






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
FPGA经验谈
前言
写一些FPGA使用经验、调试技巧等等,目的是为了提高效率。

加快FPGA开发模板
提示:以下是本篇文章正文内容,下面案例可供参考
FPGA语法速查:
数据截取(在generate语法中使用非常方便)
vect[a +: b]或vect [a -: b]
a表示起始位,b表示数据位宽,+,-表示升序或者降序。
例如vect[2 +: 5]表示起始位是2,升序,数据位宽位5,那么从2往上数5个就是:2,3,4,5,6;所以这个表达式也就是代表了vect[2:6]。
同理vect[3 -: 4]就表示vect[3:0];
defparam使用(在仿真中使用非常方便)
注意:xilinx vivado中支持defparam语法~
altddio_in ALTDDIO_IN_component (
.datain (datain),
.inclock (inclock),
.dataout_h (sub_wire0),
.dataout_l (sub_wire1),
.aclr (1'b0),
.aset (1'b0),
.inclocken (1'b1),
.sclr (1'b0),
.sset (1'b0));
defparam
ALTDDIO_IN_component.intended_device_family = "Cyclone V",
ALTDDIO_IN_component.invert_input_clocks = "OFF",
ALTDDIO_IN_component.lpm_hint = "UNUSED",
ALTDDIO_IN_component.lpm_type = "altddio_in",
ALTDDIO_IN_component.power_up_high = "OFF",
ALTDDIO_IN_component.width = 14;
一、Xilinx FPGA Block Design降低版本
使用低版本的vivado打开工程,然后File–>Export–>Block Design.生成system.tcl,然后新建FPGA工程,在FPGA工程中执行Tcl—>Run tcl Script…,选择system.tcl。Block Design重新生成后,跑Run Validation,如果没有报错说明没有问题。但是有的时候并不是所有IP都支持兼容,但是block design内部的部分IP可以复用,也可以节省时间。

二、Select IO使用
主要参考文档:
SelectIO Interface Wizard v5.1(pg070)
https://xilinx.eetrend.com/blog/2019/100043797.html :Xilinx 7系列FPGA之SelectIO(3)——高级IO逻辑资源简介
测试工程中的配置:
1.cfg_4lane8data_ddr_internal:使用了4条lane,串行率为8,双边沿采样(DDR),使用内部时钟
