







 超级会员免费看
超级会员免费看
Caffe学习笔记---Python接口(1)
参考网址:
https://blog.csdn.net/jesse_mx/article/details/58605385
http://www.voidcn.com/article/p-bdkbqjdc-dx.html
https://www.cnblogs.com/yinheyi/p/6062488.html
前言
使用caffe也有一小段时间了,但是对于caffe的python接口总是一知半解,最近终于能静下心来,仔细阅读了caffe官方例程,并写下此博客。博文主要对caffe自带的分类例程00-classification.ipynb做了详细的注释,相信能加强这方面的理解。
准备工作
加载必要的库
<span style="color:#000000"><code class="language-python"><span style="color:#000088">import</span> numpy <span style="color:#000088">as</span> np <span style="color:#880000"># 加载numpy</span>
<span style="color:#000088">import</span> matplotlib.pyplot <span style="color:#000088">as</span> plt <span style="color:#880000"># 加载matplotlib</span>
%matplotlib inline <span style="color:#880000"># 此处是为了能在notebook中直接显示图像</span>
<span style="color:#880000"># rcParams是一个包含各种参数的字典结构,含有多个key-value,可修改其中部分值</span>
plt.rcParams[<span style="color:#009900">'figure.figsize'</span>] = (<span style="color:#006666">10</span>, <span style="color:#006666">10</span>) <span style="color:#880000"># 图像显示大小,单位是英寸 </span>
plt.rcParams[<span style="color:#009900">'image.interpolation'</span>] = <span style="color:#009900">'nearest'</span> <span style="color:#880000"># 最近邻差值,像素为正方形</span>
plt.rcParams[<span style="color:#009900">'image.cmap'</span>] = <span style="color:#009900">'gray'</span> <span style="color:#880000"># 使用灰度输出而不是彩色输出</span></code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
加载caffe
<span style="color:#000000"><code class="language-python"><span style="color:#000088">import</span> sys
caffe_root = <span style="color:#009900">'../'</span> <span style="color:#880000"># caffe根目录,此处为相对路径,如果失灵,可换成绝对路径</span>
<span style="color:#880000"># sys.path是一个列表,insert()函数插入一行,也可以使用sys.path.append('模块地址')</span>
sys.path.insert(<span style="color:#006666">0</span>, caffe_root + <span style="color:#009900">'python'</span>) <span style="color:#880000"># 加载caffe的python模块</span>
<span style="color:#000088">import</span> caffe <span style="color:#880000"># 加载caffe</span>
<span style="color:#000088">import</span> os
<span style="color:#880000"># 如果该路径下存在caffemodel文件,则打印信息,否则从官网下载</span>
<span style="color:#000088">if</span> os.path.isfile(caffe_root + <span style="color:#009900">'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'</span>):
<span style="color:#000088">print</span> <span style="color:#009900">'CaffeNet found.'</span>
<span style="color:#000088">else</span>:
<span style="color:#000088">print</span> <span style="color:#009900">'Downloading pre-trained CaffeNet model...'</span>
!../scripts/download_model_binary.py ../models/bvlc_reference_caffenet</code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
加载网络以及输入预处理
设置cpu模式以及从硬盘加载网络
<span style="color:#000000"><code class="language-python">caffe.set_mode_cpu() <span style="color:#880000"># 设置caffe为cpu模式,也可设成gpu模式</span>
model_def = caffe_root + <span style="color:#009900">'models/bvlc_reference_caffenet/deploy.prototxt'</span>
