







目录
0 完整章节内容
本文为李宏毅学习笔记——2024春《GENERATIVE AI》篇——“第9讲”章节的课堂笔记,完整内容参见:
李宏毅学习笔记——2024春《GENERATIVE AI》篇
本章节主要介绍“以大型语言模型打造的AI Agent”。
1 今日多数人使用AI的方式
在今天的讨论中,我们谈到的是如何利用大型语言模型(如GPT)来构建AI代理。当前,使用AI的场景通常是让AI执行单一的任务。
例如,若你想要翻译一句话,你只需要提供原句,GPT就会给出翻译结果;
如果你希望通过GPT绘制图像,你可以要求它画图,它就会调用DALL·E来生成图像。这个过程大多是一步到位的,用户输入任务,AI完成输出。
2 未来人类对AI的期待
今天的讨论重点是如何让AI执行多步骤的复杂任务。举个例子,假设我要举办朋友间的聚餐,这个任务包含多个步骤:首先需要调查大家的空闲时间,然后根据调查结果选择餐厅,并进行预订。如果餐厅没有位置,还需要查询其他餐厅并进行调整。这些步骤需要有序进行,并且在执行过程中,计划可能会发生变化。
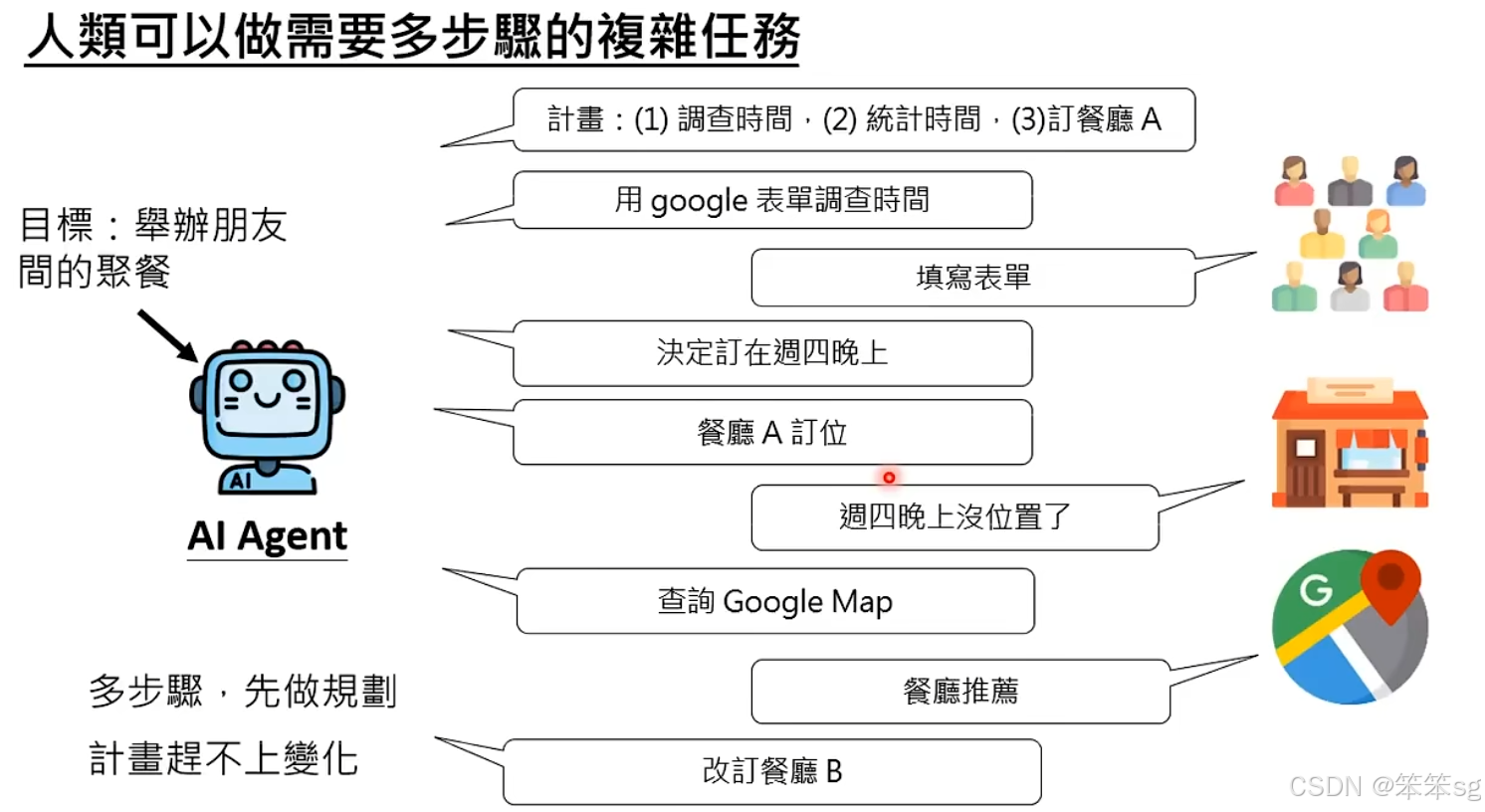
今天的AI大多只能执行单一的任务,但如果AI能够像人类一样规划任务并应对变化,那么它就能成为一个“AI agent”。这个AI agent不仅能执行计划,还能在执行过程中做出调整和修正。目前,虽然不一定每个AI都有这种能力,但借助大型语言模型,我们有可能在不久的将来看到这样的AI agent出现在日常生活中,能够处理类似上述的复杂任务,包括做计划、调整计划和使用工具来执行任务。
