







文章目录
Divergence Measures
介绍
在机器学习中,我们常常需要用一个分布Q去逼近一个目标分布P,我们希望能够找到一个目标函数 D ( Q , P ) D( Q,P) D(Q,P),计算Q到P的距离。而这一个目标函数,正是Divergence(散度),比如常见的KL-Divergence,JS-Divergence等等。通过这个散度的计算我们就能不断地去优化我们的Q,寻找一个最优的参数去逼近真实的分布P。注意,散度跟距离不一样,他没有距离的对称性( d ( x , y ) = d ( y , x ) d(x,y)=d(y,x) d(x,y)=d(y,x))或是三角不等式( d ( x , y ) ≤ d ( x , z ) + d ( z , y ) d(x,y) \leq d(x,z)+d(z,y) d(x,y)≤d(x,z)+d(z,y))的要求。
KL-Divergence 一种信息论的解释
在机器学习中,最常见的散度就是KL散度了(它还有很多名字,比如:relative entropy, relative information。),那么KL散度究竟是何方神圣?它的著名到底是历史的原因还是因为它本身优良的性质呢?
用一句话来说,KL散度, K L ( P ∥ Q ) KL(P\| Q) KL(P∥Q)可以理解为,用来衡量在同一份数据P下,使用P的编码方案和Q的编码方案的平均编码长度的差异。
熵
为了理解这个问题,我们先从熵讲起。一个随机变量X的概率密度函数为
p
(
x
)
p( x)
p(x),那么X的熵定义为:
H
(
X
)
=
−
∑
x
p
(
x
)
log
2
p
(
x
)
H( X) =-\sum _{x} p( x)\log_{2} p( x)
H(X)=−x∑p(x)log2p(x)
这里用2为底数就表示比特。熵可以看做是一个分布的不确定的程度,显然,在离散的情况下,均匀分布的熵总是最大的,此时的不确定性也是最大的。从信息的角度来看,熵是为了描述该随机变量所需要的平均比特数。
例子:考虑一个服从均匀分布且有32种可能结果的随机变量。为了确定一个结果,我们需要5个比特的编码来告诉我们到底出现了哪种可能。该随机变量的熵恰好为:
H
(
X
)
=
−
∑
i
=
1
32
1
32
log
2
1
32
=
5
比
特
H( X) =-\sum ^{32}_{i=1}\frac{1}{32}\log_{2}\frac{1}{32} =5\ 比特
H(X)=−i=1∑32321log2321=5 比特
在这种情况下,每个可能出现的状态的长度都是一样的,他们长度都是5个比特。但是如果随机变量不是均匀分布呢?在这种情况下,我们完全可以让出现概率较大的结果给他分配一个比较小的编码长度,从而总体的平均编码长度可以下降。
例子: 有8匹马参加赛马比赛。8匹马的胜率分布为:
P
=
{
1
2
,
1
4
,
1
8
,
1
16
,
1
64
,
1
64
,
1
64
,
1
64
}
P=\left\{\frac{1}{2} ,\frac{1}{4} ,\frac{1}{8} ,\frac{1}{16} ,\frac{1}{64} ,\frac{1}{64} ,\frac{1}{64} ,\frac{1}{64}\right\}
P={21,41,81,161,641,641,641,641},可以计算该比赛的熵为:
H
(
X
)
=
−
1
2
log
2
1
2
−
1
4
log
2
1
4
−
1
8
log
2
1
8
−
1
16
log
2
1
16
−
4
∗
1
64
log
2
1
64
=
2
比
特
H( X) =-\frac{1}{2}\log_{2}\frac{1}{2} -\frac{1}{4}\log_{2}\frac{1}{4} -\frac{1}{8}\log_{2}\frac{1}{8} -\frac{1}{16}\log_{2}\frac{1}{16} -4*\frac{1}{64}\log_{2}\frac{1}{64} =2\ 比特
H(X)=−21log221−41log241−81log281−161log2161−4∗641log2641=2 比特
此时,假定我们要把哪匹马会获胜的消息发送出去, 其中一个策略是发送胜出马的编号。 这样, 对任何一匹马, 描述需要3比特。 但由于获胜的概率不是均等的, 因此, 明智的方法是对获胜可能性较大的马使用较短的描述, 而对获胜可能性较小的马使用较长的描述。 这样做, 我们会获得一个更短的平均描述长度。 例如,使用以下的一组二元字符串来表示8匹马:0, 10, 110, 1110, 111100, 111101, 111110,111111。 此时, 平均描述长度为2比特, 比使用等长编码时所用的3比特小。可以证明任何随机变量的熵必为表示这个随机变量所需要的平均比特数的一个下界。注意到这里的 − log 2 1 2 = 1 , − log 2 1 4 = 2... − log 2 1 64 = 6 -\log_{2}\frac{1}{2} =1,-\log_{2}\frac{1}{4} =2...-\log_{2}\frac{1}{64} =6 −log221=1,−log241=2...−log2641=6恰好对应着最优编码的长度!也就是说,我们理解 log 2 p ( x ) \log_{2} p( x) log2p(x)为分布p在x上的最优的编码长度。