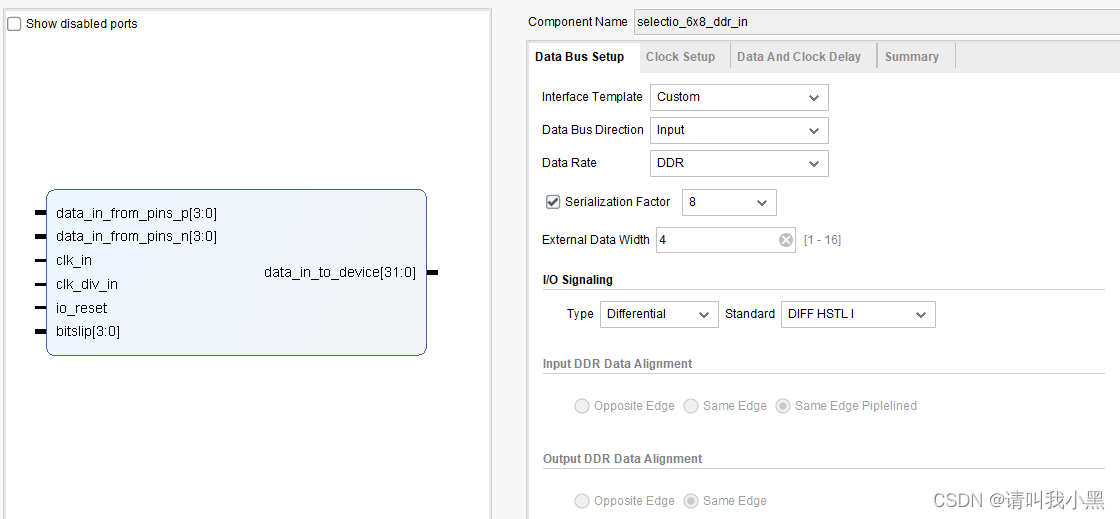
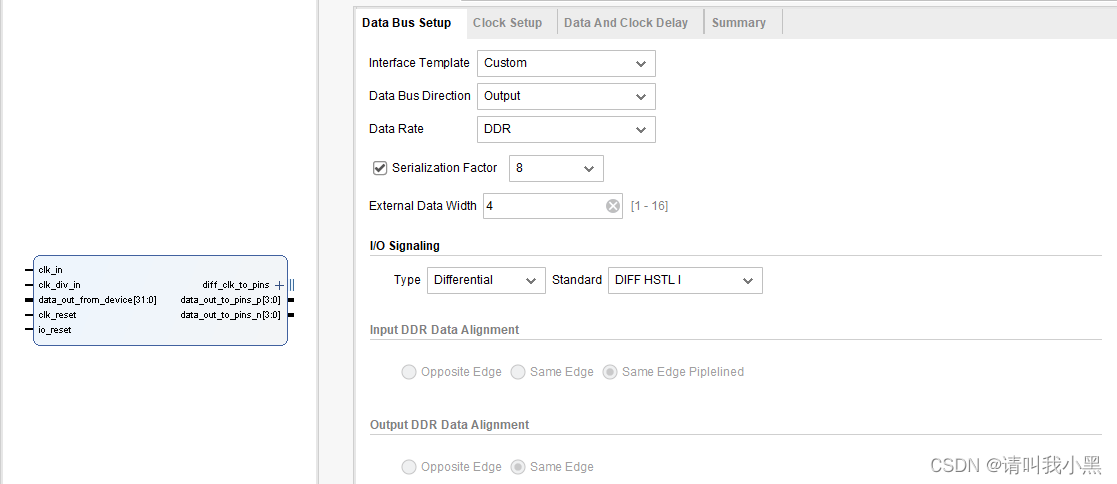
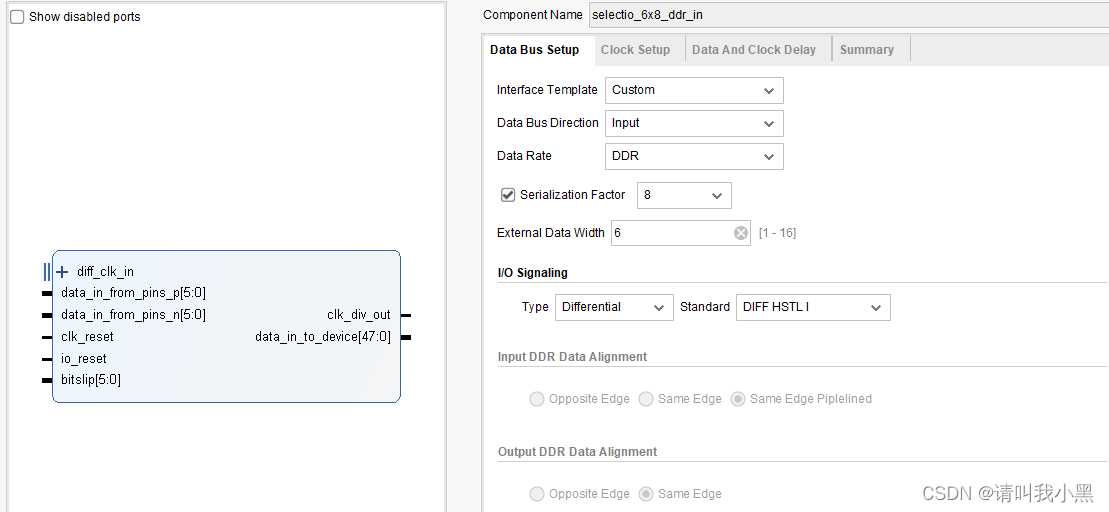
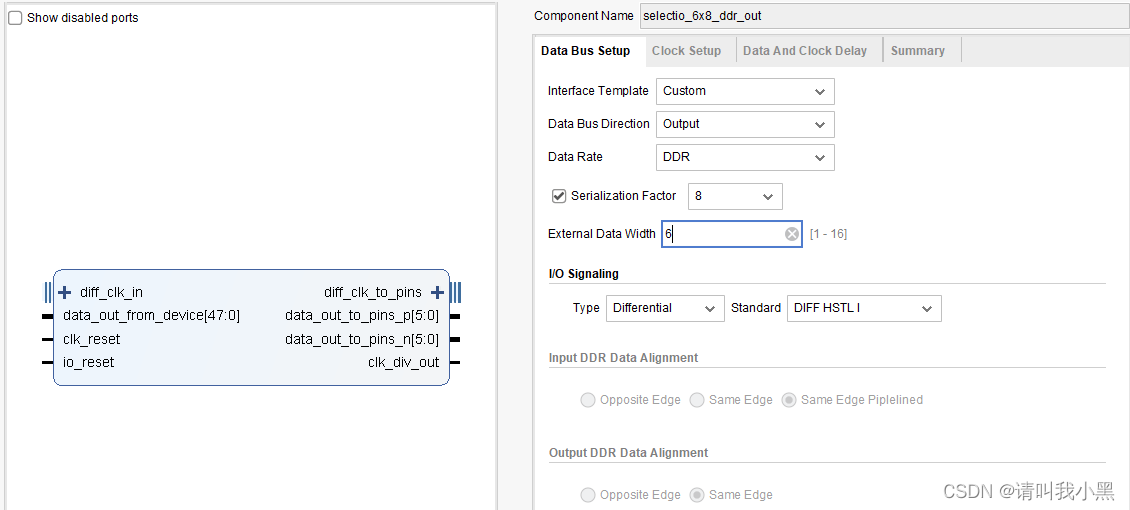
2.cfg_4lane8data_ddr_internal:使用了6条lane,串行率为8,双边沿采样(DDR),使用外部时钟
重点说明:
内部时钟与外部时钟:,如果选择内部时钟,那么在FPGA工程中,使用MMCM给clk_in和clk_div_in信号提供信号,两个信号时钟速率关系为:clk_in=clk_div_in*(串行化因子/ddr_or_sdr),这里如果IP设置了DDR,则ddr_or_sdr2;否则ddr_or_sdr1。如果选用外部时钟,那么直接从管脚输入时钟,IP核内部使用BUFR对输入差分时钟进行分频得到clk_div_out,该时钟实质上等价于clk_div_in,用作后续逻辑模块的时钟。
clk_reset与io_reset:,关于这两个复位,clk_reset是与输入时钟clk_in或者差分管脚输入时钟diff_clk_in相匹配的复位。对于io_reset用来复位后续逻辑模块的复位信号,可以认为io_reset信号,用来复位clk_div_out(clk_div_in)时钟域下的逻辑。手册上有提到,需要等待clk_in时钟稳定后,才能对io-reset信号进行解复位。因此,我的测试工程里,使用一个5bit计数器(clk_div_in域下,复位在clk_reset),当计数满时,对io_reset信号解复位。
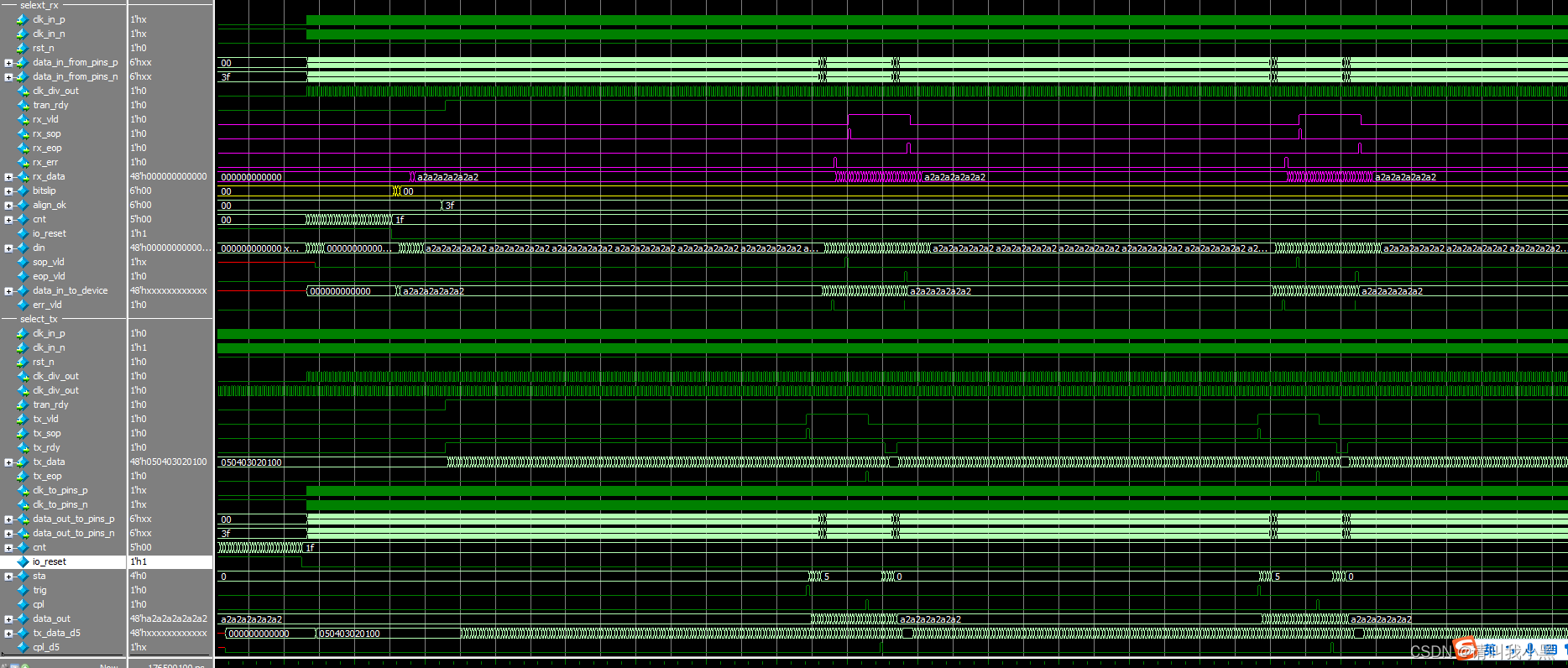
数据训练Training:,数据训练是按照lane为单位进行训练的,每条lane单独训练,即通过bitslip信号让发送数据和接收数据一致。在初始状态下,select_io tx默认时钟发送训练字节(TRAIN_WORD),select_io rx接收该数据,通过bitslip信号,让每条lane收到的数据为TRAIN_WORD,当所有lane训练成功之后,使用信号rx_tran_rdy来表示训练完成。
数据对不齐问题:,lane之间数据相差一拍,这个问题不知道为啥,最后解决方法是,系统解复位后,先将bitslip置1(15个时钟,8个时钟还不行),之后再正常使用bitslip,最后才解决该问题。
数据包发送:,数据包发送自定义格式,这里以连续发送{SYNC_CODE_1S、SYNC_CODE_2S、SYNC_CODE_3S、SYNC_CODE_SOP}作为包起始信号,以连续发送{SYNC_CODE_1S、SYNC_CODE_2S、SYNC_CODE_3S、SYNC_CODE_EOP}作为包结束信号。如果对数据正确度要求非常高,也可以在包尾部加入CRC校验,像以太网数据包格式那样,测试工程中没有加入CRC。
localparam SYNC_CODE_1S = 8'hAA ;
localparam SYNC_CODE_2S = 8'h55 ;