3 AI Agent的一些例子
下面是几种现有的AI agent,其中最知名的可能是AutoGPT。AutoGPT能够接受任务指令,比如“帮我做个网页”,然后它会自动进行任务执行,可能会上网搜索、使用工具、进行自我反思等。然而,尽管AutoGPT具有一定的能力,但它并不总是能够成功完成任务。有些用户曾给它指令,放任其自行操作,结果可能会花费大量时间而没有任何成果,甚至在某些情况下,造成资源浪费。

AutoGPT虽然曾一度非常流行,但它也展示了语言模型在处理复杂任务时的局限性。今天的语言模型仍然有一些能力的极限,尤其是当它们被要求自行解决复杂任务时。然而,AI agent的概念仍然代表着未来的趋势。未来,语言模型可能不再局限于一问一答的模式,而是能够自主与环境互动、思考并最终解决问题。
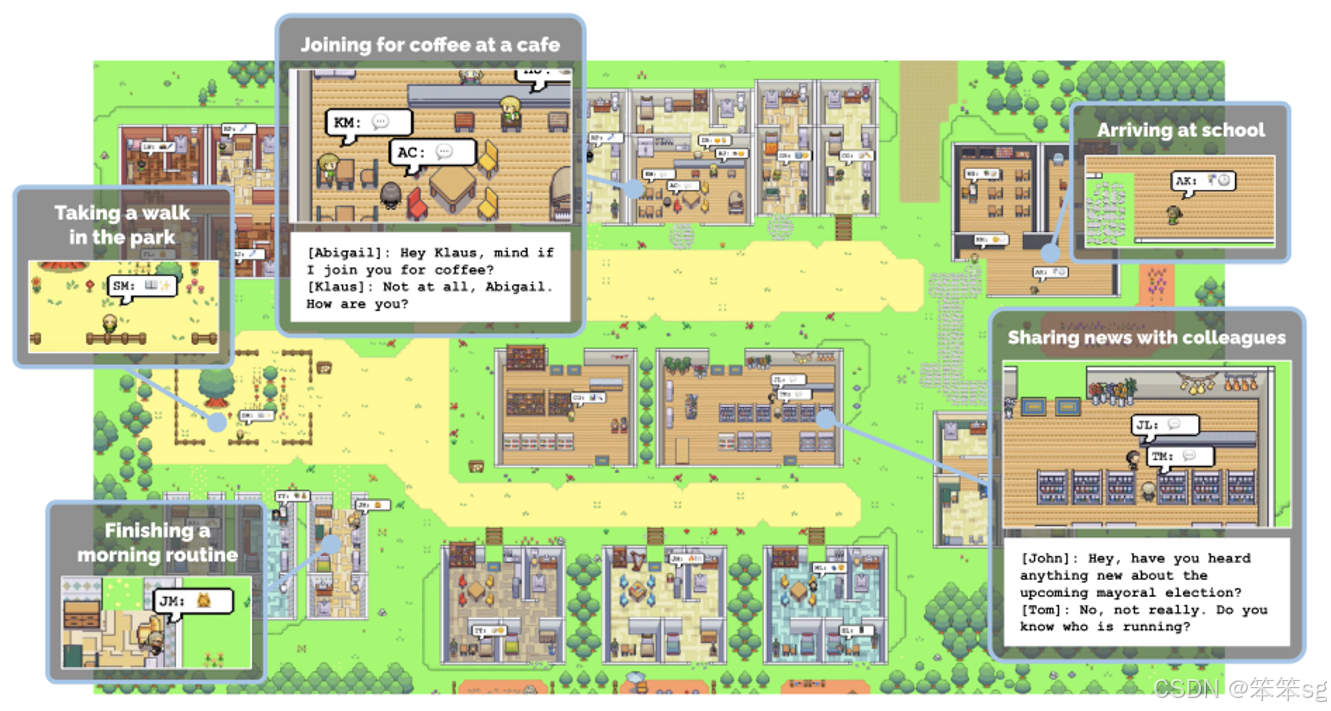
3.1 由AI村民组成的虚拟村庄
其中最知名的一个例子是由AI村民构成的“STANFORD小镇”,这个之前我们也有提到过:
让 AI 村民组成虚拟村庄会发生什么事?——GENERATIVE AI——拓展内容(第5讲)-CSDN博客
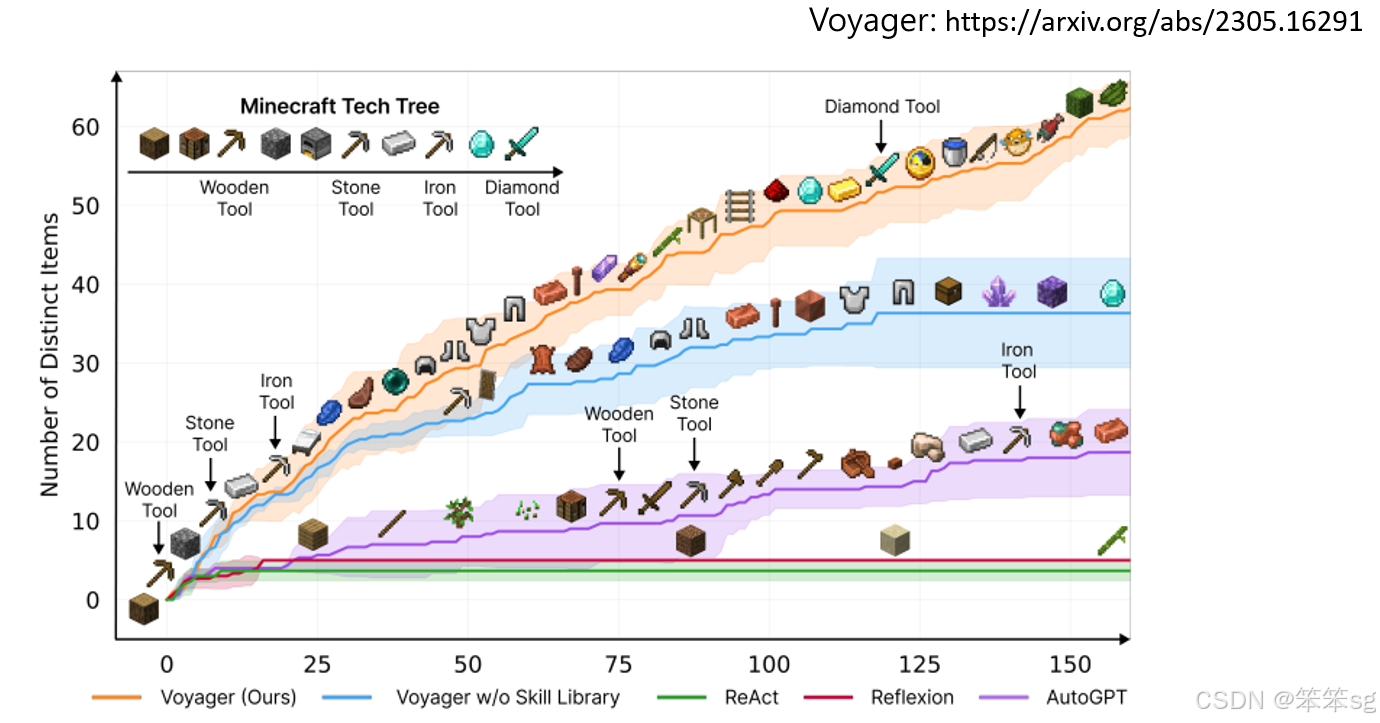
3.2 会自己玩Minecraft的AI