那么如果,我们换一套编码方案去表示这场比赛会怎样?假设另外一场赛马比赛的胜率分布为均匀分布:
Q
=
{
1
8
,
1
8
,
1
8
,
1
8
,
1
8
,
1
8
,
1
8
,
1
8
}
Q=\left\{\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8}\right\}
Q={81,81,81,81,81,81,81,81},显然它对应的最优编码一定是,每匹马都是3个比特,因为他们服从均匀分布。那么在均匀分布的编码下这场比赛的平均编码长度是:
(
1
2
+
1
4
+
1
8
+
1
16
+
1
64
+
1
64
+
1
64
+
1
64
)
∗
3
=
3
\left(\frac{1}{2} +\frac{1}{4} +\frac{1}{8} +\frac{1}{16} +\frac{1}{64} +\frac{1}{64} +\frac{1}{64} +\frac{1}{64}\right) *3=3
(21+41+81+161+641+641+641+641)∗3=3
也就是说,使用Q方案的编码,在这次比赛中,他的平均编码长度比最优的编码多了1比特!而这,正是P和Q的KL散度!即
K
L
(
P
∥
Q
)
=
1
KL( P\| Q) =1
KL(P∥Q)=1,可以验证:
K
L
(
P
∥
Q
)
=
∑
x
P
(
x
)
log
2
P
(
x
)
Q
(
x
)
=
1
KL( P\| Q) =\sum _{x} P( x)\log_{2}\frac{P( x)}{Q( x)} =1
KL(P∥Q)=x∑P(x)log2Q(x)P(x)=1
此外,KL散度还可以写作: K L ( P ∥ Q ) = ∑ x P ( x ) log 2 P ( x ) − ∑ x P ( x ) log 2 Q ( x ) KL( P\| Q) =\sum _{x} P( x)\log_{2} P( x) -\sum _{x} P( x)\log_{2} Q( x) KL(P∥Q)=∑xP(x)log2P(x)−∑xP(x)log2Q(x)$ $所以,我们可以理解为,在同一份数据P下,使用P的编码方案和Q的编码方案的平均编码长度的差异。
散度的性质
下面介绍3个公理,注意,只有KL距离能够满足下面所有的公理。
- Locality. 该性质可以认为该距离是一个关于“点”的距离,通过比较每个点的距离从而得到整个分布的距离,即,相对信息可以写成: D ( Q , P ) = ∫ f ( q ( x ) , p ( x ) , x ) d x D( Q,P) =\int f( q( x) ,p( x) ,x) dx D(Q,P)=∫f(q(x),p(x),x)dx, 其中f是一个任意的函数,我们只比较 q ( x ) , p ( x ′ ) q( x) ,p( x') q(x),p(x′)在 x = x ′ x=x' x=x′上的距离,当然我们可以推广到右梯度的情况,不过本质上还是点与点之间的比较: D ( Q , P ) = ∫ f ( q ( x ) , p ( x ) , x , ∇ q ( x ) , ∇ p ( x ) ) d x D( Q,P) =\int f( q( x) ,p( x) ,x,\nabla q( x) ,\nabla p( x)) dx D(Q,P)=∫f(q(x),p(x),x,∇q(x),∇p(x))dx。
- Coordinate invariance坐标不变性,不管坐标系怎么办,两个分布的散度都应该是不变的,形式化的说,如果x存在一个变换 ϕ \phi ϕ使得 x ~ = ϕ ( x ) \tilde{x} =\phi ( x) x~=ϕ(x),那么变换后的散度满足: D ( Q ~ , P ~ ) = ∫ f ( q ~ ( x ~ ) , p ( x ~ ) , x ~ ) d x ~ = ∫ f ( ( q ∘ ϕ − 1 ) ( x ~ ) ∣ det ∂ ϕ ∂ x ∣ , ( q ∘ ϕ − 1 ) ( x ~ ) ∣ det ∂ ϕ ∂ x ∣ , ϕ − 1 ( x ~ ) ) d x ~ = D ( Q , P ) D\left(\tilde{Q} ,\tilde{P}\right) =\int f\left(\tilde{q}\left(\tilde{x}\right) ,p\left(\tilde{x}\right) ,\tilde{x}\right) d\tilde{x} =\int