localparam SYNC_CODE_3S = 8'hFF ;
localparam SYNC_CODE_SOP = 8'h01 ;
localparam SYNC_CODE_EOP = 8'h02 ;
input tran_rdy ,//(i) 表示训练完成
input tx_vld ,//(i) 发送包数据vld信号,注意:该信号需要连续,不能断
input tx_sop ,//(i) 包头标志
output reg tx_rdy ,//(o) 表示可以发送一个包数据
input [DEV_W -1:0] tx_data ,//(i) 包数据
input tx_eop ,//(i) 包尾标志
测试工程代码自动插入包起始信号和包结束信号,对于用户侧而言,只需要关注产生具体包数据格式,包数据格式如上面代码所示,有点类似于以太网数据包。
部分仿真截图:
三、JTAG2AXI调试
有时候使用Microblaze调试并不是很方便,比如硬件上需要有串口,而且软件上需要移植代码,最终交付时Microblaze需要注释掉等等。所以引入JTAG2AXI调试工具很有必要。以下是一些参考资料:
JTAG-to-AXI Master调试AXI BRAM Controller:
https://blog.csdn.net/clj609/article/details/124933535
https://zhuanlan.zhihu.com/p/527052311
JTAG to AXI Master v1.2(pg174)
以下是一些常用命令:
create_hw_axi_txn rd_txn [get_hw_axis hw_axi_1] -address 50010000 -len 8 -size 32 -type read
create_hw_axi_txn rd_txn [get_hw_axis hw_axi_1] -address 50010000 -len 8 -size 32 -type read
# axi write 1byte*4
create_hw_axi_txn -force wr_txn_lite [get_hw_axis hw_axi_1] -address 50010040 -data 12345678 -type write
run_hw_axi wr_txn_lite
# axi read 1byte*4
create_hw_axi_txn -force rd_txn_lite [get_hw_axis hw_axi_1] -address 50010040 -type read
run_hw_axi rd_txn_lite
# axi read 8byte*4
create_hw_axi_txn -force rd_txn_lite [get_hw_axis hw_axi_1] -address 50010040 -len 8 -size 32 -type read
run_hw_axi rd_txn_lite
