







原文翻译
4.2 Mamba for Cross-Modal Interaction
Tasks and datasets.除了单模态任务外,我们还评估了 Mamba 在跨模态交互方面的性能。我们首先使用视频时间定位 (Video Temporal Grounding) 任务进行评估。所涉及的数据集包含 QvHighlight [44] 和 Charade-STA [28]。
Baseline and competitor.在这项工作中,我们使用 UniVTG [50] 来创建我们基于 mamba 的 VTG 模型。UniVTG采用变压器作为多模态交互网络。给定视频特征 V = {vi}i=1->Lv ∈ R^Lv ×D 和文本特征 Q = {qj }i=1->Lq ∈ R^Lq ×D ,我们首先将可学习的位置嵌入 Epos 和模态类型嵌入 Etype 添加到每个模态中以保留位置和模态信息:

然后,将文本和视频标记连接起来得到联合输入 Z = [ ̃V; ̃Q] ∈ R^L×D ,其中 L = Lv + Lq。此外,Z 被送入多模态变压器编码器。最后,取出文本增强的视频特征̃Ve,然后送入预测头。
为了创建跨模态 Mamba 竞争模型,我们堆叠双向 Mamba 块以形成多模态 Mamda 编码器来替换 Transformer 基线。
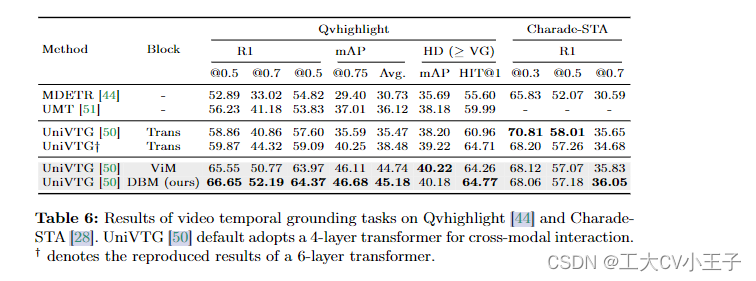
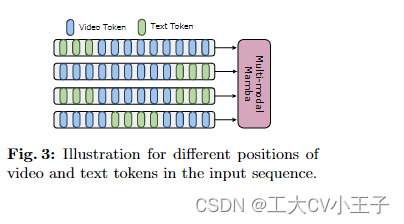
Results and analysis.我们在表 6 中展示了多个模型在 Qvhighlight [44] 上的性能。 Mamba 实现了 44.74 的平均 mAP,与Transformer相比,代表了显着的改进(44.74 对 38.48)。对于 Charade-STA [28],基于 Mamba 的方法也实现了相当的性能。这表明 Mamba 有可能有效地整合多种模态。鉴于 Mamba [30] 是一个基于线性扫描的模型,而转换器基于全局令牌交互,直观地说,我们认为标记序列中文本的位置可能会影响多模态聚合的有效性。为了研究这一点,我们在表 7 中包含了不同的文本视觉融合方法,而图 3 说明了四种不同的标记排列。我们观察到,当文本条件在视觉特征的左侧融合时,可以获得最好的结果。Qvhighlight[44]受到这种融合的影响较小,而 Charade-STA [28] 对文本位置表现出特别的敏感性,这可能是由于数据集的特征。

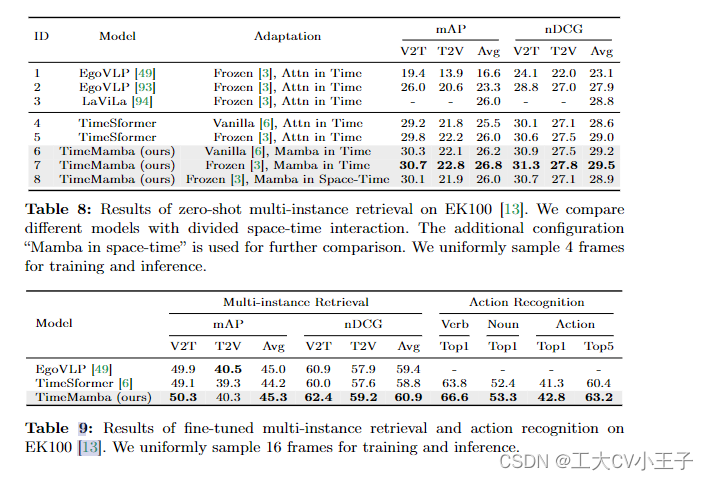
Results and analysis.TimeMamba 和 TimeSformer [6] 的性能比较如表 8、表 9、表 10 和图 5 所示。
















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