除此之外,还有让AI在Minecraft中进行自我探索和学习。比如,在《Voyager》论文中,AI通过不断的探索,学会了使用木质工具、十字工具、铁器工具,并最终学会打造钻石剑。随着学习的不断积累,AI变得越来越强,能够完成更多任务。这展示了AI在虚拟世界中的自我学习能力。
3.3 由语言模型操控的机器人
此外,还有AI与物理世界互动的例子。例如,Figure One是一个能够接受指令并执行任务的机器人,背后依赖语言模型来进行操作。通过语言模型,机器人能够执行复杂的任务,如清理桌子或拿东西。
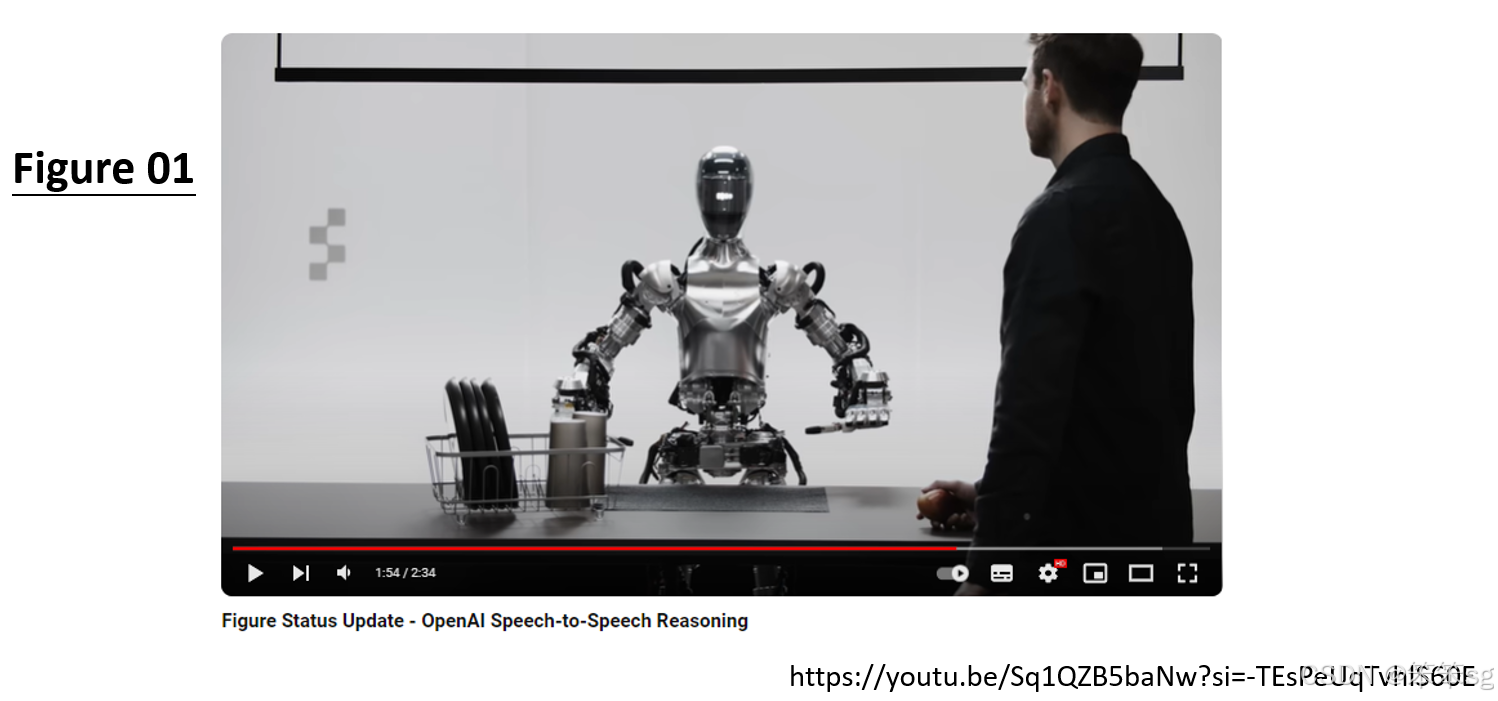
不过,值得注意的是,使用语言模型来操控机器人并不是新鲜的概念。早在2022年,就有论文《Inner Monologue》提出了语言模型与机器人结合的思路,机器人通过语言模型接受指令并自主思考解决问题的过程。
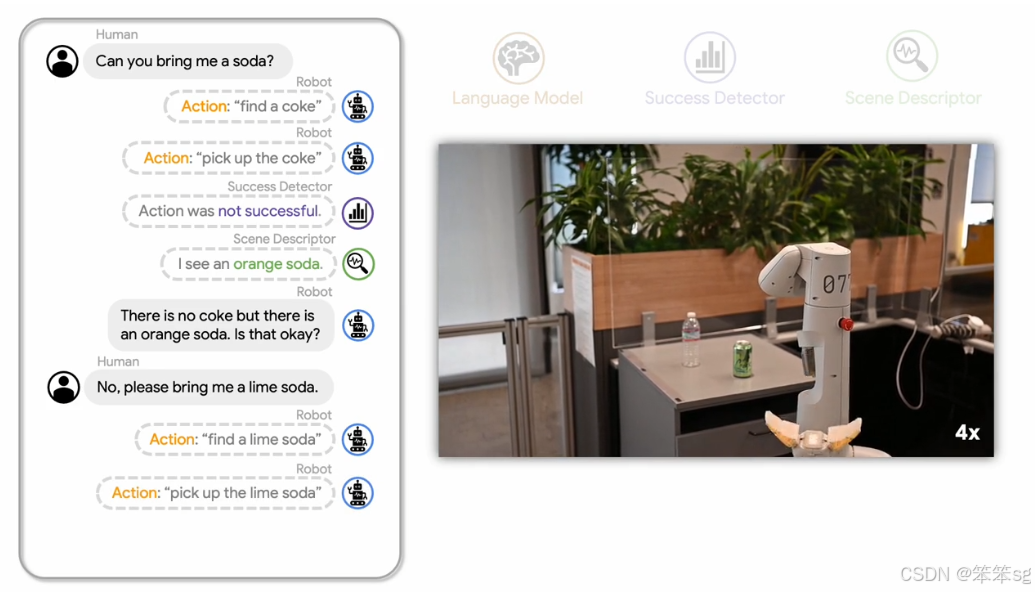
下面是完整的demo视频:
Inner Monologue
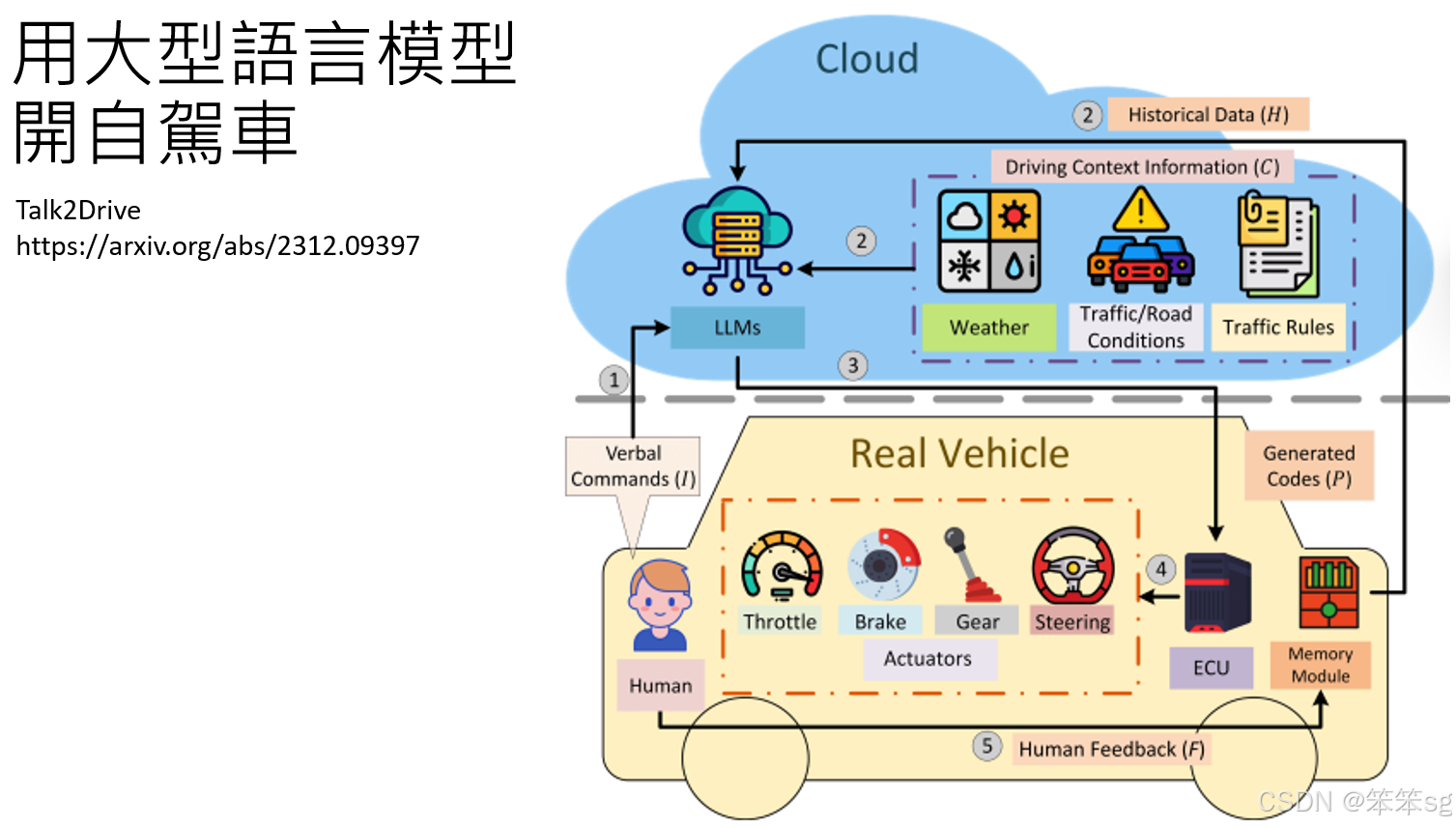
3.4 用大型语言模型开自驾车
另一个例子是自驾车领域,论文《Talk2Drive》展示了如何利用大型语言模型来开自驾车。司机给出指令后,语言模型会根据环境信息(如天气、交通状况等)生成程序代码,通过这些代码来控制自驾车的各个部分。驾驶过程中,人类也可以提供反馈,帮助AI模型不断调整决策。这些示例表明,语言模型不仅能在虚拟环境中自我学习,还能够与现实世界进行互动并执行复杂任务
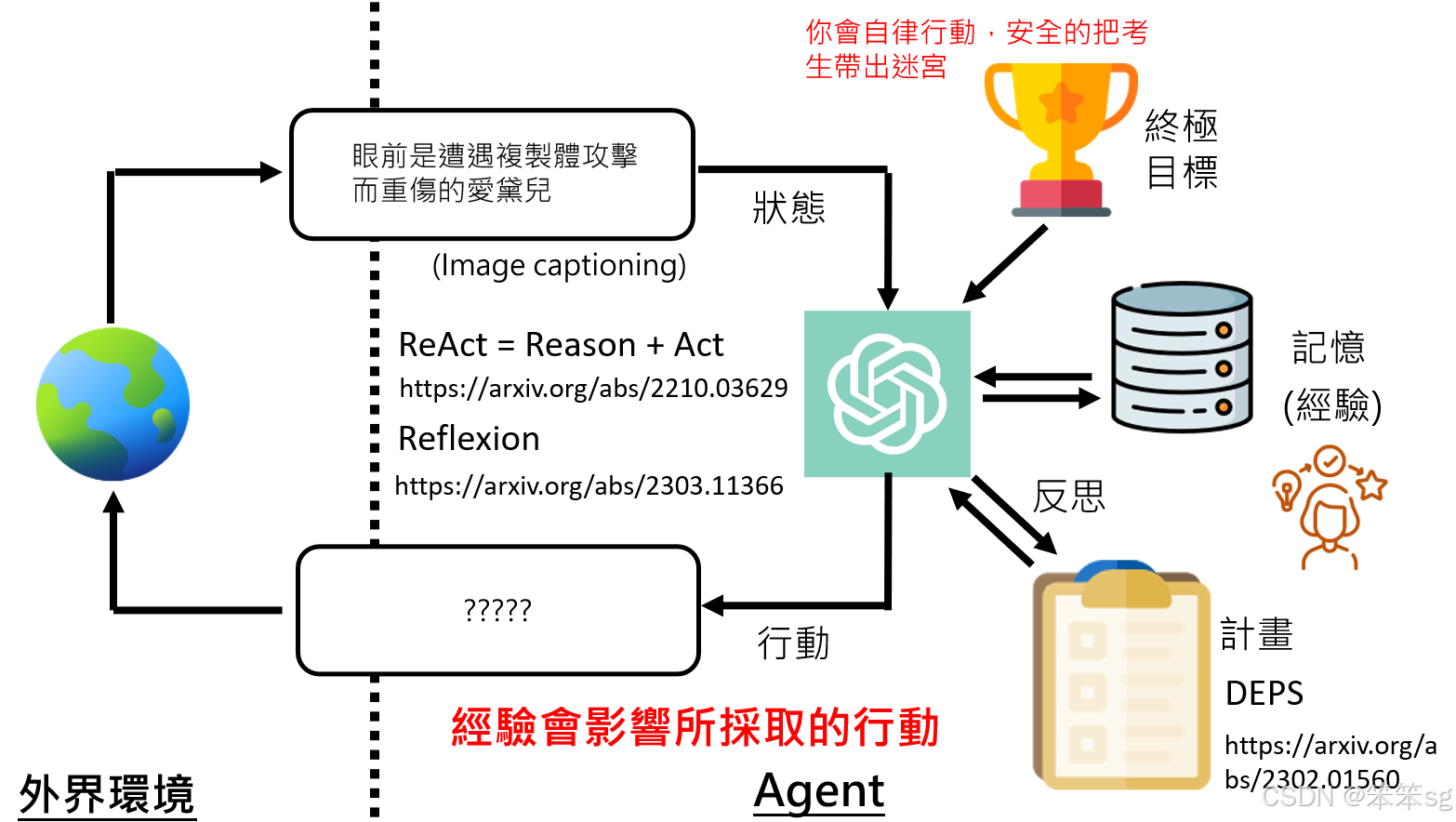
