR:通过式(1)完成多模态融合后,仅使用不相关过滤模块来生成输入到互补特征感知强化学习中的特征。 这个变体版本是为了评估精心设计的注意力融合模块的有效性。
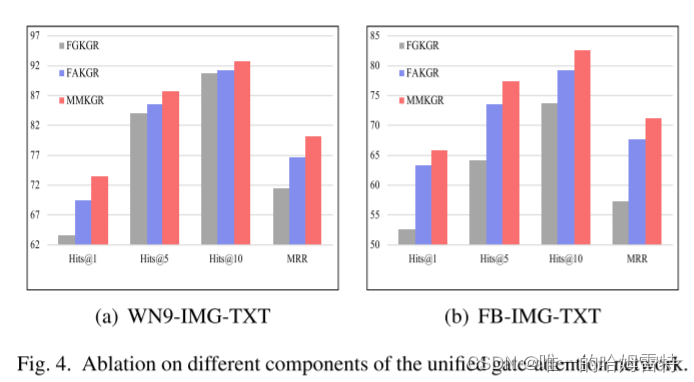
奖励函数中不同组成部分的影响
(1) DEKGR, a variant version only leveraging the destination reward as the reward function;
(2) DSKGR,a variant version where the distance reward is added on the basis of the destination reward;
(3) DVKGR, in which diverse reward is added on the basis of the destination reward.
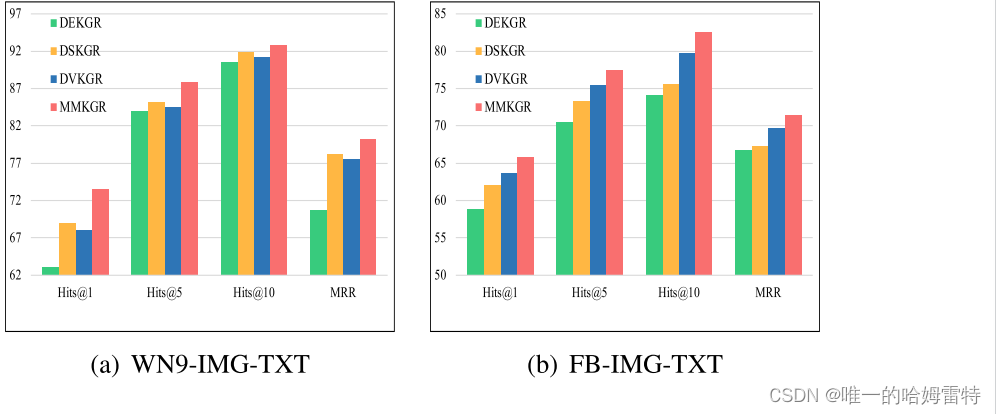
我们比较了删除某种模态特征的三个版本:
1)OSKGR:在方程(1)中仅考虑结构特征的版本。
2) STKGR:不通过统一门注意网络计算图像特征的版本。
3)SIKGR:文本特征不输入统一门注意网络的版本。

SIKGR的性能优于STKGR,这是因为每个实体都连接到更多包含更多有用信息的图片。
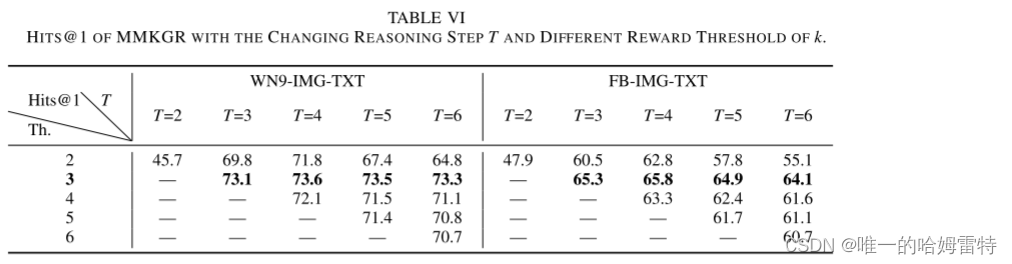
推理步骤 T 和 k 的不同奖励阈值时 MMKGR 的 HITS@1。















 2361
2361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









