







官网地址:https://internvl.readthedocs.io/en/latest/internvl2.5/introduction.html
模型地址:https://www.modelscope.cn/models/OpenGVLab/InternVL2_5-8B
开源时间:2024/12/05
InternVL2.5是第一个在 MMMU 基准上达到 70% 以上的开源 MLLM, 其以InternVL2的研究工作为基础,在模型结构上没有过多调整,但在数据处理逻辑、模型训练策略、训练数据增广方式进行优化,从而实现了有效的整体涨点。这些涨点工作表明,如果我们以InternVL2.5为基模,在过多的私域数据上训练,如果没有采用相同的数据策略,预计只会比InternVL2强一点点。毕竟InternVL2.5的强大不是完全依赖基模的提升,而是训练策略的调整。
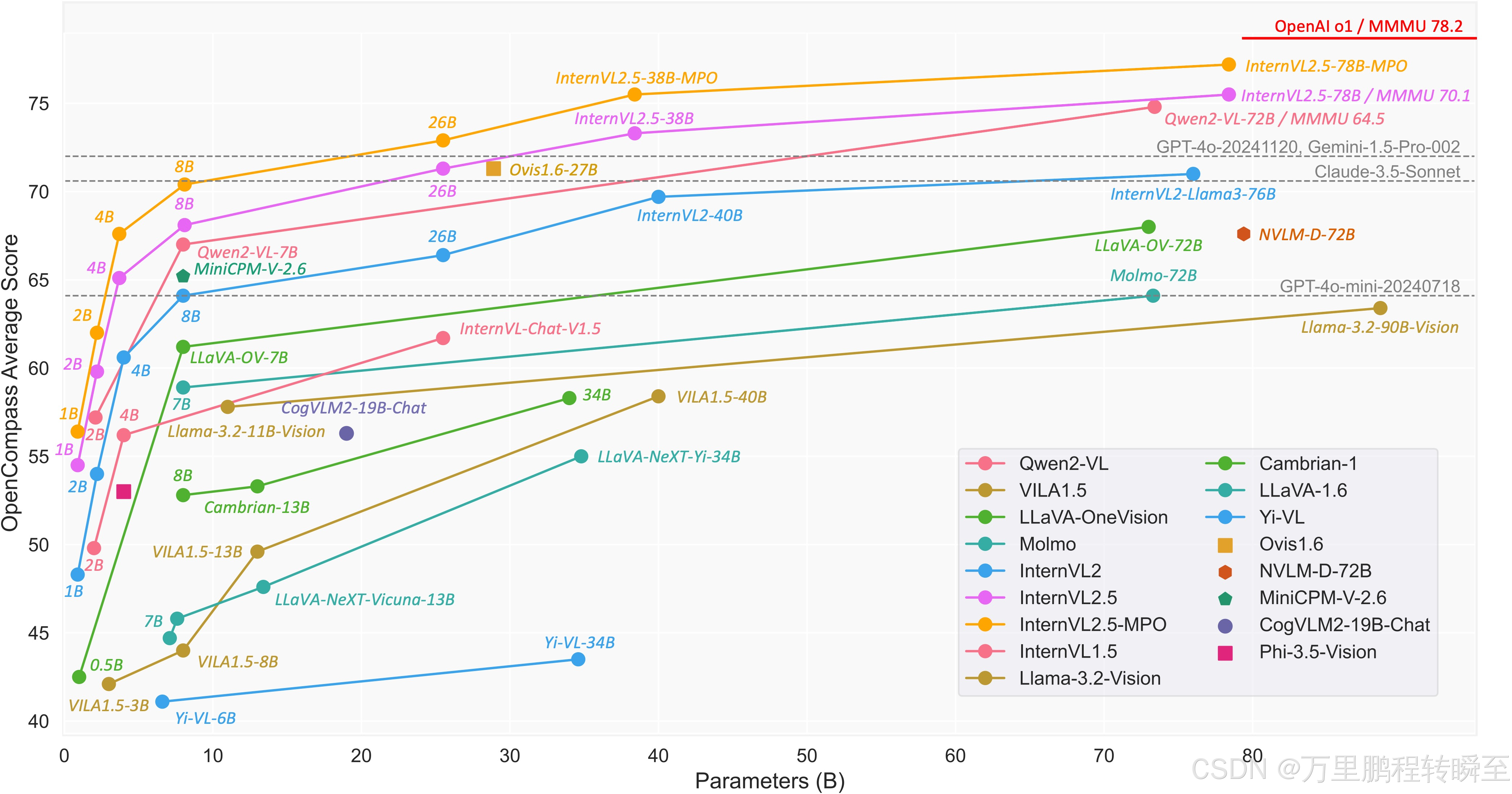
InternVL2.5的模型结构如下所示,可以发现与InternVL2高度一致,只是在部分模型上使用了qwen2.5
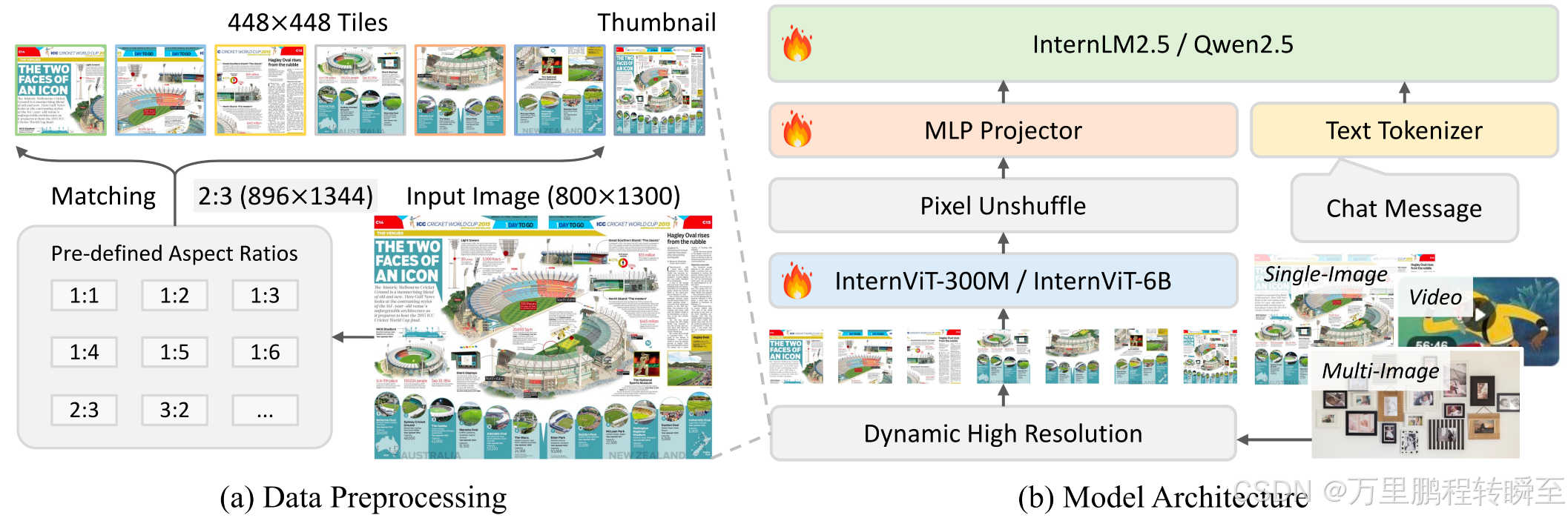
关于internvl2.5输入数据的处理流程可以参考: https://blog.csdn.net/qq_37734256/article/details/145149448
1、模型结构
1.1 模型版本