# axi write 8byte*4
create_hw_axi_txn -force wr_txn_lite [get_hw_axis hw_axi_1] -address 50010040 -data {11111111_22222222_33333333_44444444_55555555_66666666_77777777_88888888} -len 8 -size 32 -type write
run_hw_axi wr_txn_lite
# ---------------------------------------------------------------
# 对Tcl命令进行分装
#-----------------------------------
# Read CONTROL
#-----------------------------------
proc ReadReg { address } {
global data_list
global num
# axi read channel command
create_hw_axi_txn read_txn [get_hw_axis hw_axi_1] -address $address -type read
run_hw_axi read_txn
# complete one read transaction
delete_hw_axi_txn read_txn
}
#-----------------------------------
# Write CONTROL
#-----------------------------------
proc WriteReg { address data } {
global data_list
global num
# axi write channel command
create_hw_axi_txn write_txn [get_hw_axis hw_axi_1] -address $address -data $data -type write
run_hw_axi write_txn
# complete one write transaction
delete_hw_axi_txn write_txn
}
# 调用方式
WriteReg 00000008 00000003
ReadReg 00000008
# 封装命令,让寄存器读写更加方便一些
# ------------------------------------------------------------------------------------------
proc rd { address } {
global data_list
global num
# axi read channel command
create_hw_axi_txn read_txn [get_hw_axis hw_axi_1] -address $address -type read
run_hw_axi read_txn
# complete one read transaction
delete_hw_axi_txn read_txn
}
proc rd2 { address len} {