model_weights = caffe_root + <span style="color:#009900">'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'</span>
net = caffe.Net(model_def, <span style="color:#880000"># 定义模型结构 </span>
model_weights, <span style="color:#880000"># 包含模型训练权重</span>
caffe.TEST) <span style="color:#880000"># 使用测试模式(训练中不能执行dropout)</span></code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
图像预处理
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># 加载ImageNet训练集的图像均值,预处理需要减去均值</span>
<span style="color:#880000"># ilsvrc_2012_mean.npy文件是numpy格式,其数据维度是(3L, 256L, 256L)</span>
mu = np.load(caffe_root + <span style="color:#009900">'python/caffe/imagenet/ilsvrc_2012_mean.npy'</span>) <span style="color:#880000"># 加载均值文件</span>
mu = mu.mean(<span style="color:#006666">1</span>).mean(<span style="color:#006666">1</span>) <span style="color:#880000"># 对所有像素值取平均以此获取BGR的均值像素值</span>
<span style="color:#000088">print</span> <span style="color:#009900">'mean-subtracted values:'</span>, zip(<span style="color:#009900">'BGR'</span>, mu)
<span style="color:#880000"># 取平均后得到BGR均值分别是[104.00698793,116.66876762,122.67891434]</span>
<span style="color:#880000"># 对输入数据进行变换</span>
<span style="color:#880000"># caffe.io.transformer是一个类,实体化的时候构造函数__init__(self, inputs)给一个初值</span>
<span style="color:#880000"># 其中net.blobs本身是一个字典,每一个key对应每一层的名字,#net.blobs['data'].data.shape计算结果为(10, 3, 227, 227)</span>
transformer = caffe.io.Transformer({<span style="color:#009900">'data'</span>: net.blobs[<span style="color:#009900">'data'</span>].data.shape})
<span style="color:#880000"># 以下都是caffe.io.transformer类的函数方法</span>
<span style="color:#880000">#caffe.io.transformer的类定义放在io.py文件中,也可用help函数查看说明</span>
transformer.set_transpose(<span style="color:#009900">'data'</span>, (<span style="color:#006666">2</span>,<span style="color:#006666">0</span>,<span style="color:#006666">1</span>)) <span style="color:#880000"># 将图像通道数设置为outermost的维数</span>
transformer.set_mean(<span style="color:#009900">'data'</span>, mu) <span style="color:#880000"># 每个通道减去均值</span>
transformer.set_raw_scale(<span style="color:#009900">'data'</span>, <span style="color:#006666">255</span>) <span style="color:#880000"># 像素值从[0,1]变换为[0,255]</span>
transformer.set_channel_swap(<span style="color:#009900">'data'</span>, (<span style="color:#006666">2</span>,<span style="color:#006666">1</span>,<span style="color:#006666">0</span>)) <span style="color:#880000"># 交换通道,RGB->BGR</span></code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行CPU分类程序
载入图片
<span style="color:#000000"><code class="language-python"><span style="color:#880000">#设置输入图像大小</span>
net.blobs[<span style="color:#009900">'data'</span>].reshape(<span style="color:#006666">50</span>, <span style="color:#880000"># 尽管只检测一张图片,batch size仍为50</span>
<span style="color:#006666">3</span>, <span style="color:#880000"># 3通道</span>
<span style="color:#006666">227</span>, <span style="color:#006666">227</span>) <span style="color:#880000"># 图片尺寸227x227</span></code></span>- 1
