







目录
1 深度学习训练模型步骤:
任何一个深度学习训练模型的流程都要按照如下步骤:
- 准备数据;
- 建立模型;
- 训练模型;
- 评估模型;
- 测试模型;
- 改进模型
2 训练目的:
使用PyTorch训练一个语言模型,目标是根据上文预测下一个单词,并在训练过程中评估模型在验证集和测试集上的性能。
我们选取的模式是LSTM模型,为了求得目标值和预测值之间的差距,我们选取Cross-entropy(交叉熵)作为损失函数。
3 训练步骤:
3.1 准备训练数据:
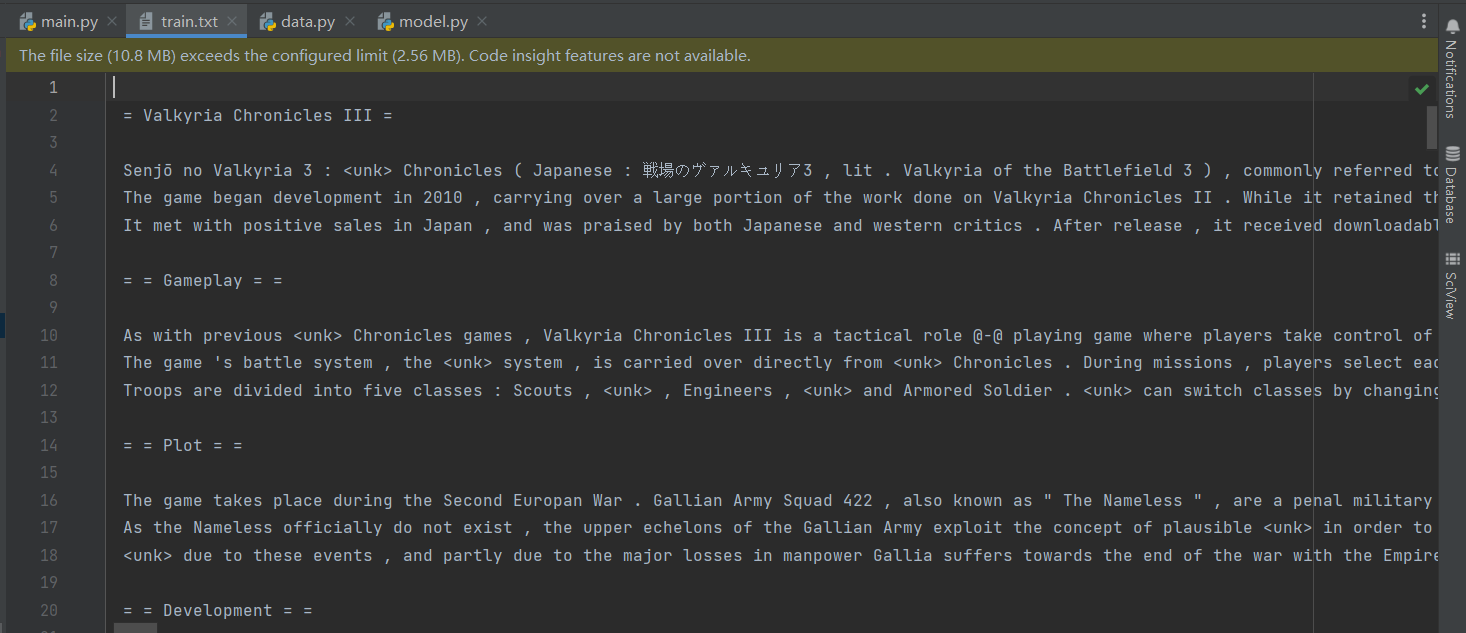
我们选取的训练数据来源于“维基百科”,并将其分割为训练集、验证集以及测试集。
3.2 main.py:
3.2.1 目的:
主函数,训练入口
3.2.2 parser模块:
简单理解就是为了进行全局参数配置。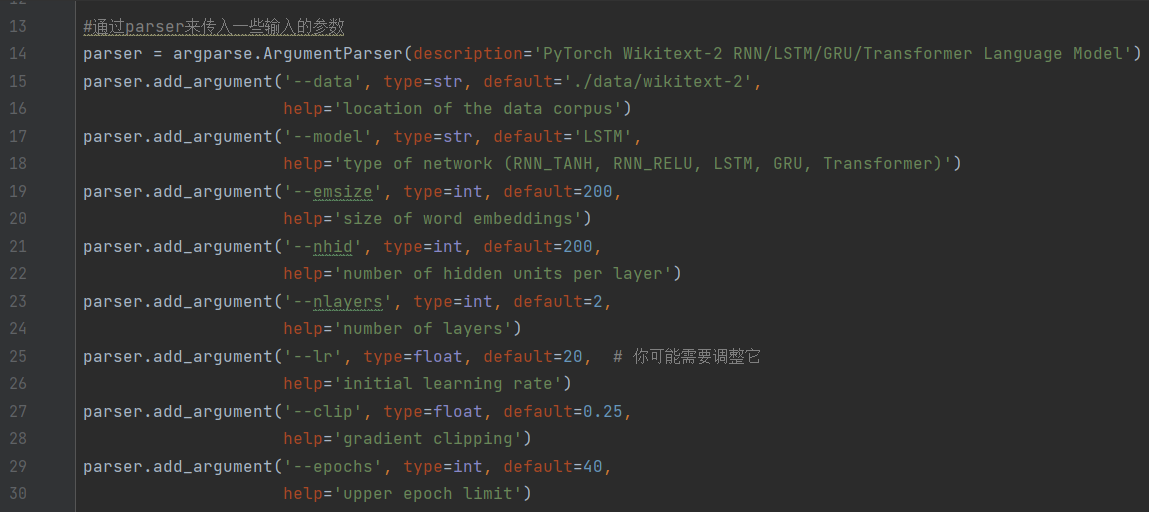
argparse 模块是 Python 内置的一个用于命令项选项与参数解析的模块,argparse 模块可以让人轻松编写用户友好的命令行接口。通过在程序中定义好我们需要的参数,然后 argparse 将会从 sys.argv 解析出这些参数。argparse 模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。
想要深入了解可以参考下面这个博客;
【精选】python之parser.add_argument()用法——命令行选项、参数和子命令解析器_parser.add_argument()参数_python-码博士的博客-CSDN博客
3.2.3 指定采用pytroch进行训练:
3.2.4 数据ID化(Corpus类):
(1)构建一个语料库对象,其中包括一个词典和经过ID化处理的训练集、验证集和测试集数据:

(2)具体来讲,Corpus的具体操作是将文本文件进行分词和标记化处理:
- 首先,通过
assert os.path.exists(path)进行断言,确保指定的文件路径存在。 - 接下来,通过打开文件并使用
with语句来读取文件内容。对于文件中的每一行,将其拆分成单词,并在末尾添加'<eos>',表示句子的结束。 - 然后,对于每个单词,调用
self.dictionary.add_word(word)方法将其添加到语料库的词典中。如果词典中已经存在该单词,就直接获取其对应的ID,如果词典中不存在该单词,就将该单词添加到词典中,并分配一个新的ID给它。 - 接下来,重新打开文件,再次遍历每一行。对于每个单词,使用
self.dictionary.word2idx[word]来获取其在词典中对应的ID,并将这些ID存储在ids列表中。 - 最后,将所有行的ID组成的列表
idss使用torch.cat方法连接起来,并将结果存储在ids变量中。这样,ids就是整个文本文件中所有单词对应的ID序列。

3.2.5 对数据进行分批处理,并构建模型和损失函数:
(1)batchify的样式转化图:
如下图所示,这里的bsz就是4(也就是分为4组),每一列表示一组连续的数据。
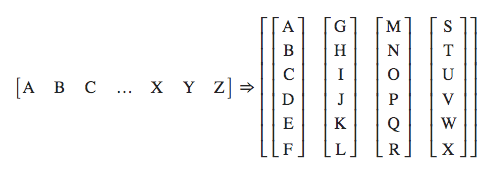
(2)具体步骤:
- 函数接收两个参数,
data和bsz。data是一个包含整型数据的张量,bsz表示每个批次的大小。 - 首先,通过计算
data.size(0) // bsz,得到可以将数据集等分为多少个批次。 - 接下来,使用
data.narrow(0, 0, nbatch * bsz)将数据集截取为能够整除bsz的大小。 - 然后,通过
data.view(bsz, -1).t().contiguous()将数据重新组织为以bsz为行数的矩阵,并进行内存连续化处理。 - 最后,将处理后的数据转移到设备上,并将其作为函数的返回值。
