










一、卷积的数学形式
1.1 卷积的连续形式
在泛函分析中,卷积(convolution)是透过两个函数 f 和 g生成第三个函数的一种数学算子,表征函数 f 与经过翻转和平移的 g 的乘积函数所围成的曲边梯形的面积。
函数f,g是定义域上的可测函数,两者的卷积记作f*g,即:

例如:
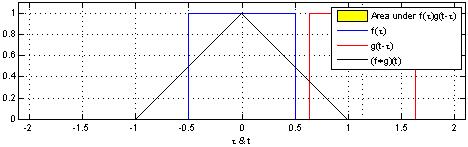
两个方波的卷积
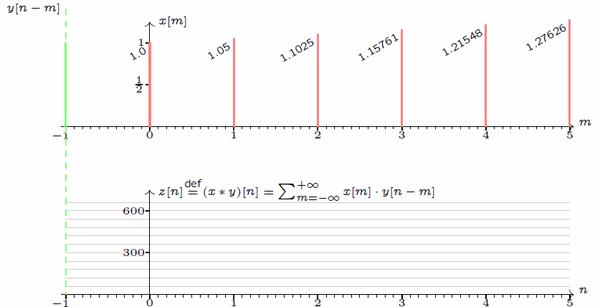
1.2. 卷积的离散形式
类比地很容易写出卷积的离散形式:

例如两个离散函数的卷积:
1.3. 离散卷积的矩阵形式
如果把上边卷积的离散形式的图解换成像素表示,那就是熟悉的神经网络中的Conv1d操作了:

卷积核kernel (w1,w2,w3) = (0,1,0), 步长stride = 1, padding = 1.
事实上对于Conv2d,也可以展平成多个类似向量点积之和的形式,那么自然地也就可以写成矩阵乘法的形式:
普通的卷积过程可以直观的理解为一个带颜色小窗户(卷积核)在原始的输入图像一步一步的挪动,来通过加权计算得到输出特征:

但是实际在计算机中计算的时候,并不是像这样一个位置一个位置的进行滑动计算,因为这样的效率太低了。计算机会将卷积核转换成等效的矩阵,将输入转换为向量。通过输入向量和卷积核矩阵的相乘获得输出向量。输出的向量经过整形便可得到我们的二维输出特征。具体的操作如下图所示。由于我们的3x3卷积核要在输入上不同的位置卷积4次,所以通过补零的方法将卷积核分别置于一个4x4矩阵的四个角落。这样我们的输入可以直接和这四个4x4的矩阵进行卷积,而舍去了滑动这一操作步骤:

补0得到不同位置的卷积核,舍去滑动操作

将feature map展平为向量,卷积核展平合并为等效矩阵

Conv2d的矩阵形式
二、卷积层 Conv
2.1 Conv1d(在由多个输入平面组成的输入信号上应用一维卷积)
一维卷积基本原理介绍[1]

- 图中输入的数据维度为8,过滤器(filter,kernel)维度为5,卷积后的数据维度为8-5+1
- 如果过滤器数量仍为1,输入数据的通道(channel)数量变为16,即输入维度为8×16。这里通道的概念相当与自然语言处理的嵌入(embedding),而该输入数据代表8个单词,其中每个单词的词向量维度大小为16。在这种情况下,过滤器维度变为5×16,而最终输出的维度仍为4
- 如果过滤器数量为n,输出维度为4×n
- 一维卷积常用于序列模型,自然语言处理
pytorch 函数
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
一维卷积层,输入的尺度是(N, C_in,L),输出尺度( N,C_out,L_out)的计算方式:

说明
bigotimes: 表示相关系数计算stride: 控制相关系数的计算步长dilation: 用于控制内核点之间的距离,详细描述在这里groups: 控制输入和输出之间的连接, group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
Parameters:
- in_channels(
int) – 输入信号的通道 - out_channels(
int) – 卷积产生的通道 - kerner_size(
intortuple) - 卷积核的尺寸 - stride(
intortuple,optional) - 卷积步长 - padding (
intortuple,optional)- 输入的每一条边补充0的层数 - dilation(
intortuple, `optional``) – 卷积核元素之间的间距 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数 - bias(
bool,optional) - 如果bias=True,添加偏置
shape:
输入: (N,C_in,L_in)
输出: (N,C_out,L_out)
输入输出的计算方式:
变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels, kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channel)
例子:
m = nn.Conv1d(3,2,2)
input = torch.randn(4,3,5)
print(input)
output = m(input)
print(output)结果如下:

从图中我们看出我们输入一个4(批大小)*3(输入通道数)*5(信号序列长度)的矩阵,我们通过Conv1d得到4(批大小)*2(输出通道数)*4(信号序列长度)(5-2*1+1)
2.2 Conv2d(在由多个输入平面组成的输入信号上应用二维卷积)
二维卷积基本原理介绍[1]