- 2
- 3
- 4
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># 加载图片,函数声明为load_image(filename, color=True)</span>
image = caffe.io.load_image(caffe_root + <span style="color:#009900">'examples/images/cat.jpg'</span>)
<span style="color:#880000"># 按照之前设置进行预处理</span>
transformed_image = transformer.preprocess(<span style="color:#009900">'data'</span>, image)
plt.imshow(image) <span style="color:#880000">#显示图片</span></code></span>- 1
- 2
- 3
- 4
- 5

进行分类,获取结果
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># 将图像数据拷贝到为net分配的内存中</span>
net.blobs[<span style="color:#009900">'data'</span>].data[...] = transformed_image
<span style="color:#880000"># 前向传播,进行分类,forward函数说明放到博客最后</span>
<span style="color:#880000"># 前向传播,跑一遍网络,默认结果为最后一层的blob(也可以指定某一中间层),赋给output</span>
output = net.forward()
<span style="color:#880000"># output['prob']矩阵的维度是(50, 1000)</span>
output_prob = output[<span style="color:#009900">'prob'</span>][<span style="color:#006666">0</span>] <span style="color:#880000"># 取batch中第一张图像的概率值</span>
<span style="color:#880000"># 打印概率最大的类别代号,argmax()函数是求取矩阵中最大元素的索引</span>
<span style="color:#000088">print</span> <span style="color:#009900">'predicted class is:'</span>, output_prob.argmax() </code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
网络输出是一个概率向量,最可能的类别是第281个类别。但是结果是否正确呢,需要查看一下ImageNet的标签。
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># 加载ImageNet标签,如果不存在,则会自动下载</span>
labels_file = caffe_root + <span style="color:#009900">'data/ilsvrc12/synset_words.txt'</span>
<span style="color:#000088">if</span> <span style="color:#000088">not</span> os.path.exists(labels_file):
!../data/ilsvrc12/get_ilsvrc_aux.sh
<span style="color:#880000"># 读取纯文本数据,三个参数分别是文件地址、数据类型和数据分隔符,保存为字典格式 </span>
labels = np.loadtxt(labels_file, str, delimiter=<span style="color:#009900">'\t'</span>)
<span style="color:#000088">print</span> <span style="color:#009900">'output label:'</span>, labels[output_prob.argmax()] </code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
打印结果如下:
output label: n02123045 tabby, tabby cat
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># 从softmax output可查看置信度最高的五个结果</span>
top_inds = output_prob.argsort()[::-<span style="color:#006666">1</span>][:<span style="color:#006666">5</span>] <span style="color:#880000"># 逆序排列,取前五个最大值</span>
<span style="color:#000088">print</span> <span style="color:#009900">'probabilities and labels:'</span>
zip(output_prob[top_inds], labels[top_inds])
</code></span>- 1
- 2
- 3
- 4
- 5
- 6
打印结果如下:
probabilities and labels:
[(0.31243545, ‘n02123045 tabby, tabby cat’),
(0.23797165, ‘n02123159 tiger cat’),
(0.12387225, ‘n02124075 Egyptian cat’),
(0.10075709, ‘n02119022 red fox, Vulpes vulpes’),
(0.07095667, ‘n02127052 lynx, catamount’)]
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># 查看CPU的分类时间,然后再与GPU进行比较</span>
%timeit net.forward() <span style="color:#880000">#计时</span></code></span>- 1
- 2
1 loop, best of 3: 4.52 s per loop,结果比较慢。
gpu模式运行