InternVL2.5 与InternVL2保持了相同的模型版本,只是在最大模型上,2.5使用了qwen2.5 72b模型,2使用了llama-3-70b模型。其中关于InternVL2.5 8b、26b模型与InternVL2是一模一样的(只是vit版本变成了2.5)。但是在公布的MMMU 榜单上,InternVL2.5 8b模型比InternVL2 8b模型高了4~5个点,甚至比InternVL2 26b也要强3个点左右。这里所展现的就不在是llm能力提升带动mllm能力提升了。

1.2 与VL2模型的差异
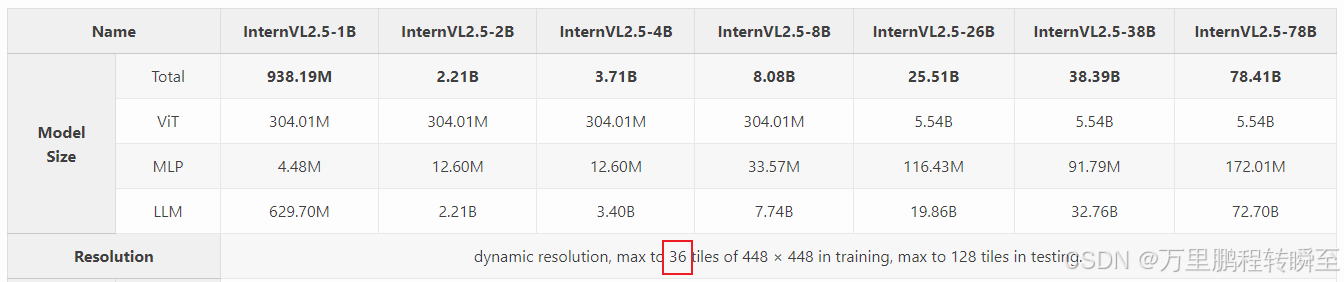
InternVL2.5 的模型结构细节如下所示,以8b、26b模型为重点观察,可以发现与InternVL2模型在VIT、MLP、LLM参数上是一模一样的。仅是在动态分辨率策略上,有所差异,原先是12个子图,现在是36个子图。同时,在测试环节,子图也增大了。

关于动态分辨率深入可以发现以下分片规则
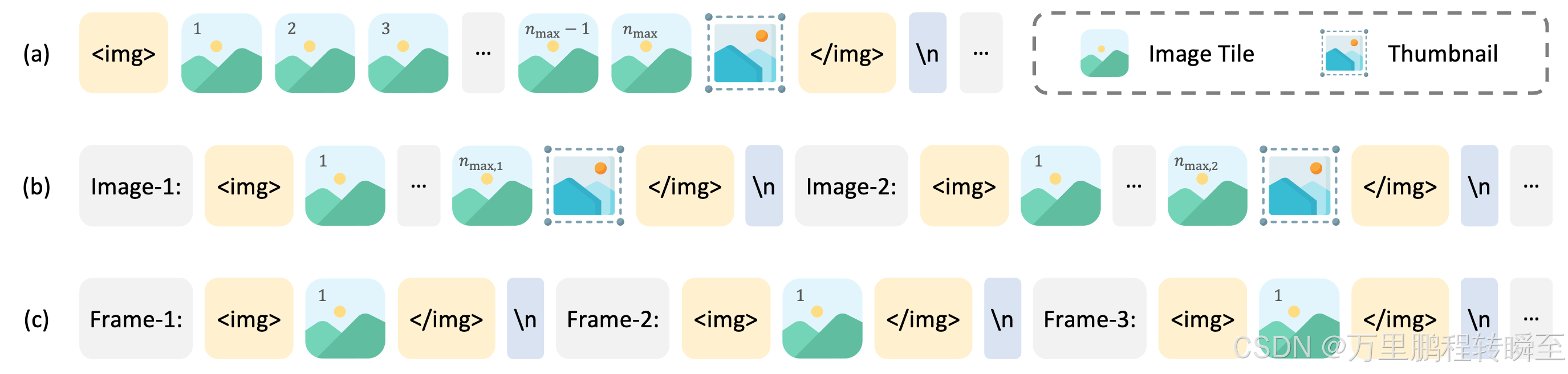
对于单图像数据集,切片总数将分配给单个图像以获得最大分辨率。视觉标记包含在 and 标记中。n_max<img></img>
对于多图像数据集,瓦片总数分布在样本中的所有图像中。每张图像都标有辅助标签,例如 and 括在 and 标签中。n_max Image-1<img></img>