- 图中的输入的数据维度为14×14,过滤器大小为5×5,二者做卷积,输出的数据维度为10×10(14−5+1=10)。如果你对卷积维度的计算不清楚,可以参考
- 上述内容没有引入channel的概念,也可以说channel的数量为1。如果将二维卷积中输入的channel的数量变为3,即输入的数据维度变为(14×14×3)。由于卷积操作中过滤器的channel数量必须与输入数据的channel数量相同,过滤器大小也变为5×5×3。在卷积的过程中,过滤器与数据在channel方向分别卷积,之后将卷积后的数值相加,即执行10×10次3个数值相加的操作,最终输出的数据维度为10×10。
- 以上都是在过滤器数量为1的情况下所进行的讨论。如果将过滤器的数量增加至16,即16个大小为10×10×3的过滤器,最终输出的数据维度就变为10×10×16。可以理解为分别执行每个过滤器的卷积操作,最后将每个卷积的输出在第三个维度(channel 维度)上进行拼接。
- 二维卷积常用于计算机视觉、图像处理领域。
pytorch函数
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
二维卷积层, 输入的尺度是(N, C_in,H,W),输出尺度(N,C_out,H_out,W_out)的计算方式:

说明bigotimes: 表示二维的相关系数计算 stride: 控制相关系数的计算步长dilation: 用于控制内核点之间的距离,详细描述在这里groups: 控制输入和输出之间的连接: group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
参数kernel_size,stride,padding,dilation也可以是一个int的数据,此时卷积height和width值相同;也可以是一个tuple数组,tuple的第一维度表示height的数值,tuple的第二维度表示width的数值
Parameters:
- in_channels(
int) – 输入信号的通道 - out_channels(
int) – 卷积产生的通道 - kerner_size(
intortuple) - 卷积核的尺寸 - stride(
intortuple,optional) - 卷积步长 - padding(
intortuple,optional) - 输入的每一条边补充0的层数 - dilation(
intortuple,optional) – 卷积核元素之间的间距 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数 - bias(
bool,optional) - 如果bias=True,添加偏置
shape:
input: (N,C_in,H_in,W_in)
output: (N,C_out,H_out,W_out)
变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels,kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channel)
官方例子
m = nn.Conv2d(16, 33, 3, stride=2)
# non-square kernels and unequal stride and with padding
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
# non-square kernels and unequal stride and with padding and dilation
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
input = autograd.Variable(torch.randn(20, 16, 50, 100))
output = m(input)2.3 Conv3d(在由多个输入平面组成的输入信号上应用三维卷积)
三维卷积基本原理介绍[1]

- 假设输入数据的大小为a1×a2×a3,channel数为c,过滤器大小为f×f×f,即过滤器维度为f×f×f×c(一般不写channel的维度),过滤器数量为n。
- 基于上述情况,三维卷积最终的输出为(a1−f+1)×(a2−f+1)×(a3−f+1)×n。该公式对于一维卷积、二维卷积仍然有效,只有去掉不相干的输入数据维度就行。
- 三维卷积常用于医学领域(CT影响),视频处理领域(检测动作及人物行为)
pytorch函数
class torch.nn.Conv3d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
三维卷积层, 输入的尺度是(N, C_in,D,H,W),输出尺度(N,C_out,D_out,H_out,W_out)的计算方式:
说明bigotimes: 表示二维的相关系数计算 stride: 控制相关系数的计算步长dilation: 用于控制内核点之间的距离,详细描述在这里groups: 控制输入和输出之间的连接: group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
参数kernel_size,stride,padding,dilation可以是一个int的数据 - 卷积height和width值相同,也可以是一个有三个int数据的tuple数组,tuple的第一维度表示depth的数值,tuple的第二维度表示height的数值,tuple的第三维度表示width的数值
Parameters:
- in_channels(
int) – 输入信号的通道 - out_channels(
int) – 卷积产生的通道 - kernel_size(
intortuple) - 卷积核的尺寸 - stride(
intortuple,optional) - 卷积步长 - padding(
intortuple,optional) - 输入的每一条边补充0的层数 - dilation(
intortuple,optional) – 卷积核元素之间的间距 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数 - bias(
bool,optional) - 如果bias=True,添加偏置
shape:input: (N,C_in,D_in,H_in,W_in)output: (N,C_out,D_out,H_out,W_out)
变量:
- weight(
tensor) - 卷积的权重,shape是(out_channels,in_channels,kernel_size)` - bias(
tensor) - 卷积的偏置系数,shape是(out_channel)
官方例子
# With square kernels and equal stride
m = nn.Conv3d(16, 33, 3, stride=2)
# non-square kernels and unequal stride and with padding
m = nn.Conv3d(16, 33, (3, 5, 2), stride=(2, 1, 1), padding=(4, 2, 0))
input = autograd.Variable(torch.randn(20, 16, 10, 50, 100))
output = m(input)三、转置卷积(反卷积)推理
1、普通的卷积计算如下图

Y中的每一个元素y,都是由2x2卷积核分别和X中对应的4个元素计算而来。所以说,卷积操作是多对一的运算。
2、转置卷积,绝不是通过Y和卷积核逆向求出原始的X。
3、转置卷积,也是一种特殊的卷积计算方式,它的目的是根据卷积相关参数,上采样,计算出一个和X一样大小的特侦图。(仅仅是一样大小而已)
4、图示演示下:
A:目的
- encoding时,输入是3x3,步长=1,padding=0,卷积核是2x2,输出是2x2;
- 基于此,通过转置卷积把2x2作为新的输入,能够输出3x3的大小特征图,如下所示:

B、计算过程
- encoding卷积计算是4对1,decoding卷积的计算是1对4,
- 所以每个y(y11/y12/y21/y22)都会分别和2x2卷积核k`里的元素计算,输出4个值,达到1变4的效果。
- 在decoding中每个y计算后,上下/左右都是移动一步(这个步子和步长没有任何关系)
所以整个计算过程如下所示:

合并之后,得到下图

以上其实就是转置卷积计算真实计算原理和过程了。
那么如果遇到encoding中存在padding>0或者stride>1,怎么处理?
特别强调:
1、Padding:标准准卷积里的padding是为了放大输出;转置卷积是为了缩小输出。为什么会这样?简单说是padding让原始输入变得虚胖,转置卷积就要对其瘦个身。举例:转置卷积的 padding 设置为 1 时,转置卷积的输出中将删除第一和最后的行与列。
- 正常卷积的padding用法:input(输入) -> padding(补零放大) -> conv(标准卷积) -> output(输出)
- 转置卷积的padding用法:input(输入) -> deconv(转置卷积) -> depadding(删除行列-缩小) -> output
比如1:标准卷积如果输入是3x3,padding=0,stride=1,kernel=3x3,那么输出的大小是[(3-3+2*0)/1+1]=1x1
那么对1x1做转置卷积,按照上面计算方式,输出的大小是3x3,可以看到输出和标准卷积的输入是一样大尺寸,参考图如下:

比如2:标准卷积如果输入是3x3,padding=1,stride=1,kernel=3x3,那么输出的大小是[(3-3+2*1)/1+1]=3x3
那么3x3转置卷积后,按照上图的计算方式,可以发现输出的大小是5x5,明显大于原始的3x3输入,基于padding=1,那么删除5x5的第一行第一列,最后一行最后一列,得到3x3。计算方式参考下图:

2、stride。上面的手动计算方式,可以清楚的看到转置卷积的每次运算都是按照步长=1进行一定的。在标准卷积中stride>1,表示是跳着计算的,比如说(x1,x2)对应y1,(x3,x4)对应y2,而当要逆向计算的时候,y1对多(x1`,x2`),y2也对多(x3`,x4`),为了不交叉,或者说,应对的视野更广一些,需要在y1,y2之间补一些0。这样,才能对的上转置卷积中的永远都是步长1的移动。
具体补多少0:在转置卷积的输入的特征图的行与列之间补 stride-1 个行与列的零。
比如:stride=2,则补零后的情况如下图