4 AI Agent背后的运作原理
下面我们来简单介绍一下Agent背后的运作原理
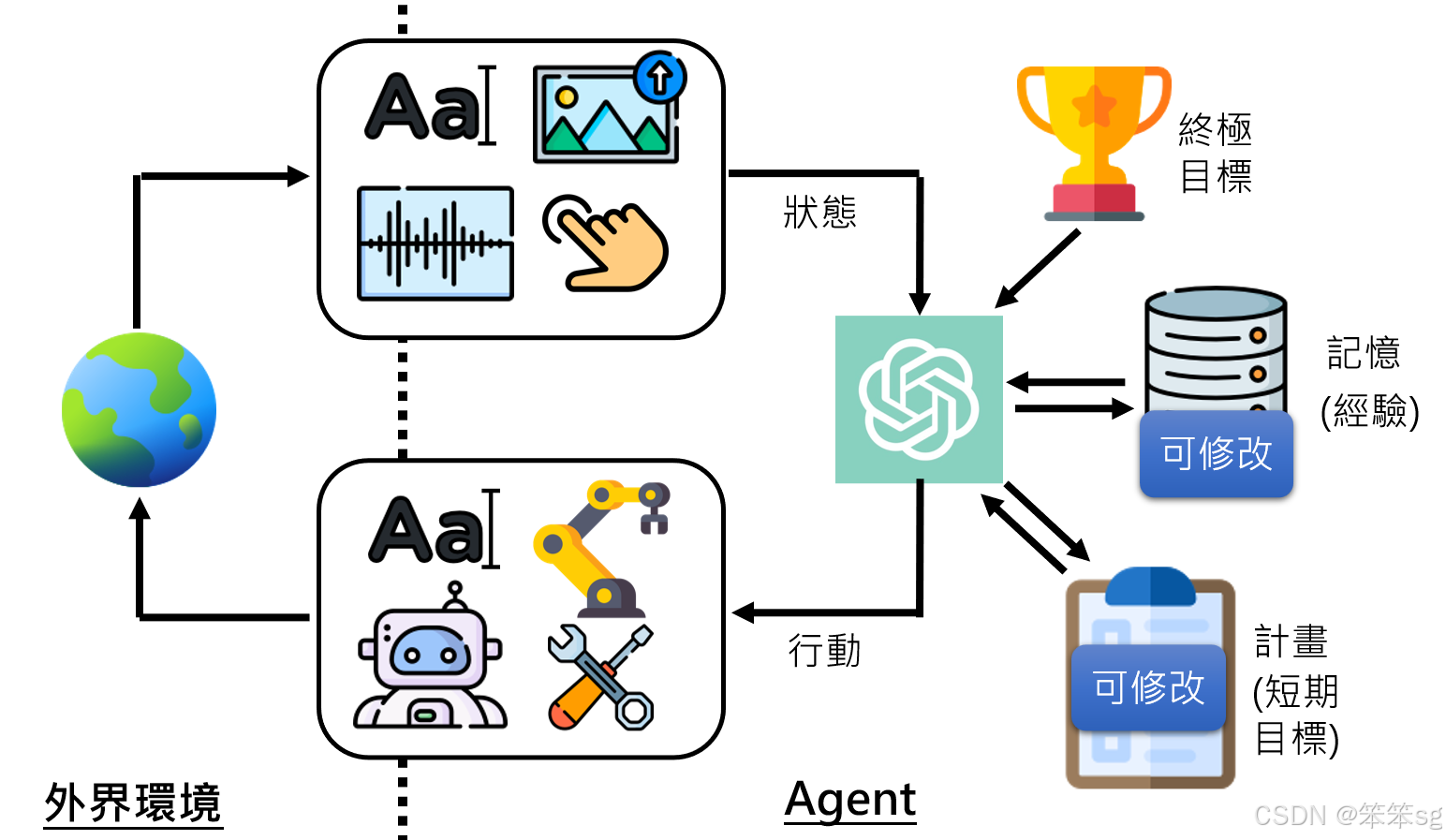
如上图所示:
-
目标和记忆:AI agent的终极目标是完成某个任务,而它会通过记忆来存储与环境互动过程中获得的经验。这个记忆是AI与环境互动的基础,可以帮助AI从过去的经历中学习。
-
感知外界:AI agent能够通过各种感知器(如文字输入、视觉、听觉、触觉等)了解外界的状态。这些感知器可以帮助AI获取当前的环境信息。
-
制定计划:根据终极目标、记忆和外界状态,AI agent会制定短期目标和计划,以便采取相应的行动。这些计划是AI实现目标的步骤,可能包括输出文字、生成图像、发声、操作机械手臂等。
-
执行行动:AI agent执行行动后,会对环境产生影响,改变外界世界的状态。这些行动可以包括通过编写程序控制机械设备,或者与其他AI互动等。
-
反馈和学习:AI agent在执行行动后,环境的状态会发生变化,AI agent根据这些变化修改记忆,调整计划,使得其行动更灵活并适应变化的环境。AI agent不会死板地按照最初的计划执行,而是根据外界反馈动态调整。
-
AI agent的现状与发展潜力:今天的语言模型已经具备了一定的能力,可以进行记忆修改、制定和调整计划等操作。因此,虽然现在AI agent的应用还不广泛,但未来可能会快速发展,并且在一两年内得到更广泛的应用。
5 有记忆的ChatGPT
-