<span style="color:#000000"><code class="language-python"><span style="color:#880000">#gpu模式下跑一次</span>
caffe.set_device(<span style="color:#006666">0</span>) <span style="color:#880000"># 使用第一块显卡</span>
caffe.set_mode_gpu() <span style="color:#880000"># 设为gpu模式</span>
net.forward() <span style="color:#880000"># 前向传播</span>
%timeit net.forward() <span style="color:#880000"># 计时</span></code></span>- 1
- 2
- 3
- 4
- 5
1 loop, best of 3: 196 ms per loop,简直飞起来了。
测试中间输出结果
中间层的可视化
卷积神经网络不单单是一个黑盒子。我们接下来看看该模型的一些参数和一些中间输出。首先,我们来看下如何读取网络的结构(每层的名字以及相应层的参数)。
net.blob对应网络每一层数据,对于每一层,都是四个维度:(batch_size, channel_dim, height, width)。
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># 循环打印每一层名字和相应维度</span>
<span style="color:#000088">for</span> layer_name, blob <span style="color:#000088">in</span> net.blobs.iteritems():
<span style="color:#000088">print</span> layer_name + <span style="color:#009900">'\t'</span> + str(blob.data.shape) </code></span>- 1
- 2
- 3
打印结果如下:
data (50, 3, 227, 227)
conv1 (50, 96, 55, 55)
pool1 (50, 96, 27, 27)
norm1 (50, 96, 27, 27)
conv2 (50, 256, 27, 27)
pool2 (50, 256, 13, 13)
norm2 (50, 256, 13, 13)
conv3 (50, 384, 13, 13)
conv4 (50, 384, 13, 13)
conv5 (50, 256, 13, 13)
pool5 (50, 256, 6, 6)
fc6 (50, 4096)
fc7 (50, 4096)
fc8 (50, 1000)
prob (50, 1000)
net.params对应网络中的参数(卷积核参数,全连接层参数等),有两个字典值,net.params[0]是权值(weights),net.params[1]是偏移量(biases),权值参数的维度表示是(output_channels, input_channels, filter_height, filter_width),偏移量参数的维度表示(output_channels,)
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># 循环打印参数名称,权值参数和偏移量参数的维度</span>
<span style="color:#000088">for</span> layer_name, param <span style="color:#000088">in</span> net.params.iteritems():
<span style="color:#000088">print</span> layer_name + <span style="color:#009900">'\t'</span> + str(param[<span style="color:#006666">0</span>].data.shape), str(param[<span style="color:#006666">1</span>].data.shape) </code></span>- 1
- 2
- 3
打印结果如下:
conv1 (96, 3, 11, 11) (96,)
conv2 (256, 48, 5, 5) (256,)
conv3 (384, 256, 3, 3) (384,)
conv4 (384, 192, 3, 3) (384,)
conv5 (256, 192, 3, 3) (256,)
fc6 (4096, 9216) (4096,)
fc7 (4096, 4096) (4096,)
fc8 (1000, 4096) (1000,)
这里要将四维数据进行特征可视化,需要一个定义辅助函数:
<span style="color:#000000"><code class="language-python"><span style="color:#000088">def</span> <span style="color:#009900">vis_square</span><span style="color:#4f4f4f">(data)</span>:
<span style="color:#880000"># 数据正则化</span>
data = (data - data.min()) / (data.max() - data.min())
<span style="color:#880000"># 此处目的是将一个个滤波器按照正方形的样子排列</span>
<span style="color:#880000"># 先对shape[0]也就是滤波器数量取平方根,然后取大于等于该结果的正整数</span>
<span style="color:#880000"># 比如40个卷积核,则需要7*7的正方形格子(虽然填不满)</span>
n = int(np.ceil(np.sqrt(data.shape[<span style="color:#006666">0</span>])))
padding = (((<span style="color:#006666">0</span>, n ** <span style="color:#006666">2</span> - data.shape[<span style="color:#006666">0</span>]),