基于补零后的样子,再去做上图的手动计算。
四、转置卷积(反卷积)pytorch
4.1 ConvTranspose1d
class torch.nn.ConvTranspose1d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True)
1维的解卷积操作(transposed convolution operator,注意改视作操作可视作解卷积操作,但并不是真正的解卷积操作) 该模块可以看作是Conv1d相对于其输入的梯度,有时(但不正确地)被称为解卷积操作。
注意
由于内核的大小,输入的最后的一些列的数据可能会丢失。因为输入和输出是不是完全的互相关。因此,用户可以进行适当的填充(padding操作)。
参数
- in_channels(
int) – 输入信号的通道数 - out_channels(
int) – 卷积产生的通道 - kernel_size(
intortuple) - 卷积核的大小 - stride(
intortuple,optional) - 卷积步长 - padding(
intortuple,optional) - 输入的每一条边补充0的层数 - output_padding(
intortuple,optional) - 输出的每一条边补充0的层数 - dilation(
intortuple,optional) – 卷积核元素之间的间距 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数 - bias(
bool,optional) - 如果bias=True,添加偏置
shape:
输入: (N,C_in,L_in)
输出: (N,C_out,L_out)
变量:
- weight(tensor) - 卷积的权重,大小是(in_channels, in_channels,kernel_size)
- bias(tensor) - 卷积的偏置系数,大小是(out_channel)
4.2 ConvTranspose2d
class torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True)
2维的转置卷积操作(transposed convolution operator,注意改视作操作可视作解卷积操作,但并不是真正的解卷积操作) 该模块可以看作是Conv2d相对于其输入的梯度,有时(但不正确地)被称为解卷积操作。
说明
stride: 控制相关系数的计算步长dilation: 用于控制内核点之间的距离,详细描述在这里groups: 控制输入和输出之间的连接: group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
参数kernel_size,stride,padding,dilation数据类型: 可以是一个int类型的数据,此时卷积height和width值相同; 也可以是一个tuple数组(包含来两个int类型的数据),第一个int数据表示height的数值,第二个int类型的数据表示width的数值
注意
由于内核的大小,输入的最后的一些列的数据可能会丢失。因为输入和输出是不是完全的互相关。因此,用户可以进行适当的填充(padding操作)。
参数:
- in_channels(
int) – 输入信号的通道数 - out_channels(
int) – 卷积产生的通道数 - kerner_size(
intortuple) - 卷积核的大小 - stride(
intortuple,optional) - 卷积步长 - padding(
intortuple,optional) - 输入的每一条边补充0的层数 - output_padding(
intortuple,optional) - 输出的每一条边补充0的层数 - dilation(
intortuple,optional) – 卷积核元素之间的间距 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数 - bias(
bool,optional) - 如果bias=True,添加偏置
shape:
输入: (N,C_in,H_in,W_in)
输出: (N,C_out,H_out,W_out)
变量:
- weight(tensor) - 卷积的权重,大小是(in_channels, in_channels,kernel_size)
- bias(tensor) - 卷积的偏置系数,大小是(out_channel)
>>> # With square kernels and equal stride
>>> m = nn.ConvTranspose2d(16, 33, 3, stride=2)
>>> # non-square kernels and unequal stride and with padding
>>> m = nn.ConvTranspose2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
>>> input = autograd.Variable(torch.randn(20, 16, 50, 100))
>>> output = m(input)
>>> # exact output size can be also specified as an argument
>>> input = autograd.Variable(torch.randn(1, 16, 12, 12))
>>> downsample = nn.Conv2d(16, 16, 3, stride=2, padding=1)
>>> upsample = nn.ConvTranspose2d(16, 16, 3, stride=2, padding=1)
>>> h = downsample(input)
>>> h.size()
torch.Size([1, 16, 6, 6])
>>> output = upsample(h, output_size=input.size())
>>> output.size()
torch.Size([1, 16, 12, 12])4.3 ConvTranspose3d
torch.nn.ConvTranspose3d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True)
3维的转置卷积操作(transposed convolution operator,注意改视作操作可视作解卷积操作,但并不是真正的解卷积操作) 转置卷积操作将每个输入值和一个可学习权重的卷积核相乘,输出所有输入通道的求和
该模块可以看作是Conv3d相对于其输入的梯度,有时(但不正确地)被称为解卷积操作。
说明
stride: 控制相关系数的计算步长dilation: 用于控制内核点之间的距离,详细描述在这里groups: 控制输入和输出之间的连接: group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
参数kernel\_size,stride, padding,dilation数据类型: 一个int类型的数据,此时卷积height和width值相同; 也可以是一个tuple数组(包含来两个int类型的数据),第一个int数据表示height的数值,tuple的第二个int类型的数据表示width的数值
注意
由于内核的大小,输入的最后的一些列的数据可能会丢失。因为输入和输出是不是完全的互相关。因此,用户可以进行适当的填充(padding操作)。
参数:
- in_channels(
int) – 输入信号的通道数 - out_channels(
int) – 卷积产生的通道数 - kernel_size(
intortuple) - 卷积核的大小 - stride(
intortuple,optional) - 卷积步长 - padding(
intortuple,optional) - 输入的每一条边补充0的层数 - output_padding(
intortuple,optional) - 输出的每一条边补充0的层数 - dilation(
intortuple,optional) – 卷积核元素之间的间距 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数 - bias(
bool,optional) - 如果bias=True,添加偏置
shape:
输入: (N,C_in,H_in,W_in)
输出: (N,C_out,H_out,W_out)
变量:
- weight(tensor) - 卷积的权重,大小是(in_channels, in_channels,kernel_size)
- bias(tensor) - 卷积的偏置系数,大小是(out_channel)
>>> # With square kernels and equal stride
>>> m = nn.ConvTranspose3d(16, 33, 3, stride=2)
>>> # non-square kernels and unequal stride and with padding
>>> m = nn.ConvTranspose3d(16, 33, (3, 5, 2), stride=(2, 1, 1), padding=(0, 4, 2))
>>> input = torch.randn(20, 16, 10, 50, 100)
>>> output = m(input)五、延迟卷积Lazy Conv
5.1 nn.LazyConv1d
torch.nn.LazyConv1d(out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
LazyConv1d 本质上就是 Conv1d,只不过是使用了延迟初始化的卷积,也就是利用 input.size(1) = Conv1d的参数in_channels 进行延迟初始化。
参数:
out_channels:类型为 int,表示经过延迟卷积后的输出通道数;
kernel_size:类型为 int、tuple of one int,控制卷积核的大小;
stride:可选参数,类型为 int、tuple of one int,控制卷积的步长,默认为 stride=1;
padding:可选参数,类型为 int、tuple of one int,控制对输入两侧进行填充点的数量,默认为 stride=0 表示不进行填充;
padding_mode:可选参数,类型为 string,控制填充模式 zeros-零填充, reflect-镜像填充, replicate-复制填充, circular,默认为 padding_mode=zeros;
dilation:可选参数,类型为 int、tuple of one int,控制卷积核元素的间距,默认 dilation=1 就是标准卷积;
groups:可选参数,类型为 int,控制从输入到输出之间的连接数,该参数必须满足能够整除input_channels & output_channels,默认为 groups=1;
bias:可选参数,类型为 bool,若 bias=True,则会添加可学习的偏差参数,默认值为 bias=True。
5.2 nn.LazyConv2d
torch.nn.LazyConv2d(out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