- 在主代码中,使用
batchify函数将训练集、验证集和测试集数据进行分批处理,并分别存储在train_data、val_data和test_data变量中。 - 接下来,使用
len(corpus.dictionary)获取词典中的词语数量,用于构建模型。 - 如果
args.model的值是'LSTM',则使用model.RNNModel构造一个RNN模型,并将模型移动到设备上。(模型细节请参考下文的model.py) - 然后,使用
nn.CrossEntropyLoss()构建交叉熵损失函数,该函数用于计算训练的目标值。
3.2.6 train函数(训练模型时的配置):
- 在函数中,首先将模型设置为训练模式(
model.train()),然后初始化一些变量,如总损失(total_loss)和起始时间(start_time)。 - 接下来,通过调用
model.init_hidden(args.batch_size)初始化隐藏状态(hidden)(这个是因为我们在第一次训练时没有前一个hidden层,因此要全部设为0作为初始状态)。在每个批次的训练过程中,通过调用get_batch(train_data, i)获取输入数据(data)和目标数据(targets)。 - 然后,通过调用
model.zero_grad()将模型的梯度置零,再通过调用repackage_hidden(hidden)对隐藏状态进行处理,这是为了防止梯度回传过程中的梯度累积问题。 - 接下来,通过调用
model(data, hidden)进行前向传播计算,得到模型的输出(output)和最新的隐藏状态(hidden)。 - 然后,通过调用
criterion(output, targets)计算输出和目标之间的损失,并调用loss.backward()进行反向传播计算梯度。 - 接下来,通过调用
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)对梯度进行裁剪,以防止梯度爆炸的问题。 - 然后,使用手动更新参数的方式,通过循环遍历模型的参数,并调用
p.data.add_(p.grad, alpha=-lr)来更新参数。 - 最后,统计损失值,并在每个一定的批次数(
args.log_interval)之后打印出当前训练的进度,包括当前的损失值(cur_loss)和困惑度(math.exp(cur_loss))。 - 整个训练过程会持续多个周期(
epoch),并在每个周期结束后,根据验证集上的损失情况判断是否达到了最佳的验证损失值(best_val_loss)。如果验证损失值最佳,则将当前模型保存为最佳模型。
3.2.7 训练过程的控制流程:
整个训练过程中,会打印出训练过程的详细信息,包括每个周期的训练和验证损失值,以及最终的测试损失值和测试困惑度。
- 首先,通过一个循环迭代训练多个周期(
args.epochs)。在每个周期中,记录当前周期的起始时间(epoch_start_time),然后调用train()函数进行模型训练。 - 接下来,通过调用
evaluate(val_data)在验证集上进行模型评估,得到验证损失值(val_loss)。然后打印出当前周期的信息,包括周期数(epoch)、训练时间、验证损失值和验证困惑度。 - 然后,判断当前的验证损失值是否是最佳的验证损失值(
best_val_loss)。如果是,则将当前模型保存为最佳模型。 - 如果当前的验证损失值没有达到最佳值,则通过将学习率(
lr)除以4.0来衰减学习率。 -
接下来,通过使用
torch.load加载保存的最佳模型,并使用flatten_parameters函数将RNN模型的参数变为连续的内存块,以加快前向传播的速度。 -
然后,通过调用