f\left(\frac{\left( q\circ \phi ^{-1}\right)\left(\tilde{x}\right)}{|\det\frac{\partial \phi }{\partial x} |} ,\frac{\left( q\circ \phi ^{-1}\right)\left(\tilde{x}\right)}{|\det\frac{\partial \phi }{\partial x} |} ,\phi ^{-1}\left(\tilde{x}\right)\right) d\tilde{x} =D( Q,P) D(Q~,P~)=∫f(q~(x~),p(x~),x~)dx~=∫f(∣det∂x∂ϕ∣(q∘ϕ−1)(x~),∣det∂x∂ϕ∣(q∘ϕ−1)(x~),ϕ−1(x~))dx~=D(Q,P)
- Subsystem independence,如果存在子系统相互独立,那么考虑 p ( x 1 , x 2 ) p( x_{1} ,x_{2}) p(x1,x2)与 p ( x 1 ) p ( x 2 ) p( x_{1}) p( x_{2}) p(x1)p(x2)就是等价的。换句话说,这里存在对数可加性(这里或许我理解的不对,详情请看[2])
实际上,如果不需要满足或部分满足上面的公理,我们就能得到各种各样不同的divergence。但是,违反公理2会导致梯度的计算有偏,违反公理3会导致计算开销很大。这也从侧面反应出,KL距离是表示相对信息最合理的一个。
- f-divergences, D f ( Q , P ) = ∫ f ( q ( x ) p ( x ) ) p ( x ) d x D_{f}( Q,P) =\int f\left(\frac{q( x)}{p( x)}\right) p( x) dx Df(Q,P)=∫f(p(x)q(x))p(x)dx,其中f是任意的strictly convex function,当 f ≠ x log x f\neq x\log x f̸=xlogx时,他违反了公理3.
- Stein divergence, D ( Q , P ) = sup f ∈ F E q [ ∇ log p ( x ) f ( x ) + ∇ f ( x ) ] 2 D( Q,P) =\sup _{f\in \mathcal{F}} E_{q}[ \nabla \log p( x) f( x) +\nabla f( x)]^{2} D(Q,P)=supf∈FEq[∇logp(x)f(x)+∇f(x)]2,其中f是所有满足 E p [ ∇ log p ( x ) f ( x ) + ∇ f ( x ) ] = 0 E_{p}[ \nabla \log p( x) f( x) +\nabla f( x)] =0 Ep[∇logp(x)f(x)+∇f(x)]=0的平滑函数。违反公理2,3
- Craner/energy distance D ( Q , P ) = 2 E [ ∥ x − y ∥ ] − E [ ∥ x − x ′ ∥ ] − E [ ∥ y − y ′ ∥ ] D( Q,P) =2E[ \| x-y\| ] -E[ \| x-x'\| ] -E[ \| y-y'\| ] D(Q,P)=2E[∥x−y∥]−E[∥x−x′∥]−E[∥y−y′∥], 其中 x , x ′ ∼ P x,x'\sim P x,x′∼P, y , y ′ ∼ Q y,y'\sim Q y,y′∼Q,违反所有公理。如果将Euclidean norm$| \ | $换成geodesic distance 可以满足公理2.
- Wasserteub dustabce D p ( Q , P ) = [ inf ρ ∫ d x d x ′ ∥ x − x ′ ∥ p ρ ( x , x ′ ) ] 1 p D_{p}( Q,P) =\left[\inf_{\rho }\int dxdx'\| x-x'\| ^{p} \rho ( x,x')\right]^{\frac{1}{p}} Dp(Q,P)=[infρ∫dxdx′∥x−x′∥pρ(x,x′)]p1其中 ρ : R d × R d → R + \rho :\mathbb{R}^{d} \times \mathbb{R}^{d}\rightarrow \mathbb{R}^{+} ρ:Rd×Rd→R+是一个密度函数,其边缘密度满足 ρ ( x ) = q ( x ) , ρ ( x ′ ) = p ( x ) \rho( x) =q( x) ,\rho ( x') =p( x) ρ(x)=q(x),ρ(x′)=p(x),这个 ρ \rho ρ应该可以给定边缘密度然后用copula函数来构造。该距离违反所有3个公理。如果将Euclidean norm ∣ ∣ ∣ ∣ ||\ || ∣∣ ∣∣换成geodesic distance 可以满足公理2.