LazyConv2d 是使用了延迟初始化的 Conv2d,也就是利用 input.size(1) = Conv2d 的参数 in_channels 进行延迟初始化。
参数:
out_channels:类型为 int,表示经过延迟卷积后的输出通道数;
kernel_size:类型为 int、tuple of two ints,控制卷积核的大小;
stride:可选参数,类型为 int、tuple of two ints,控制卷积的步长,默认为 stride=1;
padding:可选参数,类型为 int、tuple of two ints,控制对输入两侧进行填充点的数量,默认为 stride=0 表示不进行填充;
padding_mode:可选参数,类型为 string,控制填充模式 zeros-零填充, reflect-镜像填充, replicate-复制填充, circular,默认为 padding_mode=zeros;
dilation:可选参数,类型为 int、tuple of two ints,控制卷积核元素的间距,默认 dilation=1 就是标准卷积;
groups:可选参数,类型为 int,控制从输入到输出之间的连接数,该参数必须满足能够整除input_channels & output_channels,默认为 groups=1;
bias:可选参数,类型为 bool,若 bias=True,则会添加可学习的偏差参数,默认值为 bias=True。
5.3 nn.LazyConv3d
torch.nn.LazyConv3d(out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
LazyConv3d 是使用了延迟初始化的 Conv3d,即利用 input.size(1) = Conv3d 的参数 in_channels 进行延迟初始化。
参数:
out_channels:类型为 int,表示经过延迟卷积后的输出通道数;
kernel_size:类型为 int、tuple of three ints,控制卷积核的大小;
stride:可选参数,类型为 int、tuple of three ints,控制卷积的步长,默认为 stride=1;
padding:可选参数,类型为 int、tuple of three ints,控制对输入两侧进行填充点的数量,默认为 stride=0 表示不进行填充;
padding_mode:可选参数,类型为 string,控制填充模式 zeros-零填充, reflect-镜像填充, replicate-复制填充, circular,默认为 padding_mode=zeros;
dilation:可选参数,类型为 int、tuple of three ints,控制卷积核元素的间距,默认 dilation=1 就是标准卷积;
groups:可选参数,类型为 int,控制从输入到输出之间的连接数,该参数必须满足能够整除input_channels & output_channels,默认为 groups=1;
bias:可选参数,类型为 bool,若 bias=True,则会添加可学习的偏差参数,默认值为 bias=True。
六、延迟转置卷积-LazyConvTransposed
6.1 nn.LazyConvTransposed1d
torch.nn.LazyConvTranspose1d(out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros')
torch.nn.LazyConvTranspose1d 本质上是使用了延迟初始化 ConvTranspose1d,利用 input.size(1) = ConvTranspose1d 的参数 in_channels 进行延迟初始化。
参数:
out_channels:类型为 int,表示输出通道数;
kernel_size:类型为 int、tuple of one int,表示卷积核的大小;
stride:可选参数,类型为 int、tuple of one int,控制进行卷积的步长,默认 stride=1;
padding:可选参数,类型为 int、tuple of one int,可对输入的两侧进行 dilation * (kernel_size-1) - padding 数量的零填充,默认 padding=0。之所以进行固定熟练的填充点数,是为了遵循当 Conv1d 和 ConvTranspose1d 使用相同的参数初始化时,它们在输入和输出形状方面互为倒数 。
output_padding:可选参数,类型为 int、tuple of one int,控制添加到输出形状一侧的附加尺寸,默认为 output_padding=0。
padding_mode:可选参数,类型为 string,控制填充模式 zeros-零填充, reflect-镜像填充, replicate-复制填充, circular,默认为 padding_mode=zeros;
dilation:可选参数,类型为 int、tuple,控制卷积核元素的间距,默认 dilation=1 就是标准卷积,更改该参数的话标准卷积就变成了 膨胀卷积(空洞卷积),参考 [1];
groups:可选参数,类型为 int,控制从输入到输出之间的连接数,该参数必须满足能够整除input_channels & output_channels,默认为 groups=1;
bias:可选参数,类型为 bool,若 bias=True,则会添加可学习的偏差参数,默认值为 bias=True。
6.2 nn.LazyConvTransposed2d
torch.nn.LazyConvTranspose2d(out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros')')
LazyConvTransposed2d 是使用了延迟初始化的 ConvTransposed2d,也就是利用 input.size(1) = ConvTransposed2d 的参数 in_channels 进行延迟初始化。
参数:
out_channels:类型为 int,表示输出通道数;
kernel_size:类型为 int、tuple of two ints,表示卷积核的大小;
stride:可选参数,类型为 int、tuple of two ints,控制进行卷积的步长,默认 stride=1;
padding:可选参数,类型为 int、tuple of two ints,可对输入的两侧进行 dilation * (kernel_size-1) - padding 数量的零填充,默认 padding=0。之所以进行固定熟练的填充点数,是为了遵循当 Conv1d 和 ConvTranspose1d 使用相同的参数初始化时,它们在输入和输出形状方面互为倒数 。
output_padding:可选参数,类型为 int、tuple of two ints,控制添加到输出形状一侧的附加尺寸,默认为 output_padding=0。
padding_mode:可选参数,类型为 string,控制填充模式 zeros-零填充, reflect-镜像填充, replicate-复制填充, circular,默认为 padding_mode=zeros;
dilation:可选参数,类型为 int、tuple of two ints,控制卷积核元素的间距,默认 dilation=1 就是标准卷积,更改该参数的话标准卷积就变成了 膨胀卷积(空洞卷积),参考 [1];
groups:可选参数,类型为 int、tuple of two ints,控制从输入到输出之间的连接数,该参数必须满足能够整除input_channels & output_channels,默认为 groups=1;
bias:可选参数,类型为 bool,若 bias=True,则会添加可学习的偏差参数,默认值为 bias=True。
6.3 nn.LazyConvTransposed3d
torch.nn.LazyConvTranspose3d(out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros')
LazyConvTransposed3d 是使用了延迟初始化的 ConvTransposed3d,也就是利用 input.size(1) = ConvTransposed3d 的参数 in_channels 进行延迟初始化。
参数:
out_channels:类型为 int,表示输出通道数;
kernel_size:类型为 int、tuple of three ints,表示卷积核的大小;
stride:可选参数,类型为 int、tuple of three ints,控制进行卷积的步长,默认 stride=1;
padding:可选参数,类型为 int、tuple of three ints,可对输入的两侧进行 dilation * (kernel_size-1) - padding 数量的零填充,默认 padding=0。之所以进行固定熟练的填充点数,是为了遵循当 Conv1d 和 ConvTranspose1d 使用相同的参数初始化时,它们在输入和输出形状方面互为倒数 。
output_padding:可选参数,类型为 int、tuple of three ints,控制添加到输出形状一侧的附加尺寸,默认为 output_padding=0。
padding_mode:可选参数,类型为 string,控制填充模式 zeros-零填充, reflect-镜像填充, replicate-复制填充, circular,默认为 padding_mode=zeros;
dilation:可选参数,类型为 int、tuple of two ints,控制卷积核元素的间距,默认 dilation=1 就是标准卷积,更改该参数的话标准卷积就变成了 膨胀卷积(空洞卷积),参考 [1];
groups:可选参数,类型为 int、tuple of three ints,控制从输入到输出之间的连接数,该参数必须满足能够整除input_channels & output_channels,默认为 groups=1;
bias:可选参数,类型为 bool,若 bias=True,则会添加可学习的偏差参数,默认值为 bias=True。
七、膨胀卷积
在深度学习中,我们会碰到卷积的概念,我们知道卷积简单来理解就是累乘和累加,普通的卷积我们在此不做赘述,大家可以翻看相关书籍很好的理解。
最近在做项目过程中,碰到Pytorch中使用膨胀卷积的情况,想要的输入输出是图像经过四层膨胀卷积后图像的宽高尺寸不发生变化。
开始我的思路是padding='SAME'结合strides=1来实现输入输出尺寸不变,试列好多次还是有问题,报了张量错误的提示,想了好久也没找到解决方法,上网搜了下,有些人的博客说经过膨胀卷积之后图像的尺寸不发生变化,有些人又说发生变化,甚至还给出了公式,按着他们的方法修改后还是有问题,报的错误还是没有变。一时不知道怎样解决,网上关于膨胀卷积输出尺寸的大小相关的知识也很少。
终于......,经过自己的研究,发现了问题所在。好啦!我们先从膨胀卷积的概念开始。
7.1、膨胀卷积的概念
Dilated Convolutions,翻译为扩张卷积或空洞卷积。扩张卷积与普通的卷积相比,除了卷积核的大小以外,还有一个扩张率(dilation rate)参数,主要用来表示扩张的大小。扩张卷积与普通卷积的相同点在于,卷积核的大小是一样的,在神经网络中即参数数量不变,区别在于扩张卷积具有更大的感受野。感受野是卷积核在图像上看到的大小,例如5x5的卷积核的感受野大小为25。
7.2、示意图