对于视频,每帧的大小调整为 448×448。框架使用标签进行标记,例如 and 括在 and 标签中,类似于图像。Frame-1
2、方法改进
2.1 渐进式缩放策略
渐进式缩放策略:我们提出了一种渐进式缩放策略,以有效地将视觉编码器与 LLM 对齐。该策略采用分阶段训练方法,从较小、资源高效的 LLM 开始,然后逐步扩展到更大的 LLM。这种方法源于我们的观察,使 ViT 和 LLM 使用 NTP 损失进行联合训练,生成的视觉特征也是其他 LLM 可以轻松理解的可推广表示。
具体来说,InternViT 与较小的 LLM(例如 20B)一起训练,专注于优化基本视觉能力和跨模态对齐。此阶段避免了与直接使用大型 LLM 进行训练相关的高计算成本。使用共享权重机制,经过训练的 InternViT 可以无缝转移到更大的 LLM(例如 72B),而无需重新训练。因此,在训练更大的模型时,需要的数据要少得多,计算成本也大大降低。 【即VIT与小规模LLM对齐后,可以快速无缝的迁移到大规模LLM中】`
与 Qwen2-VL 的 1.4 万亿个token相比,InternVL2.5-78B 仅使用 1200 亿个token,不到十分之一。此策略可最大限度地减少冗余,最大限度地提高预训练组件的重用率,并支持对复杂视觉语言任务进行高效训练。
2.2 改进的训练策略
改进的训练策略:为了增强模型对真实场景和整体性能的适应性,我们引入了两种关键技术: 随机 JPEG 压缩 和 损失重新加权。