当前的ChatGPT没有长期记忆:ChatGPT在每次新对话开始时,都会清空之前的对话内容。也就是说,每次与ChatGPT对话时,它不会记得之前的对话,所有信息都需要从头开始。
-
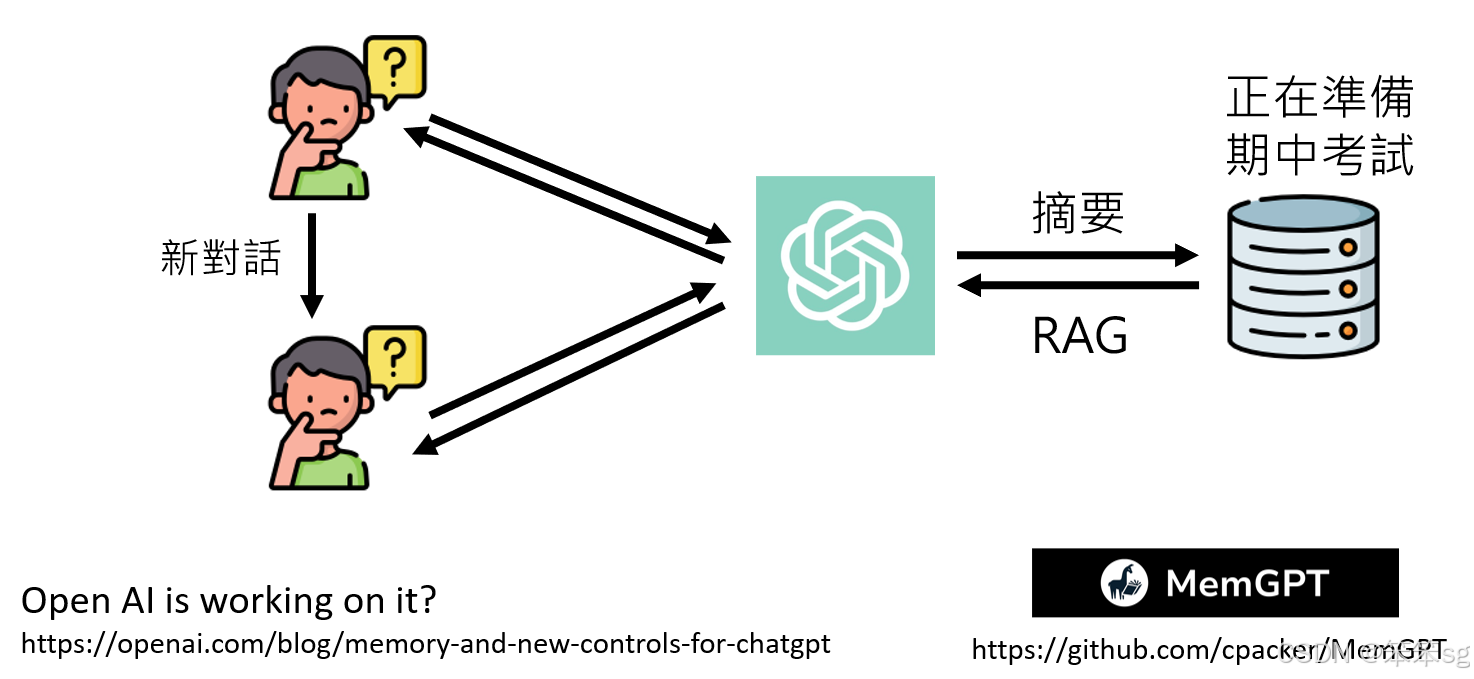
OpenAI曾尝试打造有记忆的ChatGPT:OpenAI曾在博客中提到过计划打造具有记忆功能的ChatGPT,声称此功能能让模型在对话之间记住关键信息,如知道用户正在准备期中考试等。然而,尽管这一功能曾经在某些用户中出现过,但目前这一功能并未广泛推出,也没有出现在常规的ChatGPT账号中。
-
记忆的运作方式:如果ChatGPT拥有记忆,它可能会在每次对话结束后,对对话内容进行摘要,保存其中的关键信息。例如,它可能会知道用户正在准备期中考试,并在下一次对话时通过提问或回顾之前的信息提供更个性化的帮助。
-
记忆的潜在影响:拥有记忆功能的ChatGPT可以更加个性化地与用户互动。例如,下一次对话时,它可能会问用户期中考试的结果或根据记忆提供更加贴切的建议和反馈。
-
Memory GPT论文:许多研究者正在尝试通过改进大型语言模型来使其具备记忆能力。例如,论文《Memory GPT》展示了如何给大型语言模型添加记忆,使其能在对话之间保留和学习用户的历史信息。
6 Agent的例子——芙莉莲的故事
这个故事详细描绘了一个AI代理(AI agent)——格列姆(Golem),它是基于大型语言模型运作的自主行动体,在一个虚构的魔法世界中发挥着至关重要的作用。通过这个例子,我们可以深入理解AI代理如何通过记忆、目标、状态和反思来优化行动,并应对复杂任务。以下是更详细的总结:

6.1 格列姆的基本设定和功能
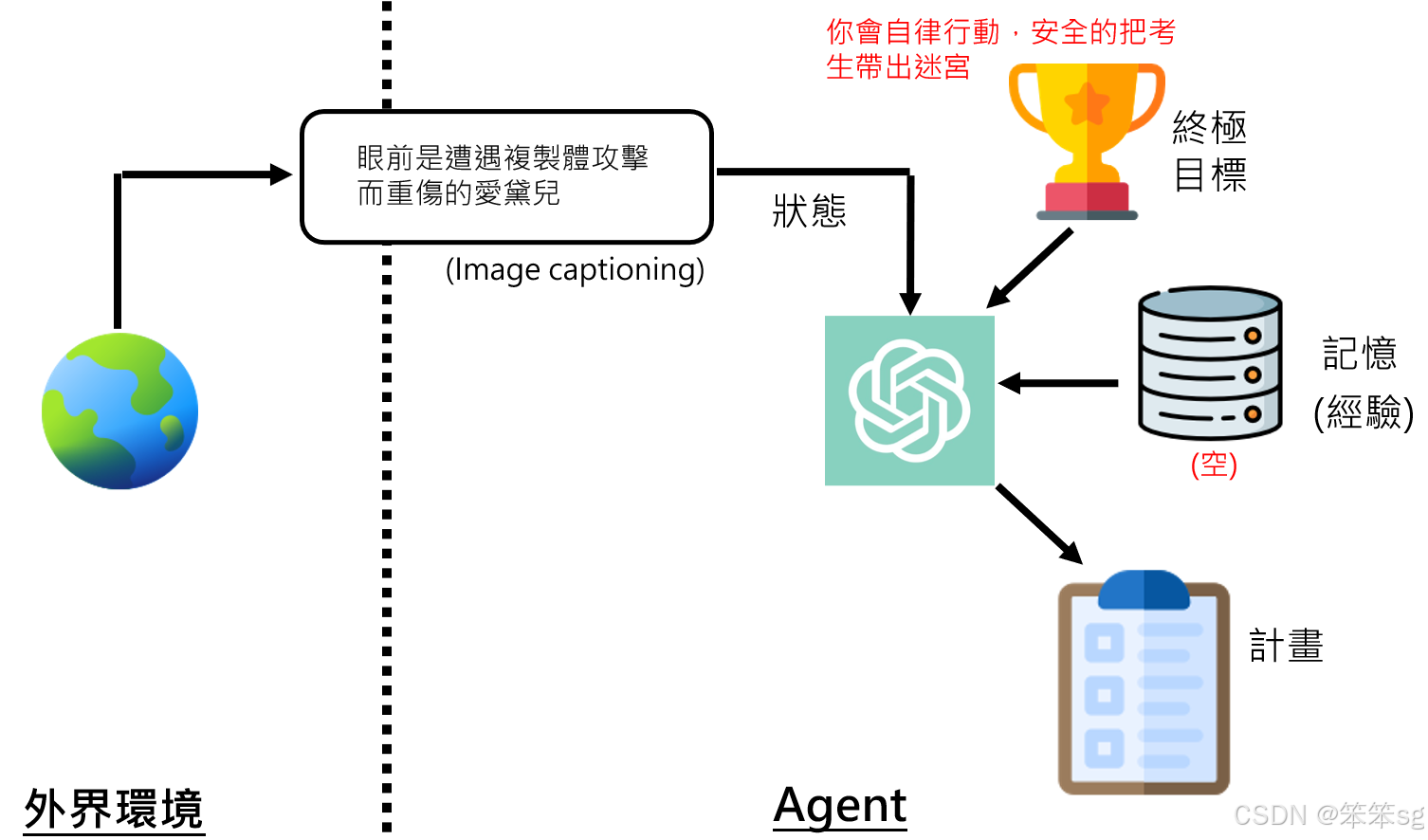
- 背景设定:在芙莉莲的魔法师考试中,考生需要进入一个危险的迷宫。在进入迷宫之前,每位考生都会被提供一个叫做“逃脱用格列姆”的物品,这是一种装在瓶子里的泥人。格列姆的作用是,当考生遇到危险时,可以打破瓶子,释放出格列姆来保护考生并带其逃脱。
- 格列姆的初始状态:格列姆在开始时并没有记忆,它只是一个由大型语言模型驱动的AI代理。其唯一的目标是:确保考生的安全,并安全地将考生从迷宫中带出。

6.2 格列姆的行动流程和决策
- 目标和状态识别:当格列姆被释放后,它首先面临的任务是评估当前的环境。艾黛尔(考生)遭遇了敌人攻击并受伤,因此格列姆的目标是“自律行动,确保艾黛尔安全离开迷宫”。
- 输入信息和决策:格列姆的决策过程基于当前的环境状态和其目标。例如,它知道艾黛尔受伤,因此其任务是帮助艾黛尔评估伤势、提供急救等。这些行动通过语言模型生成的文字指令来表示,如“立即评估伤势”,“施予急救”等。


6.3 从文字到行动的转化
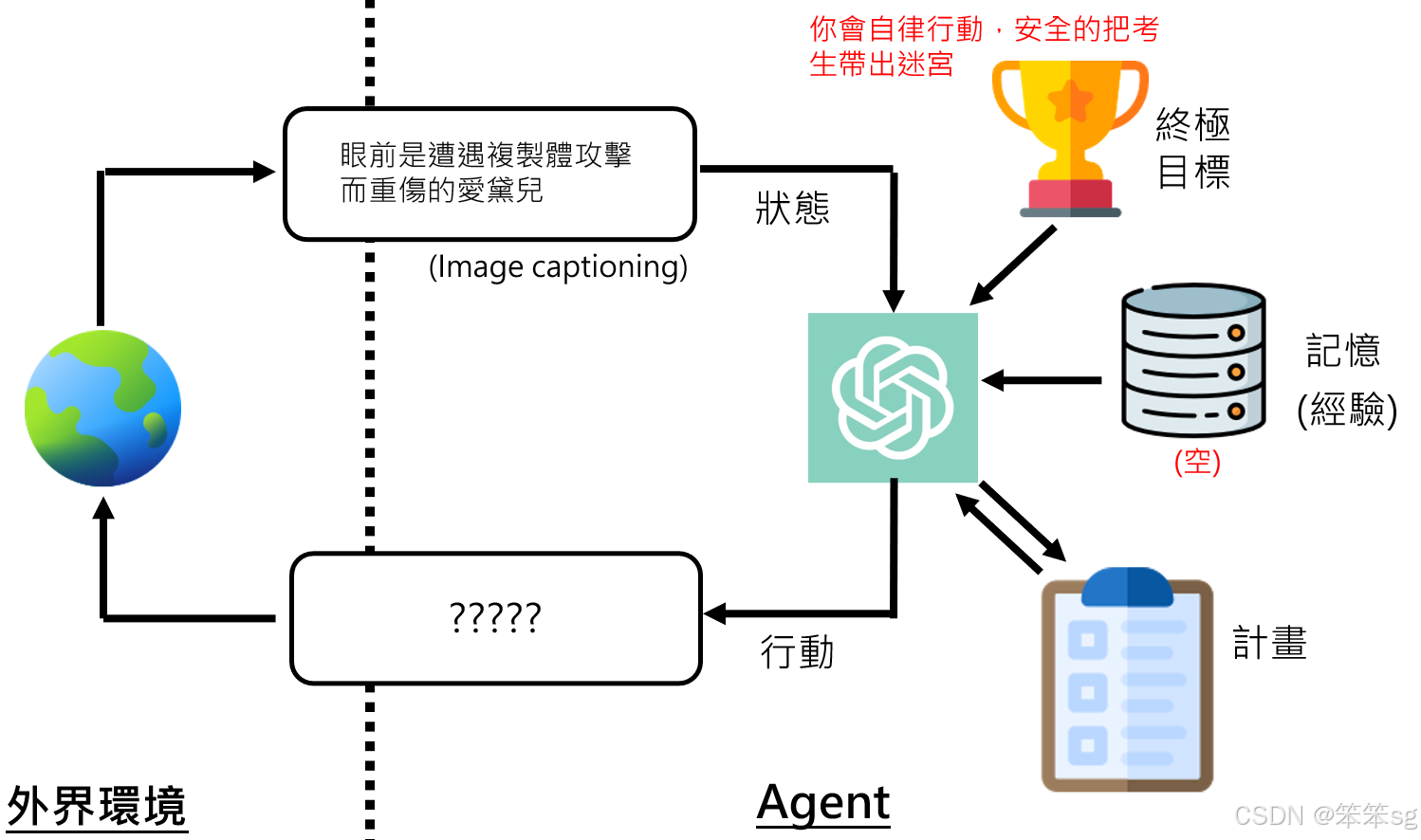
- 行动指令的生成:格列姆的决策不仅仅依赖于目标,还要根据具体的环境输入(例如,艾黛尔的伤势和敌人攻击的情况)来生成具体的行动计划。例如,格列姆会评估伤势并执行急救,但更重要的是它要注意周围的环境,因为敌人的威胁仍然存在。