global data_list
global num
# axi read channel command
create_hw_axi_txn read_txn [get_hw_axis hw_axi_1] -address $address -len $len -size 32 -type read
run_hw_axi read_txn
# complete one read transaction
delete_hw_axi_txn read_txn
}
#-----------------------------------
# Write CONTROL
#-----------------------------------
proc wr { address data } {
global data_list
global num
# axi write channel command
create_hw_axi_txn write_txn [get_hw_axis hw_axi_1] -address $address -data $data -type write
run_hw_axi write_txn
# complete one write transaction
delete_hw_axi_txn write_txn
}
四、7 series FPGA DDR3调试
调测试方法:
基于之前在VU19P平台上使用过DDR4,但是IP Core并没有自己动手实例化。为了更好的调测DDR IP Core,我想到使用JTAG来进行测试,当然也可以使用axi4或者ddr原生app接口来测试,但是这样测试还需要自己动手写一个测试代码,有点繁琐。JTAG测试DDR的基本方法是,使用JTAG2AXI IP Core,然后将入AXI DATA Converter,实现JTAG与DDR3 AXI4接口的互联,Block Design如下图所示。下载程序后使用JTAG读写DDR,查看能否读写成功。
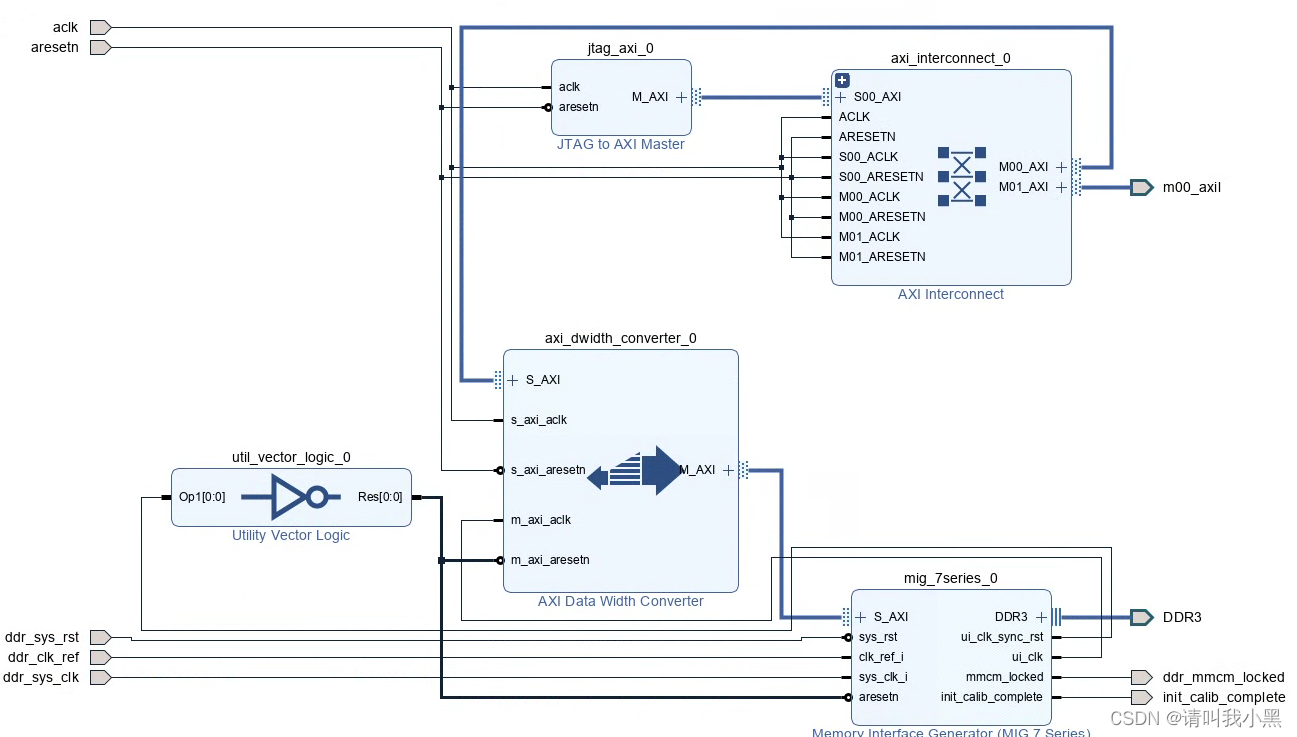
DDR3 IP的使用方法
- 时钟相关
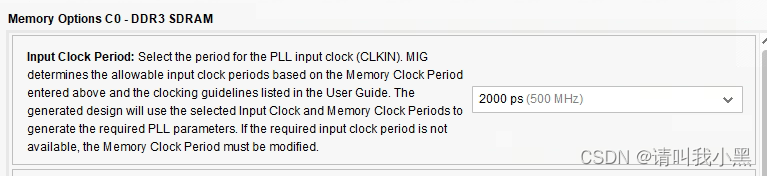
ui_clk:用户接口时钟,用于原生app接口发送或者接收数据提供时钟信号,如果接口为AXI4,则为AXI4接口提供时钟。ui_clk时钟计算方法为,DDR IO时钟的4:1或者2:1,由IP Core中设置。如下图所示ui_clk为500M/4=125MHz

sys_clk:系统时钟,该时钟接入DDR3 IP核之后,接入IP核内部的PLL,PLL内部分出DDR IO时钟及ui_clk。这个时钟选择需要注意,不能随便选择,需要注意VCO的时钟频率不能超过1000MHz。由于用户只需要设置输入时钟,PLL内部倍频系数以及分频系数软件自己计算,极有可能导致VCO>1000MHz,因此建议sys_clk>=200Mhz。
clk_ref:该时钟主要为IP内部 IO Dealy模块提供时钟。对于DDR3 IO时钟<600M,该时钟固定为200Mhz,否则该时钟为300M/400Mhz。如果sys_clk==200Mhz,该时钟可以由sys_clk提供。
