







 本文介绍了一种结合ultralytics库中的yolov8s-world和mobile_sam模型的方法,以实现在语言指导下进行物体分割。虽然yolov8s-world在速度上有优势,但性能不如GroundingDINO。通过实验,作者发现yolov8s-world在精度上存在不足,但通过改进可能提高检测效果。
本文介绍了一种结合ultralytics库中的yolov8s-world和mobile_sam模型的方法,以实现在语言指导下进行物体分割。虽然yolov8s-world在速度上有优势,但性能不如GroundingDINO。通过实验,作者发现yolov8s-world在精度上存在不足,但通过改进可能提高检测效果。
lang-segment-anything基于segment-anything 和 GroundingDINO 实现基于语言分割出任意对象,但是segment-anything 模型与GroundingDINO 都是运算量比较大的模型。而mobile_sam号称是sam的同等性能替代品,而yolo-world同样是号称比GroundingDINO 更快更准,故而博主尝试基于ultralytics项目,使用yolo-world与mobile_sam的组合实现类似lang-segment-anything的功能。
1、背景说明
1.1 mobile_sam
MobileSAM本质就是对SAM中ViT模型的知识蒸馏,使用了原来SAM中的mask解码器。其采用解耦蒸馏的方式,使得image encoder变得十分小,同时也保持了相同的性能。
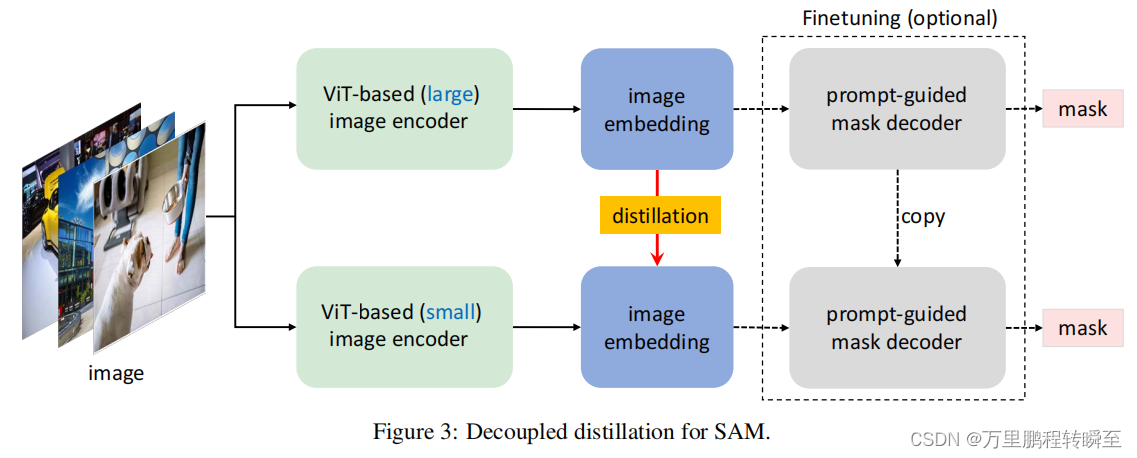
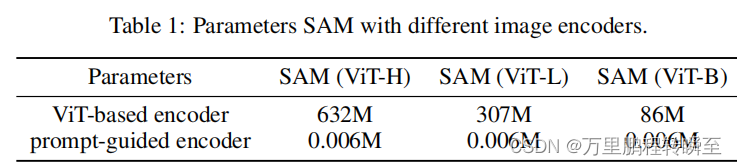

1.2 yolo-world