-
对于随机 JPEG 压缩,将应用质量级别在 75 到 100 之间的随机 JPEG 压缩,以模拟 Internet 来源图像中常见的退化。
-
对于损失加权,我们以统一的格式表达广泛应用的策略(即token 平均和样本平均),并提出平方平均来平衡对多或短响应的梯度偏差。Random JPEG CompressionLoss Reweighting
【将图像退化引入到了数据增强中,由样本平均与token平均】
2.3 结构良好的数据组织
结构良好的数据组织:对训练数据的质量进行提升,基于 LLM 的质量评分和基于规则的过滤组成的过滤管道
数据集配置
在 InternVL 2.0 和 2.5 中,训练数据的组织由几个关键参数控制,以优化训练期间数据集的平衡和分布。

数据增强:JPEG 压缩是有条件地应用的:对图像数据集启用以增强稳健性,对视频数据集禁用以保持一致的帧质量。
最大图块数量:该参数控制每个数据集的最大图块数。例如,较高的值 (24-36) 用于多图像或高分辨率数据,较低的值 (6-12) 用于标准图像,1 用于视频。n_max
重复系数:重复因子调整数据集采样频率。低于 1 的值会降低数据集的权重,而高于 1 的值会增加数据集的权重。这可确保任务之间的均衡训练,并防止过拟合或欠拟合。
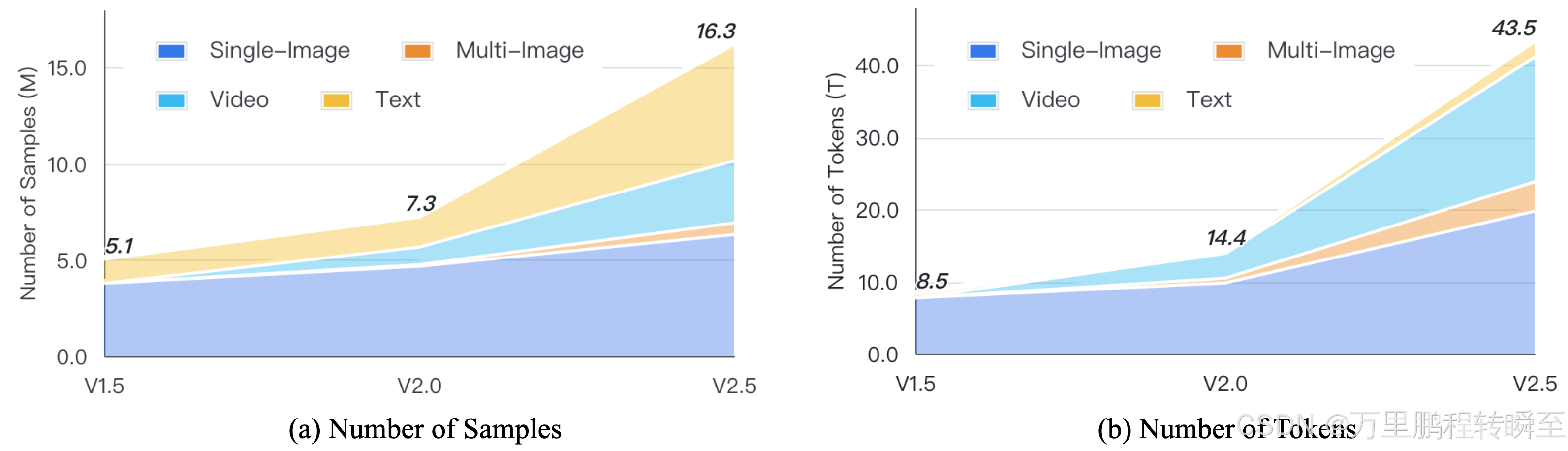
在总体的训练数据规模上,可以发现v2.5比v2模型多了近一倍,同时由于tille数量的变化,训练token数提升的比例变得更大了。