evaluate(test_data)在测试集上进行模型评估,得到测试损失值(test_loss)。然后打印出最终的训练结果,包括测试损失值和测试困惑度。
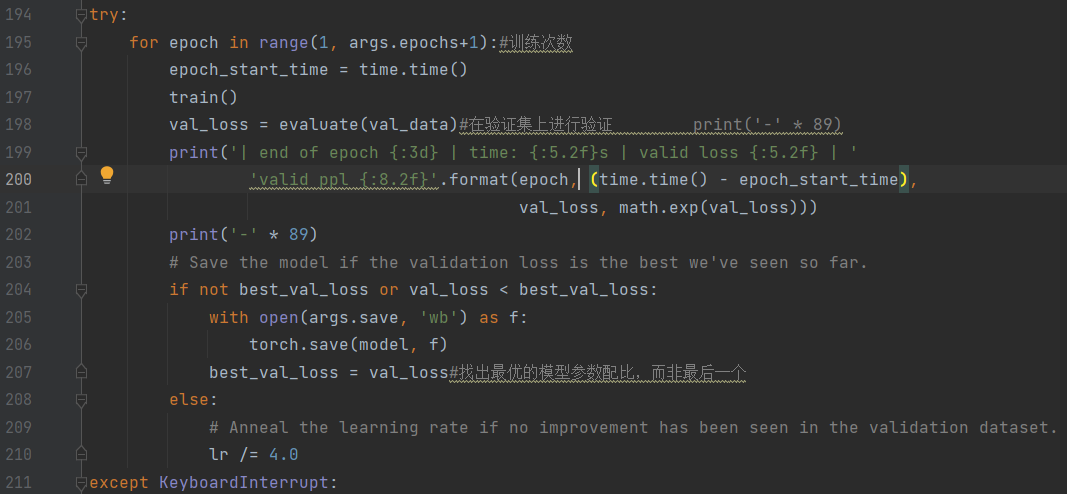
3.2.8 完整代码:
# coding: utf-8
# 训练的入口
import argparse
import time
import math
import os
import torch
import torch.nn as nn
import data
import model
#通过parser来传入一些输入的参数
parser = argparse.ArgumentParser(description='PyTorch Wikitext-2 RNN/LSTM/GRU/Transformer Language Model')
parser.add_argument('--data', type=str, default='./data/wikitext-2',
help='location of the data corpus')
parser.add_argument('--model', type=str, default='LSTM',
help='type of network (RNN_TANH, RNN_RELU, LSTM, GRU, Transformer)')
parser.add_argument('--emsize', type=int, default=200,
help='size of word embeddings')
parser.add_argument('--nhid', type=int, default=200,
help='number of hidden units per layer')
parser.add_argument('--nlayers', type=int, default=2,
help='number of layers')
parser.add_argument('--lr', type=float, default=20, # 你可能需要调整它
help='initial learning rate')
parser.add_argument('--clip', type=float, default=0.25,
help='gradient clipping')
parser.add_argument('--epochs', type=int, default=40,
help='upper epoch limit')
parser.add_argument('--batch_size', type=int, default=20, metavar='N',
help='batch size')
parser.add_argument('--bptt', type=int, default=35,
help='sequence length')
parser.add_argument('--dropout', type=float, default=0.2,
help='dropout applied to layers (0 = no dropout)')
parser.add_argument('--tied', action='store_true',
help='tie the word embedding and softmax weights')
parser.add_argument('--seed', type=int, default=1111,
help='random seed')
parser.add_argument('--cuda', action='store_true',
help='use CUDA')