- Fisher distance D ( Q , P ) = E p [ ∥ ∇ x ln p ( x ) − ∇ x ln q ( x ) ∥ 2 ] D( Q,P) =E_{p}\left[ \| \nabla _{x}\ln p( x) -\nabla _{x}\ln q( x) \| ^{2}\right] D(Q,P)=Ep[∥∇xlnp(x)−∇xlnq(x)∥2],满足公理1,还可以推广到度量空间从而满足不变性,满足公理2.
- Max-min distance (MMD) D ( Q , P ) = sup f ( E [ f ] Q − E [ f ] P ) D( Q,P) =\sup _{f}( E[ f]_{Q} -E[ f]_{P}) D(Q,P)=supf(E[f]Q−E[f]P),其中f连续有界。违反公理3.
散度的不变性
当数据的坐标系发生变换后,两个分布的散度还是一样的吗?如果不能他会变成怎样?这一节就是为了探索这个问题。
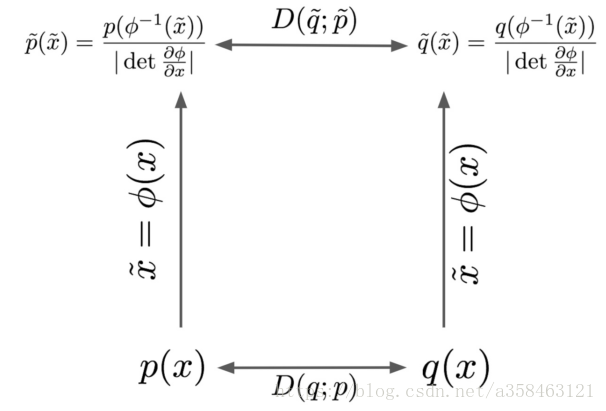
在上图x是没有变换的坐标系,而 x ~ = ϕ ( x ) \tilde{x} =\phi ( x) x~=ϕ(x)则是经过一个可逆函数$\phi $变换后得到的值,经过变换后,下表列出了所有统计量会出现的变化

根据表格的公式,我们可以发现两个有趣的事实
-
即使坐标发生了变化,但是密度与测度的乘积是不变的: p ~ ( x ~ ) d x ~ = p ∘ ϕ − 1 ( x ~ ) ∣ det ∂ ϕ ∂ x ∣ ∣ det ∂ ϕ ∂ x ∣ d x = p ( x ) d x \tilde{p}\left(\tilde{x}\right) d\tilde{x} =\frac{p\circ \phi ^{-1}\left(\tilde{x}\right)}{|\det\frac{\partial \phi }{\partial x} |} |\det\frac{\partial \phi }{\partial x} |dx=p( x) dx p~(x~)dx~=∣det∂x∂ϕ∣p∘ϕ−1(x~)∣det∂x∂ϕ∣dx=p(x)dx
-
概率密度的比率也是不变的: p ~ ( x ~ ) q ~ ( x ~ ) = \frac{\tilde{p}\left(\tilde{x}\right)}{\tilde{q}\left(\tilde{x}\right)} = q~(x~)p~(x~)= p ∘ ϕ − 1 ( x ~ ) ∣ det ∂ ϕ ∂ x ∣ \frac{p\circ \phi ^{-1}\left(\tilde{x}\right)}{|\det\frac{\partial \phi }{\partial x} |} ∣det∂x∂ϕ∣p∘ϕ−1(x~) ∣ det ∂ ϕ ∂ x ∣ q ∘ ϕ − 1 ( x ~ ) = p ( x ) q ( x ) \frac{|\det\frac{\partial \phi }{\partial x} |}{q\circ \phi ^{-1}\left(\tilde{x}\right)} =\frac{p( x)}{q( x)} q∘ϕ−1(x~)∣det∂x∂ϕ∣=q(x)p(x)
性质2恰恰说明了为什么在统计学中为什么似然比率这么常见,因为对于比率来说,他对数据的坐标系是不敏感的。同时这也说明了为什么散度只有在 D ( P , Q ) = ∫ f ( p ( x ) , q ( x ) , x ) d x = ∫ f ( p ( x ) q ( x ) ) p ( x ) d x D( P,Q) =\int f( p( x) ,q( x) ,x) dx=\int f\left(\frac{p( x)}{q( x)}\right) p( x) dx D(P,Q)=∫f(p(x),q(x),x)dx=∫f(q(x)p(x))p(x)dx时才会有invariant的性质(f-divergences)