YOLO-World,这是一种创新的方法,通过视觉语言建模和在大型数据集上的预训练,将YOLO与开集检测能力相结合。具体来说,作者提出了一种新的可重参化的视觉语言路径聚合网络(RepVL-PAN)和区域文本对比损失,以促进视觉和语言信息之间的交互。作者的方法在以零样本方式检测广泛范围的物体时表现出色,且效率高。
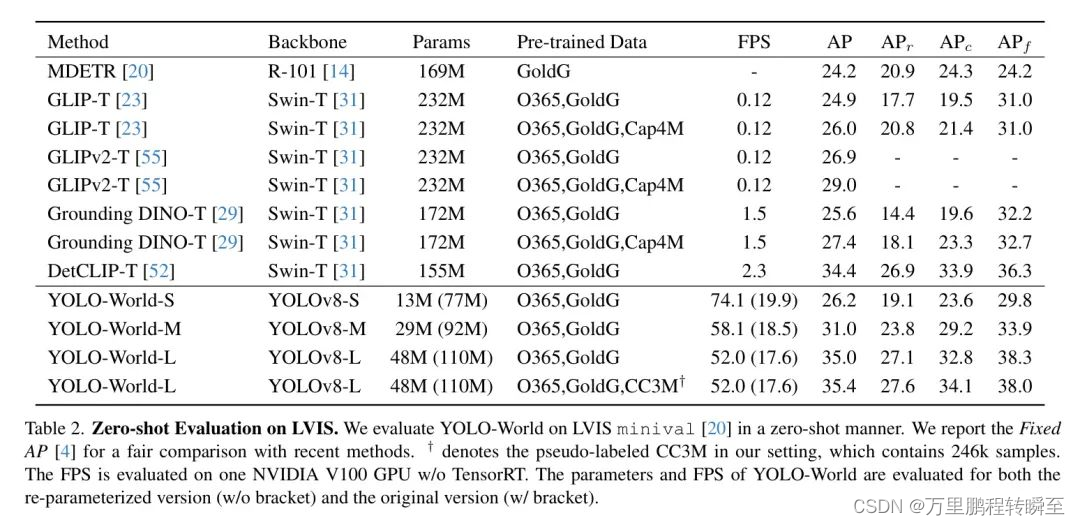
在具有挑战性的LVIS数据集上,YOLO-World在V100上实现了35.4 AP和52.0 FPS,在准确性和速度上都超过了许多最先进的方法。此外,经过微调的YOLO-World在包括目标检测和开集实例分割在内的几个下游任务上取得了显著性能。
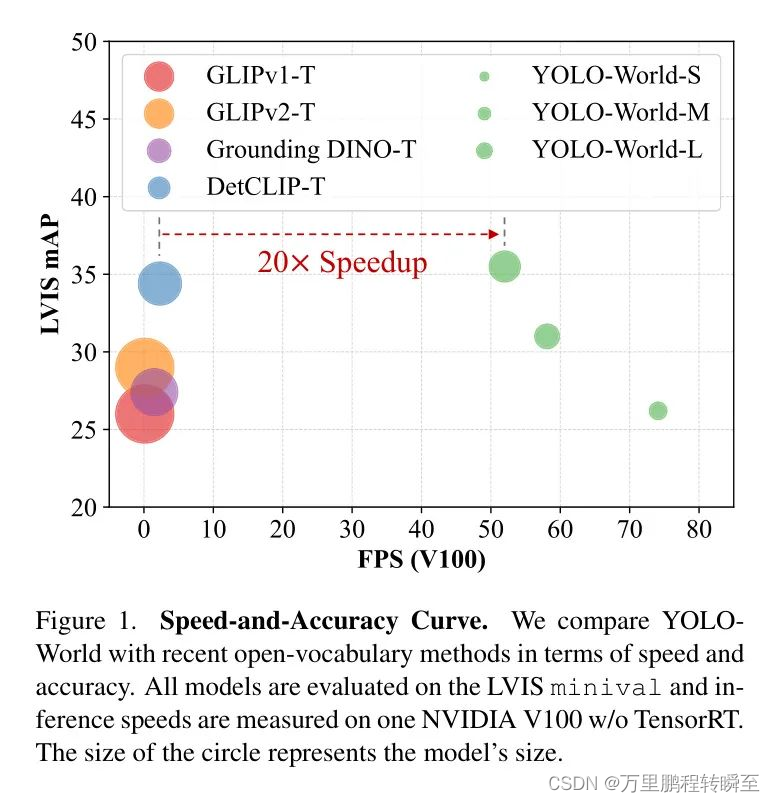
根据yolo-wolrd的论文数据,其比GroundingDINO 要强很多。
2、实现与使用
安装依赖项
pip install ultralytics
pip install gradio
pip install lightning
2.1 实现代码
以下代码支持多种任务组合,基于task type可以指定是否使用mobile_sam对目标检测结果进行细化分割;基于第二个参数,设置text可以指定检测类型,设置all则检测所有目标。
以下代码涉及到一个目录 assets,该目录源自项目 https://github.com/luca-medeiros/lang-segment-anything/tree/main 中的资源

运行以下代码,会自动打开浏览器,具体内容如2.2中图所示。
import os
import warnings
from ultralytics import YOLO,SAM
import gradio as gr
import lightning as L
import numpy as np
from lightning.app.components.serve import ServeGradio