a.普通卷积,dilation=1,感受野为3x3=9
b.膨胀卷积,dilation=2,感受野为7x7=49
c.膨胀卷积,dilation=4,感受野为16x16 = 256
7.3、感受野的概念
在卷积神经网络中,感受野的定义是 卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小

重点来啦
卷积核经过膨胀后实际参与运算的卷积大小计算公式:
膨胀后的卷积核尺寸 = 膨胀系数 × (原始卷积核尺寸-1)+ 1
例如对于输入是19 x 19(暂且不考虑图像通道数)大小的图像做膨胀卷积,要使输出的图像大小保持不变,即就是仍然为19 x 19,我们要怎样实现呢?
我们的代码是基于pytorch实现的,它的卷积参数中没有padding='SAME‘的选项,padding的可取值为0,1,2,3等等的值。它的计算方式和tensorflow中的padding='VALID'的计算方式一样。
Output=(W-F+2P)/S+1
我们取strides=1,这里的原始卷积核为3 x 3大小,dilation=6,我们可以计算出膨胀后的卷积核大小为6(3-1)+1=13
带入公式可以求得:
(19-13+2*p)/1+1=19,要使这个式子成立,可以反推出padding=6。
这样一来,就可以使得输入输出的尺寸保持不变。达到了我们想要的效果。
7.4、膨胀卷积的优点
膨胀卷积在保持参数个数不变的情况下增大了卷积核的感受野
7.5、应用领域
图像修复,图像分割,语音合成。
八、其他
8.1 nn.Unfold
该方法 torch.nn.Unfold(kernel_size, dilation=1, padding=0, stride=1) 可以从批量输入张量中提取滑动局部块。
8.2 nn.Fold
与上面的方法相反的是 torch.nn.Fold(output_size, kernel_size, dilation=1, padding=0, stride=1) 可以将一组滑动局部块组合成一个大的组合张量。
九、CNN基础知识
CNN(Convolution Neural Network,卷积神经网络)主要用于图像分类问题
- 但CNN不仅可以处理图像,还可以处理音频、文本、游戏等,只要数据能变成图像格式就可以
- 若数据把两列互换,信息量不受影响,则表示该类数据不能用CNN处理
结构:卷积层 —> 池化层 —> 卷积层 —> 池化层 —> 全连接层 —> 输出层【卷积、池化可以堆积很多层】
Having more layers helps the CNN to learn features in a hierarchical manner. For example the first layer learns various edge orientations in the image, the second layer learns basic shapes (circles, triangles, etc.) and the third layer learns more advance shapes (e.g shape of an eye, shape of a nose), and so on. This delivers better performance
- 卷积层(Convolution):提取图像的底层特征,将原图中符合卷积核特征的特征提取出来(卷积核特征是由网络自己学习出来的)
- 池化层/降采样层/下采样层(Pooling/Subsampling):降低feature map的维度,防止过拟合
- 全连接层/密集连接层(Fully Connected/Dense Layer):将池化层的结果拉平(flatten)成一个长向量,汇总之前卷积层和池化层得到的底层的信息和特征
- 输出层(Output):全连接+激活(二分类用sigmoid;多分类用softmax归一化)