如果散度中包含梯度,想要满足invariant的性质就更加困难了,因为梯度经过变换后是会形成一个张量的,想要有不变性,我们必须把这个张量给消除掉(乘一个逆)。举个例子,对于 ( ∇ x ln p ( x ) ) T ∇ x ln p ( x ) ( \nabla _{x}\ln p( x))^{T} \nabla _{x}\ln p( x) (∇xlnp(x))T∇xlnp(x)来说肯定不满足不变性,如果要满足就要在他们中间乘一个张量G来消掉他们的变化: ( ∇ x ln p ( x ) ) T G − 1 ∇ x ln p ( x ) ( \nabla _{x}\ln p( x))^{T} G^{-1} \nabla _{x}\ln p( x) (∇xlnp(x))TG−1∇xlnp(x) . 也就是说,对于Fisher distance,需要将 L 2 L_{2} L2 norm的散度,替换成可以抵消其变化的模才能保证其不变性。
补充:MMD :maximum mean discrepancy
MMD:
D
(
Q
,
P
)
=
sup
f
∈
F
(
E
[
f
]
Q
−
E
[
f
]
P
)
D( Q,P) =\sup _{f\in \mathcal{F}}( E[ f]_{Q} -E[ f]_{P})
D(Q,P)=f∈Fsup(E[f]Q−E[f]P)
MMD的思想是两个分布是相同的,那么对于任意变换后的均值也应该是相等的,那么这个函数到底取什么呢?其中的一种方法就是用kernel trick,该方法认为f是将x映射到希尔伯特空间上的映射,用$\phi $表示,于是其散度可以用以下kernel函数计算。
∥
1
m
∑
i
=
1
m
ϕ
(
x
i
)
−
1
n
∑
j
=
1
n
ϕ
(
y
i
)
∥
H
2
=
<
1
m
∑
i
=
1
m
ϕ
(
x
i
)
−
1
n
∑
j
=
1
n
ϕ
(
y
i
)
,
1
m
∑
i
=
1
m
ϕ
(
x
i
)
−
1
n
∑
j
=
1
n
ϕ
(
y
i
)
>
=
1
m
2
<
∑
i
=
1
m
ϕ
(
x
i
)
,
1
m
∑
i
=
1
m
ϕ
(
x
i
)
>
+
.
.
.
=
1
m
2
∑
i
=
1
m
∑
j
=
1
m
k
(
x
i
,
x
j
)
+
1
n
2
∑
i
=
1
n
∑
j
=
1
n
k
(
y
i
,
y
j
)
−
2
m
n
∑
i
=
1
m
∑
j
=
1
n
k
(
x
i
,
y
j
)
\begin{aligned} \| \frac{1}{m}\sum ^{m}_{i=1} \phi ( x_{i}) -\frac{1}{n}\sum ^{n}_{j=1} \phi ( y_{i}) \| ^{2}_{\mathcal{H}} & =< \frac{1}{m}\sum ^{m}_{i=1} \phi ( x_{i}) -\frac{1}{n}\sum ^{n}_{j=1} \phi ( y_{i}) ,\frac{1}{m}\sum ^{m}_{i=1} \phi ( x_{i}) -\frac{1}{n}\sum ^{n}_{j=1} \phi ( y_{i}) >\\ & =\frac{1}{m^{2}} < \sum ^{m}_{i=1} \phi ( x_{i}) ,\frac{1}{m}\sum ^{m}_{i=1} \phi ( x_{i}) >+...\\ & =\frac{1}{m^{2}}\sum ^{m}_{i=1}\sum ^{m}_{j=1} k( x_{i} ,x_{j}) +\frac{1}{n^{2}}\sum ^{n}_{i=1}\sum ^{n}_{j=1} k( y_{i} ,y_{j}) -\frac{2}{mn}\sum ^{m}_{i=1}\sum ^{n}_{j=1} k( x_{i} ,y_{j}) \end{aligned}\\
∥m1i=1∑mϕ(xi)−n1j=1∑nϕ(yi)∥H2=<m1i=1∑mϕ(xi)−n1j=1∑nϕ(yi),m1i=1∑mϕ(xi)−n1j=1∑nϕ(yi)>=m21<i=1∑mϕ(xi),m1i=1∑mϕ(xi)>+...=m21i=1∑mj=1∑mk(xi,xj)+n21i=1∑nj=1∑nk(yi,yj)−mn2i=1∑mj=1∑nk(xi,yj)
这个方法的直觉在于,如果
ϕ
(
x
)
=
x
\phi ( x) =x
ϕ(x)=x的话,就相当于比较两个分布的均值,如果
ϕ
(
x
)
=
[
x
x
2
]
\phi ( x) =\left[ x\ x^{2}\right]
ϕ(x)=[x x2]的话,就相当于比较均值和方差,那么如果φ足够复杂,我们就能够精确地计算两个分布间的差异!
