







【多模态】internvl-2.5模型技术学习
1.前言
在12月的时候,internvl2.5也出来了,效果看上去比qwen2-vl好一些,和minicpm-o-2.6接近,internvl2.5的架构、图片处理方式和minicpmv更像。
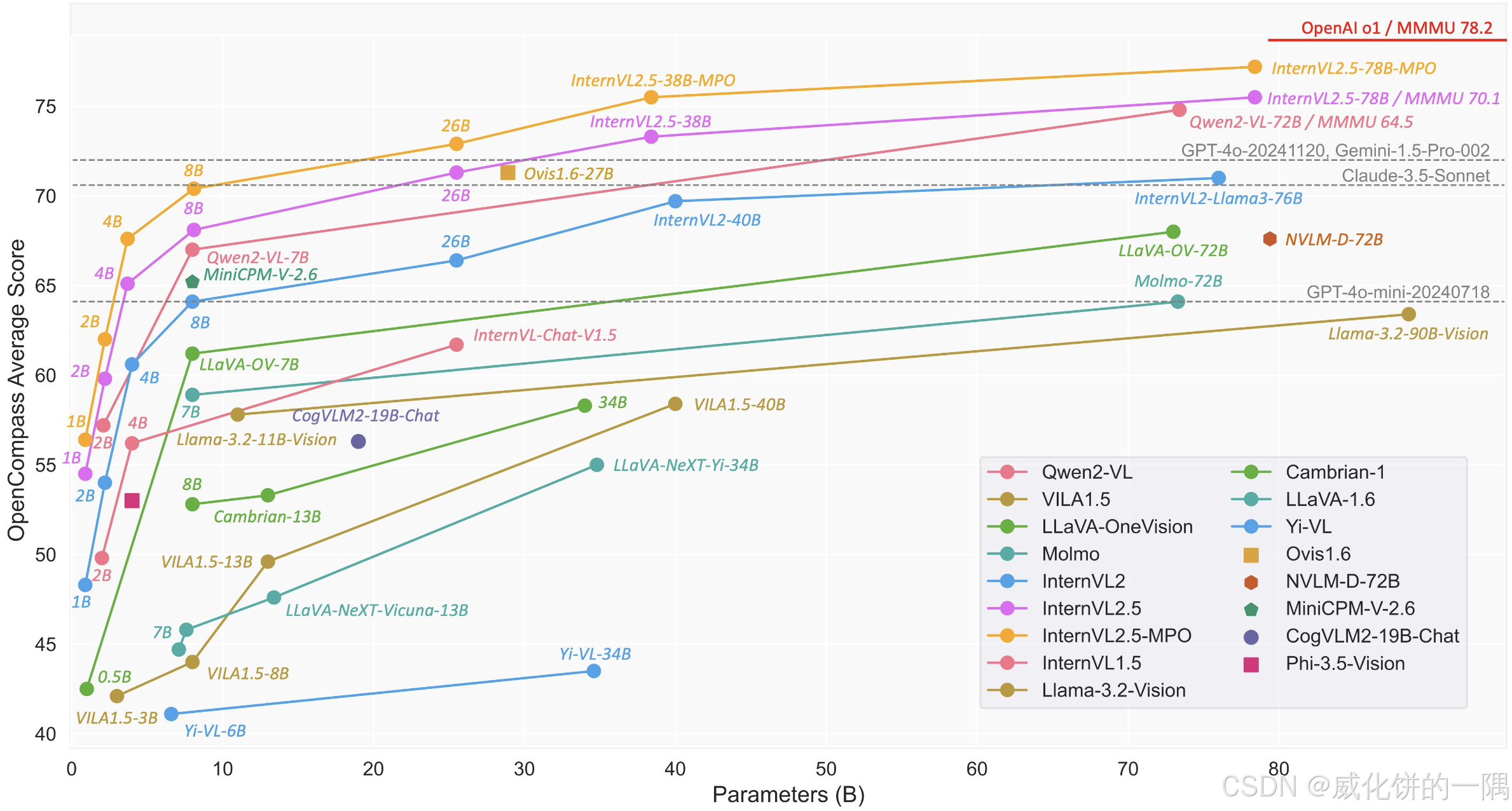
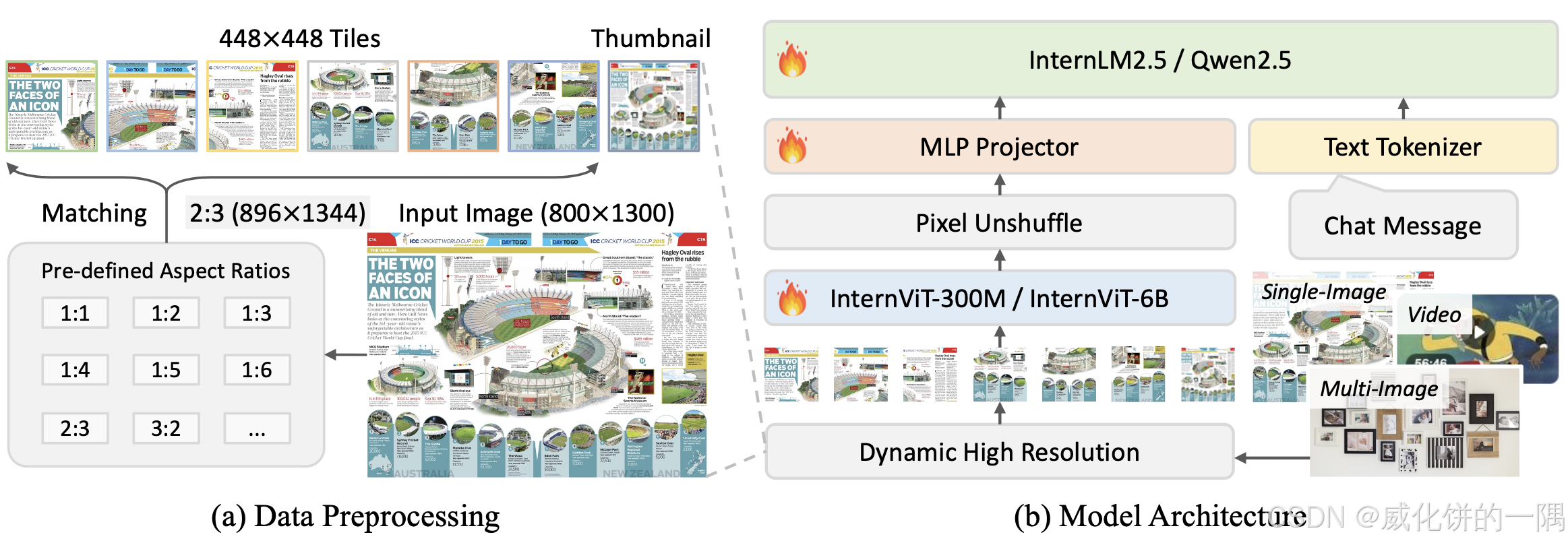
2.internvl2.5架构
架构上internvl2.5延续了internvl系列的架构,也是ViT+merger+LLM,对于图片的处理上和minicpmv类似,采用了放缩后切图的策略。
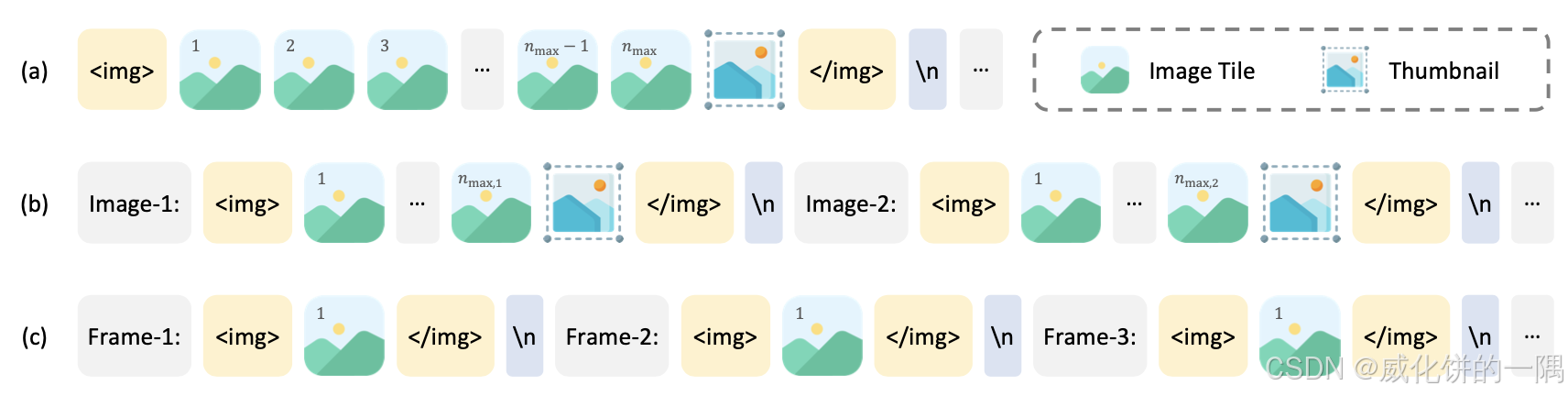
3.internvl2.5输入流程
以官方的代码示例为例
3.1 图片动态裁剪
对于一张大小为2300*1200的图片,load image时会计算最优的裁剪方案,在dynamic_preprocess函数中完成。最优的是缩放为
4
×
2
4 \times 2
4×2的比例,默认像素单位为
448
×
448
448 \times 448
448×448(internvl没有改变原始ViT的分辨率),resize之后的图片大小为(1792,896),然后要把原图图片切成8块(image tile x),每块是
448
×
448
448 \times 448
448×448,再把缩小的原图贴在最后(thumbnile),总共9个
448
×
448
448 \times 448
448×448的图片块。
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB') # (2300,1200)
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values # (9,3,448,448)
3.2 图片位置预留
进入chat中,首先拼接和预留token用于存放image信息, 448 × 448 448 \times 448 448×448大小的图片经过ViT后是变成 32 × 32 32 \times 32 32×32的(patch_size=14),internvl会压缩然后只保留1/4长度的token得到 16 × 16 16 \times 16 16×16大小,self.num_image_token=256,预留出放图片的位置。
for num_patches in num_patches_list: # num_patches=9
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
query = query.replace('<image>', image_tokens, 1)
3.3 ViT提取图片特征
def extract_feature(self, pixel_values):
vit_embeds = self.vision_model(
