







在fpga实现cnn中最重要的模块部分-conv计算部分,可以称为是用fpga加速的根本。而计算最重要的关键则是如何充分利用fpga内的DSP,目前本人用的主要是ultrascale+,对应的dsp为DSP48e2。
实现conv的两种方式:
(1)并行方式,目前大多数fpga的conv计算都不是采用的此种方式,简单的说,如果要计算一个3*3的conv,则需要9个dsp,可以在一个时钟内计算完乘,第二个时钟得到乘加结果,由于一个网络往往有多个conv层,又有多种的kernel size,你不能把所有的size都并行化,那样dsp的数量将是巨大的。因此并行的方式一般不为大家所用,除非是针对特殊网络的卷积计算。
(2)串行方式,被大多数人所采用,计算一个3*3的conv,只需要一个dsp,需要9个时钟完成,第10个时钟完成加和操作,这种方式较为灵活,肯以根据指令完成不同的size计算。对dsp需求数量也较少,控制好并行度,也可以完成大量的卷积计算。
大多数人会针对串行方式进行大量的优化方式,本次主要对xilinx官方文档内对dsp48e2 关于int8方式的具体优化方式:
dsp48e2可以进行27*18的乘法计算,A*B+D*B=(A+D)*B
仔细看DSP48e2的结构,额可以发现在A和D之间有pre-add模块,由于是计算int8类型,则可以将A D的值提前相加在一起,则一个DSP可以同时计算两个两个INT8类型乘法,对DSP需求的数量可以减小1倍。
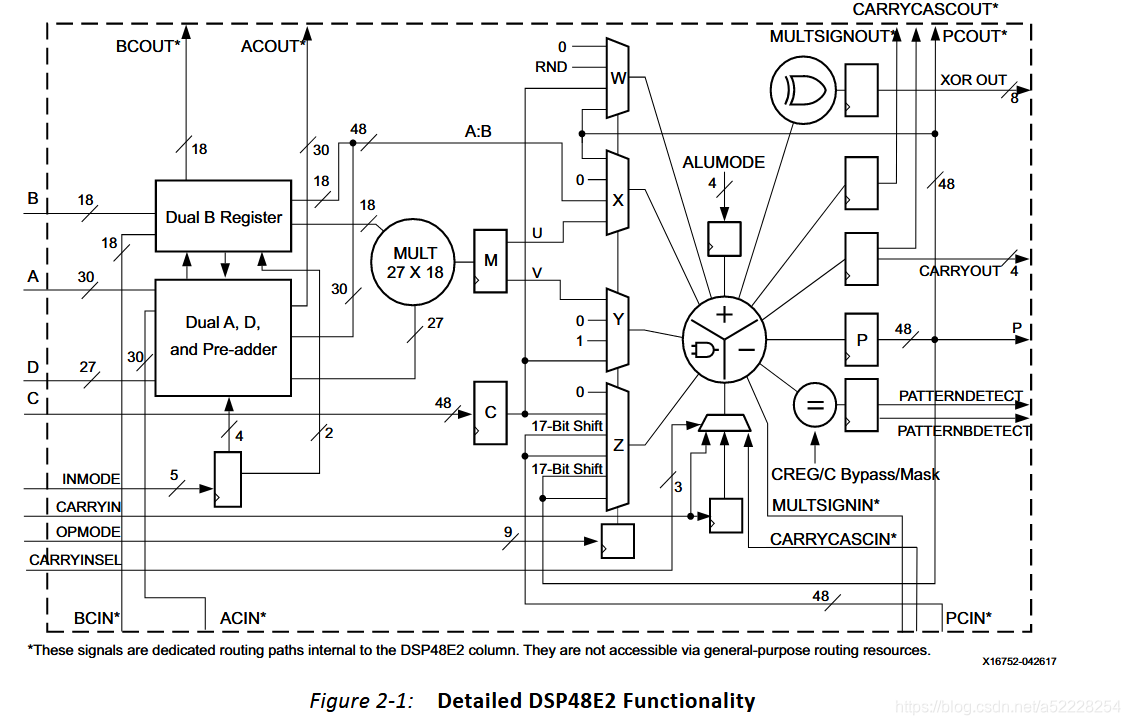

而计算完成后,可以发现两个结果中间还有2bit空余,则还可以充分利用DSp48e2的后加器,将两个dsp计算结构相加,可以保证7个dsp结果相加后,不会超过进位需求。后面多余的计算可以用lut进行搭建。充分利用此优化技术,可以对dsp和lut数量优化很多。
后面还可以利用fpga的兵乓操作,将DSp核心部分倍频,增加计算效能,进一步增加计算能力。
















 1648
1648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