历史模型:LeNet-5(7层)—> AlexNet —> GoogLeNet/VGG —> ResNet —> ...
1、卷积层

Convolution operation outputs a high value for a given position if the convolution feature is present in that location, else outputs a low value
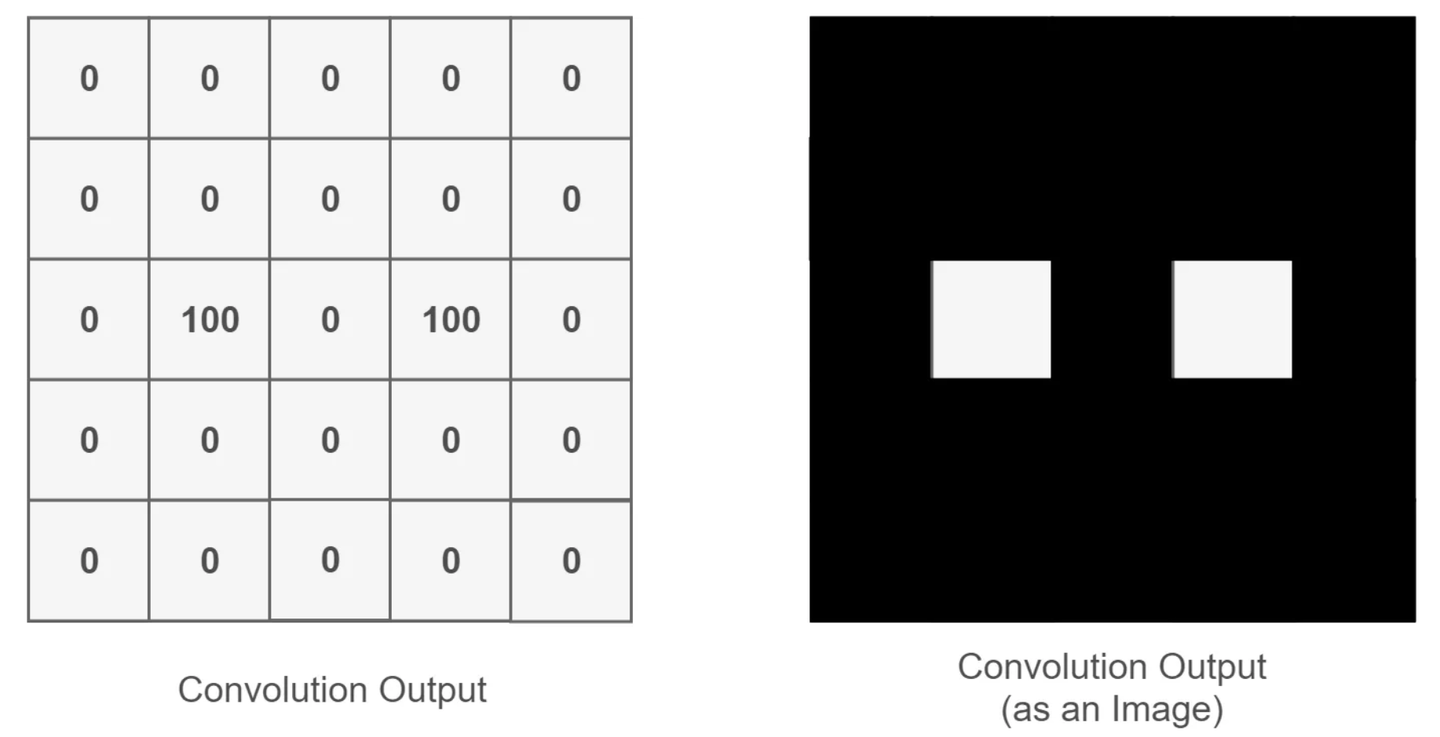
0 for black,100 for white
卷积核(kernel)/ 特征提取器(filter):一般都是原图里包含的部分特征。不需人工设置,通过反向传播、梯度下降,模型自己找到(若图像是多通道的,卷积核也是多通道)
感受野(receptive field):卷积核在原图上光顾到的区域
padding:防止边缘信息被丢失或忽略。为了识别边缘特征,通常在外圈补0(即zero padding)
-
- same padding:保证输入、输出特征矩阵维度一样
- full padding:保证边缘像素点和中间像素点被处理的次数是一样的
特征图(feature map):input和kernel对应相乘得到。有多少个kernel就有多少个feature map
偏置项:往往是一个标量,直接加在原始的feature map上即可
例:对于一张具有三通道的RGB颜色的图像(大小为6×6×3)
具有三个颜色通道的卷积核(大小为3×3×3)
= 生成一个4×4大小的特征图 (6-3+2*0)/1 + 1 = 4
计算公式:
������=(�����−������_����+2∗�������)/������+1 (向下取整)
激活函数放在卷积后
Normalization:如 ReLus(Rectified Linear Units,修正线性单元激活函数)把feature map上负数的部分全部变为0
2、池化层