参考文章:
Xilinx vivado DDR3 MIG IP核中系统时钟、参考时钟解释及各个时钟的功能详解
DDR读写带宽计算:
以上面截图为例来推演,500M x 2 x 64 = 64000Mb/s = 64Gb/s(乘以2是因为DDR是双边沿采样)。由于DDR读写是读和写分开的,不能并发,因此带宽需要除以2,同时DDR需要刷新等操作,有效带宽得打7折,因此实际有效带宽为64Gb/2 x 0.7=22.4Gb/s。
使用ui_clk来计算,125M x 512=64000Mb/s=64Gb/s。
遇到的问题及解决方法:
1.Vivado 2018.3 MIG 7 series IP核 导致的闪退问题
2.vivado2020.2版本中,每次打开IP配置时,系统时钟变为下面选项,实际上自己修改该选项后,重新generate是有效的,但是在打开IP选项,又变回下面的样子。这个是IP核的BUG,不用管。
VIVADO报错:[opt31-67]之MIG ip核综合失败
2.complete_init信号初始化不成功,经过找bug发现,原来自己在工程中对ddr_addr[14]信号没有连接,只是用了ddr_addr[13:0]信号,这个bug找了好久,以后还是得仔细。
DDR3应用场景
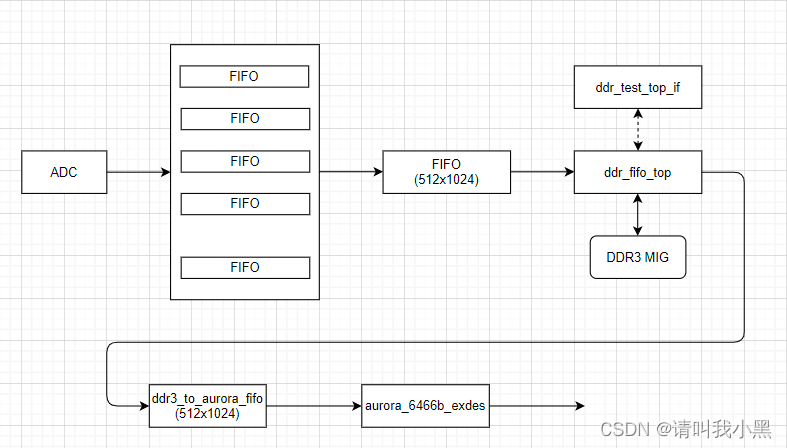
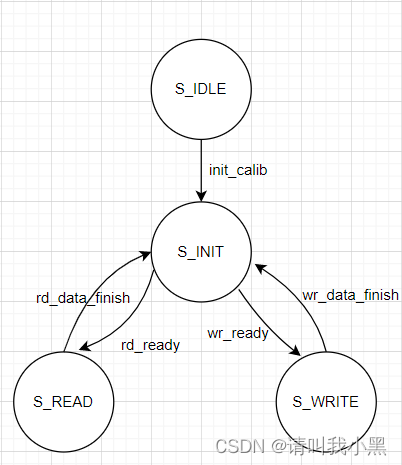
wr_ready:1.DDR未存满且rd_data_count>=WR_BURST_NUM。2.如果complete为高,且fifo不为空。
rd_ready:1.对面FIFO未满且ddr_store_num>=RD_BURST_NUM(即DDR内部有足够数据) 2.对面fifo未满,且comlete标志为高,且ddr内部有数据。
思考:这种方式利用DDR,挺使用的,比AXI接口的DDR更为实用,如果有多个通道使用DDR存储,那该如何使用呢?比如两个写通道,两个通道,我们可以用RR轮询调度读写DDR。
五、Aurora 8b10b调试
参考手册:1.pg046-aurora-8b10b 2.aurora_8b10b_protocol_spec_sp002
使用情况:1lane环回测试,配置如下:
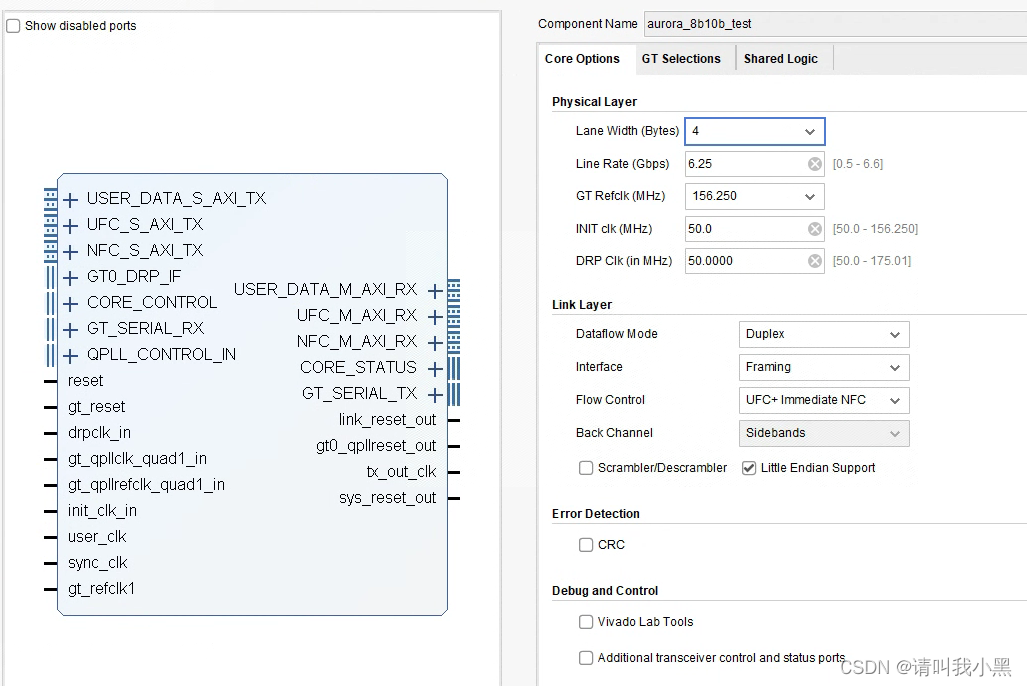
这个选项重点说明:
Inerfcae: 可以选择Framing和Streaming。两个都是axi-stram接口,Framing是完整的axi-streaming(适用于以包形势的数据发送),而Streaming接口是简化版的axi-streaming(适用于大数据量的数据传输,接口类似fifo,应为没有tlast信号)。
Flow Control: 这个接口挺重要的,对于数据传输,为了达到满流量,需要有反压的机制,Aurora也不例外。试想,当接收端从Aurora接收数据,用户逻辑从axi-streaming接口读取比较慢,而对端设备(Aurora发送)发送比较快,那么接收端的FIFO就会溢出,或者Aurora接收丢包,为了避免这种情况需要Flow Control机制。Aurora Flow Control机制有两种:UFC和NFC,这两种机制的具体使用方法可以参看datasheet。