(<span style="color:#006666">0</span>, <span style="color:#006666">1</span>), (<span style="color:#006666">0</span>, <span style="color:#006666">1</span>)) <span style="color:#880000"># 在相邻的卷积核之间加入空白</span>
+ ((<span style="color:#006666">0</span>, <span style="color:#006666">0</span>),) * (data.ndim - <span style="color:#006666">3</span>)) <span style="color:#880000"># 不填充最后一维</span>
data = np.pad(data, padding, mode=<span style="color:#009900">'constant'</span>, constant_values=<span style="color:#006666">1</span>) 每张小图片向周围扩展一个白色像素
<span style="color:#880000"># pad函数声明:pad(array, pad_width, mode, **kwargs),作用是把list在原维度上进行扩展;</span>
<span style="color:#880000"># pad_width是扩充参数,例如参数((3,2),(2,3));</span>
<span style="color:#880000"># 其中(3,2)为水平方向上,上面加3行,下面加2行;</span>
<span style="color:#880000"># (2,3)为垂直方向上,上面加2行,下面加3行;</span>
<span style="color:#880000"># constant是常数填充的意思。</span>
<span style="color:#880000"># 将卷积核平铺成图片,没太看懂,有空补充</span>
data = data.reshape((n, n) + data.shape[<span style="color:#006666">1</span>:]).transpose((<span style="color:#006666">0</span>, <span style="color:#006666">2</span>, <span style="color:#006666">1</span>, <span style="color:#006666">3</span>) + tuple(range(<span style="color:#006666">4</span>, data.ndim + <span style="color:#006666">1</span>)))
data = data.reshape((n * data.shape[<span style="color:#006666">1</span>], n * data.shape[<span style="color:#006666">3</span>]) + data.shape[<span style="color:#006666">4</span>:])
plt.imshow(data); plt.axis(<span style="color:#009900">'off'</span>)</code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
<span style="color:#000000"><code class="language-python">filters = net.params[<span style="color:#009900">'conv1'</span>][<span style="color:#006666">0</span>].data <span style="color:#880000"># 选取conv1的卷积核权值参数</span>
vis_square(filters.transpose(<span style="color:#006666">0</span>, <span style="color:#006666">2</span>, <span style="color:#006666">3</span>, <span style="color:#006666">1</span>)) <span style="color:#880000"># 调用函数显示</span></code></span>- 1
- 2

<span style="color:#000000"><code class="language-python">feat = net.blobs[<span style="color:#009900">'conv1'</span>].data[<span style="color:#006666">0</span>, :<span style="color:#006666">36</span>] <span style="color:#880000"># 选取‘conv1’的blob数据,只选择前面36张图片</span>
vis_square(feat)</code></span>- 1
- 2

<span style="color:#000000"><code class="language-python">feat = net.blobs[<span style="color:#009900">'pool5'</span>].data[<span style="color:#006666">0</span>] <span style="color:#880000"># 选取pool5的第一个输出结果</span>
vis_square(feat) </code></span>- 1
- 2
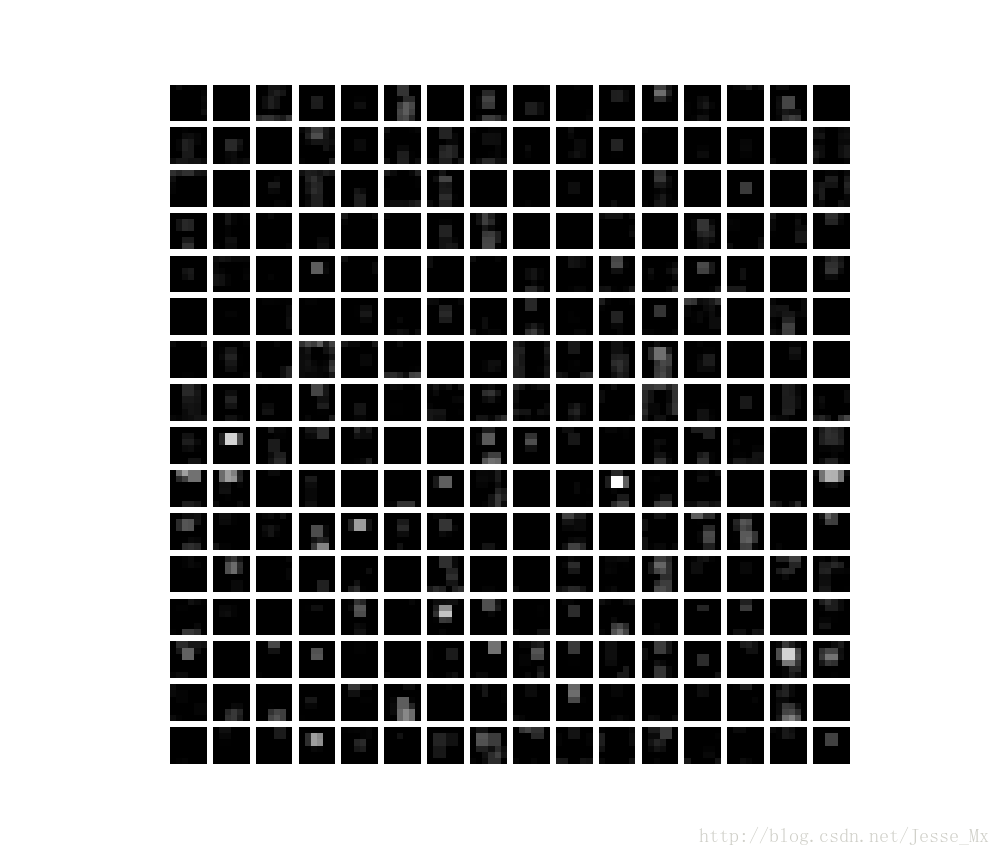
直方图显示
<span style="color:#000000"><code class="language-python">feat = net.blobs[<span style="color:#009900">'fc6'</span>].data[<span style="color:#006666">0</span>] <span style="color:#880000"># 选取fc6的输出数据,这是一个4096维的向量</span>
plt.subplot(<span style="color:#006666">2</span>, <span style="color:#006666">1</span>, <span style="color:#006666">1</span>) <span style="color:#880000"># 创建2行1列的子图,现在是第1个子图</span>
