







本学习笔记参考自Andrew的机器学习课程(点此打开), 内容来自视频以及其讲义, 部分内容引用网友的学习笔记,会特别注明
本集课程内容
1.生成学习算法
2.高斯判别分析(GDA)
3.判别学习与生成学习的对比
4.朴素贝叶斯
5.Laplace平滑
生成学习算法与判别学习算法
像前面的介绍的线性回归模型,逻辑回归,softmax回归等都是对P(y | x)进行建模得到的,这种方式叫做判别学习算法
滑;如果是直接对特征进行建模的,即对P(x | y)(包含P(y))这样的叫做生成学习算法。在对p(x|y)以及p(y)建模好了后,我们最终是要实现给定输入的特征x输出一些信息y,即p(y|x),用贝叶斯方法展开:
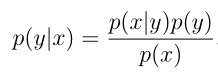
其中p(x)可以用全概率公式展开,但实际上是不需要计算p(x)的,我们要计算的是在给定输入特征x下哪一个y值取的概率最大,我们就认为特征x下的输出是那个y值,即
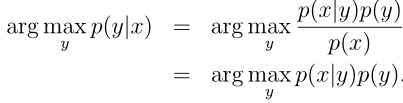
高斯判别分析
高斯判别分析是生成学习的算法的一个例子,它假设p(x|y)服从多元正态分布,它模型如下:
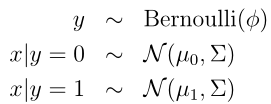
由此写成分布得到:

我们可以看到这个模型的参数是 φ, Σ, µ 0 和 µ 1,注意在判别学习算法中的这些参数都可以用θ来表示。同样的用最大化对数似然函数来求的这些参数,这里和判别学习算法不同的是,这里的似然函数取的是联合概率,判别学习算法是p(y|x)
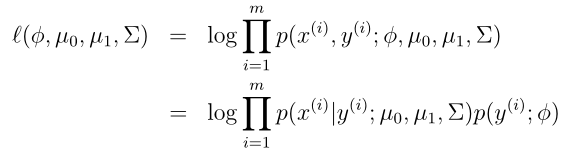
可以求解得到
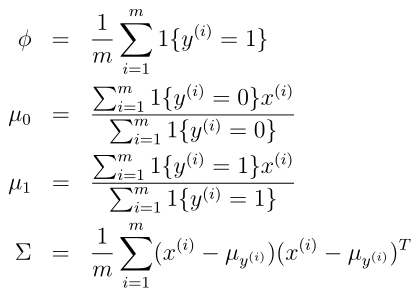
这样就得到模型的所有参数了,那么模型得到后,我们的目的是利用这个模型对输入特征x进行输出预测,预测的方式在开头的生成学习介绍里面写过了
判别学习与生成学习的对比
对于高斯判别分析模型,我们先 将p(y = 1|x;φ,µ 0 ,µ 1 ,Σ)看做是x的函数,这个式子可以被表示成如下形式:
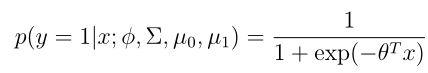
其中θ是关于φ,µ 0 ,µ 1 ,Σ的一个合适的函数,可以看到等式后面的形式就是逻辑函数的形式,这说明高斯判别分析和逻辑回归有相当的关联。上面的式子说明p(x|y)服从多元高斯分布,可以得到p(y|x)是逻辑函数,但是这里反过来并不成立,即p(y|x)是逻辑函数,并不能推出P(x|y)服从多元高斯分布。这表示高斯判别分析的假设是要强于逻辑回归的。当所有的假设都是合理的情况下,高斯判别分析是更好的一个模型,高斯判别分析需要更少的训练数据去"学习"得更好。当情况并不满足多元高斯分布时,且训练集比较大,逻辑回归会比高斯判别分析更好。
朴素贝叶斯算法
前面介绍的高斯判别分析的输入特征假设的是连续随机变量,这里朴素贝叶斯假设输入特征是离散随机变量。这里考虑一个例子,垃圾邮件过滤器。
训练集
这个例子的训练集是很多封邮件,每一封邮件被标记了是否为垃圾邮件
输入特征
输入特征来表示一封邮件,这里用到了一个词典,如果词典里面某个词语出现在了邮件里面,我们就用1标记,否则用0标记,这样得到描述一封邮件的输入特征如下:

这里输入特征的维度和词典大小是一致的,现在可以考虑对p(x|y)进行建模了,这里已经不能假设p(x | y)服从多元高斯分布了,因为输入特征是可以穷举的,并不是连续的随机变量。那如果用多项式分布对p(x|y)进行建模呢?我们先假设一个词典大小是5000, 那么穷举特征x的所有可能有2^5000种,用多项式分布必须有2^5000 -1个参数来表示前面的2^5000 -1特征的概率,显然参数的数量太过巨大了,不合适
朴素贝叶斯假设(NB assumption)
给定y的条件下假设输入特征的各个分量之间是相互独立,这个假设叫朴素贝叶斯假设,算法所得到的结果叫做贝叶斯分类器,更具体一点,这个假设可以举例为p(x2087|y) = p(x2087|x3000, y),或者也可以写成p(x2087, x300|y) = p(x2087|y)p(x3000|y),这里并不是x2087与x3000相互独立,而是在给定y下的条件独立。这样我们就可以得到:
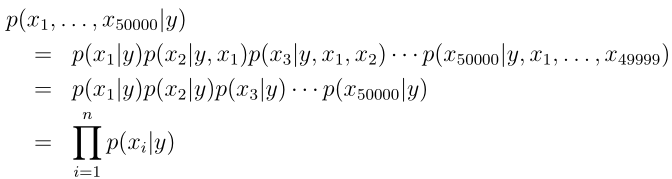
该模型的参数是 φ i|y=1 = p(x i = 1|y = 1), φ i|y=0 = p(x i = 1|y = 0), 和 φ y = p(y = 1)
同样假设样本有m个,用最大似然函数(仍然是联合概率)

这样朴素贝叶斯分类器模型建立好了,如果对于一个新的样本,要预测是否未垃圾邮件,则可以用下面:
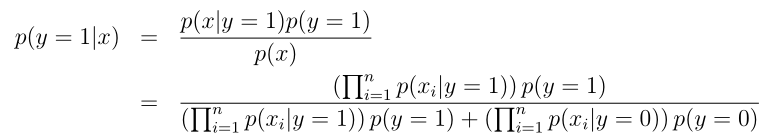
这里的xi只取0或1,如果xi有k种取值,则对p(xi|y)建模应该选择多项分布。另外很多情况下,都会把连续的随机变量离散化,比如将连续的变量以区间的形式表示为离散变量,再用朴素贝叶斯方法建模
Laplace平滑
问题引入
我们先来看一下最原始的朴素贝叶斯存在的问题,这里假设要判断一封新的邮件是否为垃圾邮件,这封邮件里面包含了一个词语nips,并假设在训练集合中从来没有出现过。该词语在x3500,那么在通过最大化似然函数获取参数φ35000|y时有如下计算式:
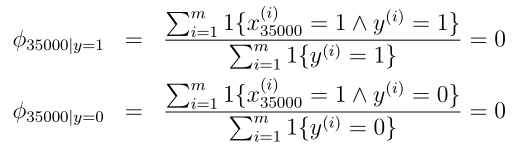
所以在对该新邮件进行预测时,按照上面的公式有:

这样就出现了问题,因为模型不知道怎么决策了。这个问题其实是比较普遍的,当在有限的集合里面计算出来的某些事件的概率为0,只是因为训练集合里面没有看见过它。但如果直接赋予0显然不合适。
Laplace算法
现假设随机变量z有k种取值,我们用 φ i = p(z = i)来表示其参数,并给定m组训练样本,通过最大似然函数可以得到参数计算如下:

这样如果训练样本中z的某些值未取到,相应的参数就可能得到0,Laplace用如下方式计算:

这样通过Laplace平滑处理后上面的问题就得到解决,计算如下:
















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