pixel_values=pixel_values,
output_hidden_states=True,
return_dict=True).hidden_states[self.select_layer]
(1)图片进encoder之前,先把像素进行编码,patch_embedding卷积,实际上是进行互相不交叉的卷积,步长大小都是patch_size=14,然后还进行了乘法运算,和原始ViT一致。最后拼接上了一个class_embedding,现在大小变为(9, 1025, 1024)。
# InternVisionEmbeddings
self.patch_embedding = nn.Conv2d(
in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size
) # embed_dim=1024
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
# pixel_values (9, 3, 448, 448)
target_dtype = self.patch_embedding.weight.dtype
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, channel, width, height] (9, 1024, 32, 32)
batch_size, _, height, width = patch_embeds.shape
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
class_embeds = self.class_embedding.expand(batch_size, 1, -1).to(target_dtype)
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
position_embedding = torch.cat([
self.position_embedding[:, :1, :],
self._get_pos_embed(self.position_embedding[:, 1:, :], height, width)
], dim=1)
embeddings = embeddings + position_embedding.to(target_dtype)
return embeddings # (9, 1025, 1024)
(2)在extract_feature的最后一步是特征压缩,pixel_shuffle函数
def extract_feature(self, pixel_values):
if self.select_layer == -1:
vit_embeds = self.vision_model(
pixel_values=pixel_values,
output_hidden_states=False,
return_dict=True).last_hidden_state