from PIL import Image
warnings.filterwarnings("ignore")
sam_model = SAM("mobile_sam.pt")
model_det_all = YOLO('yolov8s-world.pt') # or choose yolov8m/l-world.pt
class LitGradio(ServeGradio):
inputs = [
gr.Dropdown(choices=['seg','det'], label="task type", value="text"),
gr.Dropdown(choices=['text','all'], label="检测所有(all)?或根据text检测(text)", value="text"),
gr.Slider(0, 1, value=0.25, label="Text threshold"),
gr.Image(type="filepath", label='Image'),
gr.Textbox(lines=1, label="Text Prompt"),
]
outputs = [gr.outputs.Image(type="pil", label="Output Image")]
examples = [
[
'seg',
'text',
0.25,
os.path.join(os.path.dirname(__file__), "assets", "fruits.jpg"),
"kiwi",
],
[
'seg',
'text',
0.25,
os.path.join(os.path.dirname(__file__), "assets", "car.jpeg"),
"car",
],
[
'seg',
'text',
0.25,
os.path.join(os.path.dirname(__file__), "assets", "food.jpg"),
"food",
],
]
def __init__(self,):
super().__init__()
self.ready = False
def predict(self, task_type, text_promt, box_threshold, image_path, text_prompt):
print("Predicting... ", box_threshold, image_path, text_prompt,text_prompt.split(";"))
pimg=Image.open(image_path)
img=np.array(pimg)
if text_promt=='text':
self.model.set_classes(text_prompt.split(";"))
results = self.model.predict(img,conf=box_threshold)
print("det by text prompt!")
else:
results = model_det_all.predict(img,conf=box_threshold)
print("det all!")
result=results[0]
# Show det results
#image=result.plot()
#image = Image.fromarray(np.uint8(image))#.convert("RGB")
#--segment
if len(result.boxes)>0:
if task_type=='seg':
boxes = result.boxes.xyxy
sam_results = sam_model(result.orig_img, bboxes=boxes, device='cuda')