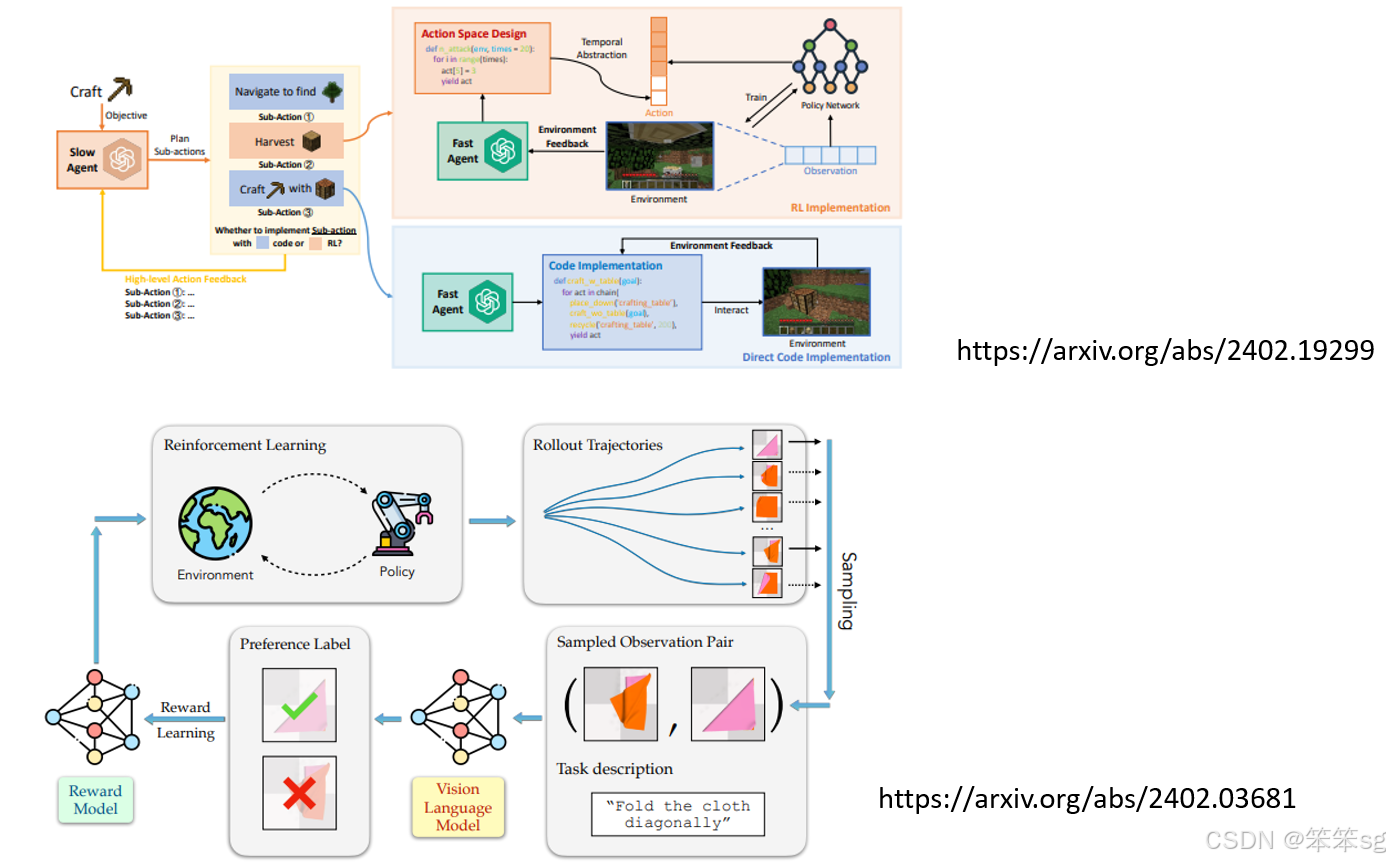
- “Slow Agent”和“Fast Agent”的结合:为了将这些文字指令转化为真实的行动,AI系统采用了“slow agent”和“fast agent”的结合:
- Slow Agent:负责高层次的决策,生成自然语言的行动计划(例如:“评估伤势”,“施予急救”)。
- Fast Agent:负责低层次的执行,将高层次指令转化为实际可执行的行为,可能通过程序代码或神经网络模型来实现。例如,它可以控制机器人执行具体的动作,如为艾黛尔检查伤口。
6.4 反应与环境变化
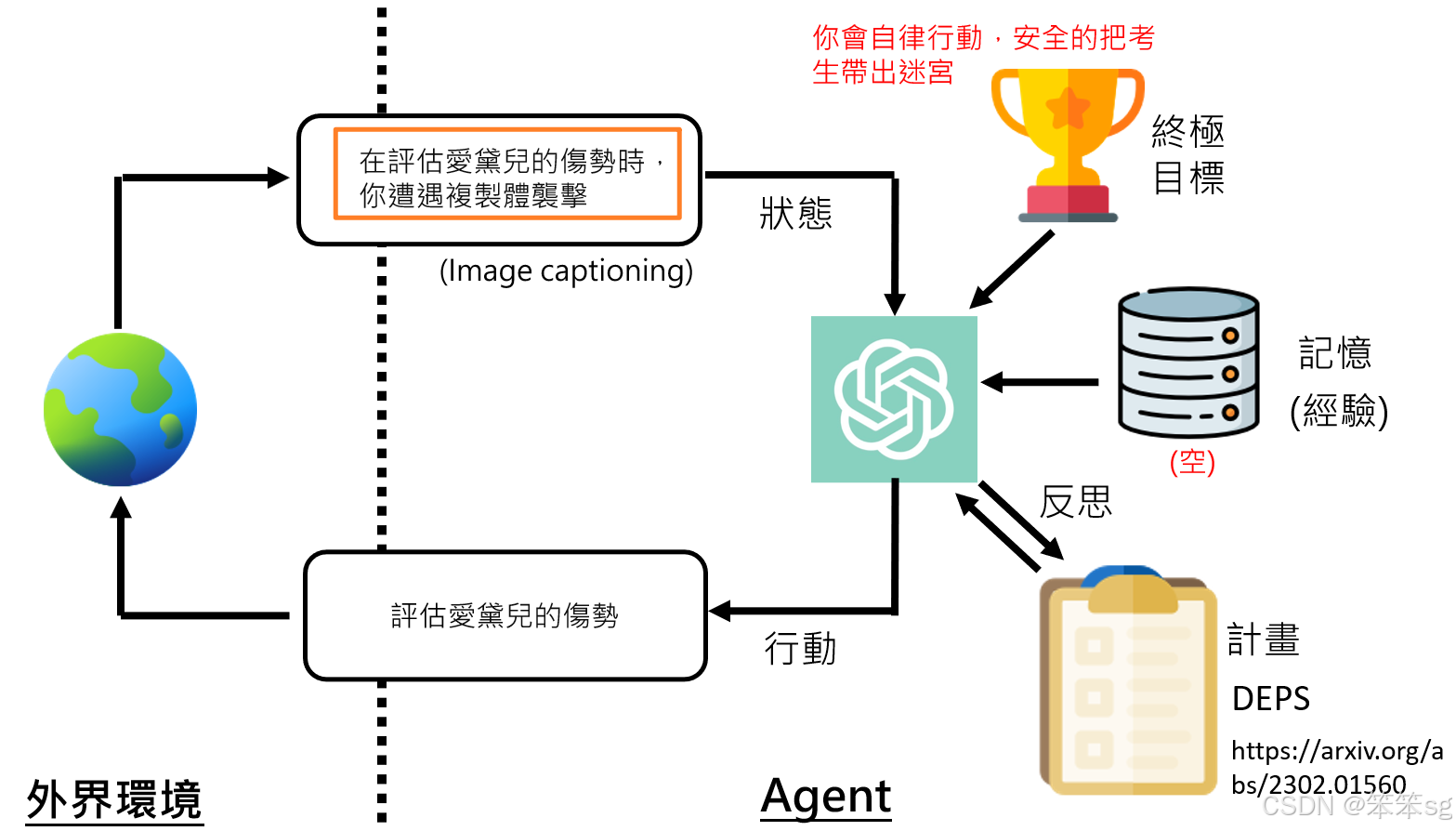
- 动态调整行动计划:在格列姆执行行动时,外部环境可能会发生变化。例如,在评估艾黛尔伤势时,格列姆遇到了敌人攻击,外部威胁增加了。这时,格列姆必须调整其行动计划,优先保护艾黛尔,而不是继续评估伤势。语言模型能够根据新的环境变化自动调整原有的计划,以应对突发情况。
- 语言模型的反思能力:在复杂环境中,格列姆不仅能够调整行动,还能反思其过去的经历,并从中获取经验。这种反思能力使得格列姆能够在未来的类似情境中作出更加明智的决策。例如,在后续的行动中,格列姆会保持对环境的高度警觉,避免再次陷入类似的危险。
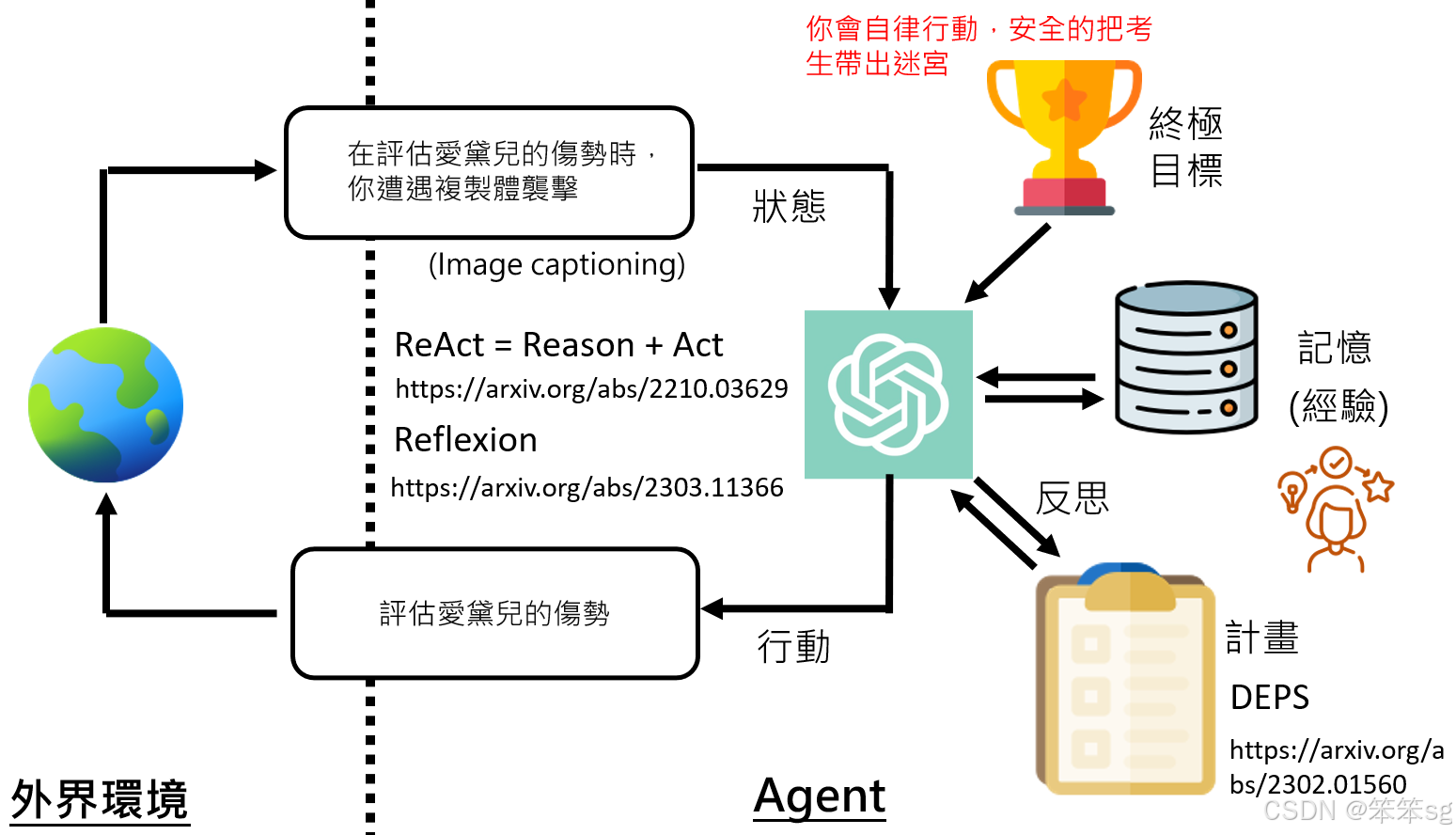
6.5 记忆和学习的引入