parser.add_argument('--log-interval', type=int, default=200, metavar='N',
help='report interval')
parser.add_argument('--save', type=str, default='model.pt',
help='path to save the final model')
parser.add_argument('--nhead', type=int, default=2,
help='the number of heads in the encoder/decoder of the transformer model')
parser.add_argument('--dry-run', action='store_true',
help='verify the code and the model')
args = parser.parse_args()
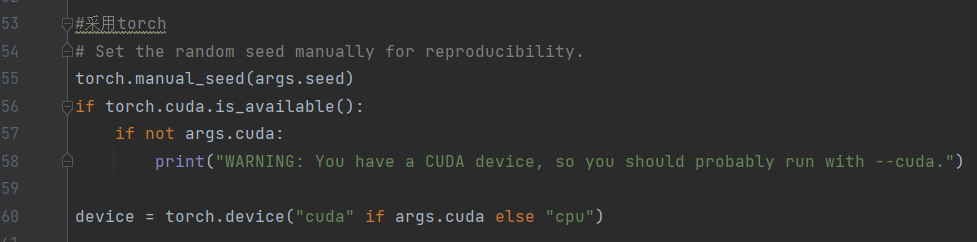
#采用torch
# Set the random seed manually for reproducibility.
torch.manual_seed(args.seed)
if torch.cuda.is_available():
if not args.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda.")
device = torch.device("cuda" if args.cuda else "cpu")
# 和word_language_model不同, sst2的corpus既要包含输入也要包含输出(label)
corpus = data.Corpus(args.data)
# Starting from sequential data, batchify arranges the dataset into columns.
# For instance, with the alphabet as the sequence and batch size 4, we'd get
# ┌ a g m s ┐
# │ b h n t │
# │ c i o u │
# │ d j p v │
# │ e k q w │
# └ f l r x ┘.
# These columns are treated as independent by the model, which means that the
# dependence of e. g. 'g' on 'f' can not be learned, but allows more efficient
# batch processing.
###############################################################################
# sst2改动batchify功能: 输出是一个数组,每个元素代表一个batch,每个batch是一个pair,包含data和label, data的shape为[seq_len, bsz](可由[bsz, seq_len]转置得到),label是一维0/1数组
###############################################################################
#batchify函数将文本数据映射成连续数字, 并转换成指定的样式,bsz是就是batch_size, 每次模型更新参数的数据量
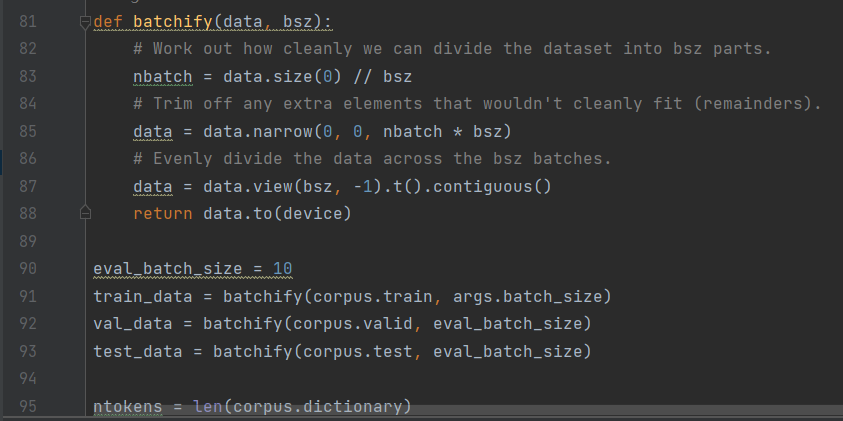
def batchify(data, bsz):
