导言 本教程中,我们将会利用Caffe官方提供的深度模型——CaffeNet(该模型是基于Krizhevsky等人的模型的)来演示图像识别与分类。我们将分别用CPU和GPU来进行演示,并对比其性能。然后深入探讨该模型的一些其它特征。
1、准备工作 1.1 首先,安装Python,numpy以及matplotlib。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize' ] = (10 , 10 )
plt.rcParams['image.interpolation' ] = 'nearest'
plt.rcParams['image.cmap' ] = 'gray' 1.2 然后,加载Load caffe。
# caffe模块要在Python的路径下;
# 这里我们将把caffe 模块添加到Python路径下.
import sys
caffe_root = '../' #该文件要从路径{caffe_root}/examples下运行,否则要调整这一行。
sys.path.insert(0, caffe_root + 'python')
import caffe
# 如果你看到"No module named _caffe",那么要么就是你没有正确编译pycaffe;要么就是你的路径有错误。
说明:该步骤,本人是将编译好的pycaffe文件下的全部东西复制到Python的“site-packages”下的。所以不知道按上述做法具体会出现什么问题。 1.3 必要的话,需要事先下载“CaffeNet”模型,该模型是AlexNet的变形。
import os
if os .path.isfile(caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel' ):
print 'CaffeNet found.'
else :
print 'Downloading pre-trained CaffeNet model...'
!../scripts/download_model_binary.py ../models/bvlc_reference_caffenet说明:该步骤,本人是事先下载好”bvlc_reference_caffenet.caffemodel”,然后将其放在”caffe_root + ‘models/bvlc_reference_caffenet/”目录下面,因为用代码下载太慢了。 2、加载网络并设置输入预处理 2.1 将Caffe设置为CPU模式,并从硬盘加载网络。
caffe.set_mode_cpu()
model_def = caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt'
model_weights = caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
net = caffe.Net(model_def,
model_weights,
caffe.TEST)
mu = np.load(caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy' )
mu = mu.mean(1 ).mean(1 )
print 'mean-subtracted values:' , zip('BGR' , mu)
transformer = caffe.io.Transformer({'data' : net.blobs['data' ].data.shape})
transformer.set_transpose('data' , (2 ,0 ,1 ))
transformer.set_mean('data' , mu)
transformer.set_raw_scale('data' , 255 )
transformer.set_channel_swap('data' , (2 ,1 ,0 )) 3、用CPU分类 3.1 现在我们开始进行分类。尽管我们只对一张图像进行分类,不过我们将batch的大小设置为50以此来演示batching。
net.blobs['data' ].reshape(50 ,
3 ,
227 , 227 ) 3.2 加载图像(caffe自带的)并进行预处理。
image = caffe.io.load_image(caffe_root + 'examples/images/cat.jpg' )
transformed_image = transformer.preprocess('data' , image )
plt.imshow(image )
plt.show()
说明:这里的”plt.show()”是我自己加的,不加的话没法显示图像。 3.3 接下来,开始进行识别分类
net.blobs['data' ].data[... ] = transformed_image