Littile Endian: 这个选项几乎是必选,即高字节放在高位,低字节放在地位。
user_clk频率计算:user_clk = line_rate /10 * 8 /(lane_width) 以上面配置为例:6.25G/10*8/32=156.25MHz.
Aurora时钟: Aurora时钟是使用CPLL,追寻底层代码,CPLL使用的参考管脚是MGTREF0P/N,且参考时钟管脚不能修改。
六、Aurora 64b66b调试
参考文档:1.pg074-aurora-64b66b 2.aurora_64b66b_protocol_spec_sp011
user_clk公用:
最近查看IP手册发现,对于单条lane,一个Quad内,列化四份IP Core,对于Aurora 8b10b或者Aurora 64b66b IP core而言都可以公用一个user_clk,这一点很重要,可以减少时钟(而不是让每个IP core有一个user_clk),让逻辑简化。下面来分析为啥可以使用一个user_clk。
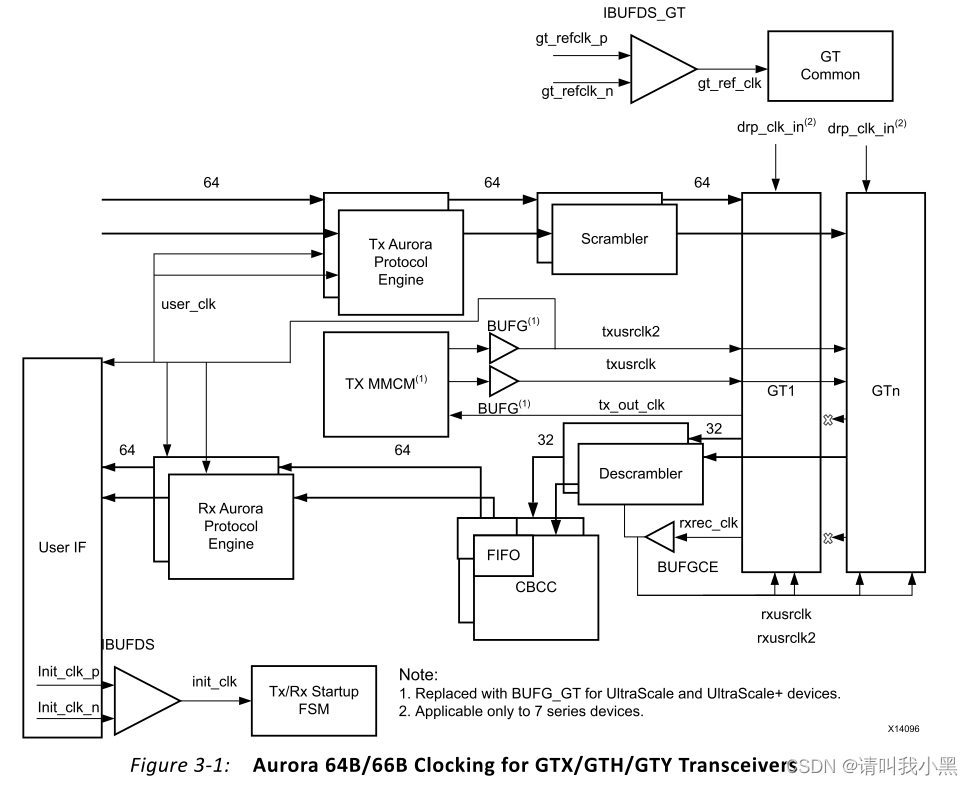
如上图所示的时钟结构,发现不同lane的txusrclk和txusrclk2都是由mmcm提供(该mmcm输入时钟由第一个channel的tx_out_clk作为输入源)。
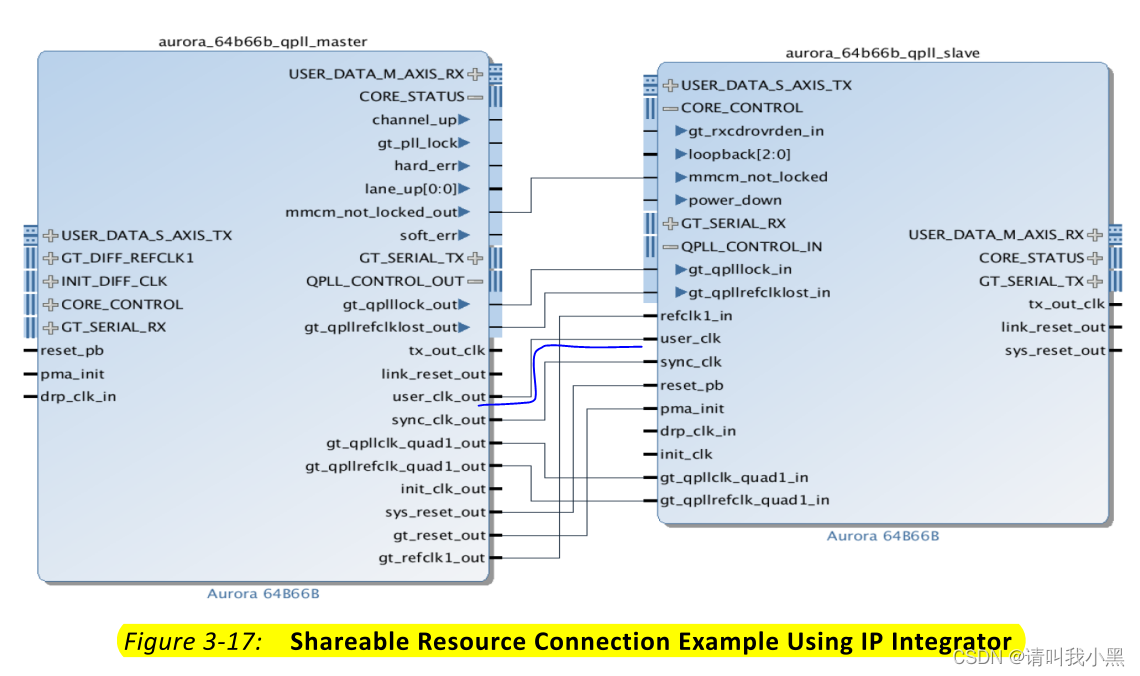
再看上图所示,当有多条lane时,使用user_clk_out连接到下一级channel的user_clk,这使得所有channel用户侧都是同一个时钟user_clk。
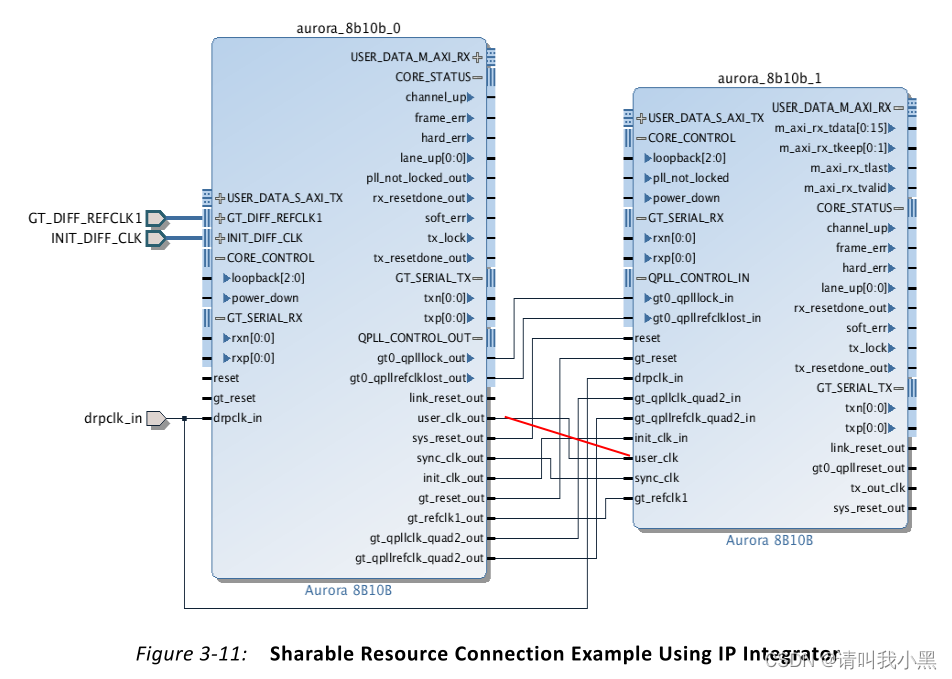
对于Aurora 8b10b也是如此。
Aurora 64b66b调试遇到的问题
1.example design中的MMCM输入频率,由于自己列化的MMCM IP输入时钟不对,导致无法link_up,这个问题很久才解决。
2.组合逻辑loop问题:这个问题是由于自己写的发包器,axis输出接口没有寄存器打拍,导致与IP互联时存在组合逻辑loop,使用Modelsim仿真是会报错,vivado综合时包组合逻辑环错误,通过查看Implement报告,看原理图,解决该问题(其实是tlast信号和tready信号形成了逻组合逻辑环,最好的解决方法是对发包器输出axis接口打怕)。
3.由于自己的疏忽,导致SERDES参考输入时钟没有进行时序约束(位置约束已经写了),进行多次跑版本的时候,发现Aurora有时能够link,有的版本无法link。通过对参考时钟管脚进行了时序约束,该问题得以解决
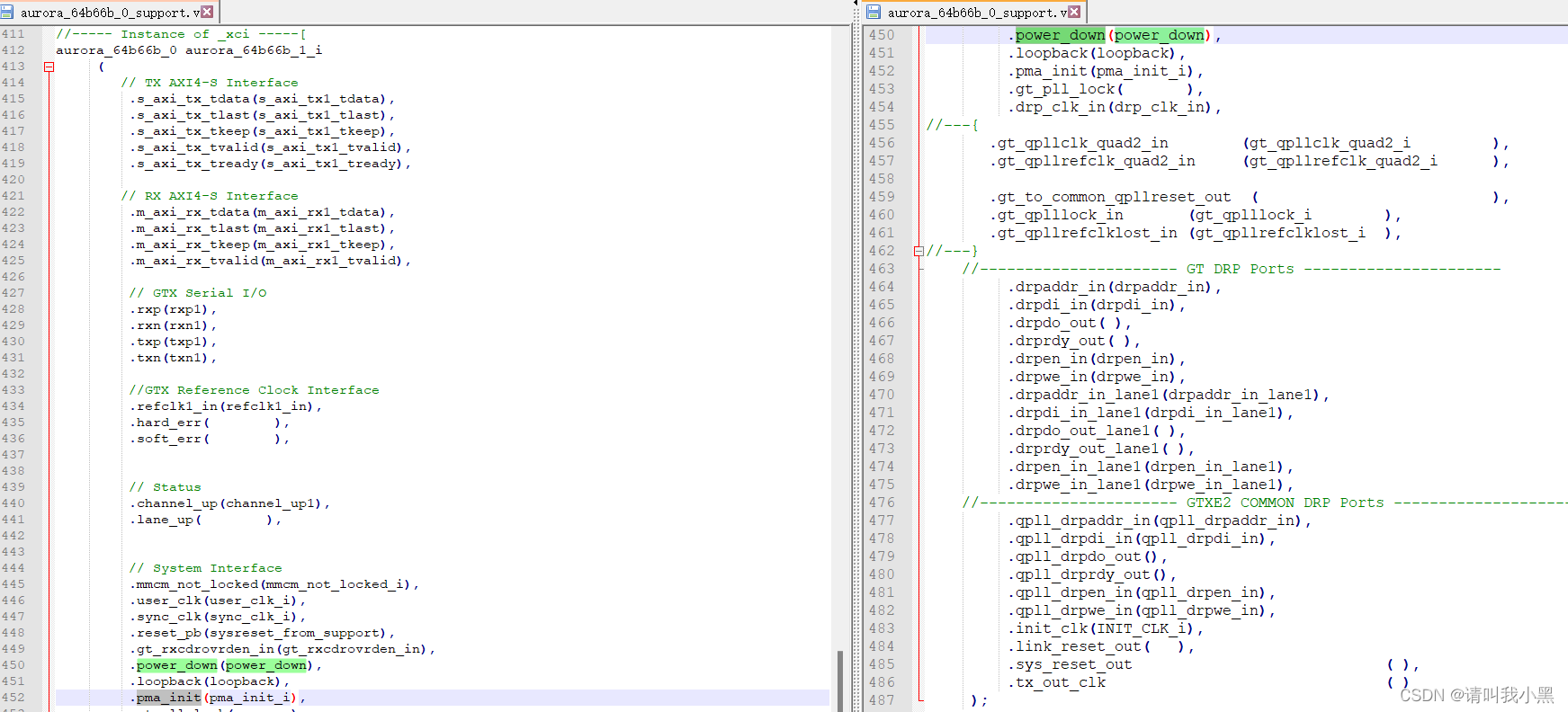
Aurora 64b66b同个Quad,多个core快速集成