# Work out how cleanly we can divide the dataset into bsz parts.
nbatch = data.size(0) // bsz
# Trim off any extra elements that wouldn't cleanly fit (remainders).
data = data.narrow(0, 0, nbatch * bsz)
# Evenly divide the data across the bsz batches.
data = data.view(bsz, -1).t().contiguous()
return data.to(device)
eval_batch_size = 10
train_data = batchify(corpus.train, args.batch_size)
val_data = batchify(corpus.valid, eval_batch_size)
test_data = batchify(corpus.test, eval_batch_size)
ntokens = len(corpus.dictionary)
if args.model == 'LSTM':#构建模型
model = model.RNNModel(args.model, ntokens, args.emsize, args.nhid, args.nlayers, args.dropout, args.tied).to(device)
criterion = nn.CrossEntropyLoss()#构建训练目标,我们的目标是使得这个损失函数的值尽可能得小
def repackage_hidden(h):
"""Wraps hidden states in new Tensors, to detach them from their history."""
if isinstance(h, torch.Tensor):
return h.detach()
else:
return tuple(repackage_hidden(v) for v in h)
# get_batch subdivides the source data into chunks of length args.bptt.
# If source is equal to the example output of the batchify function, with
# a bptt-limit of 2, we'd get the following two Variables for i = 0:
# ┌ a g m s ┐ ┌ b h n t ┐
# └ b h n t ┘ └ c i o u ┘
# Note that despite the name of the function, the subdivison of data is not
# done along the batch dimension (i.e. dimension 1), since that was handled
# by the batchify function. The chunks are along dimension 0, corresponding
# to the seq_len dimension in the LSTM.
# 这个函数可能不再需要了,因为经过batchify后,我们的数据已经处理成一个batch一个batch的数组了,直接取就可以了
def get_batch(source, i):
seq_len = min(args.bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].view(-1)
return data, target
def evaluate(data_source): # 参考下面的train函数更改
# Turn on evaluation mode which disables dropout.
model.eval()
total_loss = 0.
ntokens = len(corpus.dictionary)
hidden = model.init_hidden(eval_batch_size)
with torch.no_grad():#为了防止评测过程中产生任何梯度,只希望去使用这组参数去做评测,而不对参数进行更新修改
for i in range(0, data_source.size(0) - 1, args.bptt):
data, targets = get_batch(data_source, i)
output, hidden = model(data, hidden)#前向传递和训练过程中的一致
hidden = repackage_hidden(hidden)
total_loss += len(data) * criterion(output, targets).item()
###############################################################################
# sst2不应只得到loss, 还要评测label正确的概率, 即acc
###############################################################################
# 怎么得到预测结果呢?
# 提示:pred = output.argmax(dim=1)
return total_loss / (len(data_source) - 1)
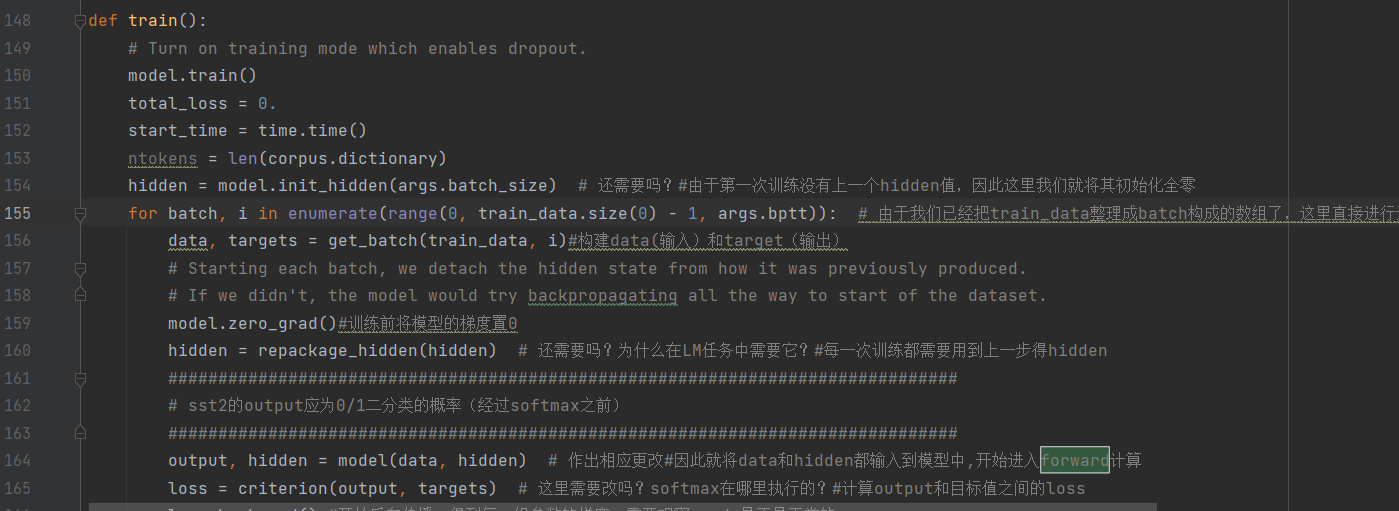
def train():
# Turn on training mode which enables dropout.
model.train()
total_loss = 0.
