






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、环境
- 语言:Python3、Pytorch
- 开发环境
- 电脑系统:Windows 10
- 语言环境:Python 3.9.2
- 编译器:VS Code
- 显卡:3060
- CUDA版本:Release 11.4, V11.4.48
二、处理数据
1、准备好自己的数据
- 我使用了水果检测数据集
- 数据集的文件按一定结构放置
2、划分训练集验证集
# 添加命令行参数,用于指定XML文件的路径,默认为"Annotations"文件夹
parser.add_argument('--xml_path',default="自己的文件路径",type=str,help='input xml label path')
# 添加命令行参数,用于指定输出txt标签文件的路径,默认为'ImageSets/Main'文件夹
parser.add_argument('--txt_path',default='自己的文件路径' ,type=str,help='output txt label path')
运行split_train_val.py文件即可,注意需将上述代码的路径改为自己的路径
3、生成train.txt、test.txt、val.txt文件
# 定义类别列表,这里有两个类别,可以根据需要添加更多类别
classes = ['pineapple', 'snake fruit','dragon fruit','banana']
运行voc_label.py文件即可,注意需将上述代码的类别改为自己的类别
4、创建.yaml文件
train: F:/365data/Y2/train.txt
val: F:/365data/Y2/val.txt
nc: 4
names: ['pineapple', 'snake fruit', 'dragon fruit', 'banana']
运行ab.yaml文件,需将路径及类别都改为自己的
三、训练模型
python train.py --img900 --batch 2 --epoch 100 --data ab.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --device ‘0’
在终端中运行即可,需注意将高亮处文件换成自己的文件路径
四、结果
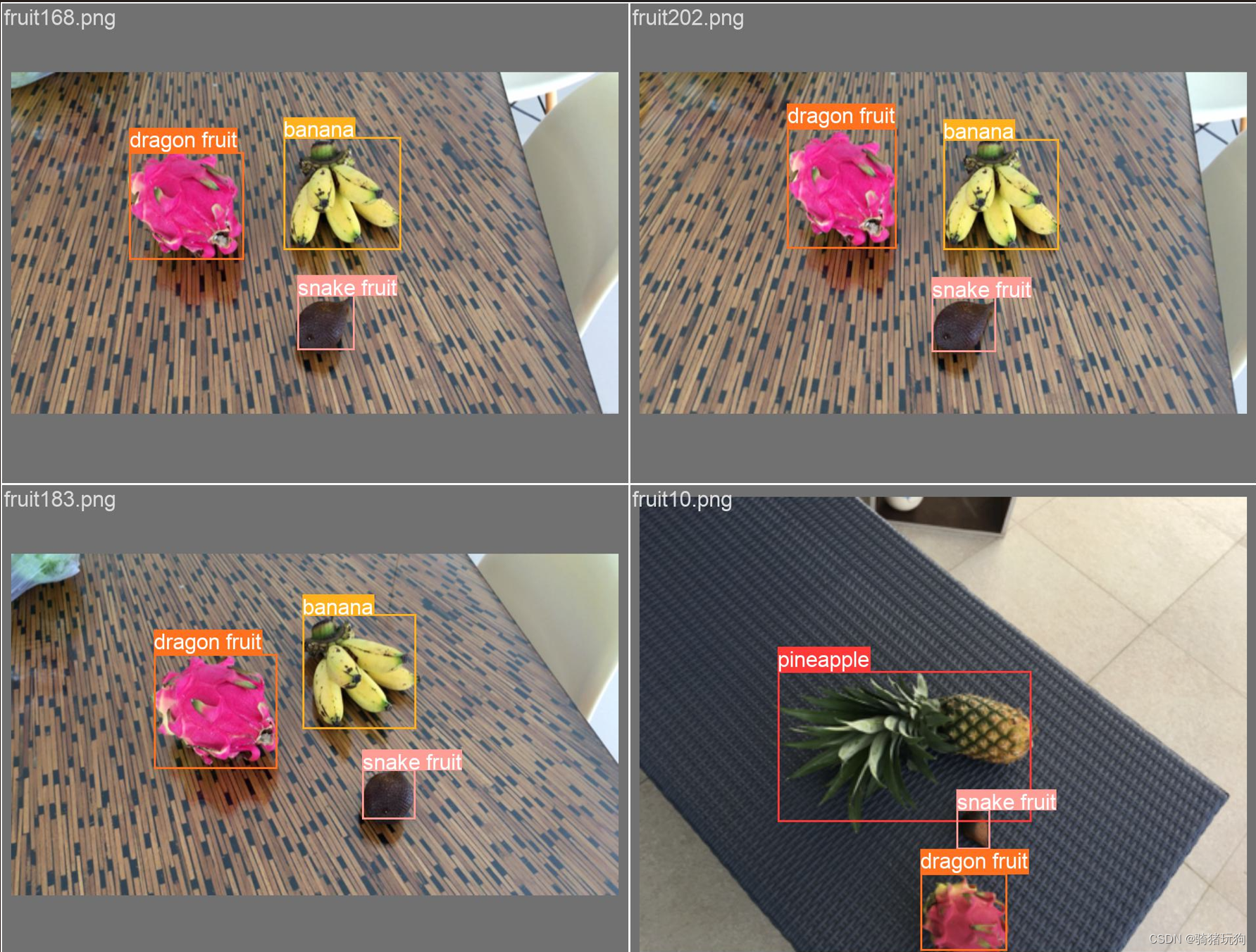
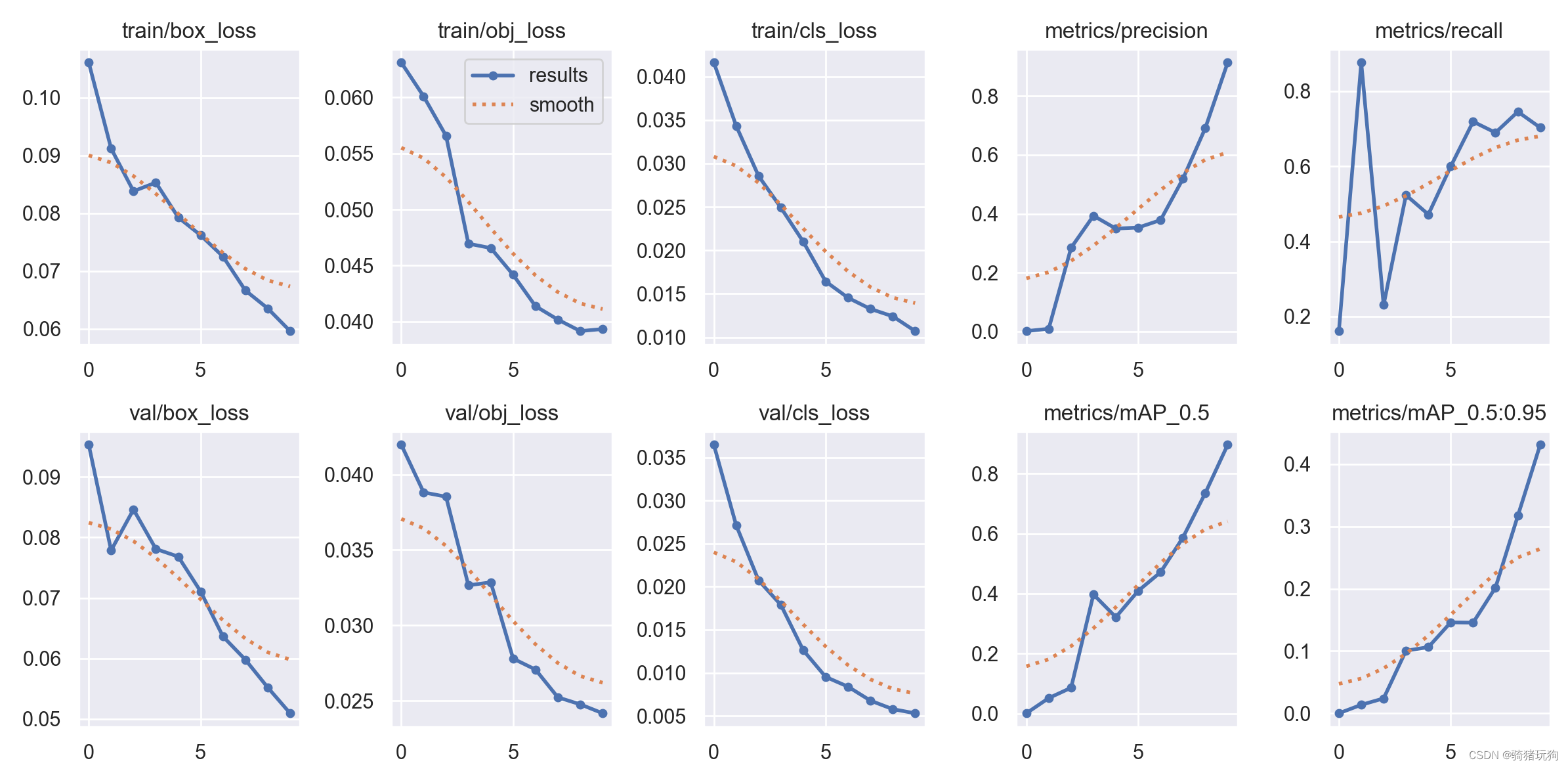
四、总结
- 本周任务使用与上周一样的模型,区别是训练自己的数据
- 重点在训练集验证集的划分,以及需修改代码中文件的路径















 1294
1294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