补充:Wasserstein距离
该补充来自:https://zhuanlan.zhihu.com/p/25071913 ,是一篇非常棒的文章
注意Wasserstein距离不是散度,因此它是对称的,满足三角不等式等距离的性质。Wasserstein距离又叫Earth-Mover(EM)距离,定义如下:
W
(
P
r
,
P
g
)
=
inf
γ
∼
Π
(
P
r
,
P
g
)
E
(
x
,
y
)
∼
γ
[
∣
∣
x
−
y
∣
∣
]
W(P_r, P_g) = \inf_{\gamma \sim \Pi (P_r, P_g)} \mathbb{E}_{(x, y) \sim \gamma} [||x - y||]
W(Pr,Pg)=γ∼Π(Pr,Pg)infE(x,y)∼γ[∣∣x−y∣∣]
解释如下:
Π
(
P
r
,
P
g
)
\Pi (P_r, P_g)
Π(Pr,Pg)是
P
r
P_r
Pr和
P
g
P_g
Pg组合起来的所有可能的联合分布的集合,反过来说,
Π
(
P
r
,
P
g
)
\Pi (P_r, P_g)
Π(Pr,Pg)中每一个分布的边缘分布都是
P
r
P_r
Pr和
P
g
P_g
Pg。对于每一个可能的联合分布
γ
\gamma
γ而言,可以从中采样
(
x
,
y
)
∼
γ
(x, y) \sim \gamma
(x,y)∼γ得到一个真实样本x和一个生成样本y,并算出这对样本的距离
∣
∣
x
−
y
∣
∣
||x-y||
∣∣x−y∣∣,所以可以计算该联合分布
γ
\gamma
γ下样本对距离的期望值
E
(
x
,
y
)
∼
γ
[
∣
∣
x
−
y
∣
∣
]
\mathbb{E}_{(x, y) \sim \gamma} [||x - y||]
E(x,y)∼γ[∣∣x−y∣∣]。在所有可能的联合分布中能够对这个期望值取到的下界
inf
γ
∼
Π
(
P
r
,
P
g
)
E
(
x
,
y
)
∼
γ
[
∣
∣
x
−
y
∣
∣
]
\inf_{\gamma \sim \Pi (P_r, P_g)} \mathbb{E}_{(x, y) \sim \gamma} [||x - y||]
infγ∼Π(Pr,Pg)E(x,y)∼γ[∣∣x−y∣∣],就定义为Wasserstein距离。
直观上可以把 E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ] \mathbb{E}_{(x, y) \sim \gamma} [||x - y||] E(x,y)∼γ[∣∣x−y∣∣]理解为在 γ \gamma γ这个“路径规划”下把 P r P_r Pr这堆“沙土”挪到 P g P_g Pg“位置”所需的“消耗”,而 W ( P r , P g ) W(P_r, P_g) W(Pr,Pg)就是“最优路径规划”下的“最小消耗”,所以才叫Earth-Mover(推土机)距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
参考资料
[1] Cover, Thomas M., and Joy A. Thomas. Elements of information theory. John Wiley & Sons, 2012.
[2] short notes on divergence measures
[3] Caticha, Ariel. “Relative entropy and inductive inference.” AIP conference proceedings. Vol. 707. No. 1. AIP, 2004.
[4] CCN2018 tutorial : Deep Generative Models
[5] Ariel Caticha. Relative entropy and inductive inference. In AIP Conference Proceedings, volume 707, pages

















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