output = net.forward()
output_prob = output['prob' ][0 ]
print 'predicted class is:' , output_prob.argmax()predicted class is: 281
网络输出是一个概率向量;最可能的类别是第281个类别。但是结果是否正确呢,让我们来查看一下ImageNet的标签。
labels_file = caffe_root + 'data/ilsvrc12/synset_words.txt'
if not os.path.exists (labels_file):
!../data/ilsvrc12/get_ilsvrc_aux.sh
labels = np.loadtxt(labels_file, str, delimiter='\t' )
print 'output label:' , labels[output_prob.argmax()]说明:ImageNet标签文件(synset_words.txt)需要自己下载 output label: n02123045 tabby, tabby cat
”Tabby cat”是正确的,然后我们再来看下其它几个置信的较高的结果。
# sort top five predictions from softmax output
top_inds = output_prob.argsort()[::-1 ][:5 ] # reverse sort and take five largest items
print 'probabilities and labels:'
zip(output_prob[top_inds], labels[top_inds])probabilities and labels:
[(0.31243637 , 'n02123045 tabby, tabby cat'),
(0.2379719 , 'n02123159 tiger cat'),
(0.12387239 , 'n02124075 Egyptian cat'),
(0.10075711 , 'n02119022 red fox, Vulpes vulpes'),
(0.070957087 , 'n02127052 lynx, catamount')]我们可以看出,较低置信度的结构也是合理的。
4、GPU模式 4.1 让我们先看下CPU的分类时间,然后再与GPU进行比较。
%timeit net.forward()1 loop, best of 3: 1.42 s per loop
还是需要一段时间的,即使是对批量的50张图像。然后,让我们看下GPU模式下的运行时间。
caffe.set _device(0 ) # 如果你有多个GPU,那么选择第一个
caffe.set _mode_gpu()
net.forward () # run once before timing to set up memory
%timeit net.forward ()10 loops, best of 3: 70.2 ms per loop
这下就快多了。
5、测试网络的中间层输出 我们的网络不单单是一个黑盒子。接下来,我们来看下该模型的一些参数和一些中间输出。首先,我们来看下如何读取网络的结构(每层的名字以及相应层的参数)。对于每一层,其结构构成为:(batch_size, channel_dim, height, width)。
# 对于每一层,显示输出类型。
for layer_name, blob in net.blobs.iteritems():
print layer_name + '\t' + str(blob.data .shape)data (50, 3, 227, 227) 50 , 96 , 55 , 55 )
pool1 (50 , 96 , 27 , 27 )
norm1 (50 , 96 , 27 , 27 )
conv2 (50 , 256 , 27 , 27 )
pool2 (50 , 256 , 13 , 13 )
norm2 (50 , 256 , 13 , 13 )
conv3 (50 , 384 , 13 , 13 )
conv4 (50 , 384 , 13 , 13 )
conv5 (50 , 256 , 13 , 13 )
pool5 (50 , 256 , 6 , 6 )
fc6 (50 , 4096 )
fc7 (50 , 4096 )
fc8 (50 , 1000 )
prob (50 , 1000 ) 现在,我们来看下参数的形状。参数是OrderdDict类型,net.params。我们根据索引来访问参数。[0]:表示weights,[1]:表示biases。
参数形状的构成为:
for layer_name, param in net.params .iteritems ():