else:
vit_embeds = self.vision_model(
pixel_values=pixel_values,
output_hidden_states=True,
return_dict=True).hidden_states[self.select_layer]
vit_embeds = vit_embeds[:, 1:, :] # 取的(9,1024,1024)
h = w = int(vit_embeds.shape[1] ** 0.5) # h=w=32
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], h, w, -1) #(9, 32, 32, 1024)
vit_embeds = self.pixel_shuffle(vit_embeds, scale_factor=self.downsample_ratio) # downsample_ratio=0.5,输出大小为(9, 16, 16, 4096)
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], -1, vit_embeds.shape[-1]) # (9, 256, 4096)
vit_embeds = self.mlp1(vit_embeds) # 然后经过一个mlp和对应上文本向量大小
return vit_embeds
(3)具体的,internvl系列使用的是pixel_shuffle方式,把token的长度减少为之前的1/4,宽度变大了,和qwen2-vl很像,不过internvl在压缩时没有过mlp,压缩完之后过的mlp1,向量维度统一到文本向量的维度。
def pixel_shuffle(self, x, scale_factor=0.5):
n, w, h, c = x.size()
# N, W, H, C --> N, W, H * scale, C // scale
x = x.view(n, w, int(h * scale_factor), int(c / scale_factor))
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
x = x.permute(0, 2, 1, 3).contiguous()
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
x = x.view(n, int(h * scale_factor), int(w * scale_factor),
int(c / (scale_factor * scale_factor)))
if self.ps_version == 'v1':
warnings.warn("In ps_version 'v1', the height and width have not been swapped back, "
'which results in a transposed image.')