image=sam_results[0].plot()
image = Image.fromarray(np.uint8(image))
print("seg detect boxes!")
return image
else:
image=result.plot()
image = Image.fromarray(np.uint8(image))
print("show detect boxes!")
return image
else:
return pimg
def build_model(self, model_type="yolov8s-world.pt"):
model = YOLO(model_type)
self.ready = True
return model
lg=LitGradio()
import os
os.environ["LIGHTNING_DETECTED_DEBUGGER"] = "1"
app = L.LightningApp(lg)
2.2 使用效果
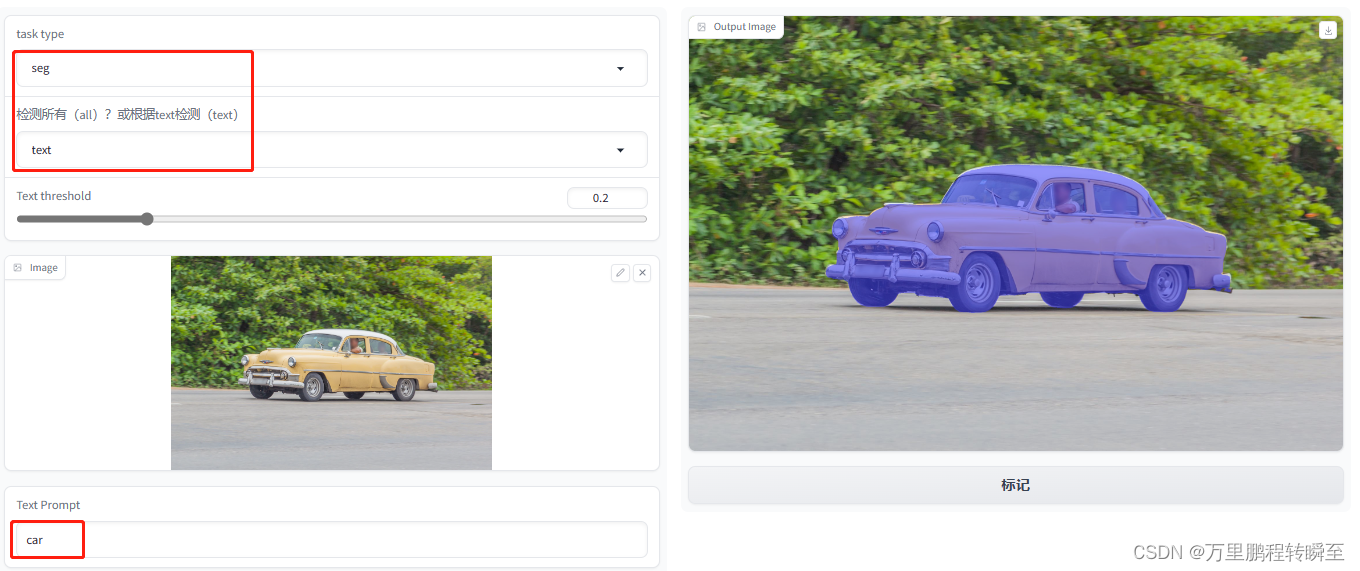
使用效果如下所示,个人觉得是不如lang-segment-anything,这应该是yolo-world性能不足所导致的。
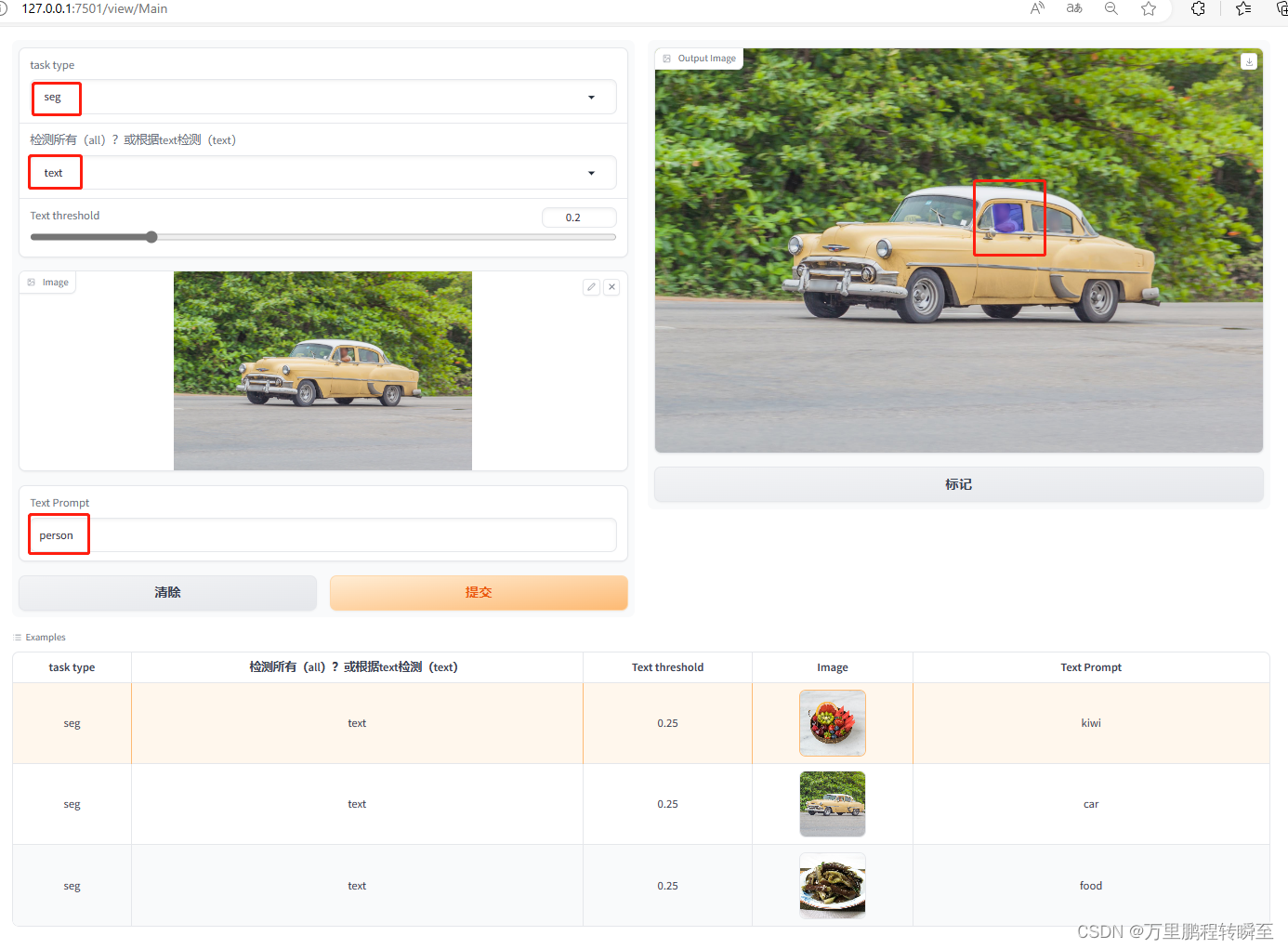
可以看出,yolo-world检测的目标数很少,车灯、车轮都没有检测出
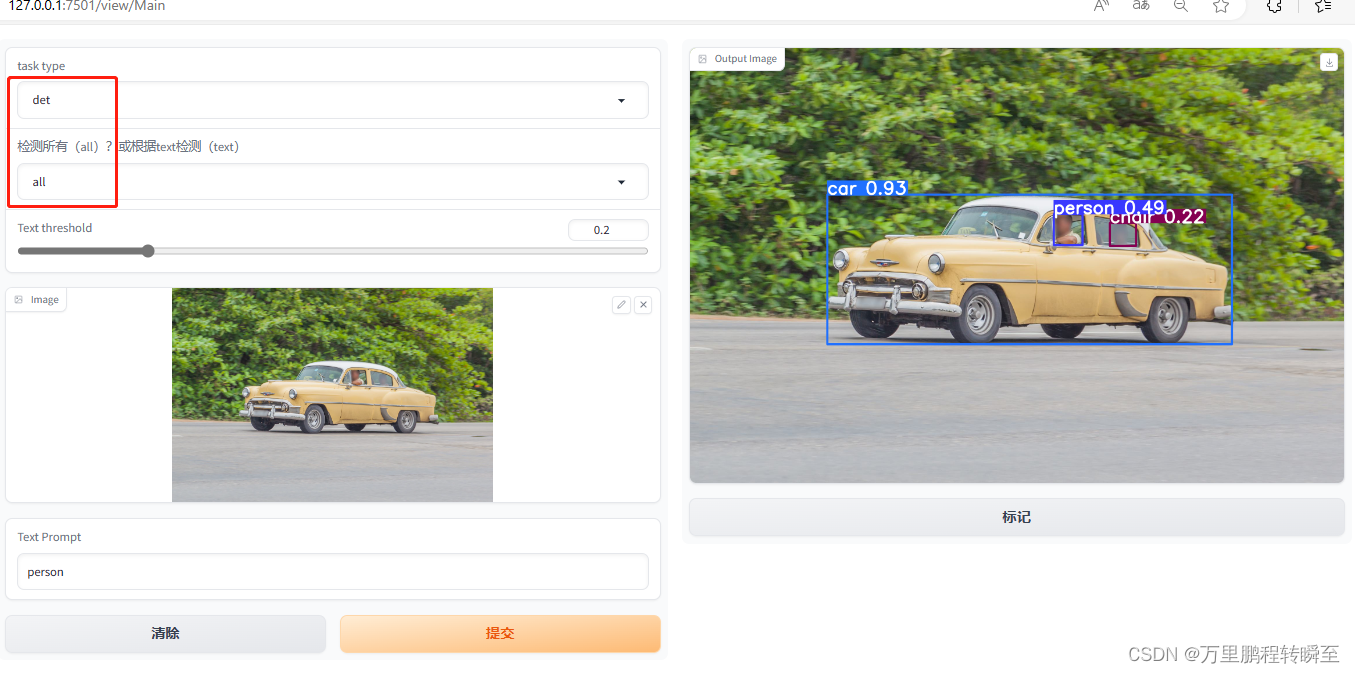
虽然效果略差,但是速度有显著提升。或许更换更强的yolo-world模型,或许可以检测出更多目标。


















 8523
8523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