数据筛选管道 在开发过程中,我们发现 LLM 对数据噪声高度敏感,即使是很小的异常(如异常值或重复数据)也会在推理过程中引起异常行为。事实证明,重复生成,尤其是在长格式或 CoT 推理任务中,特别有害。

为了应对这一挑战并支持未来的研究,我们设计了一种高效的数据过滤管道来去除低质量的样本。
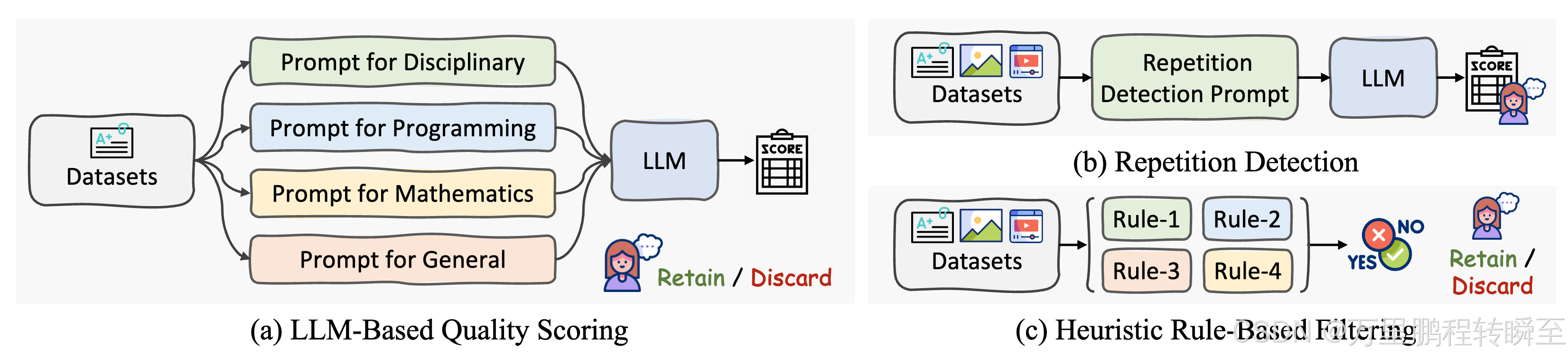
该管道包括两个模块,对于纯文本数据,使用了三个关键策略:
- 基于 LLM 的质量评分:使用预先训练的 LLM 和特定领域的提示对每个样本进行评分 (0-10)。分数低于阈值(例如 7)的样本将被删除,以确保数据质量。
- 重复检测:使用基于 LLM 的提示标记重复样本并手动审查。得分低于更严格阈值(例如 3)的样本被排除在外,以避免重复模式。
- 基于规则的启发式过滤:使用规则检测异常句子长度或重复行等异常情况。标记的样品在去除前经过手动验证以确保准确性。
对于多模态数据,使用两种策略:
重复检测:标记非学术数据集中的重复样本并手动审查,以防止模式循环。高质量的数据集不受此过程的约束。
基于规则的启发式过滤:应用类似的规则来检测视觉异常,手动验证标记的数据以保持完整性。
3、训练步骤
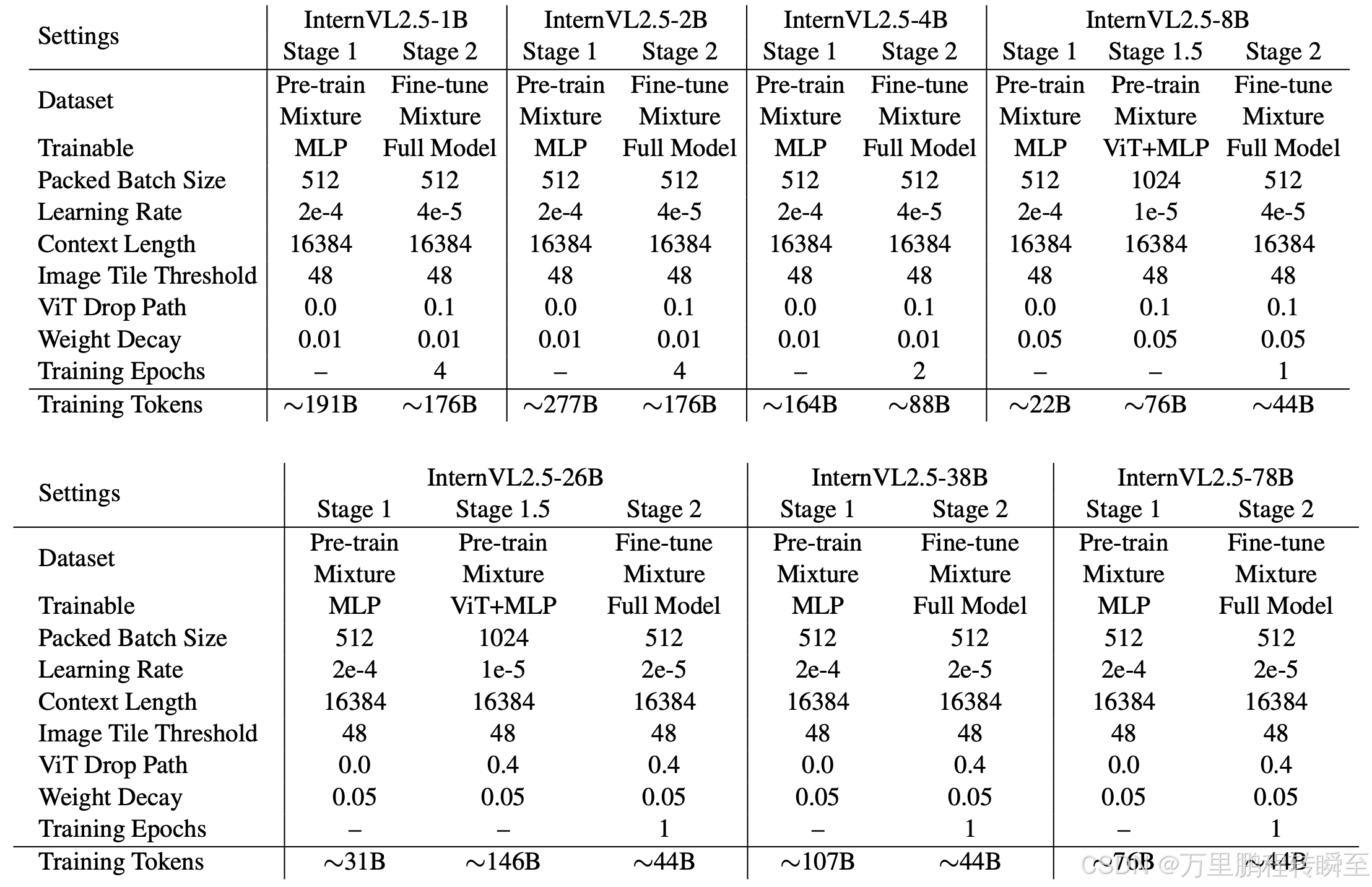
这里可以发现与2版本模型相比,多了一个可选的1.5步骤.