else:
x = x.permute(0, 2, 1, 3).contiguous()
return x
3.4 向量拼接,LLM推理
最后把图片信息填入到文本向量上预留的位置上,再输入到LLM中
if pixel_values is not None:
if visual_features is not None:
vit_embeds = visual_features
else:
vit_embeds = self.extract_feature(pixel_values)
input_embeds = self.language_model.get_input_embeddings()(input_ids)
B, N, C = input_embeds.shape
input_embeds = input_embeds.reshape(B * N, C)
input_ids = input_ids.reshape(B * N)
selected = (input_ids == self.img_context_token_id) # 找到预留的图片位置
assert selected.sum() != 0
# 把图片embedding填入进去
input_embeds[selected] = vit_embeds.reshape(-1, C).to(input_embeds.device)
4. 论文里提到的一些点
- internvl训练方式上,和minicpm-v一样,没怎么训练ViT,qwen2-vl是重新训练了ViT。并且internvl里面用的是下一词预测的loss,不像之前的多模态模型还有图文对比学习的loss,现在直接端到端训练了,qwen-vl/qwen2-vl也是直接ce_loss端到端训练。
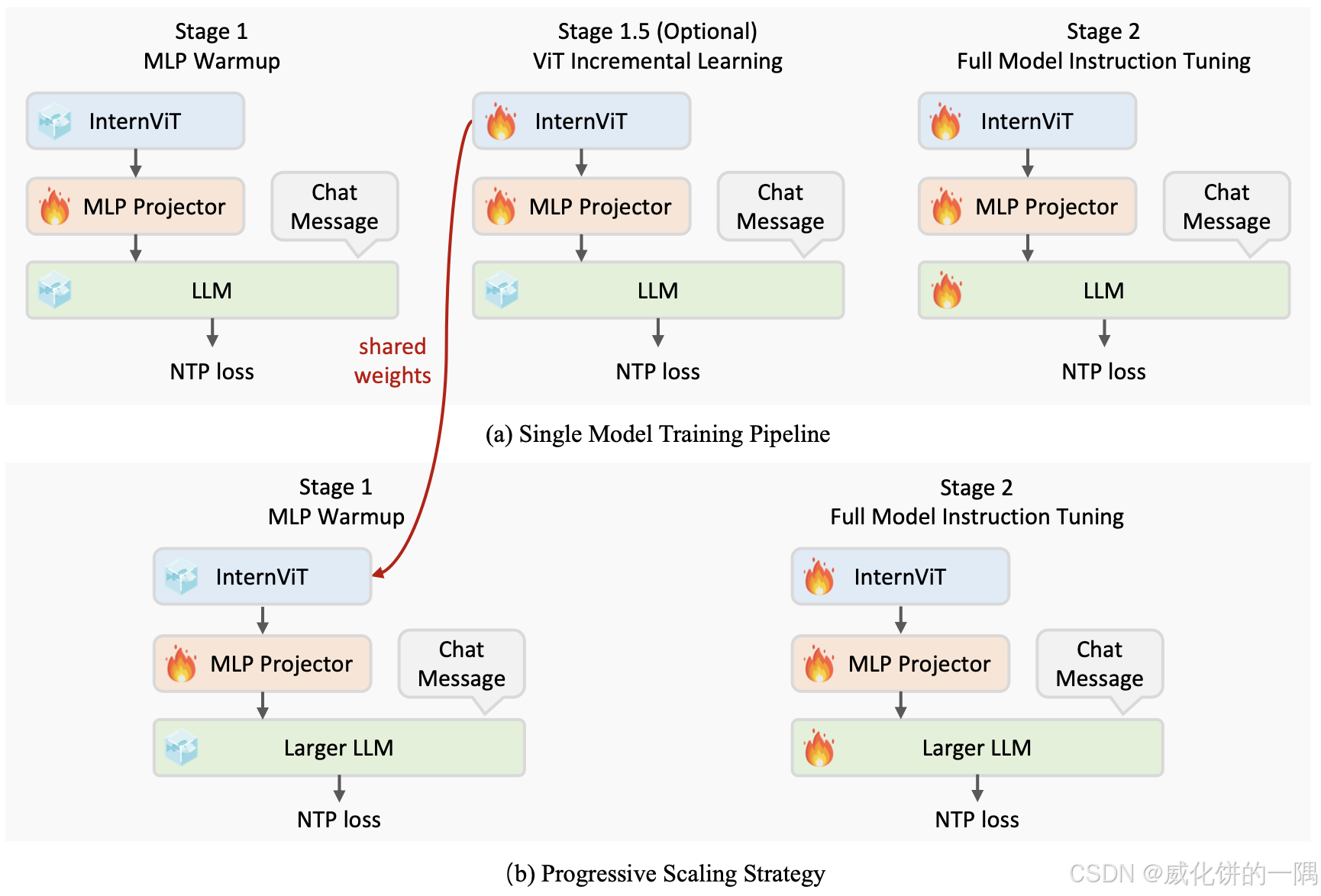
- 做了CoT的实验,看上去多模态多CoT提升不明显(4%,且是78B上),minicpm-o-8b里面也用了CoT达到70.0+,但是这样开销变大了,目前这样来实际业务使用可能不太能用


















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