Pooling (or sometimes called subsampling) layer make the CNN a little bit translation invariant in terms of the convolution output
缩小得到的feature map,在保留feature map原先特征的同时,缩小数据量
- 最大池化(max pooling):常用
- 平均池化(avg pooling)
池化的作用:
- 减少参数量且保留原始特征(大图变为小图,但保留了大图的特征)
- 防止过拟合
- 可以为CNN带来“平移不变性”(强化学习训练一个打桩游戏,不能加入池化层,会丢失位置信息)
3、全连接层

Fully connected layers will combine features learnt by different convolution kernels so that the network can build a global representation about the holistic image
每个神经元都要乘以一定的权重,最后加和起来。隐藏层里可以有不止一个全连接层
CNN & 全连接神经网络 异同:
CNN和全连接神经网络都是通用函数的拟合器(黑箱),都为 input layer + hidden layer + output layer;
对比全连接神经网络, CNN是局部连接,且CNN的 hidden layer 增加了convolution和subsampling
4、参数计算
可训练参数个数:
- 6个5×5卷积核:(5×5+1)×6 = 156 (+1为偏置项)
- 假设最后一层卷积得到的结果是5×5×16,flatten后为5×5×16=400。输入下一层全连接层(有120个神经元),可训练参数个数为:120×(400+1)= 48120 (+1为偏置项)
初始参数/超参数(hyper parameters,即事先人为定好的参数):
- 卷积核尺寸、数目
- 池化步长、大小
- 全连接层神经元的数量
5、总结
- 卷积层将学习数据中的各种局部特征,池化层将使CNN对这些特征的平移具有不变性
The convolution layers will learn various local features in the data (e.g. what an eye looks like), then the pooling layer will make the CNN invariant to translations of these features (e.g. if the eye appear slightly translated in two images, the CNN will still recognise it as an eye). Finally we have fully connected layers, that says, “we found two eyes, a nose and a mouth, so this must be a person, and activate the correct output.
- 卷积核&全连接层的权重都不是人为指定的,而是通过大量的样本进行反向传播学习出来的(一般计算模型有多少层,都是指带权重的层数)
- 梯度下降(Gradient Descent):通过修改卷积层的参数&全连接层每一个神经元的权重 —> finetune —> 最小化 loss function —> 反馈
We optimise each convolution kernel and fully-connected neurons, by taking a small step in the opposite direction shown by the gradient of each parameter with respect to the loss
- 可视化神经网络的一个工具:tensorboard
- T-SNE/PCA:降维&可视化
6、CNN保持平移、缩放、变形不变性的原因
- 局部感受野:每个神经元仅与输入神经元的一块区域连接,这块局部区域称作感受野。局部连接的思想也是受启发于生物学里面的视觉系统结构,视觉皮层的神经元就是局部接受信息的(平移不变性)
- 权值共享:卷积核是共享的,即用的都是同一个卷积核(缩放不变性)
- 下采样、池化:减少参数,防止过拟合(变形不变性)
















 3157
3157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