- 记忆机制:格列姆最初没有记忆,但随着任务的进行,它开始积累经验。当格列姆遇到新的威胁或变化时,它能够根据记忆中的经验调整策略。例如,如果格列姆在之前的任务中发现某些威胁导致失败,它会记住这些威胁并在以后的行动中更加警觉。
- 影响行为的记忆:格列姆根据记忆生成新的行动计划。比如,在没有记忆的情况下,格列姆的第二步行动计划是“立即施予急救”。但有了记忆后,行动计划会变为“保持警觉性,优先保护艾黛尔”。这反映了记忆和经验对决策的深远影响。



6.6 技术实现的挑战
- 将语言转化为具体行动:当前的技术中,虽然语言模型可以生成高层次的指令,但如何将这些文字指令转化为可以在物理世界中执行的行动仍然是一个巨大的挑战。为了实现这一目标,AI系统需要有高效的执行机制,如“Fast Agent”模型,或者直接生成代码来驱动机械执行这些指令。
- 计划的动态调整:当环境状态变化时,格列姆的行动计划必须做出相应调整。这要求AI代理不仅能生成固定的行动计划,还能实时分析并应对新的挑战。反思机制在这一过程中非常关键,它帮助AI在执行任务后从经验中学习,从而改善未来的决策。
7 延申阅读
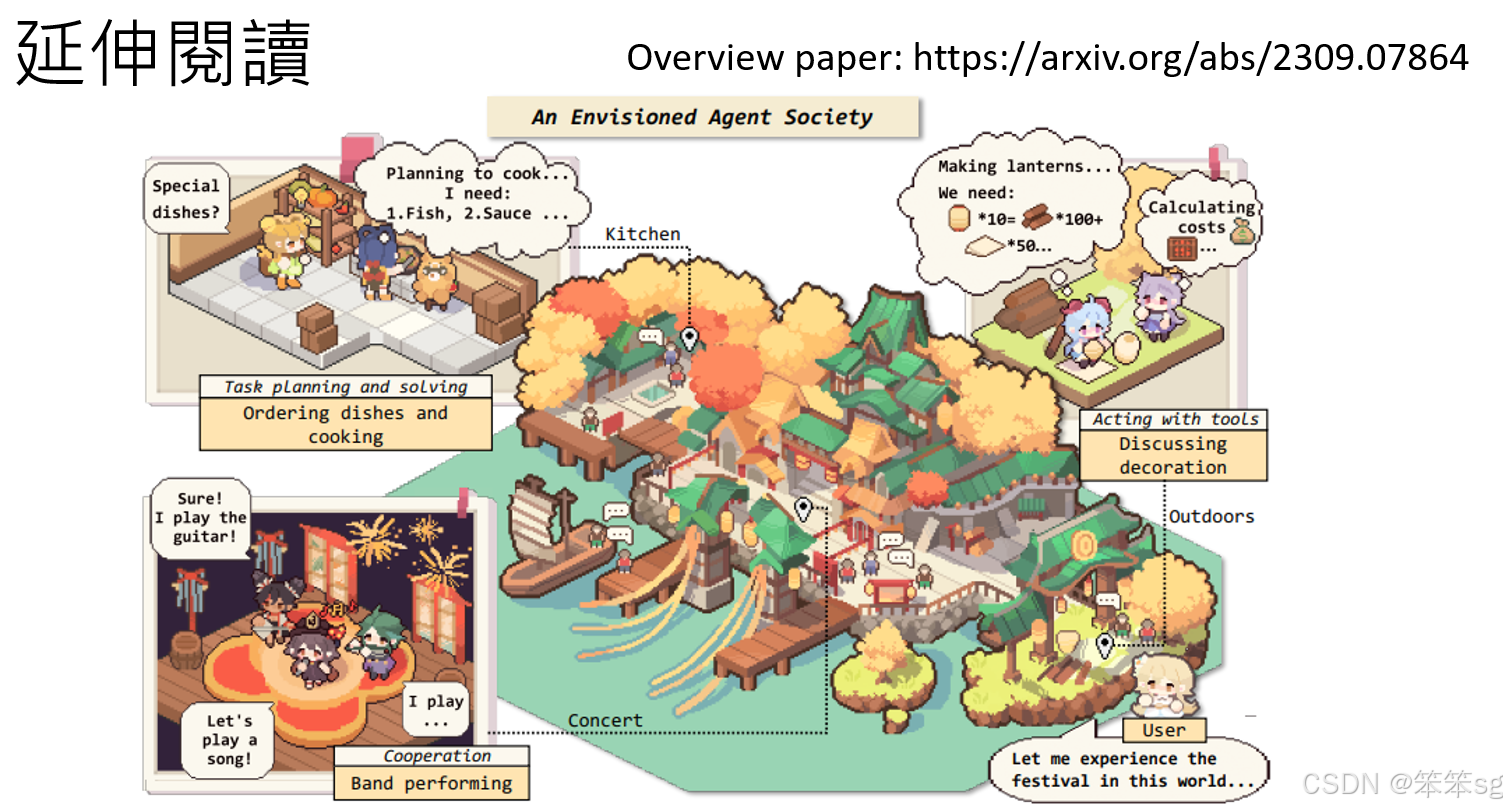
如果你想要知道更多AI agent的事情的话,我这边放了一篇overview paper,然后这个图是从overview paper里面截取出来的啦,这是作者想象了一个未来,重构了AI agent的虚拟世界。


















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









