







目录
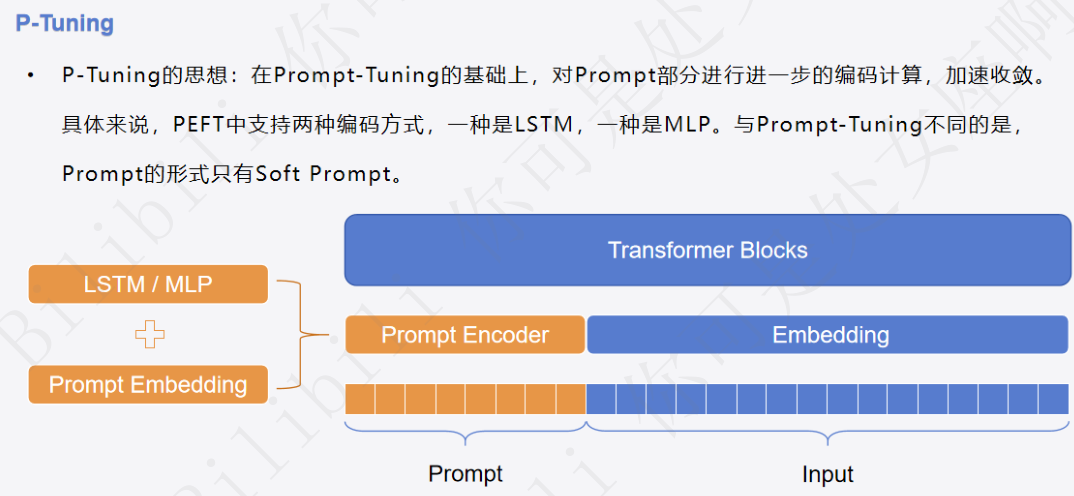
1 P-Tuning回顾:
2 Prefix-Tuning原理:
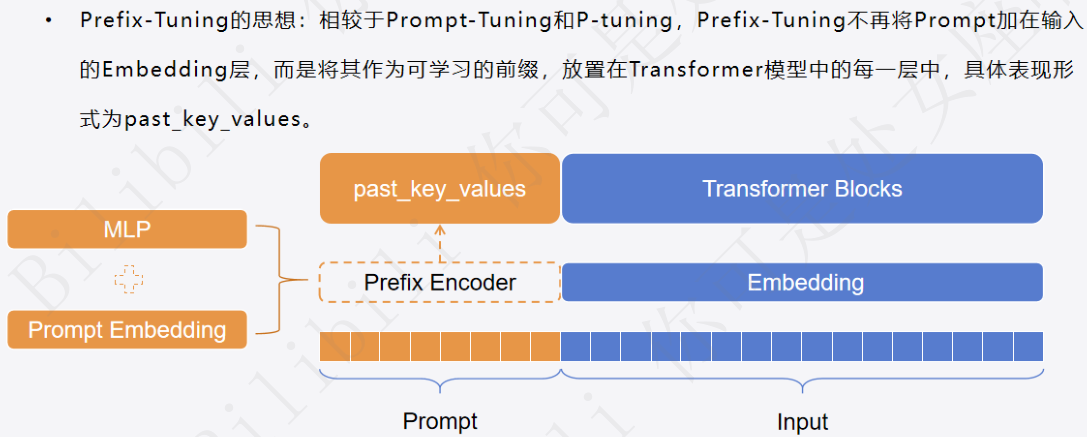
2.1 区别:
- Prefix-Tuning的核心想法是向每个Transformer块添加可训练的张量,而不是像在P-Tuning中那样仅向输入嵌入层添加张量;
- Prompt-tuning微调的是加入的prompt_encoder模块中embedding的那部分参数;而Prefix tuning将prefix参数(可训练的张量)添加到所有的transformer层。

2.2 机制:
将多个prompt vectors 放在每个multi-head attention的key矩阵和value矩阵之前
2.3 计算方式:
相当于微调后会训出一个固定的前缀向量。推理的时候输入的token向量化后会和这个前缀向量拼起来,再进行后面的qkv操作,模型的结构和参数都没有变,只是输入变了;注意只是将prompt vectors加在K、V上,Q、K、V的维度是一样的,但是seq_len不一定要一样。
3 环境配置:
4 代码实战演练(基于Bloom模型):

4.1 导包
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer4.2 加载数据集
ds = Dataset.load_from_disk("../data/alpaca_data_zh/")
ds4.3 数据集处理
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")
tokenizer
def process_func(example):
MAX_LENGTH = 256
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
response = tokenizer(example["output"] + tokenizer.eos_token)
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds4.4 创建模型
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)4.4.1 配置文件
from peft import PrefixTuningConfig, get_peft_model, TaskType
config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10, prefix_projection=True)
config当 prefix_projection=True 时,模型将会在输入的前缀嵌入上应用一个线性变换(通常是一个全连接层),使得前缀向量可以映射到与主模型输入相同的特征空间中。
一般来讲,Prefix-Tuning包含这个,P-Tuning不包含这个。
4.4.2 构建模型
model = get_peft_model(model, config)model.prompt_encoderModuleDict(
(default): PrefixEncoder(
(embedding): Embedding(10, 2048)
(transform): Sequential(
(0): Linear(in_features=2048, out_features=2048, bias=True)
(1): Tanh()
(2): Linear(in_features=2048, out_features=98304, bias=True)
)
)
)
model.print_trainable_parameters()trainable params: 205,641,728 || all params: 1,508,753,408 || trainable%: 13.629909759249406
4.5 配置训练参数
args = TrainingArguments(
output_dir="./chatbot",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
logging_steps=10,
num_train_epochs=1
)4.6 创建训练器
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)4.7 模型训练
trainer.train()4.8 模型推理
model = model.cuda()
ipt = tokenizer("Human: {}\n{}".format("数学考试有哪些技巧?", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(model.device)
print(tokenizer.decode(model.generate(**ipt, max_length=256, do_sample=True)[0], skip_special_tokens=True))

















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