start_time = time.time()
ntokens = len(corpus.dictionary)
hidden = model.init_hidden(args.batch_size) # 还需要吗?#由于第一次训练没有上一个hidden值,因此这里我们就将其初始化全零
for batch, i in enumerate(range(0, train_data.size(0) - 1, args.bptt)): # 由于我们已经把train_data整理成batch构成的数组了,这里直接进行迭代即可。
data, targets = get_batch(train_data, i)#构建data(输入)和target(输出)
# Starting each batch, we detach the hidden state from how it was previously produced.
# If we didn't, the model would try backpropagating all the way to start of the dataset.
model.zero_grad()#训练前将模型的梯度置0
hidden = repackage_hidden(hidden) # 还需要吗?为什么在LM任务中需要它?#每一次训练都需要用到上一步得hidden
###############################################################################
# sst2的output应为0/1二分类的概率(经过softmax之前)
###############################################################################
output, hidden = model(data, hidden) # 作出相应更改#因此就将data和hidden都输入到模型中,开始进入forward计算
loss = criterion(output, targets) # 这里需要改吗?softmax在哪里执行的?#计算output和目标值之间的loss
loss.backward() #开始反向传播,得到每一组参数的梯度,需要观察grade是否是正常的
# `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs.
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)#为了防止梯度爆炸,将梯度超过clip的部分截掉
# 这里展示的是手动更新参数的方式,而不是使用optimizer。你可以试一试改成optimizer。
for p in model.parameters():
p.data.add_(p.grad, alpha=-lr)#更新参数
total_loss += loss.item()
if batch % args.log_interval == 0 and batch > 0:
cur_loss = total_loss / args.log_interval
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches | lr {:02.2f} | ms/batch {:5.2f} | '
'loss {:5.2f} | ppl {:8.2f}'.format(
epoch, batch, len(train_data) // args.bptt, lr,
elapsed * 1000 / args.log_interval, cur_loss, math.exp(cur_loss))) # 去掉perplexity
total_loss = 0
start_time = time.time()
if args.dry_run:
break
# Loop over epochs.
lr = args.lr
best_val_loss = None
# At any point you can hit Ctrl + C to break out of training early.
try:
for epoch in range(1, args.epochs+1):#训练次数
epoch_start_time = time.time()
train()
val_loss = evaluate(val_data)#在验证集上进行验证 print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | '
'valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss)))
print('-' * 89)
# Save the model if the validation loss is the best we've seen so far.
if not best_val_loss or val_loss < best_val_loss:
with open(args.save, 'wb') as f:
torch.save(model, f)
best_val_loss = val_loss#找出最优的模型参数配比,而非最后一个
else:
# Anneal the learning rate if no improvement has been seen in the validation dataset.
lr /= 4.0
except KeyboardInterrupt:
print('-' * 89)
print('Exiting from training early')
# Load the best saved model.
with open(args.save, 'rb') as f:
model = torch.load(f)
# after load the rnn params are not a continuous chunk of memory
# this makes them a continuous chunk, and will speed up forward pass
# Currently, only rnn model supports flatten_parameters function.
if args.model in ['RNN_TANH', 'RNN_RELU', 'LSTM', 'GRU']:
model.rnn.flatten_parameters()