print layer_name + '\t' + str(param[0 ].data .shape ), str(param[1 ].data .shape )
conv1 (96 , 3 , 11 , 11 ) (96 ,)
conv2 (256 , 48 , 5 , 5 ) (256 ,)
conv3 (384 , 256 , 3 , 3 ) (384 ,)
conv4 (384 , 192 , 3 , 3 ) (384 ,)
conv5 (256 , 192 , 3 , 3 ) (256 ,)
fc6 (4096 , 9216 ) (4096 ,)
fc7 (4096 , 4096 ) (4096 ,)
fc8 (1000 , 4096 ) (1000 ,) 因为我们处理的是四位数据,所以我们将定义一个帮助函数来可视化特征。
def vis_square(data ):"" "输入一个形如:(n, height, width) or (n, height, width, 3)的数组,并对每一个形如(height,width)的特征进行可视化sqrt(n) by sqrt(n)" ""
# 正则化数据
data = (data - data .min () ) / (data .max () - data .min() )data .shape[0])))0 , n ** 2 - data .shape[0]),0 , 1 ), (0 , 1 )) # 在相邻的滤波器之间加入空白
+ ((0 , 0 ),) * (data .ndim - 3)) # 不扩展最后一维data = np.pad(data , padding , mode ='constant' , constant_values =1) # 扩展一个像素(白色) data = data .reshape((n , n ) + data .shape[1:]).transpose((0, 2, 1, 3) + tuple(range (4, data .ndim + 1) ))data = data .reshape((n * data .shape [1], n * data .shape [3]) + data .shape[4:])data ) 首先,我们来看下第一个卷积层(conv1)的输出特征。
filters = net.params ['conv1' ][0 ].data
vis_square(filters.transpose (0 , 2 , 3 , 1 ))
上图为conv1的输出。
feat = net.blobs['conv1'].data [0, :36]
上图为pool5的输出。
feat = net.blobs['pool5'].data [0]
上图为第一个全连接层(fc6)的输出。
接下来,我们将显示输出结果及直方图。
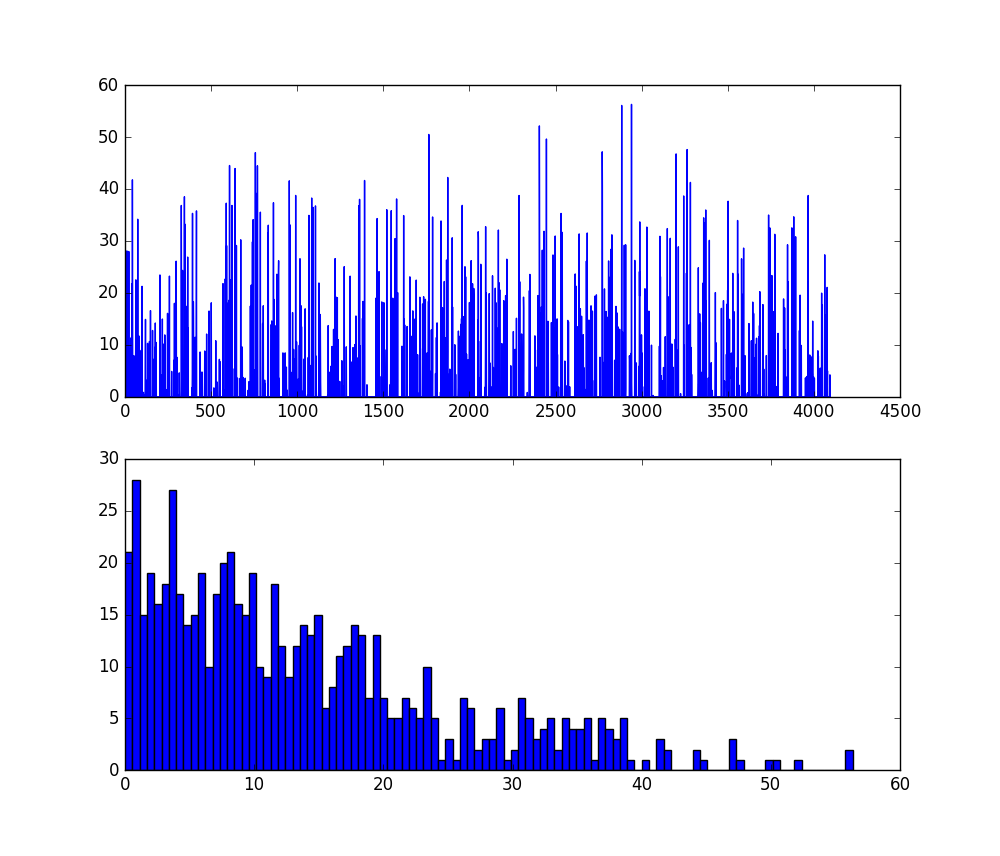
feat = net.blobs['fc6'].data[0 ]
plt.subplot(2 , 1 , 1 )
plt.plot(feat.flat )
plt.subplot(2 , 1 , 2 )
_ = plt.hist(feat.flat [feat.flat > 0 ], bins=100 )
plt.show()
上图为最终的概率输出,prob。
feat = net.blobs['prob'].data [0]15 , 3 ))
plt.plot(feat.flat)
plt.show()
上图显示了分类的聚类结果,峰值对应的标签为预测结果。
6、测试自己的图像
现在,我们随便从网上找一种图像,然后安装上述步骤来进行分类。
将”my_image_url”设为图像的链接(URL)
my_image_url = "..."
!wget -O image.jpg $my_image_url
image = caffe.io.load_image('image.jpg' )
net.blobs['data' ].data[... ] = transformer.preprocess('data' , image)
net.forward()
output_prob = net.blobs['prob' ].data[0 ]
top_inds = output_prob.argsort()[::-1 ][:5 ]
plt.imshow(image)
plt.show()
print 'probabilities and labels:'
zip(output_prob[top_inds], labels[top_inds])





























 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