plt.plot(feat.flat) <span style="color:#880000"># 平铺向量,图像显示其每一个值</span>
plt.subplot(<span style="color:#006666">2</span>, <span style="color:#006666">1</span>, <span style="color:#006666">2</span>) <span style="color:#880000"># 现在是第2个子图</span>
_ = plt.hist(feat.flat[feat.flat > <span style="color:#006666">0</span>], bins=<span style="color:#006666">100</span>) <span style="color:#880000"># 做直方图,总共100根条形</span>
plt.show() <span style="color:#880000"># 显示两张图表</span></code></span>- 1
- 2
- 3
- 4
- 5
- 6

<span style="color:#000000"><code class="language-python">feat = net.blobs[<span style="color:#009900">'prob'</span>].data[<span style="color:#006666">0</span>] <span style="color:#880000"># 选取最后一层的输出结果,</span>
plt.figure(figsize=(<span style="color:#006666">15</span>, <span style="color:#006666">3</span>)) <span style="color:#880000"># 设置图像大小为(15,3),单位是英寸</span>
plt.plot(feat.flat) <span style="color:#880000"># 平铺向量,图像显示其每一个值</span>
plt.show() <span style="color:#880000"># 显示图表</span></code></span>- 1
- 2
- 3
- 4

测试自己的图片
<span style="color:#000000"><code class="language-python"><span style="color:#880000"># 下载图像</span>
my_image_url = <span style="color:#009900">"..."</span> <span style="color:#880000"># 图像URL地址</span>
!wget -O image.jpg $my_image_url <span style="color:#880000"># 在线下载图片</span>
<span style="color:#880000"># 变换图像并将其拷贝到网络</span>
image = caffe.io.load_image(<span style="color:#009900">'image.jpg'</span>)
net.blobs[<span style="color:#009900">'data'</span>].data[...] = transformer.preprocess(<span style="color:#009900">'data'</span>, image)
<span style="color:#880000"># 预测分类结果</span>
net.forward()
<span style="color:#880000"># 获取输出概率值</span>
output_prob = net.blobs[<span style="color:#009900">'prob'</span>].data[<span style="color:#006666">0</span>]
<span style="color:#880000"># 将softmax的输出结果按照从大到小排序,并取前5名</span>
top_inds = output_prob.argsort()[::-<span style="color:#006666">1</span>][:<span style="color:#006666">5</span>]
plt.imshow(image)
plt.show()
<span style="color:#000088">print</span> <span style="color:#009900">'probabilities and labels:'</span>
zip(output_prob[top_inds], labels[top_inds]) <span style="color:#880000"># zip函数依次取值,然后组合</span></code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
附:forward函数说明
Net_forward(self, blobs=None, start=None, end=None, **kwargs) method of caffe._caffe.Net instance
Forward pass: prepare inputs and run the net forward.<span style="color:#000000"><code>Parameters ---------- blobs : list of blobs to return in addition to output blobs. kwargs : Keys are input blob names and values are blob ndarrays. For formatting inputs for Caffe, see Net.preprocess(). If None, input is taken from data layers. start : optional name of layer at which to begin the forward pass end : optional name of layer at which to finish the forward pass (inclusive) Returns ------- outs : {blob name: blob ndarray} dict.</code></span>















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