第 1 阶段:MLP 预热。在此阶段,仅训练 MLP 投影仪,而冻结视觉编码器和语言模型。尽管成本增加,但应用动态高分辨率训练策略以获得更好的性能。此阶段可确保稳健的跨模态对齐,并为稳定的多模态训练准备模型。
阶段 1.5:ViT 增量学习(可选)。此阶段允许使用与阶段 1 相同的数据对视觉编码器和 MLP 投影仪进行增量训练。它增强了编码器处理多语言 OCR 和数学图表等罕见域的能力。训练后,编码器可以在 LLM 之间重复使用,而无需重新训练,除非引入新域,否则此阶段是可选的。
第 2 阶段:全模型指令调整。整个模型在高质量的多模态教学数据集上进行训练。实施严格的数据质量控制以防止 LLM 降级,因为嘈杂的数据会导致重复或不正确的输出等问题。在此阶段之后,训练过程完成。

4、模型效果
详细的模型效果可以参考:https://www.modelscope.cn/models/OpenGVLab/InternVL2_5-8B,这里只是摘取了博主认为重要的部分。
4.1 CoT prompt效果
CoT是通过让GPT参考Prompt中的中间推理步骤,然后询问类似的问题,将GPT的推理透明化,从而获得比原始提问更高的准确率。以下数据展示了,InternVL 2.5 26b模型使用CoT的提问方式也能获取精度提升,而V2版本的同架构模型则没有增益。CoT方式通常只能在大参数模型上去的有益效果,而这个案例中的llm模型是一样的,只能表明是训练数据的变多,使得llm部分能力提升了。