一定在example design上修改,不建议将example design中的common时钟以及复位的代码独立出来(原因:把代码提取出来虽然代码简洁,但是会引入错误,移植和找bug都非常消耗时间)。直接在example design中support.v修改,直接额外列化Aurora IPcore,这样不用修改example design中的common时钟以及复位的部分代码。如下图所示:
七、MicroBlaze经验积累
MicroBlaze作为调试利器,还是非常方便的,使用Block Design可以加快调试并找到Bug。
1.Microbalze串口调试
直接拷贝代码到src文件夹下面,vitis内部自动识别并添加到工程目录。
2.Microbalze程序固化
首先生成download.bit文件,其次在烧写到flash中。
aurora_1lane_top.mmi文件修改(否则生成download.bit文件报错):

上面错误依据vitis错误提示,直接将第12替换为错误提示的内容即可。
之前烧写flash之后,microblaze启动不了,找到原因了,是因为每次只替换了bit文件,没有替换.mmi文件,两个都需要替换,才能正常启动!
参考文档:
MicroBlaze在纯FPGA下 Xilinx SDK固化程序到外部SPI FLASH
八、FPGA调试杂谈
1.防止信号被综合时被优化,可以使用如下(主要用于ILA抓取信号):
(* KEEP = "TRUE", MARK_DEBUG = "TRUE" *)wire sin_vld ;
(* KEEP = "TRUE", MARK_DEBUG = "TRUE" *)wire [SIN_DATA_WD -1:0] sin_data ;
2.防止信号在布局布线是被优化,可以使用如下(主要用于VIO观测信号,VIO调试时保留信号名称):
(* DONT_TOUCH = "yes" *)output [SIN_DATA_WD -1:0] max_val ,//(o)
(* DONT_TOUCH = "yes" *)output [POS_DATA_WD -1:0] max_val_pos ,//(o)
(* DONT_TOUCH = "yes" *)output [SIN_DATA_WD -1:0] min_val ,//(o)
(* DONT_TOUCH = "yes" *)output [POS_DATA_WD -1:0] min_val_pos ,//(o)
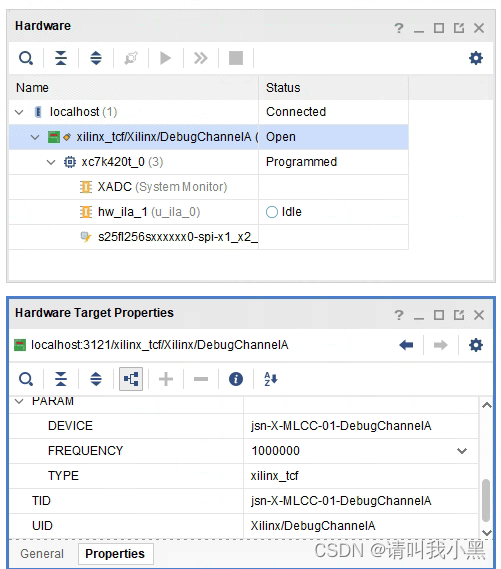
FPGA ILA 在线调试抓取信号报错误,如下:

解决方法:调整JTAG时钟频率,需要保证JTAG时钟频率低于所有抓取信号的时钟,这里设置JTAG时钟为1M。
参考文章:
FPGA Vivado 调试提示ILA时钟有问题
ILA调试报错
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 7840
7840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