# Run on test data.
test_loss = evaluate(test_data)
print('=' * 89)
print('| End of training | test loss {:5.2f} | test ppl {:8.2f}'.format(
test_loss, math.exp(test_loss)))
print('=' * 89)
3.3 data.py:
3.3. 1 目的:
预处理数据,来构建一个词典,并将单词ID化,得到ID化的三个数据集。主要的Corpus类主要用于将输入数据ID化。
3.3.2 完整代码:
# 预处理数据,来构建一个词典,并将单词ID化,得到ID化的三个数据集
import os
from io import open
import torch
class Dictionary(object):
def __init__(self):
self.word2idx = {}
self.idx2word = []
def add_word(self, word):
if word not in self.word2idx:
self.idx2word.append(word)
self.word2idx[word] = len(self.idx2word) - 1
return self.word2idx[word]
def __len__(self):
return len(self.idx2word)
class Corpus(object):
def __init__(self, path):#包括一个词典和ID化后的三个数据集,词典中的每一个词语对应一个ID
self.dictionary = Dictionary()
# 添加一个参数,记录设置的最大序列长度
self.train = self.tokenize(os.path.join(path, r'F:\学习笔记\NLP\Pipeline_pytorch\data\wikitext\train.txt')) # 改成相应的文件名
self.valid = self.tokenize(os.path.join(path, r'F:\学习笔记\NLP\Pipeline_pytorch\data\wikitext\valid.txt'))
self.test = self.tokenize(os.path.join(path, r'F:\学习笔记\NLP\Pipeline_pytorch\data\wikitext\test.txt'))
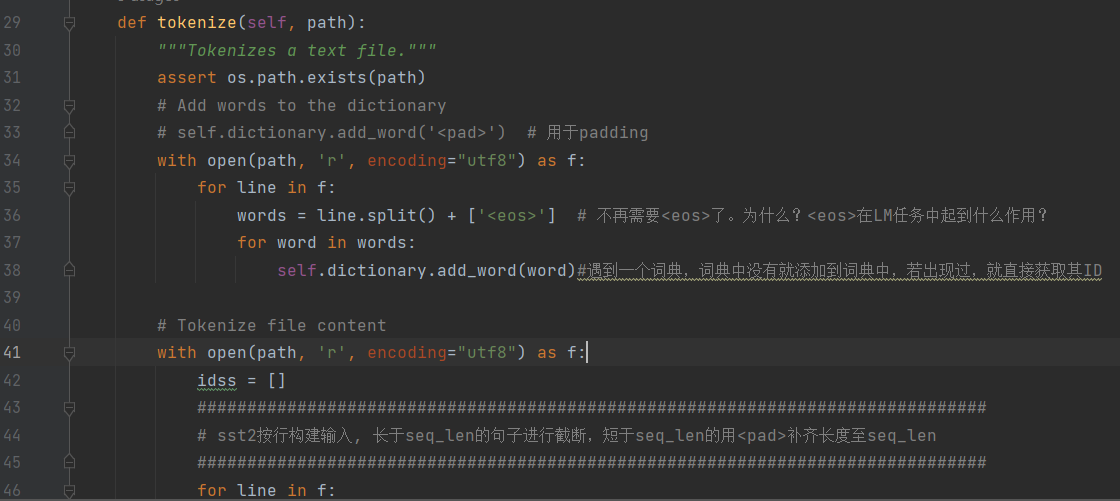
def tokenize(self, path):
"""Tokenizes a text file."""
assert os.path.exists(path)
# Add words to the dictionary
# self.dictionary.add_word('<pad>') # 用于padding
with open(path, 'r', encoding="utf8") as f:
for line in f:
words = line.split() + ['<eos>'] # 不再需要<eos>了。为什么?<eos>在LM任务中起到什么作用?
for word in words:
self.dictionary.add_word(word)#遇到一个词典,词典中没有就添加到词典中,若出现过,就直接获取其ID
# Tokenize file content
with open(path, 'r', encoding="utf8") as f:
idss = []
###############################################################################
# sst2按行构建输入, 长于seq_len的句子进行截断,短于seq_len的用<pad>补齐长度至seq_len
###############################################################################
for line in f:
words = line.split() + ['<eos>']#终止符
ids = []
for word in words:
ids.append(self.dictionary.word2idx[word])
idss.append(torch.tensor(ids).type(torch.int64))
ids = torch.cat(idss)
###############################################################################
# 构建输出, sst2的label取出, positive的label为1, negative的label为0, 返回格式为多行(ids, label)
###############################################################################
###############################################################################
# sst2语料库
# The dinner is great. \t positive
# I hate summer. \t negative
# ...
# sst2返回格式, 其中pad_id=0
# (torch.tensor[9,6,7,4,0,0,...], 1)
# (torch.tensor[3,2,8,0,0,0,...], 0)
# ...
###############################################################################
return ids
3.4 model.py:
3.4.1 目的:
一个封装好的LSTM模型,其中主要定义了RNNModel类。
3.4.2 具体步骤:
- 这段代码定义了一个名为
RNNModel的LSTM模型类,该类继承自nn.Module。 - 模型类包含了一个嵌入层(
self.encoder)(用于将ID向量转换为词向量)、一个循环层(self.rnn)(直接调用troch中的LSTM即可)和一个线性层(self.decoder)(将hidden维度的向量转换为词典长度维度的向量)。 - 在
__init__方法中,模型类接收一些参数,包括循环层的类型(rnn_type),词汇表的大小(ntoken),嵌入层的维度(ninp),隐藏层的维度(nhid),循环层的层数(nlayers),以及一些可选的参数如dropout(防止过拟合)和tied_weights等。 - 在模型的前向传播(
forward)方法中:首先将输入的ID序列通过嵌入层转换为词向量(emb);然后将词向量输入到循环层(self.rnn)中进行训练;循环层的输出(output)经过dropout层(self.drop)处理后;再经过线性层(self.decoder)得到词表上的概率分布(decoded)。 - 模型还定义了一个
init_hidden方法,用于初始化隐藏状态(hidden),并返回一个与输入批次大小(bsz)相匹配的零张量。 - 整体上,这个
RNNModel类封装了一个LSTM模型的结构和计算过程,可以用于文本分类或其他相关任务。
3.4.3 完整代码:
#封装好的LSTM模型
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class RNNModel(nn.Module):
"""Container module with an encoder, a recurrent module, and a decoder."""