关于CoT prompt的应用效果 https://zhuanlan.zhihu.com/p/659102403,有详细的说明。
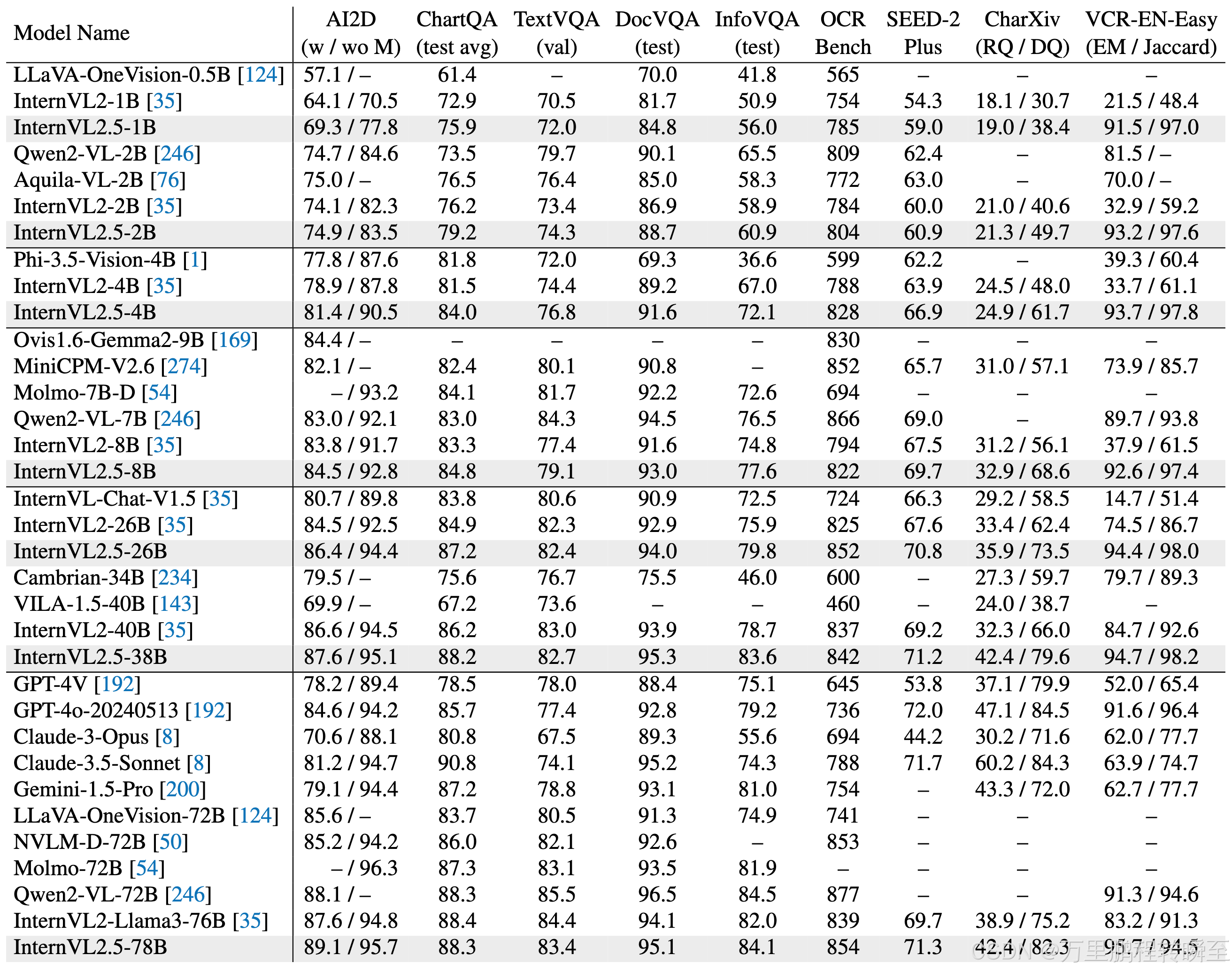
4.2 OCR、图表和文档理解
4.3 多图像和真实世界理解
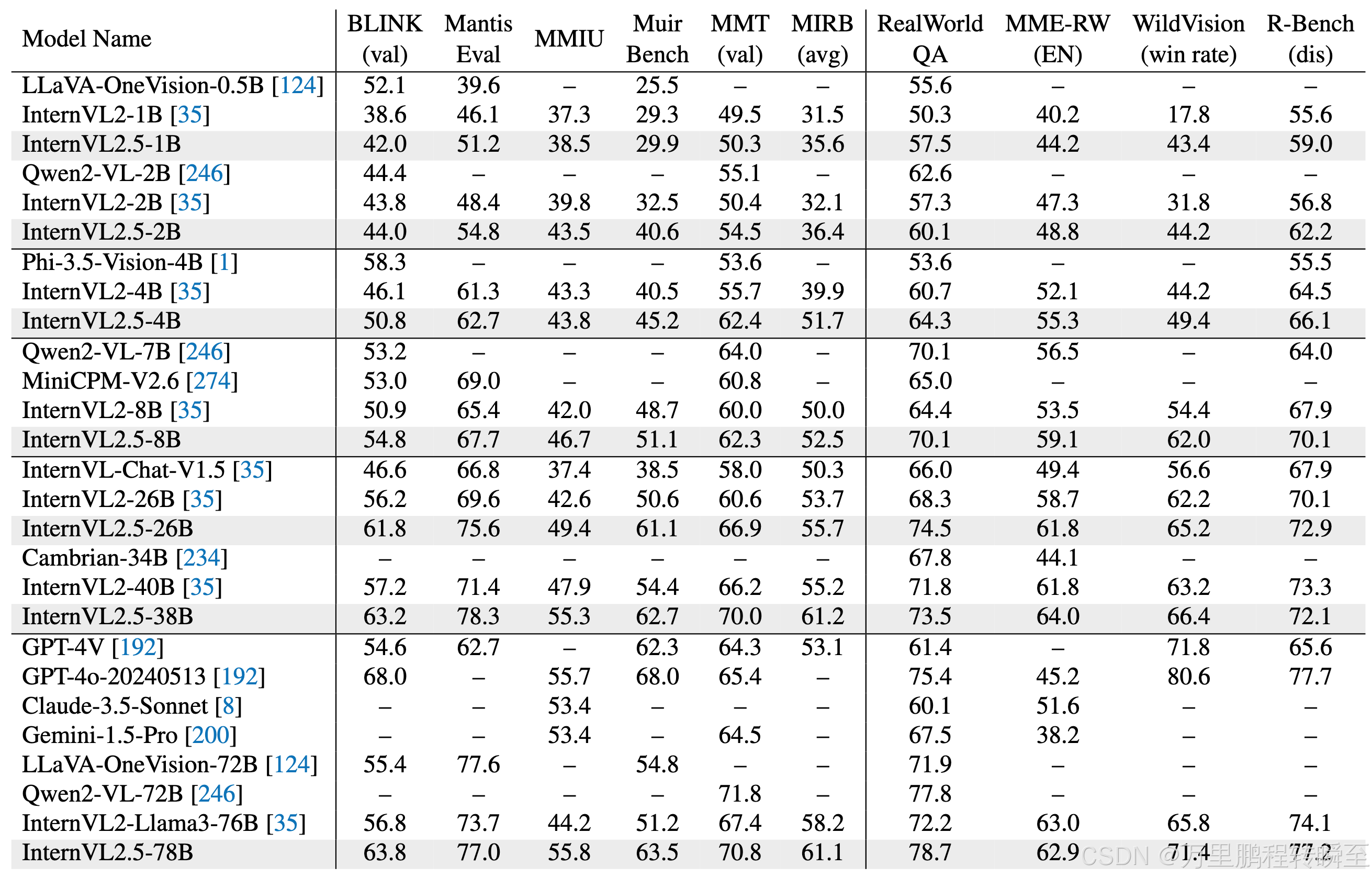
4.4 视频理解
这里主要与Qwen2-vl模型对比,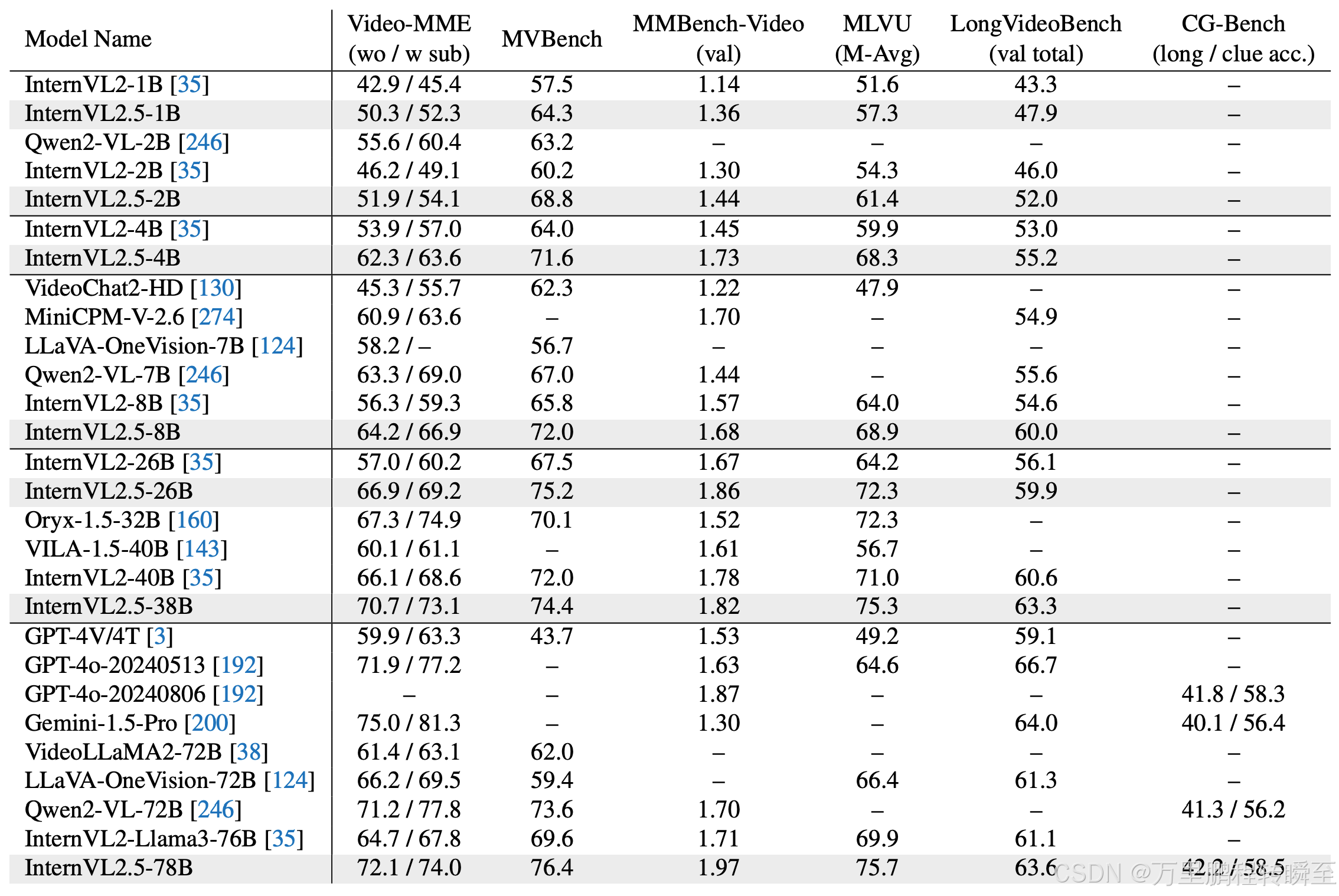


















 1974
1974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