def __init__(self, rnn_type, ntoken, ninp, nhid, nlayers, dropout=0.5, tie_weights=False):
super(RNNModel, self).__init__()
self.ntoken = ntoken
self.encoder = nn.Embedding(ntoken, ninp)#:负责将输入(Input)转化为特征(Feature)||向量
if rnn_type in ['LSTM', 'GRU']:#直接调用torch中封装好的LSTM层
self.rnn = getattr(nn, rnn_type)(ninp, nhid, nlayers, dropout=dropout)
else:
try:
nonlinearity = {'RNN_TANH': 'tanh', 'RNN_RELU': 'relu'}[rnn_type]
except KeyError:
raise ValueError( """An invalid option for `--model` was supplied,
options are ['LSTM', 'GRU', 'RNN_TANH' or 'RNN_RELU']""")
self.rnn = nn.RNN(ninp, nhid, nlayers, nonlinearity=nonlinearity, dropout=dropout)
###############################################################################
# sst2的decoder不应在整个词表上预测,而是预测0/1的概率,因此下面ntoken可能需要改成2,即2分类
###############################################################################
self.decoder = nn.Linear(nhid, ntoken)#Decoder类接收Encoder类的实现,Decoder类接收Encoder类输出的h,输出目标字符串,
self.drop = nn.Dropout(dropout)#防止过拟合
self.init_weights()
self.rnn_type = rnn_type
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):#初始化模型之后,对其结构进行初始化操作
initrange = 0.1
nn.init.uniform_(self.encoder.weight, -initrange, initrange)
nn.init.zeros_(self.decoder.bias)
nn.init.uniform_(self.decoder.weight, -initrange, initrange)
#进行前向传播计算
#第一步:将输入得ID转换为对应的词向量
#第二步:输入到LSTM模型中进行训练
#第三步:输出词表上的概率分布(但是首先得到的一个hidden维度的)
#第四步:通过decodeer经过线性层得到一个词表维度的概率分布
def forward(self, input, hidden): # hidden在这里面没用了,我们不需要上一个状态的hidden,每个样本都是独立的
emb = self.drop(self.encoder(input))
output, hidden = self.rnn(emb, hidden) # 这里面也不需要hidden作为输入了,输出也不用要hidden
output = self.drop(output) # shape是seq_len, bsz, nhid#防止过拟合
# 补充代码,从上面的output中,抽取最后一个词的输出作为最终输出。要注意考虑到序列的真实长度。最后得到一个shape是bsz, nhid的tensor
# 提示:output = output[real_seq_lens - 1, torch.arange(output.shape[1]), :]
decoded = self.decoder(output)
decoded = decoded.view(-1, self.ntoken)#为了和目标值target维度保持一致,把bath维度和句子维度压到一个维度里
return decoded, hidden # 不再需要输出hidden;最终输出的shape是bsz, 2
def init_hidden(self, bsz):
weight = next(self.parameters())
if self.rnn_type == 'LSTM':
return (weight.new_zeros(self.nlayers, bsz, self.nhid),
weight.new_zeros(self.nlayers, bsz, self.nhid))
else:
return weight.new_zeros(self.nlayers, bsz, self.nhid)
4 模型训练结果:
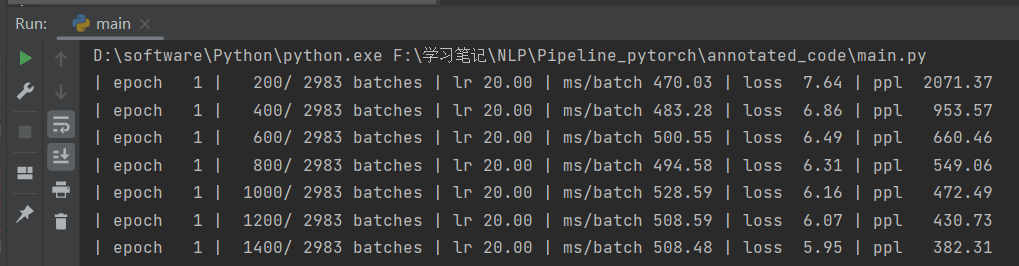
可以看到无论是训练集还是验证集,它的loss和ppl都是逐渐下降的

5 其他优秀pytroch训练项目:
由于本节课的讲解过于模糊,因此如果想要深入学习可以参考下面这篇博客:
Pytorch LSTM实现中文单词预测(附完整训练代码)_ngram模型代码-CSDN博客
但是苦于没有源码,不过倒是有比较清晰完善的思路,值得一看。

















 8093
8093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









